Longitudinal Survey, Nonmonotone, Nonresponse, Imputation, Nonparametric Regression ()
1. Introduction
Longitudinal surveys refer to a type of sampling surveys done repeatedly over time on the same sampled units. In such surveys, data which are rich in information about the specific sampled unit can be obtained and thus suitable for various purposes. While longitudinal surveys are regarded to be better and reliable in informing about various features of a study unit, they suffer from monotone and intermittent patterns of missing data. This is often as a result of inaccessibility to or deliberate refusal of respondents to provide information after having participated in the surveys thus the occurrence of nonresponses.
Missing data are a problem because nearly all standard statistical methods presume complete information for all the variables included in the analysis. Using data with missing values leads to reduction in sample size which significantly affects the precision of the confidence interval, statistical power reduce and biased population parameter estimates. Imputation is one of the approaches used to intuitively fill in these missing values. Over time, various imputation models have been developed and they have been used to overcome quite a number of challenges caused by missing data. However, some shortcomings still exist such as biasedness and inefficiency of estimators. This is because imputation models have different assumptions in both parametric and nonparametric contexts.
Parametric methods like maximum likelihood estimation have limitations like sensitivity to model misspecification while nonparametric methods are more robust and flexible [1] . Some of the methods used by [2] are simple linear regression imputation and Nadaraya-Watson technique. From their simulation results, it was found that the simple linear regression imputation approach has the weakness of producing biased estimates even when the responses at a particular time (including previous values) are correctly specified. On the other hand, Nadaraya-Watson technique of [3] and [4] used in the imputation of missing values in the longitudinal data has some weaknesses of producing a large design bias and boundary effects that give unreliable estimates for inference.
As shown by [5] and [6] , a rival for Nadaraya-Watson technique is the local linear regression estimator which was found to produce unbiased estimates without boundary effects. [7] studied the weighted Nadaraya-Watson method and was concerned with the limitations of the method such as consistency, asymptotic normality and the interior and boundary point effects. In his study, he found that local linear regression is much better than the weighted Nadaraya-Watson method as it produces asymptotically unbiased estimates without boundary effects. Moreover, [8] also found that the local linear regression estimator (introduced by [9] ) has desirable properties.
In order to overcome the limitations of Nadaraya-Watson estimator, we derive a local linear regression estimator in the imputation of the nonresponndents in a longitudinal data set. The asymptotic properties (unbiasedness and consistency) of the proposed estimator are investigated. Comparisons between various estimators (parametric and nonparametric) are performed based on the bootstrap standard deviation, mean square error and percentage relative bias. A simulation study is conducted to determine the best performing estimator of the finite population mean.
2. Assumptions and Notations
1) All sampled units are observed on the first time point 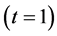 and remain in the sample till the final time
and remain in the sample till the final time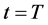 . The variable of interest
. The variable of interest 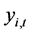 is the value of y for the
is the value of y for the 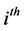 unit at time point t.
unit at time point t.
2) The prediction process is past last value dependent and the vectors
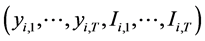 are independently and identically distributed (i.i.d) from the superpopulation under the model-assisted approach.
are independently and identically distributed (i.i.d) from the superpopulation under the model-assisted approach.
For 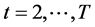 and
and 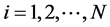 and the response indicator function
and the response indicator function 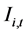 is
is
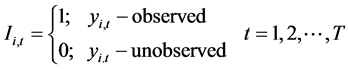 (1)
(1)
3) The vector 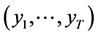 follows the Markov chain for longitudinal survey data without missing values
follows the Markov chain for longitudinal survey data without missing values
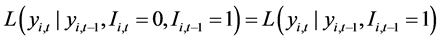 (2)
(2)
4) We assume that the population P is divided into a fixed number of imputation classes, which are basically unions of some small strata.
3. Regularity Conditions
Denote f to be a probability density function (pdf) of X and 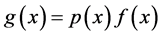 where
where 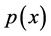 is defined by;
is defined by;
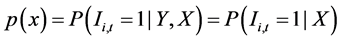 (3)
(3)
and g and f have bounded second derivatives
i) The Kernel function K is a bounded and twice continuously differentiable symmetric function on the interval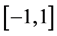 , and such that
, and such that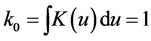 ,
,
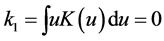 ,
, 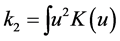 ,
, ![]() and
and![]() .
.
ii) The regression function ![]() is at least twice continuously differentiable every- where in the neighborhood of
is at least twice continuously differentiable every- where in the neighborhood of![]() .
.
iii) The sample survey variable of interest has a finite second moment bounded on the interval![]() . Thus
. Thus![]() .
.
iv) The conditional variance ![]() is bounded and continuous.
is bounded and continuous.
4. Methodology
4.1. Imputation Process
Considering the case of the last past value, we do impute for missing value ![]() by the value obtained through the prediction procedure. But according to [10] , the joint distribution of bivariate random variables (
by the value obtained through the prediction procedure. But according to [10] , the joint distribution of bivariate random variables (![]() ) is preserved when the missing value, Y is imputed by the conditional distribution of Y given X. Therefore, considering the conditional mean imputation approach for the single imputation.
) is preserved when the missing value, Y is imputed by the conditional distribution of Y given X. Therefore, considering the conditional mean imputation approach for the single imputation.
Let
![]() (4)
(4)
be the conditional expectation with respect to the superpopulation for unobserved value ![]() with observed value
with observed value ![]() for
for![]() .
.
It is therefore clear that when ![]() is known, then the imputed value of unobserved
is known, then the imputed value of unobserved ![]() is given by
is given by![]() . In cases where
. In cases where ![]() in Equation (4) is unknown, for nonmonotone nonrespondents, we employ the last value dependent mechanism.
in Equation (4) is unknown, for nonmonotone nonrespondents, we employ the last value dependent mechanism.
Under assumption (2), we have
![]() (5)
(5)
Using Equation (4), we are limited to do estimation by regressing the nonrespondents ![]() on the observed values
on the observed values ![]() based on the longitudinal survey data, therefore, we apply the equivalent Equation (5) which allows estimation using data from all subjects having observed
based on the longitudinal survey data, therefore, we apply the equivalent Equation (5) which allows estimation using data from all subjects having observed ![]() and observed
and observed![]() . Then, the imputation of the nonrespondents is done using
. Then, the imputation of the nonrespondents is done using ![]() in Equation (5) and under the last value dependent assumption, we are able to use auxiliary survey data in regression fitting. According to [11] , imputing nonresponses using (5) was done for monotone case and their approach is easy to apply if the conditional expectation say,
in Equation (5) and under the last value dependent assumption, we are able to use auxiliary survey data in regression fitting. According to [11] , imputing nonresponses using (5) was done for monotone case and their approach is easy to apply if the conditional expectation say, ![]() in (4) has a linear relationship with x. Adopting the concept of nonparametric method in [12] , here, the local linear estimator of
in (4) has a linear relationship with x. Adopting the concept of nonparametric method in [12] , here, the local linear estimator of ![]() is
is![]() . Let
. Let ![]() be the variable of interest for the i-th unit at time t where
be the variable of interest for the i-th unit at time t where ![]() and
and![]() . Associated with each
. Associated with each ![]() are the known
are the known![]() ,
, ![]() , of q auxiliary variables. To make the notations and writings simple, we relax the index t and write with a single subscript i, thus
, of q auxiliary variables. To make the notations and writings simple, we relax the index t and write with a single subscript i, thus ![]() is written as
is written as![]() .
.
The regression imputation model ![]() is given by the relation
is given by the relation
![]() (6)
(6)
such that![]() ’s are residuals which are assumed to be independently normally distri- buted with mean zero and variance
’s are residuals which are assumed to be independently normally distri- buted with mean zero and variance![]() .
.
It is clear that
![]() (7)
(7)
![]() (8)
(8)
where ![]() is an unknown regression function which is a smooth function of x.
is an unknown regression function which is a smooth function of x.
To obtain the estimator of ![]() at
at ![]() and its derivatives, we use the weighted local polynomial fitting by assuming that the regression function with
and its derivatives, we use the weighted local polynomial fitting by assuming that the regression function with ![]() derivatives at a point, say
derivatives at a point, say![]() , exists and are continuous.
, exists and are continuous.
We can rewrite the imputation model (6) as
![]() (9)
(9)
where approximation of ![]() about
about ![]() is done following the Taylor series expansion.
is done following the Taylor series expansion.
The kernel weight given as
![]() (10)
(10)
where h is the bandwidth and K is the kernel function which should be strictly positive and ![]() controls the weights,
controls the weights, ![]() is the point of focus and
is the point of focus and ![]() being the covariate with design matrix centered at past last value and j is the order of the local polynomial.
being the covariate with design matrix centered at past last value and j is the order of the local polynomial.
Let
![]() (11)
(11)
Accordingly, for![]() ,
,
![]() (12)
(12)
Equation (12) is the Nadaraya-Watson estimator.
With estimator the![]() , the conditional expectation given by
, the conditional expectation given by ![]() is used to impute the missing values, i.e.
is used to impute the missing values, i.e.
![]() (13)
(13)
where ![]() is the survey weight and
is the survey weight and
![]() (14)
(14)
Similarly for![]() ,
,
![]() (15)
(15)
Minimizing S with respect to ![]() and
and ![]() in Equation (15) and solving for
in Equation (15) and solving for ![]() and
and![]() , we get
, we get
![]() (16)
(16)
and
![]() (17)
(17)
Defining:
![]() and
and
![]() , Thus:
, Thus:
Using![]() , in Equation (17), we obtain
, in Equation (17), we obtain
![]() (18)
(18)
and with![]() , in Equation (17), it yields
, in Equation (17), it yields
![]() (19)
(19)
Similarly, using![]() , in Equation (16) gives
, in Equation (16) gives
![]() (20)
(20)
and with![]() , Equation (16) becomes
, Equation (16) becomes
![]() (21)
(21)
The local linear estimator for the regression function ![]() is now given by:
is now given by:
![]() (22)
(22)
Substituting for ![]() (from Equation (20)) and
(from Equation (20)) and ![]() (from Equation (18)) in Equation (22) gives,
(from Equation (18)) in Equation (22) gives,
![]() (23)
(23)
With estimator, ![]() , the conditional expectation given by
, the conditional expectation given by ![]() is used to impute the missing values, i.e.
is used to impute the missing values, i.e.
![]() (24)
(24)
where![]() , is the weight according to the survey design and
, is the weight according to the survey design and ![]() is as defined earlier.
is as defined earlier.
4.2. Estimation of the Finite Population Means Using the Imputed Data
In this study, we consider a finite population from which samples are drawn. Before estimation of the population parameters, imputation process is done. Suppose that the survey measurements are ![]() on the variables
on the variables ![]() respectively and a simple random sample without replacement,
respectively and a simple random sample without replacement, ![]() , of size n is selected from a finite population, P of size N. The sample consists of two parts:
, of size n is selected from a finite population, P of size N. The sample consists of two parts: ![]() and
and![]() , where
, where ![]() is the set of all respondents in the survey and
is the set of all respondents in the survey and ![]() is the set of all non-respondents. The missing observations of the sample unit
is the set of all non-respondents. The missing observations of the sample unit![]() , for
, for ![]() are considered. Impu- tation of the missing value
are considered. Impu- tation of the missing value ![]() for
for ![]() and
and ![]() is done and then a complete data set is produced which is then used in the estimation of finite population means.
is done and then a complete data set is produced which is then used in the estimation of finite population means.
Let ![]() be the finite population mean at time point, t for
be the finite population mean at time point, t for ![]()
The value to be imputed for the non respondent is denoted by ![]() such that the imputed data is given as
such that the imputed data is given as
![]() (25)
(25)
The mean of the finite population is given by
![]()
Now, using the imputed data, the estimator of the finite population total is the sample total of the imputed data denoted by ![]() and is given by
and is given by
![]() (26)
(26)
Thus, using the imputed data, the estimator of the finite population mean is the sample mean of the imputed data denoted by![]() , given by
, given by
![]() (27)
(27)
Assuming that for each ![]()
![]() (28)
(28)
for each![]() .
.
The imputed values are treated as if they were observed such that both observed and the imputed are used in the estimation of the population mean:
Sample mean for the imputed data becomes
![]() (29)
(29)
Note that the same weight due to sampling design is used in Equation (29) for all units in the sample.
![]() (30)
(30)
for![]() .
.
Since t is used as a constant variable, Equation (30) is re-written as
![]() (31)
(31)
As for [12] , the local constant estimation for the nonrespondents in Equation (31) is obtained as:
![]() (32)
(32)
and the local linear estimation for the nonrespondents, ![]() in Equation (31) is given by:
in Equation (31) is given by:
![]() (33)
(33)
Clearly, ![]() in Equation (31) is substituted by Equation (32) and Equation (33) for use of local constant estimator and local linear regression estimator respectively.
in Equation (31) is substituted by Equation (32) and Equation (33) for use of local constant estimator and local linear regression estimator respectively.
5. Asymptotic Properties of the Estimator
In the derivation of the asymptotic properties, we use the set of regularity conditions. According to [12] , the asymptotic theory development is provided by the concept of a sequence of finite populations ![]() with
with ![]() strata in
strata in![]() . It is assumed that there is a sequence of finite populations and the corresponding sequence of samples. The finite population P indexed by
. It is assumed that there is a sequence of finite populations and the corresponding sequence of samples. The finite population P indexed by ![]() is assumed to be a member of the sequence of the populations. The sample size denoted by
is assumed to be a member of the sequence of the populations. The sample size denoted by ![]() and the population size denoted by
and the population size denoted by ![]() approach infinity as
approach infinity as![]() . The uniform response and the size
. The uniform response and the size ![]() of the nonrespon-
of the nonrespon-
dents set ![]() satisfy the condition
satisfy the condition![]() . All limiting processes will be under-
. All limiting processes will be under-
stood as ![]() such that the regularity conditions are satisfied. For easy notation, the subscript
such that the regularity conditions are satisfied. For easy notation, the subscript ![]() will be ignored in the subsequent work.
will be ignored in the subsequent work.
Theorem 1. Assuming the regularity conditions (i)-(iv) and also the assumptions in section 2 hold. Then under the regression imputation model![]() , (6), the estimator,
, (6), the estimator, ![]() in Equation (31), is asymptotically unbiased and consistent for the population mean
in Equation (31), is asymptotically unbiased and consistent for the population mean![]() .
.
Proof. 1) Bias of![]() .
.
The general formula for the finite population total is given by:
![]() (34)
(34)
where ![]() and
and ![]() are the sampled and the non sampled sets respectively.
are the sampled and the non sampled sets respectively.
Equation (34) can be decomposed as
![]() (35)
(35)
For simplicity, denote![]() ,
, ![]() and
and ![]() by
by![]() ,
, ![]() and
and ![]() respec- tively throughout the remaining work.
respec- tively throughout the remaining work.
From Equation (31), the estimator for the finite population total is given by
![]() (36)
(36)
Now consider the difference,
![]()
![]() (37)
(37)
![]() (38)
(38)
Taking expectation on both sides of Equation (38), we have
![]() (39)
(39)
Clearly, ![]() since
since![]() .
.
Now,
![]() (40)
(40)
![]() (41)
(41)
Assuming ![]() such that
such that![]() , then
, then ![]() in Equation (41) and hence,
in Equation (41) and hence,
![]() (42)
(42)
But from Lemma 1 (see Appendix),
![]() (43)
(43)
where![]() .
.
Thus the bias of ![]() becomes
becomes
![]() (44)
(44)
2) Variance of![]() .
.
The variance of ![]() is given by the variance of the error term
is given by the variance of the error term![]() . That is,
. That is,
![]() (45)
(45)
![]() (46)
(46)
![]() (47)
(47)
![]() (48)
(48)
Thus,
![]() (49)
(49)
for sufficiently large n such that ![]() and
and![]() ; where
; where
![]() .
.
3) Mean square error (MSE) of![]() .
.
Finally, we have
![]() (50)
(50)
![]() (51)
(51)
which is the asymptotic expression of the MSE for![]() .
. ![]() as
as ![]() and
and![]() , and thus
, and thus ![]() is consistent.
is consistent.
Consequently, ![]() is asymptotically unbiased and consistent.
is asymptotically unbiased and consistent.
6. Simulation Study
6.1. Description of Longitudinal Data
In this section, a study of the finite population mean estimators based on four measures of performance (percentage relative bias (%RB), MSE and bootstrap standard deviation (SD bootstrap)) is carried out.
Simulations and computations of the finite population mean estimators were done using R (R version 3.2.3 (2015-12-10)) based on 1000 runs. For the the local linear and local constant estimators, the Gaussian kernel with a fixed bandwidth of ![]() was used. To fit the nonparametric regression, the loess function in R was used.
was used. To fit the nonparametric regression, the loess function in R was used.
For comparison purposes, we used complete data as our main reference in the evaluation of the performance of the estimators (Proposed local linear estimator, local constant estimator and the simple linear regression estimator).
In this simulation study, a sample of size ![]() was considered. The longitudinal data for each of the sampled units is of size
was considered. The longitudinal data for each of the sampled units is of size ![]() that is,
that is,![]() . This will yield 23 different patterns of the longitudinal data with each of respondent and non- respondent values being denoted by 1 and 0 respectively at different time points.
. This will yield 23 different patterns of the longitudinal data with each of respondent and non- respondent values being denoted by 1 and 0 respectively at different time points.
Longitudinal data was generated according to two models:
1) In model 1, simulation of ![]() is done from a multivariate normal distribution with the means for the 4 time points as 1.33, 1.94, 2.73, 3.67 respectively and the covariance matrix following the
is done from a multivariate normal distribution with the means for the 4 time points as 1.33, 1.94, 2.73, 3.67 respectively and the covariance matrix following the ![]() model with standard error 1 and correlation coefficient 0.9.
model with standard error 1 and correlation coefficient 0.9.
2) In model 2, simulation of ![]() is done from a multivariate normal distribution with the means for the 4 time points as 1.33, 1.94, 2.73, 3.67 respectively and the covariance matrix following the
is done from a multivariate normal distribution with the means for the 4 time points as 1.33, 1.94, 2.73, 3.67 respectively and the covariance matrix following the ![]() model with standard error 1 and correlation coefficient 0.9.
model with standard error 1 and correlation coefficient 0.9.
In order to obtain the nonmonotone pattern in the simulated data, we used the predetermined unconditional probabilities of [13] shown in Table 1.
6.2. Bootstrap Variance Estimation
The following steps were used to obtain the bootstrap variance.
1) We constructed a pseudo population by replicating the sample of size 1500 times through 1000 simulation runs.
![]()
Table 1. Probabilities of nonresponse patterns for![]() .
.
2) A simple random sample of size 200 was drawn with replacement from the pseudo population.
3.) We applied the simple linear regression, local constant and local linear regression imputation models to impute the missing![]() ’s of the sample.
’s of the sample.
4) Repeating the steps 2 and 3 for a large number of times (![]() ) to obtain
) to obtain ![]() where
where ![]() is the analog of
is the analog of![]() , for the b-th bootstrap sample.
, for the b-th bootstrap sample.
5) Obtain the bootstrap variance of ![]() by the formula
by the formula
![]() where
where ![]() is the mean bootstrap analog of
is the mean bootstrap analog of![]() , given by
, given by![]() .
.
6.3. Results and Discussion
The results of this simulation study are summarized in Table 2 and Table 3.
In terms of the percentage relative bias (%RB), at time point![]() , it can be seen that the local linear estimator has the least value followed by the Nadaraya-Watson estimator and then the simple linear regression estimator, which was the largest value of %RB.
, it can be seen that the local linear estimator has the least value followed by the Nadaraya-Watson estimator and then the simple linear regression estimator, which was the largest value of %RB.
At time point![]() , observe that the the simple linear regression estimator has the least %RB value compared to that of the local linear estimator and the Nadaraya- Watson estimator performed worst with the largest %RB. The %RB values of the local linear estimator and the simple linear regression estimator are very much closer to zero than those for the other estimators.
, observe that the the simple linear regression estimator has the least %RB value compared to that of the local linear estimator and the Nadaraya- Watson estimator performed worst with the largest %RB. The %RB values of the local linear estimator and the simple linear regression estimator are very much closer to zero than those for the other estimators.
At time point![]() , observe that the local linear estimator has the least %RB value followed by the simple linear regression estimator and the Nadaraya-Watson estimator performed worst. Through comparisons based on %RB with reference to the complete data, the local linear estimator has its %RB values approaching zero.
, observe that the local linear estimator has the least %RB value followed by the simple linear regression estimator and the Nadaraya-Watson estimator performed worst. Through comparisons based on %RB with reference to the complete data, the local linear estimator has its %RB values approaching zero.
In terms of MSE, at time point![]() , Nadaraya-Watson estimator has the least values followed by the local linear estimator and lastly the simple linear regression estimator which has the largest values. At time point
, Nadaraya-Watson estimator has the least values followed by the local linear estimator and lastly the simple linear regression estimator which has the largest values. At time point![]() , the local linear estimator has the least values of MSE followed by the simple linear regression estimator and lastly
, the local linear estimator has the least values of MSE followed by the simple linear regression estimator and lastly
![]()
Table 2. Simulated results for mean estimation (normal case).
![]()
Table 3. Simulated results for mean estimation (log-normal case).
the Nadaraya-Watson estimator which has the largest MSE value. At time points![]() , Nadaraya-Watson estimator has the least values of MSE followed by the simple linear regression estimator and lastly the local linear estimator which has the largest MSE value.
, Nadaraya-Watson estimator has the least values of MSE followed by the simple linear regression estimator and lastly the local linear estimator which has the largest MSE value.
In terms of the bootstrap standard deviation, it can be seen that the local linear estimator performs the best at all the three time points![]() ,
, ![]() , and
, and ![]() in which its values are even lower than those of the complete data implying that the results got with the local linear estimator are the best. The simple linear regression and Nadaraya-Watson estimators are competing interchangeably in terms of performance for the bootstrap samples.
in which its values are even lower than those of the complete data implying that the results got with the local linear estimator are the best. The simple linear regression and Nadaraya-Watson estimators are competing interchangeably in terms of performance for the bootstrap samples.
In terms of the percentage relative bias (%RB), at time points ![]() and
and![]() , observe that the simple linear regression estimator has the least %RB values followed by the local linear estimator and the Nadaraya-Watson estimator has the biggest %RB values. Based on these aforementioned results, it is viable to choose the best estimator as the local linear estimator which handles both linear and nonlinear models. At time points
, observe that the simple linear regression estimator has the least %RB values followed by the local linear estimator and the Nadaraya-Watson estimator has the biggest %RB values. Based on these aforementioned results, it is viable to choose the best estimator as the local linear estimator which handles both linear and nonlinear models. At time points![]() , observe that the local linear estimator has the least %RB value followed by simple linear regression estimator and lastly the Nadaraya-Watson. This implies that, for
, observe that the local linear estimator has the least %RB value followed by simple linear regression estimator and lastly the Nadaraya-Watson. This implies that, for![]() , the local linear estimator has the smallest bias close to zero as for the complete data, hence the best estimator compared to others.
, the local linear estimator has the smallest bias close to zero as for the complete data, hence the best estimator compared to others.
In terms of the MSE, at time points ![]() and
and![]() , Nadaraya-Watson estimator has the least values of MSE, followed by the simple linear regression estimator and lastly the local linear estimator which has the largest values of MSE. At time point
, Nadaraya-Watson estimator has the least values of MSE, followed by the simple linear regression estimator and lastly the local linear estimator which has the largest values of MSE. At time point![]() , the the local linear estimator has the least values implying that it performed well at time point
, the the local linear estimator has the least values implying that it performed well at time point![]() .
.
In terms of the bootstrap standard deviation, observe from Table 3 that the local linear estimator performs the best at all the three time points since it has the least bootstrap standard deviations and these values are even smaller than those of the complete data in order of increasing time.
From Table 3 of results, it is can be seen that the bootstrap standard deviations of the local linear estimator are more close to those of the Nadaraya-Watson estimator than the simple linear regression estimator.
7. Conclusion
Generally, nonrespondents in any survey data has a significant impact on the bias and the variance of the estimators and therefore, before using such data in statistical inference, imputation with an appropriate technique ought to be done. In this study, the main objective was to obtain an imputation method based on local linear regression for nonmonotone nonrespondents in longitudinal surveys and determine its asymptotic properties. Comparing the parametric and nonparametric methods, nonparametric methods performed better than the parametric methods. This was evident from the MSE and %RB values in both the normal and log-normal data. Among the nonpara- metric methods, the local linear estimator was the best estimator as it behaved better than the Nadaraya-Watson estimator in terms of %RB. In terms of the bootstrap standard deviation, the local linear estimator performs the best at all the three time points since it has the least bootstrap standard deviations for the two data sets. Generally, the local linear estimator performs relatively well and in particular in the normal data. We conclude that use of the nonparametric estimators seem plausible in both theoretical and practical scenarios.
Acknowledgements
We wish to thank the African Union Commission for fully funding this research.
Appendix
LEMMA 1. The bias of ![]() is given by
is given by
![]() (52)
(52)
Under the regularity conditions in section 3, ![]() as
as ![]() and
and
![]() .
.
PROOF OF LEMMA 1.
Proof. From Equation (23),
![]() (53)
(53)
where![]() ,
,
![]() , where
, where![]() .
.
The expectation of ![]() is given by
is given by
![]() (54)
(54)
![]() (55)
(55)
The bias of ![]() is therefore given by
is therefore given by
![]() (56)
(56)
For fixed design points of![]() ’s on the interval
’s on the interval![]() , the expression
, the expression
![]() almost everywhere, see [14] .
almost everywhere, see [14] .
Now,
1) ![]()
2) ![]()
3) ![]()
4) ![]()
Equation (56) becomes
![]() (57)
(57)
Letting ![]()
Hence, the bias of ![]() can be re-written as
can be re-written as
![]() (58)
(58)
and hence the result.
LEMMA 2. The asymptotic expression of the variance of ![]() is given by
is given by
![]() (59)
(59)
as ![]() and
and![]() ; where
; where![]() .
.
PROOF OF LEMMA 2.
Proof. Using Equation (23),
![]() (60)
(60)
since![]() .
.
It follows that
![]() (61)
(61)
where
![]() (62)
(62)
and
![]()
as ![]()
Thus,
![]() (63)
(63)
The asymptotic expression of the variance of ![]() becomes
becomes
![]() (64)
(64)
where![]() . Hence the result.
. Hence the result.
MSE of ![]()
From LEMMA 1 and 2, the MSE of ![]() becomes
becomes
![]() (65)
(65)
![]()
Submit or recommend next manuscript to SCIRP and we will provide best service for you:
Accepting pre-submission inquiries through Email, Facebook, LinkedIn, Twitter, etc.
A wide selection of journals (inclusive of 9 subjects, more than 200 journals)
Providing 24-hour high-quality service
User-friendly online submission system
Fair and swift peer-review system
Efficient typesetting and proofreading procedure
Display of the result of downloads and visits, as well as the number of cited articles
Maximum dissemination of your research work
Submit your manuscript at: http://papersubmission.scirp.org/
Or contact ojs@scirp.org