Application of ANN and MLR Models on Groundwater Quality Using CWQI at Lawspet, Puducherry in India ()
1. Introduction
Fresh water covers about 2.5% of earth’s water out of which groundwater constitutes about 30.1% (https://water.usgs.gov). Even though groundwater is abundant, it may still be unusable when its quality is considerably deteriorated by chemical and bacteriological contamination due to anthropogenic activities in social and industrial sectors. The increase in population and urbanization plays a pressing role in augmenting the demand for water supply in municipal and industrial sectors.
The natural processes like weathering of rocks/soils, atmospheric precipitation etc., play an important role in the chemical constitution of groundwater [1] [2] . Further exploitation of groundwater due to agrarian, industrial and urban activities plays a critical part in the degradation of groundwater quality [3] . However in the recent years, anthropogenic activities like discharge of untreated or partially treated waste water, mining and related activities, solid waste dumping, contaminated agricultural runoff due to pesticides etc., compound the likelihood of groundwater deterioration [4] .
Furthermore the groundwater qualitatively relies on the physio-chemical and bacteriological quality of recharged water, inland surface run off and subterranean geochemical responses. Cyclic changes in groundwater may also be brought about by hydrological and anthropogenic components [5] [6] .
Casual regulation and multiplying anthropogenic activities frequently lead to the disproportionate dispensation of chemical components in groundwater, resulting in varying analytical data. So there is a critical demand for the planners, administrators and managers to distinguish the groundwater pollution and search for a fruitful and reliable system for regulating ground water resources and allied pollution [6] .
The monitoring and analysis of water quality status are absolutely necessary to detect long-term trends in selected water quality parameters so as to discern prospective water quality problems. It is intended to determine the most contributing parameters which cause alterations in groundwater quality by calculating water quality indices for various water uses like drinking water, irrigation, recreation, aquatic life etc. The water quality assessment shows the variation of water quality parameters. At the same moment, good quality of water must be adequately accessible to nurture hale and healthy life.
Regionally because of non-availability of surface water, the entire population of Puducherry, India has to rely upon groundwater reserves. With respect to groundwater deterioration from human activities at Puducherry, we then have two significant aspects:
・ Contamination based on non-engineered Municipal Solid Waste (MSW) dumping
・ Partially treated or Secondary Wastewater (SWW) application on land
In order to assess the groundwater qualitatively, dependable data on water quality is required, which can be acquired through routine water quality surveillance programs. These programs usually generate huge and complicated data matrix containing a number of water quality attributes, which are generally hard to comprehend and evaluate the water quality as a whole. To overcome this, a mathematical technique, which transforms the massive of water quality data into a single count, such as WQI is required to ascertain the extent of pollution in water bodies. Thus WQI is a powerful tool to get overall information on water quality in a readily explicit form that can be utilized by administrators, decision makers and people. The theory of WQI is contingent on the precept of collating water quality parameters with respect to controlling threshold limits.
A single WQI value gives information more precisely and it is easy to understand than a long list of parametric values. Additionally, WQI also facilitates comparison between different sampling locations at different points of time. Considering the simplicity and reliable approach of WQI, it is ascertained that these indices will furnish explicit outlines of overall water quality and possible drifts. Thus, WQI can be used to furnish a comprehensive summary of environmental performance that can be expressed to the public in an understandable pattern. While appreciating the importance and usability of WQI, it is important to know about the limitations of WQI:
1) Lack of information due to amalgamation of several parameters to a single index measure.
2) Sensitivity of the results due to the formulation of the index.
3) Loss of information due to exchange among parameters, and
4) Want of flexibility of the index to divergent ecosystems.
Thus, WQI can be used as a powerful tool to get overall information and a comprehensive summary of environmental performance on water quality in a readily explicit form that can be utilized by administrators, decision makers and people in an understandable pattern [7] . Further, WQI is neither a replacement to the detailed analysis of environmental monitoring and modeling, nor should it be the only tool for the management of water bodies.
In this situation, if deterministic models using MLR or simulation models like ANN could be developed for finding out water quality index, then it will be of great help to the managerial community to closely monitor the groundwater quality and the models so developed, could be a reliable alternative to the complicated and time consuming water quality index calculations. Further these models are very practical, robust and cost effective.
2. Study Area and Present Scenario
Puducherry is a Union Territory in India with an extent of 293 km2. The entire urban and sub urban areas of Puducherry are divided into nine zones for the purpose of water supply and comprehensive underground drainage system. Among the nine zones, Zone V (Lawspet) is a likely zone for groundwater exploitation. The borewells in Zone V are the only sources of water supply to coastal zones like Zone II (Muthialpet) and Zone V (Lawspet), as the current water supply in these zones are contaminated due to sea water intrusion. Of late, Zone V area is also getting affected due to the above said anthropogenic activities. Under these circumstances, it was decided to adopt Zone V which is a potential groundwater source, for study purposes in order to prevent further contamination.
The study area falls in Zone V (Lawspet) area, wherein the STP and solid waste landfill are located in the same campus at Karuvadikuppam, Lawspet at Latitude 11˚58'16''N and Longitude 79˚48'11''E on the northern part of Puducherry, India (Figure 1). The terrain declines from North to South and the ground elevation ranges from 53 m to 6 m as shown in Figure 1. The area is identified with tropical climate with a mean yearly precipitation of 1200 mm, 35% of which takes place during the South-West monsoon from June to September and the remaining 65% befalls during the North-East monsoon i.e. from October to December [8] . Presently 15 MLD of wastewater is treated using four serially connected facultative oxidation ponds and 1 UASB of capacity 2.5 MLD. Domestic sewage of BOD 250 mg/L is treated with a removal efficiency of 65%. Nearly, 12.5 MLD of partially treated SWW is discharged into a recharge pond area of 18 acres, since 1980 [8] .
A portion of Sewage Treatment Plant (STP) site at Karuvadikuppam is used as solid waste landfill. Solid waste tipping started in 2004 and discontinued in 2013 only and it spreads over an area of 21 acres approximately [9] . It is a non-engi- neered low lying open dump. The land fill is unlined and the solid waste has been dumped indiscriminately in an unscientific way and irregular fashion. The solid waste landfill height varies from 2 m to 6 m. So in Puducherry, a unique situation of co-disposal of MSW dumping and SWW disposal on land prevails simultaneously within the same campus.
Against this back drop an effort has been attempted to investigate the spatial variation of water quality using, a readily understandable indicator, i.e. water quality index (WQI) for various intended uses (drinking and domestic uses).
Broadly the objectives of the study were to 1) to apply the water quality index (WQI) so that the changes in the ground water quality of the study area can be monitored mainly for drinking purposes 2) to develop a Multivariate Linear Regression (MLR) model, to simulate WQI which is commonly used as an indicator of groundwater pollution 3) to establish an Artificial Neural Network (ANN) model that can be applied to directly foretell the water quality condition in the study area and thus furnish a dependable substitute to the WQI calculation method presently in use and 4) to evaluate the effectiveness of two data oriented methodologies viz., MLR and ANN.
![]()
Figure 1. Location map, elevation and sampling borewell sites in study area.
3. Methodology
3.1. Sample Collection and Monitoring of Borewells
Nearly 125 water supply and agricultural borewells are located in and around STP within a radial distance of 2.5 km from STP and solid waste landfill. To accurately represent the groundwater quality, a sampling strategy was formulated to include a wide range of bore wells at the pivotal locations. Totally, 68 borewells were identified in and around the study area and depicted in Figure 1. All the bore wells were considered for investigation and water samples were collected every month from Jan 2014-Dec 2015 from solid waste dump area, recharge pond area, sewage farm area (existing) and peripheral area (private & Govt.) in order to study the seasonal and spatial variations.
3.2. Physio-Chemical Analysis of Groundwater
Water samples were collected from the borewells after pumping for 15 minutes. The samples were analyzed in the Public Health Laboratory, PWD, Puducherry, India. Totally 1065 water samples were collected and tested for 17 physiochemical and bacteriological parameters viz. EC, pH, TDS, Alkalinity, 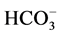 , TH, Ca2+, Mg2+, Fe2+, Cl−,
, TH, Ca2+, Mg2+, Fe2+, Cl−, 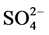 ,
, 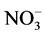 , Na+, F-, K+,
, Na+, F-, K+, 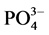 , Si4+, BOD, COD. Total Coliforms and Faecal Coliforms according to the standard methods [9] [10] . However the study was restricted to the pollution aspects of tenwater quality parameters viz. EC, TDS,
, Si4+, BOD, COD. Total Coliforms and Faecal Coliforms according to the standard methods [9] [10] . However the study was restricted to the pollution aspects of tenwater quality parameters viz. EC, TDS, 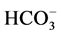 , TH, Ca2+, Mg2+, Cl−,
, TH, Ca2+, Mg2+, Cl−, 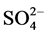 , Na+, and K+.
, Na+, and K+.
3.3. Canadian Water Quality Index (CWQI)
The Canadian Council of Ministers of the Environment Water Quality Index (CWQI) is a well-established and universally accepted model for evaluating the WQI. The CWQI compares observations to a guideline value, which can be a water quality criterion or a locality specific chemical composition of a hydro geological parameter.
The CWQI was formulated with the purpose of rendering a mechanism for reducing the documentation of water quality data [11] [12] [13] . As a compendious tool, it furnishes a wide sketch of water quality data and it is functional for various purposes including drinking water quality, data communications, ambient water quality data processing, combined watershed designing, management and policy decisions in the water supply sector.
The model essentially consists of three measures of variance based on selected guideline values or threshold limits (scope, frequency, amplitude) as detailed below:
1) The number of variables whose objectives are not met (scope).
2) The frequency with which the objectives are not met (frequency).
3) The amount by which the objectives are not met (amplitude).
These values are concerted to bring about a single value (between 0 and 100) portraying the water quality. A value of 100 is the best possible index score and a value of 0 is the worst possible. The Canadian Water Quality Index (CWQI) is computed as follows:
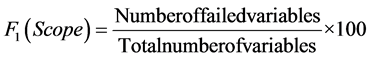
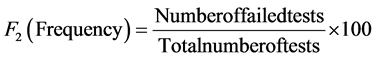
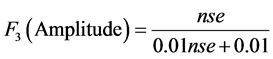
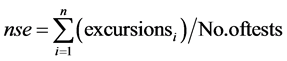
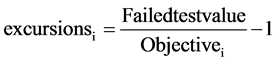
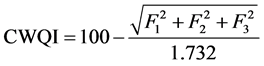
A sample calculation for computing CWQI (refer Table 1) for borewell (BW1) is as follows:
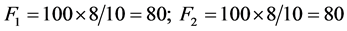
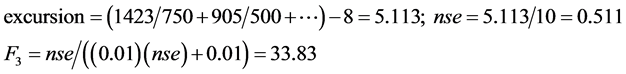
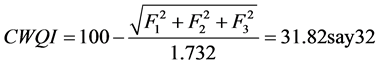
3.4. Multivariate Statistical Analysis
As there is wide spatial variation (2 to 3 km radius) with ground elevation (more than 45 m) among the borewells it is appropriate to investigate the quality of the ground water in the entire study area applying multivariate statistical analysis.
Uncertainty is innate in all methods of evaluating groundwater pollution, arising from missing data, the natural, spatial and temporal in consistency of the hydrogeological variables in the field, and in mathematical computation. Conventional procedures are inferior at addressing the non-linearity, subjectivity, and intricacy of the cause-effect association between water quality parameters and conditions but still they are the presently accepted procedures.
In similar situations, multivariate statistical methods [14] [15] [16] [17] and artificial neural networks, can be effectively used in a wide variety of environmental applications. The results demonstrated that the combined approach effectively interpreted the geological significance of the factors, and also reduced the area of exploration targets.
3.5. Artificial Neural Networks (ANN)
Several deterministic models have been tried in the past for prediction of CWQI
![]()
Table 1. Mean physio-chemical test results of BW1.
Note: EC-µs/cm, all other parameters mg/L.
in groundwater. These models require input data, model parameters, and extensive information to obtain results. But, in practice the statistical precision of the models is not encouraging because natural systems tend to be too complex for deterministic modeling [18] [19] .
Further, because of large number of factors affecting the water quality, and their complicated nonlinear relationships with the variables, the traditional deterministic models are not easy to handle. On the contrary ANNs provide a quick, flexible and reliable means of creating models for estimating groundwater quality. Currently ANNs have revealed very good realization as regression tools, chiefly when applied for pattern recognition and function estimation. Thus ANN is used as an approximation tool rather than a complex mathematical calculation, which results in admissible deviation of predicted value from observed data [20] [21] .
In relation to the conventional approaches, ANNs admit approximate or missing data, inexact results, and they are less susceptible to outliers. Further they are highly parallel, i.e., their multitudinous independent operations can be handled concurrently. Because of parallel processing architecture, ANN is competent enough to manipulate complicated numerations, thus making it the most popular technique today for high speed computing of large data. In addition, there are many advantages in problem solving as elaborated below:
1) Application of a neural network does not call for previous comprehension of the underlying process, so it can be employed to solve the problems vaguely described.
2) No need to identify all the complex associations among various features of the process under analysis.
3) A conventional optimisation procedure or statistical model delivers a solution only when executed completely whereas a neural network always converges to a local optimal result.
4) The model has more forbearance to noise and ambiguous data thereby requiring less information for model development.
5) The findings are the outcome of the generic behaviour of data, as such the influence of outlier is reduced.
For these reasons ANNs are found to be more suitable for handling various hydrological modeling problems [22] [23] .
3.5.1. Structure of an ANN
ANN is a simulation of the real nervous system in other words, it is a numerical model contingent on biological neural networks. It is a system which consists of a collection of units called “neurons” communicating with each other in a network that works to produce a simulated output. ANNs are inspired by the activity of human brain. The basic units of any biological neural system are neurons, which are classified into sets, consisting of millions of them, organized in layers and constitute their own functional arrangement. A set of these subsystems create a global system [24] [25] .
3.5.2. Components of an ANN
Typically a neuron receives many parallel and multiple inputs. Each input has its own relative weight which signifies the importance of the input within the activation function of the neuron. These weights do the same role played by the biological neurons in synapses. In both cases, some inputs are more important than others so they have more involvement in the processing of the neuron and to produce a neuronal result. The weights are coefficients that can be adapted within the network depending on the intensity of the input signal, received by the artificial neuron [26] .
Based on the inputs and weights, the summing part provides the potential postsynaptic value “hi” of the neuron. The most common function is the sum of all weights and inputs, by grouping the inputs and weights in two vectors (![]() ) and (
) and (![]() ) and then calculate this amount making the scalar product of two vectors.
) and then calculate this amount making the scalar product of two vectors.
![]() (1)
(1)
where hi(t) is post synaptic potential.
The inputs and weights can be combined in different ways before transferring the value to the activation function. The specific algorithm for the propagation of neural inputs depends on the choice of architecture. The result of the summing part in most cases is a weighed sum, which is transformed into the actual output of the neuron through an algorithmic process known as activation function.
![]() (2)
(2)
The activation function depends on the postsynaptic potential “hi(t)” and its previous state of activation. However, in many models of ANN, the current state of the neuron does not depend on its previous state “ai(t − 1)”, but only on the current state.
![]() (3)
(3)
In the activation function, the value of the output combination can be compared with a threshold value for determining the output of the neuron. If the sum is greater than the threshold value, a neuron signal is generated. If the sum is less than the threshold, no signal is generated. Usually the threshold value, or transfer function value is typically nonlinear.
Before applying the activation function, some noise is added to the inputs. The source and amount of this noise are determined by training of a particular network. This noise is commonly known as temperature of the neuron. In fact by adding different noise levels to the result of the combination or summing, a model more similar to the brain can be created.
3.5.3. Activation Function
The activation (transfer) function establishes the reaction of a node to the total input signal it acquires. Generally hidden layer utilizes logistic transfer function. By means of an activation function, from hidden layer to output layer, a linear transfer function is applied. Most commonly used non-linear sigmoid function is
![]()
Also hyperbolic tangent transfer function is used in many networks as follows:
![]()
![]()
wi―weights & xi―input variables.
3.5.4. Architecture of an ANN
Generally ANN models (Figure 2) were specified by the network topology, training and/or learning rules [27] [28] . These ambiences have primarily configured the network behaviour with three different layers in the network topology which can be distinguished as:
1) An input layer: contains neurons that acquire information from the environment and connects the input information to the system (network).
2) Hidden layer: acting as an intermediate computational layer.
3) Output layer: the neurons provide the response and produce the desired output of the neural network.
The connections between neurons can be excitatory or inhibitory: a negative synaptic weight defines a negative inhibitory connection, while a positive determines excitatory connection. Intra-layer connections, also called side connections, take place between neurons in one single layer, while the inter-layer connections occur between neurons in different layers. There are also feedback
connections that have an opposite way input-output. Based on these concepts, different neural architectures can set:
・ Single Layer Networks consist just one layer of neurons.
・ Multi-Layer Networks are those whose neurons are organized in several layers, in response to the data flow in a neural network.
・ Feed Forward Networks circulate the information unidirectionally from the input neurons to the output neurons.
・ Feedback Networks circulate the information between the layers in any direction.
3.5.5. Training and Testing Algorithm
In this research work, Multilayer Perceptron (MLP), a feed forward kind of ANN model is employed. In this model, a set of input data is fed into a network to receive a set of suitable output data after due mathematical processing. The MLP model is a network comprises of multiple layers of nodes (neurons) and these layers are interconnected from one layer to another. All the interconnected nodes of various layers form a directed graphical network system. The hidden layer and the output layer are connected through neurons, exercising a nonlinear activation function by a technique known as “back propagation” to train the network system. To standardize the model, the entire data set is segregated into three phases. The first phase is the learning phase which is utilized to train the network. The goal of training is to guarantee that the network replicates the inherent characteristic of the information availed in the ANN modelling. ANN weights and biases are fixed during the training procedure. The input variables and already ascertained output parameters decide the associated weights in such a way that the predicted and observed values are in agreement. Secondly the ANN models are put to testing in order to fix up the stopping criterion as when to stop. Lastly the model is validated utilizing the data which are not included in the training phase [29] [30] [31] .
3.5.6. Model Performance Appraisal
Performance appraisal of the MLR and ANN models is accomplished using three statistical indices, namely: Mean Absolute Error (MAE), Root Mean Squared Error (RMSE) and Coefficient of Determination (R2) to study the capability of simulating cluster wise CWQI. MAE demonstrates the mean of the errors simulated by the developed model and is employed to detect the proximity of simulated values (observed values). RMSE signifies the comprehensive variation between observed and simulated values. R2 represents the measure of the total variance with respect to the observed values, which can be explained by the developed model. The mathematical expressions for MAE and RMSE are as follows:
![]()
![]()
where xoi―observed CWQI and xp―predicted CWQI.
4. Results and Discussion
4.1. Hierarchical Cluster Analysis (HCA)
HCA visualizes intra-relationship among the parameters for a good perception of the studied system. Divergent sampling locations in the study area can be grouped into clusters to spatially explain the similarity in chemical composition of the groundwater quality among the bore wells [32] [33] [34] . The selected ten hydro-chemical parameters in the study area were subjected to HCA. The clustering procedure generated three well defined clusters. Cluster 1 involves 28 bore wells, forming 41% of the sampling stations. Cluster 2 comprises of 8 bore wells, representing 12% of the sampling stations. Cluster 3 accounts for 32 bore wells comprising of 47% of the sampling stations. Clusters 1, 2 and 3 correspond to polluted, highly polluted and non-polluted regions of the study area.
4.2. Descriptive Statistics
During this study some important physio-chemical attributes from shallow groundwater in the study area were obtained and measured. The main intention of this study was to evaluate, determine, predict and compare the groundwater quality dispensation and extent of prospective contamination in the study area using MLR and ANN models. Besides statistically reporting the current status of shallow groundwater for impending comparisons, the study will also be precious to the managers answerable for groundwater development, regulation, exploitation and deterioration. Cluster wise important physio-chemical attributes (EC, TH, ![]() , Cl−,
, Cl−, ![]() , Na+, Ca2+,Mg2+ and K+) of water quality impaired by MSW & SWW exercises, apprehending the complete geology and ambient condition, are statistically assessed and presented in Tables 2-4.
, Na+, Ca2+,Mg2+ and K+) of water quality impaired by MSW & SWW exercises, apprehending the complete geology and ambient condition, are statistically assessed and presented in Tables 2-4.
![]()
Table 2. Descriptive statistics Cluster 1.
NOTE: EC-µs/cm, all other parameters mg/L.
![]()
Table 3. Descriptive statistics Cluster 2.
NOTE: EC-µs/cm, all other parameters mg/L.
![]()
Table 4. Descriptive statistics Cluster 3.
NOTE: EC-µs/cm, all other parameters mg/L.
4.3. Canadian Water Quality Index (CWQI)
CWQI has been formulated, based on the conceptual framework of Canadian Council of Ministers of the Environment [35] [36] [37] . CWQI so developed reflected the physio-chemical quality of the groundwater in the study area. The results from the model are an evidence of the degrading nature of groundwater in the borewell locations. The cluster wise Descriptive Statistics of CWQI values are presented in Tables 2-4. From the findings, it can be observed that the mean value of CWQI in Cluster 1 is 51.67 and the groundwater quality falls under the category “marginal”. Similarly the mean values of CWQI for Clusters 2 and 3 are 30.90 and 84.60 respectively and based on this, the overall groundwater quality of Clusters 2 and 3 can be ascribed as “poor” and “good”. The poor nature of groundwater in Clusters 1 and 2 is mainly attributed to anthropogenic activities viz. 1) indiscriminate solid waste dumping and 2) partially treated SWW land application.
4.3.1. Analysis of Variance (ANOVA)
ANOVA has wide applicability in groundwater quality problems as a versatile diagnostic tool. The parametric one way ANOVA is an addendum of the t-test to multiple sample groups. ANOVA tests for significant differences in one or more clusters. If an overall significant difference is found as measured by F-statistic, post-hoc statistical contrasts may be used to determine where the differences lie among individual group means. In the CWQI monitoring context, only differences of mean relative to background are considered to be important.
The one way ANOVA technique generates one way analysis of variance for a quantitative dependent variable by a single factor independent variable. The purpose of using ANOVA is to address the following questions:
1) What are the main effects of independent variables (monitoring locations/ clusters) on dependent variables (i.e. mean value of CWQI)?
2) What are the interactions among the independent variables?
Thus, one way ANOVA identifies spatial variability among monitoring borewells. Equality of variances among the clusters is evaluated with ANOVA and if it identifies significant differences then natural spatial variability is the likely cause. ANOVA compares the average values of CWQI among clusters to determine whether they are from same continuous distribution and whether significant differences existed between the mean values of CWQI among the clusters.
The hypothesis used is as follows:
H0: There is no difference in the average levels of CWQI between the Clusters 1, 2 and 3.
H1: There are differences in the average levels of CWQI between the Clusters 1, 2 and 3.
Decision making is the rejection of Ho if P value is less than α. The F-statistic and Sig (significance) conform the differentiation of clusters. P < 0.05 shows that high variations of CWQI in terms of their spatial distribution in the study area and consequently it may be concluded that H0 is rejected and H1 is accepted. In other words there are cluster wise differences in the mean values of CWQI, which means the spatial variability and clustering of bore wells based on physio- chemical parameters of the bore wells perform a very crucial role in the study area.
The ANOVA test findings are presented in Table 5. The test results evince that F-statistic (F = 134.55) and p-value (p = 0.000) is less than α = 0.05, implying that there are critical differences in the average values of CWQI among the clusters. Further the difference in the mean values of CWQI, results in the formation of clusters and are mainly due to anthropogenic activities viz. 1) Contamination based on indiscriminate MSW dumping and 2) Partially treated or SWW land application.
4.4. Multi-Linear Regression Model (MLR)
Regression models are best fit for establishing association between dependent and independent variables of small sample size. The MLR is a method applied to ascertain relationship between a dependent variable and one or more independent variables in a linear fashion and it is based on the method of least squares [38] [39] . In the best model, sum of the squared error between observed and predicted values of the parameters should be minimum. CWQI estimation also can be performed using MLR models which explain linear relationship among various hydrogeological parameters and is as follows:
![]()
where, Y―CWQI ; α―regression constant ; ??andom error.
a, b, c, d, e, f, g, h, i and j are coefficients of predictors in linear regression model;
EC, TDS, TH, ![]() , Cl−,
, Cl−, ![]() , Na+, Ca2+, Mg2+ and K+ are input parameters.
, Na+, Ca2+, Mg2+ and K+ are input parameters.
The findings of MLR study for three clusters adopting 10 independent water quality parameters are summarized in Table 6. These are unstandardized regression co-efficients/weights which are incorporated in the regression equation. The MLR model developed employing stepwise regression technique to predict CWQI in Cluster 1 is:
![]()
Similarly MLR models for Clusters 2 and 3 can be developed. In Cluster 2, the variables EC, TDS and Ca2+ had been removed from the model during stepwise regression because their regression co-efficients were observed to be statistically inconsequential in simulating CWQI. Further F-test was adopted to examine the complete significance of the formulated MLR model for simulating CWQI. Furthermore the results of ANOVA of the MLR models of the three clusters are presented in Table 5.
From Table 5 & Table 6, it is observed that in Cluster 1 from the F-statistic (F= 12.165) and p value (p = 0.000), it is resolved that it is in fact a significant model i.e. the independent variables interpret a significant degree of variability in the prediction of CWQI and it is also confirmed that R2 (0.88) is remarkably significant for this model.
It is evident from the Table 6 that the MLR model for Cluster 2 has the highest R2 (1) value and is supported by F-statistic and p-level. However the MLR
![]()
Table 5. ANOVA test for cluster classification and MLR models.
![]()
Table 6. MLR model co-efficients for selected water quality parameters.
model for Cluster 3 has the lowest R2 (0.58) value. This indicates that CWQI of Cluster 3 is not influenced by the anthropogenic activities under consideration. Thus the values of R2, F-statistic, and p-level for MLR models for all the three clusters are statistically significant which indicate that the formulated MLR models can simulate/predict CWQI reasonably.
In general the “sig” column in Table 5 provides the computed value of “p”, if p < 0.05 then null hypothesis Ho is rejected and alternate hypothesis H1 is accepted. In other words the independent variables are significant. In case of CWQI, it can be interpreted that there is spatial variability in Clusters 1, 2 and 3. Similarly the MLR models for Clusters 1, 2 and 3 are significant as the p values are <0.05, and so the alternate hypothesis H1 is accepted and Ho is rejected.
4.5. Development of ANN-MLP Models
To simulate CWQI of groundwater, 10 most significant physio-chemical parameters were chosen. Multi Layer Perceptron (MLP) methodology of ANN was applied using SPSS Version 21.0. 1065 groundwater samples were analysed to model CWQI. 70% of the samples were utilized to train the ANN models and the balance 30% of data were employed to evaluate the model. Primarily 10 variables were used as inputs to ANN. To select the best fit ANN model, a methodology has been worked out for periodic removal of input parameters. By eliminating the input parameters the structure of optimized ANN model was made to run again.
4.5.1. Sensitivity Analysis
Sensitivity analyses were carried out for the ANN model to ascertain the relative weight of each input variable for reasonably simulating CWQI. This analysis was employed for all the three clusters by making certain modifications on distinct inputs and examining their consequences on the model output. The modification in the input was designed by removing certain parameters, while keeping the other input parameters intact and then the model output was simulated. Pursuing this removal approach 9 ANN models for Cluster 1 were developed and furnished in Table 7.
The same approach was adopted for Clusters 2 and 3. The optimal simulated results of all the 9 ANN and MLR models in all the three clusters are summarized in Tables 8-10.
4.5.2. Comparative Performance of the ANN and MLR Models
Further the performances of nine ANN models in simulating CWQI were collated with those of the corresponding MLR models by using R2, RMSE and MAE (quantitative indicators) [40] [41] [42] [43] . The results of this comparison are also presented in Tables 8-10. The model which indicated high R2 value and considerably low MAE and RMSE values, was considered to be best simulated model and is suitable for further analysis.
From the Tables 8-10 it could be seen that in Cluster 1, five ANN models showed R2 values more than 0.9 and the remaining 4 models showed R2 values between 0.85 and 0.9. The MLR model showed R2 value as 0.88. Based on the RMSE (3.99) and MAE (3.52) values, the ANN 9 and MLR models could be considered for further analysis.
In Cluster 2, the R2 values ranged from 0.175 to 0.995. The ANN 2 and ANN 6 models showed R2 values as low as 0.175 and 0.232 respectively. Interestingly the MLR and ANN 8 models showed exactly the same values of R2 (0.995), RMSE (0.23) and MAE (0.207). Both of these models could be considered for further investigation.
![]()
Table 7. Combination of input parameters in ANN models (Cluster 1).
![]()
Table 8. MLR and ANN models―Cluster 1 (CWQI).
Note: BW―Borewell. All values in the Table indicate observed and simulated values of CWQI.
![]()
Table 9. MLR and ANN models―Cluster 2 (CWQI).
Note: BW―Borewell. All values in the Table indicate observed and simulated values of CWQI.
![]()
Table 10. MLR and ANN models―Cluster 3 (CWQI).
Note: BW―Borewell. All values in the Table indicate observed and simulated values of CWQI.
In Cluster 3, the R2 values ranged from 0.122 to 0.925. The ANN 1 and ANN 4 to ANN 8 models showed low R2 values. The ANN 3 is the only model which showed R2 value as high as 0.925 while MLR showed R2 value as 0.555. So ANN 3 model could be termed as best fit model for further examination.
Conclusively in the anthropogenically polluted Clusters 1 and 2, both MLR and ANN models could be considered for further investigation. But, in Cluster 3 which is less polluted, only ANN model is best fit for simulation.
The graphical comparison of observed and optimal simulated CWQI by ANN and MLR models in all the 3 clusters are depicted in Figures 3-5. It is evident from these figures that the predicted CWQI derived by both MLR and ANN models tally fairly well with the observed CWQI in Clusters 1 and 2, whereas in Cluster 3 only ANN model fits well with the observed values. In addition to the concurrent plots, the comparison between observed and simulated CWQIs by ANN was analysed by scatter plots with 1:1 equilines and error bands for all the 3 clusters and the same are illustrated in Figures 6-8.
![]()
Figure 3. Observed and predicted CWQI in Cluster 1.
![]()
Figure 4. Observed and predicted CWQI in Cluster 2.
![]()
Figure 5. Observed and predicted CWQI in Cluster 3.
In these figures the parallel lines (qualitative indicators) indicate higher and lower error bands in relation to 1:1 line. Understandably the simulated CWQI of 23 borewells (82%) fall within ±10% error band in Cluster 1. In Clusters 2and 3, 100% and 94% of the borewells fall within ±5% error band respectively. In view of the quantitative and qualitative realization gauges, the ANN models outperform MLR models in a much better way and this could be ascribed to the fact that MLR is dependent on method of least squares and it is linear in nature, whereas ANN is based on sophisticated nonlinear methods.
5. Conclusion
This research work was attempted to investigate the strength of two data induced methodologies viz. MLR and ANN, for predicting CWQI in groundwater
quality scenario. Using HCA, 3 clusters were developed based on 10 most significant physio-chemical parameters. The cluster classification based on anthropo- genic activities and MLR models so developed have been validated by ANOVA using F-statistic. Each cluster was subjected to simulation of CWQI using one MLR and nine ANN models. The quantitative and qualitative performances of MLR and ANN models were assessed statistically and graphically. The analyses of the results revealed that both MLR and ANN models were fairly good in predicting CWQI in Clusters 1 and 2 with high R2, low RMSE and MAE values. In Cluster 3 only ANN model fared well. This is because MLR models are generally linear in nature and they are poor in their prediction ability especially in noisy data environment. Therefore, ANN models can be considered as a powerful and dependable tool in simulating complex, inter-dependable physio-chemical parameters. Based on the required information, it will be very simple, clear and convenient to adopt either MLR or ANN model depending on environmental conditions to predict the water quality of the study area in a more practical way so that the associated costs, sampling points etc., can be minimized to the maximum extent possible. Thus this research attempt will be very practical to the groundwater management community which is involved in water quality problems.