1. Introduction
In this paper we present a new type of Restarted Krylov methods. Given a symmetric matrix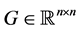 , the method is aimed at calculating a cluster of k exterior eigenvalues of G. Other names for such eigenvalues are “peripheral eigenvalues” and “extreme eigenvalues”. The method is best suited for handling large sparse matrices in which a matrix-vector product needs only 0(n) flops. Another underlying assumption is that k2 is considerably smaller than n. The need for computing a few extreme eigenvalues of such a matrix arises in many applications, see [1] - [21] .
, the method is aimed at calculating a cluster of k exterior eigenvalues of G. Other names for such eigenvalues are “peripheral eigenvalues” and “extreme eigenvalues”. The method is best suited for handling large sparse matrices in which a matrix-vector product needs only 0(n) flops. Another underlying assumption is that k2 is considerably smaller than n. The need for computing a few extreme eigenvalues of such a matrix arises in many applications, see [1] - [21] .
The traditional restarted Krylov methods are classified into three types of restarts: “Explicit restart” [1] , [9] , [11] , “Implicit restart” [1] , [3] , [12] , and “Thick restart” [18] , [19] . See also [7] , [11] , [14] , [16] . When solving symmetric eigenvalue problems all these methods are carried out by repeated use of the Lanczos tridiagonalization process, and the use of polynomial filtering to determine the related starting vectors. This way each iteration generates a new tridiagonal matrix and computes its eigensystem. The method proposed in this paper is based on a different framework, one that avoids these techniques. The basic iteration of the new method have recently been presented by this author in [4] . The driving force is a monotonicity property that pushes the estimated eigenvalues toward their limits. The rate of convergence depends on the quality of the Krylov matrix that we use. In this paper we introduce a modified scheme for generating the Krylov matrix. This leads to dramatic improvement in the rate of convergence, and turns the method into a powerful tool.
Let the eigenvalues of G be ordered to satisfy
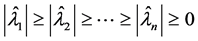 (1.1)
(1.1)
or
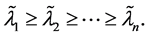 (1.2)
(1.2)
Then the new algorithm is built to compute one of the following four types of target clusters that contain k extreme eigenvalues.
A dominant cluster
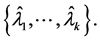 (1.3)
(1.3)
A right-side cluster
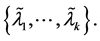 (1.4)
(1.4)
A left-side cluster
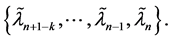 (1.5)
(1.5)
A two-sides cluster is a union of a right-side cluster and a left-side cluster. For example, 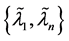 or
or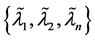 .
.
Note that although the above definitions refer to clusters of eigenvalues, the algorithm is carried out by computing the corresponding k eigenvectors of G. The subspace that is spanned by these eigenvectors is called the target space.
The basic iteration
The qth iteration, 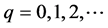 , is composed of the following five steps. The first step starts with a matrix
, is composed of the following five steps. The first step starts with a matrix 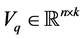 that contains “old” information on the target space, a matrix
that contains “old” information on the target space, a matrix 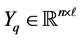 that contains “new” information, and a matrix
that contains “new” information, and a matrix 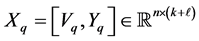 that includes all the known information. The matrix
that includes all the known information. The matrix 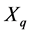 has
has 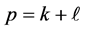 orthonormal columns. That is
orthonormal columns. That is
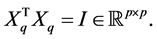
(Typical values for 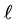 lie between k to 2k.)
lie between k to 2k.)
Step 1: Eigenvalues extraction. First compute the Rayleigh quotient matrix
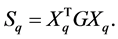
Then compute k eigenpairs of 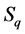 which correspond to the target cluster. (For example, if it is desired to compute a right-side cluster of G, then compute a right-side cluster of
which correspond to the target cluster. (For example, if it is desired to compute a right-side cluster of G, then compute a right-side cluster of![]() .) The corresponding k eigenvectors of
.) The corresponding k eigenvectors of ![]() are assembled into a matrix
are assembled into a matrix
![]()
which is used to compute the related matrix of Ritz vectors,
![]()
Note that both ![]() and
and ![]() have orthonormal columns, and
have orthonormal columns, and ![]() inherits this property.
inherits this property.
Step 2: Collecting new information. Compute a Krylov matrix ![]() that contains new information on the target space.
that contains new information on the target space.
Step 3: Orthogonalize the columns of ![]() against the columns of
against the columns of![]() . There are several ways to achieve this task. In exact arithmetic the resulting matrix,
. There are several ways to achieve this task. In exact arithmetic the resulting matrix, ![]() , satisfies the Gram-Schmidt formula
, satisfies the Gram-Schmidt formula
![]()
Step 4: Build an orthonormal basis of Range (Zq). Compute a matrix,
![]()
whose columns form an orthonormal basis of Range (Zq). This can be done by a QR factorization of![]() . (If rank (Zq) is smaller than
. (If rank (Zq) is smaller than![]() , then
, then ![]() is temporarily reduced to be rank (Zq).)
is temporarily reduced to be rank (Zq).)
Step 5: Define ![]() by the rule
by the rule
![]()
which ensures that
![]()
At this point we are not concerned with efficiency issues, and the above description is mainly aimed to clarify the purpose of each step. Hence there might be better ways to carry out the basic iteration.
The plan of the paper is as follows. The monotonicity property that motivates the new method is established in the next section. Let![]() , denote the Ritz values which are computed at Step 1 of the qth iteration. Then it is shown that each iteration gives a better approximation of the target cluster. Moreover, for each
, denote the Ritz values which are computed at Step 1 of the qth iteration. Then it is shown that each iteration gives a better approximation of the target cluster. Moreover, for each![]() , the sequence
, the sequence![]() , proceeds monotonously toward the desired eigenvalue of G. The rate of convergence depends on the information matrix
, proceeds monotonously toward the desired eigenvalue of G. The rate of convergence depends on the information matrix![]() . The method proposed in Section 3 is based on a three-term recurrence relation that leads to rapid convergence. A further improvement can be gained by Power acceleration, see Section 4. The paper ends with numerical experiments that illustrate the usefulness of the proposed methods.
. The method proposed in Section 3 is based on a three-term recurrence relation that leads to rapid convergence. A further improvement can be gained by Power acceleration, see Section 4. The paper ends with numerical experiments that illustrate the usefulness of the proposed methods.
2. The Monotonicity Property
The monotonicity property is an important feature of the new iteration, whose proof is given in [4] . Yet, in order to make this paper self-contained, we provide the proof. We start by stating two well-known interlacing theorems, e.g., [8] , [10] and [20] .
Theorem 1 (Cauchy interlace theorem) Let ![]() be a symmetric matrix with eigenvalues
be a symmetric matrix with eigenvalues
![]() (2.1)
(2.1)
Let the symmetric matrix ![]() be obtained from G by deleting
be obtained from G by deleting ![]() rows and the corresponding
rows and the corresponding ![]() columns. Let
columns. Let
![]() (2.2)
(2.2)
denote the eigenvalues of H. Then
![]() (2.3)
(2.3)
and
![]() (2.4)
(2.4)
In particular, for ![]() we have the interlacing relations
we have the interlacing relations
![]() (2.5)
(2.5)
Corollary 2 (Poincarà separation theorem) Let the matrix ![]() have k orthonormal columns. That is
have k orthonormal columns. That is![]() . Let the matrix
. Let the matrix ![]() have the eigenvalues (2.2). Then the eigenvalues of H and G satisfy (2.3) and (2.4).
have the eigenvalues (2.2). Then the eigenvalues of H and G satisfy (2.3) and (2.4).
Let us turn now to consider the qth iteration of the new method,![]() . Assume first that the algorithm is aimed at computing a cluster of k right-side eigenvalues of G,
. Assume first that the algorithm is aimed at computing a cluster of k right-side eigenvalues of G,
![]()
and let the eigenvalues of the matrix
![]()
be denoted as
![]()
Then the Ritz values which are computed at Step 1 are
![]()
and these values are the eigenvalues of the matrix
![]()
Similarly,
![]()
are the eigenvalues of the matrix
![]()
Therefore, since the columns of ![]() are the first k columns of
are the first k columns of![]() ,
,
![]()
On the other hand from Corollary 2 we obtain that
![]()
Hence by combining these relations we see that
![]() (2.6)
(2.6)
for ![]() and
and![]() .
.
The treatment of a left-side cluster is done in a similar way. Assume that the algorithm is aimed at computing a cluster of k left-side eigenvalues of G,
![]()
Then similar arguments show that
![]() (2.7)
(2.7)
for![]() , and
, and![]() .
.
Recall that a two-sides cluster is the union of a right-side cluster and a left- side one. In this case the eigenvalues of ![]() that correspond to the right-side satisfy (2.6) while eigenvalues of
that correspond to the right-side satisfy (2.6) while eigenvalues of ![]() that correspond to the left-side satisfy (2.7). A similar situation occurs in the computation of a dominant cluster, since a dominant cluster is either a right-side cluster, a left-side cluster, or a two-sides cluster.
that correspond to the left-side satisfy (2.7). A similar situation occurs in the computation of a dominant cluster, since a dominant cluster is either a right-side cluster, a left-side cluster, or a two-sides cluster.
3. The Basic Krylov Matrix
The basic Krylov information matrix has the form
![]() (3.1)
(3.1)
![]()
where ![]() is a vector of ones. Note that there is no point in setting
is a vector of ones. Note that there is no point in setting![]() , since in the next step
, since in the next step ![]() is orthogonalized against
is orthogonalized against![]() .
.
The proof of the Kaniel-Paige-Saad bounds relies on the properties of Chebyshev polynomials, while the building of these polynomials is carried out by using a three term recurrence relation, e.g. [10] , [11] . This observation suggests that in order to achieve these bounds the algorithm for generating our Krylov sequence should use a “similar” three term recurrence relation. Indeed this feature is one of the reasons that make the Lanczos recurrence so successful, see ( [11] , p. 138). Below we describe an alternative three term recurrence relation, which is based on the Modified Gram-Schmidt (MGS) orthogonaliza- tion process.
Let ![]() be a given vector and let
be a given vector and let ![]() be a unit length vector. That is
be a unit length vector. That is ![]() where
where ![]() denotes the Euclidean vector norm. Then the statement “orthogonalize
denotes the Euclidean vector norm. Then the statement “orthogonalize ![]() against
against![]() ” is carried out by replacing
” is carried out by replacing ![]() with
with![]() . Similarly, the statement “normalize
. Similarly, the statement “normalize![]() ” is carried out by replacing
” is carried out by replacing ![]() with
with![]() . With these conventions at hand the construction of the vectors
. With these conventions at hand the construction of the vectors![]() , is carried out as follows.
, is carried out as follows.
The preparations part
a) Compute the starting vector:
![]() (3.2)
(3.2)
b) Compute![]() : Set
: Set![]() .
.
Orthogonalize ![]() against
against![]() .
.
Normalize![]() .
.
c) Compute![]() : Set
: Set![]() .
.
Orthogonalize ![]() against
against![]() .
.
Orthogonalize ![]() against
against![]() .
.
Normalize![]() .
.
The iterative part
For![]() , compute
, compute ![]() as follows:
as follows:
a) Set![]() .
.
b) Orthogonalize ![]() against
against![]() .
.
c) Orthogonalize ![]() against
against![]() .
.
d) Reorthogonalization: For![]() , orthogonalize
, orthogonalize ![]() against
against![]() .
.
e) Normalize![]() .
.
The reorthogonalization step is aimed to ensure that the numerical rank of ![]() will stay close to
will stay close to![]() . Yet for small values of
. Yet for small values of ![]() it is not essential.
it is not essential.
4. The Power-Krylov Matrix
Assume for a moment that the algorithm is aimed at calculating a cluster of k dominant eigenvalues. Then the Kaniel-Paige-Saad bounds suggest that slow rate of convergence is expected when these eigenvalues are poorly separated from the other eigenvalues. Indeed, this difficulty is seen in Table 2, when the basic Krylov matrix is applied on problems like “Very slow geometric” and “Dense equispaced”. Let ![]() be a small integer. Then the larger eigenvalues of the powered matrix,
be a small integer. Then the larger eigenvalues of the powered matrix, ![]() , are better separated than those of G. This suggests that a faster rate of convergence can be gained by replacing G with
, are better separated than those of G. This suggests that a faster rate of convergence can be gained by replacing G with![]() .
.
The implementation of this idea is carried out by introducing a small modification in the construction of![]() : Here the computation of
: Here the computation of![]() ,
, ![]() , starts with
, starts with
![]() (4.1)
(4.1)
(In our experiments![]() .) It is important to stress that this is the only part of the algorithm that uses
.) It is important to stress that this is the only part of the algorithm that uses![]() . All the other steps of the basic iteration remain unchanged. In particular, the Ritz values which are computed in Step 1 are those of G (not
. All the other steps of the basic iteration remain unchanged. In particular, the Ritz values which are computed in Step 1 are those of G (not![]() ). Of course, in practice
). Of course, in practice ![]() is never computed. Instead
is never computed. Instead ![]() is computed by a sequence of
is computed by a sequence of ![]() matrix-vector multiplications.
matrix-vector multiplications.
The usefulness of the Power-Krylov approach depends on two factors: The cost of a matrix-vector product and the distribution of the eigenvalues. As noted above, it is expected to reduce the number of iterations when the k largest eigenvalues of G are poorly separated from the rest of the spectrum. See Table 3. Another advantage of this approach is that ![]() is kept small. Note that although the computational effort per iteration increases, a smaller portion of time is spent on orthogonalizations and on the Rayleigh-Ritz procedure.
is kept small. Note that although the computational effort per iteration increases, a smaller portion of time is spent on orthogonalizations and on the Rayleigh-Ritz procedure.
5. The Initial Orthonormal Matrix
To start the algorithm we need to supply an “initial” orthonormal matrix, ![]() , where
, where![]() . This task can be done in the following way. Define
. This task can be done in the following way. Define ![]() and let
and let ![]() matrix
matrix
![]() (5.1)
(5.1)
be generated as in Section 3, using some arbitrary starting vector![]() . Then
. Then ![]() is obtained by computing an orthonormal basis of Range(B0). A similar procedure is used in the Power-Krylov method.
is obtained by computing an orthonormal basis of Range(B0). A similar procedure is used in the Power-Krylov method.
In our experiments ![]() is initiated by the vector
is initiated by the vector ![]() where
where ![]() . Yet a random starting vector is equally good. In the next section we shall see that the above choice of
. Yet a random starting vector is equally good. In the next section we shall see that the above choice of ![]() is often sufficient to provide accurate estimates of the desired eigenpairs.
is often sufficient to provide accurate estimates of the desired eigenpairs.
6. Numerical Experiments
In this section we describe some experiments with the proposed methods. The test matrices have the form
![]() (6.1)
(6.1)
where
![]() (6.2)
(6.2)
Recall that in Krylov methods there is no loss of generality in experimenting with diagonal matrices, e.g., ( [6] , p. 367). The diagonal matrices that we have used are displayed in Table 1. All the experiments were carried out with n = 12,000. The experiments that we have done are aimed at computing a cluster of k dominant eigenvalues. The figures in Table 2 and Table 3 provide the number of iterations that were needed to satisfy the inequality
![]() (6.3)
(6.3)
Thus, for example, from Table 2 we see that only 4 iterations are needed when the algorithm computes ![]() eigenvalues of the Equispaced test matrix.
eigenvalues of the Equispaced test matrix.
The ability of the basic Krylov matrix to achieve accurate computation of the eigenvalues is illustrated in Table 2. We see that often the algorithm terminates within a remarkably small number of iterations. Observe that the method is highly successful in handling low-rank matrices, matrices which are nearly low-
rank, like “Harmonic” or “Geometric”, and matrices with gap in the spectrum. In such matrices the initial orthonormal matrix, ![]() , is sufficient to provide accurate eigenvalues. Note also that the method has no difficulty in computing multiple eigenvalues.
, is sufficient to provide accurate eigenvalues. Note also that the method has no difficulty in computing multiple eigenvalues.
As expected, a slower rate of convergence occurs when the dominant eigen- alues that we seek are poorly separated from the other eigenvalues. This situation is demonstrated in matrices like “Dense equispaced” or “Very slow geometric”. Yet, as Table 3 shows, in such cases the Power-Krylov method leads to considerable reduction in the number of iterations.
7. Concluding Remarks
The new type of Restarted Krylov methods avoids the use of Lanczos algorithm. This simplifies the basic iteration, and clarifies the main ideas behind the
![]()
Table 2. Computing k dominant eigenvalues with the basic Krylov matrix,![]() .
.
![]()
Table 3. Computing k dominant eigenvalues with the Power-Krylov matrix,![]() .
.
method. The driving force that ensures convergence is the monotonicity proper- ty, which is easily concluded from the Cauchy-Poincaré interlacing theorems. The proof indicates too important points. First, there is a lot of freedom in choosing the information matrix, and that monotonicity is guaranteed as long as we achieve proper orthogonalizations. Second, the rate of convergence depends on the “quality” of the information matrix. This raises the question of how to define this matrix. Since the algorithm is aimed at computing a cluster of exterior eigenvalues, a Krylov information matrix is a good choice. In [4] we have tested the classical Krylov matrix where ![]() is obtained by normalizing
is obtained by normalizing![]() . However, as shown in [5] , this matrix suffers from certain deficiencies. In this paper the Krylov basis is built by a three term recurrence relation, which leads to dramatic reduction in the number of iterations.
. However, as shown in [5] , this matrix suffers from certain deficiencies. In this paper the Krylov basis is built by a three term recurrence relation, which leads to dramatic reduction in the number of iterations.
Indeed, the results of our experiments are quite encouraging. We see that the algorithm requires a remarkably small number of iterations. In particular, it efficiently handles various kinds of low-rank matrices. In these matrices the initial orthonormal matrix is often sufficient for accurate computation of the desired eigenpairs. The algorithm is also successful in computing eigenvalues of “difficult” matrices like “Dense equispaced” or “Very slow geometric decay”.