Estimations of Weibull-Geometric Distribution under Progressive Type II Censoring Samples ()
Received 23 October 2015; accepted 15 December 2015; published 18 December 2015

1. Introduction
The Weibull distribution is one of the most popular widely usable models of failure time in life testing and reliability theory. The Weibull distribution has been shown to be useful for modeling and analysis of life time data in medical, biological and engineering sciences. Some applications of the Weibull distribution in forestry are given in Green et al. [1] . Several distributions have been proposed in the literature to extend the Weibull distribution. Adamidis and Loukas [2] introduce the two-parameter exponential-geometric (EG) distribution with decreasing failure rate. Marshall and Olkin [3] present a method for adding a parameter to a family of distributions with application to the exponential and Weibull families. Adamidis et al. [4] introduce the extended exponential-geometric (EEG) distribution which generalizes the EG distribution and discuss variety of its statistical properties along with its reliability features. The hazard function of the EEG distribution can be monotone decreasing, increasing or constant. Kus [5] proposes the exponential-Poisson distribution (following the same idea of the EG distribution) with decreasing failure rate and discusses its various properties. Souza et al [6] introduce the Weibull-geometric (WG) distribution that contains the EEG, EG and Weibull distributions as special sub- models and discuss some of its properties. For more details about Weibull-geometric (WG) distribution and its properties, see Barreto-Souza [7] and Hamedani and Ahsanullah [8] .
Let X follows a WG distribution, then the probability density function (pdf) 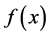 and distribution function (cdf)
and distribution function (cdf) 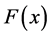 of WG distribution are given respectively by
of WG distribution are given respectively by
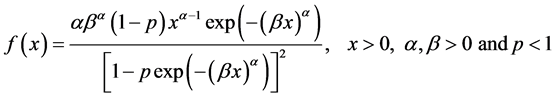 (1)
(1)
and
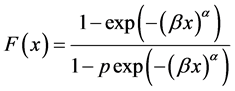 (2)
(2)
Some special sub-models of the WG distribution (1) are obtained as follows. If , we have the Weibull distribution. When
, we have the Weibull distribution. When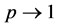 , the WG distribution tends to a distribution degenerate in zero. Hence, the parameter p can be interpreted as a concentration parameter. The EG distribution corresponds to
, the WG distribution tends to a distribution degenerate in zero. Hence, the parameter p can be interpreted as a concentration parameter. The EG distribution corresponds to 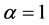 and
and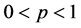 , whereas the EEG distribution is obtained by taking
, whereas the EEG distribution is obtained by taking  for any
for any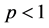 . Clearly, the EEG distribution extends the EG distribution. WG density functions are displayed. For
. Clearly, the EEG distribution extends the EG distribution. WG density functions are displayed. For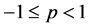 , the WG density is unimodal if
, the WG density is unimodal if 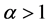 and strictly decreasing if
and strictly decreasing if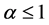 . The mode
. The mode 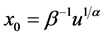 is obtained by solving the nonlinear equation
is obtained by solving the nonlinear equation
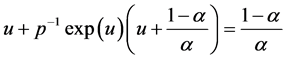 (3)
(3)
For![]() , the WG density can be unimodal. For example, the EEG distribution (
, the WG density can be unimodal. For example, the EEG distribution (![]() ) is unimodalif
) is unimodalif![]() .
.
The survival and hazard functions of X are
![]() (4)
(4)
and
![]() (5)
(5)
Suppose that n independent items are put on a life test with continuous identically distributed failure times![]() . Let further that a censoring scheme
. Let further that a censoring scheme ![]() is previously fixed such that immediately following the first failure
is previously fixed such that immediately following the first failure![]() ,
, ![]() surviving items are removed at random from the test, after the next failure
surviving items are removed at random from the test, after the next failure![]() ,
, ![]() surviving items are removed at random from the test; this process continues until, at the time of the m-th observed failure
surviving items are removed at random from the test; this process continues until, at the time of the m-th observed failure![]() , the remaining
, the remaining ![]() items are removed from the test. The m is ordered observed failure times denoted by
items are removed from the test. The m is ordered observed failure times denoted by![]() , are called progressive Type II right censored order statistics of size m from a sample of size n with progressive censoring scheme
, are called progressive Type II right censored order statistics of size m from a sample of size n with progressive censoring scheme![]() . If the failure times of the n items, originally on the test are from a continuous population with pdf
. If the failure times of the n items, originally on the test are from a continuous population with pdf ![]() and cdf
and cdf![]() , the joint probability density function for
, the joint probability density function for ![]() is given (see Balakrishnan and Sandhu [9] ) by
is given (see Balakrishnan and Sandhu [9] ) by
![]() (6)
(6)
where
![]() (7)
(7)
Progressive Type II censored sampling is an important scheme of obtaining data in lifetime studies. For more details on the progressive censored samples see Aggarwala and Balakrishnan [10] .
2. Markov Chain Monte Carlo Techniques
MCMC methodology provides a useful tool for realistic statistical modeling (Gilks et al. [11] ; Gamerman, [12] ), and has become very popular for Bayesian computation in complex statistical models. Bayesian analysis requires integration over possibly high-dimensional probability distributions to make inferences about model parameters or to make predictions. MCMC is essentially Monte Carlo integration using Markov chains. The integration draws samples from the required distribution, and then forms sample averages to approximate expectations (see Geman and Geman, [13] ; Metropolis et al., [14] ; Hastings, [15] ).
Gibbs Sampler
The Gibbs sampling algorithm is one of the simplest Markov chain Monte Carlo algorithms. It was introduced by Geman [13] . The paper by Gelfand and Smith [16] helped to demonstrate the value of the Gibbs algorithm for a range of problems in Bayesian analysis. Gibbs sampling is a MCMC scheme where the transition kernel is formed by the full conditional distributions.
The Gibbs sampler is applicable for certain classes of problems, based on two main criterions. Given a target distribution![]() , where
, where ![]() The first criterion is 1) that it is necessary that we have an analytic (mathematical) expression for the conditional distribution of each variable in the joint distribution given all other variables in the joint. Formally, if the target distribution
The first criterion is 1) that it is necessary that we have an analytic (mathematical) expression for the conditional distribution of each variable in the joint distribution given all other variables in the joint. Formally, if the target distribution ![]() is d-dimensional, we must have d in-
is d-dimensional, we must have d in-
dividual expressions for ![]()
Each of these expressions defines the probability of the i-th dimension given that we have values for all other (![]() ) dimensions. Having the conditional distribution for each variable means that we don’t need a proposal distribution or an accept/reject criterion, like in the Metropolis-Hastings algorithm. Therefore, we can simply sample from each conditional while keeping all other variables held fixed. So that we must be able to sample from each conditional distribution if we want an implementable algorithm.
) dimensions. Having the conditional distribution for each variable means that we don’t need a proposal distribution or an accept/reject criterion, like in the Metropolis-Hastings algorithm. Therefore, we can simply sample from each conditional while keeping all other variables held fixed. So that we must be able to sample from each conditional distribution if we want an implementable algorithm.
To define the Gibbs sampling algorithm, let the set of full conditional distributions be ![]() .
.
Now one cycle of the Gibbs sampling algorithm is completed by simulating ![]() from these distributions, recursively refreshing the conditioning variables.
from these distributions, recursively refreshing the conditioning variables.
Algorithm:
1) Choose an arbitrary starting point ![]() for which
for which![]() ;
;
2) Obtain ![]() from conditional distribution
from conditional distribution![]() ;
;
3) Obtain ![]() from conditional distribution
from conditional distribution![]() ;
;
4) Obtain ![]() from conditional distribution
from conditional distribution![]() ;
;
5) Repeat of steps 2 - 4 thousands (or millions) of times for the number of samples M.
The results of the first M or so iterations should be ignored, as this is a “burn-in” period for the algorithm to set itself up.
In this paper, we obtain and compare several techniques of estimation based on progressive Type II censoring for the three unknown parameter of WG distribution. In Bayesian technique, we use the idea of Markov chain Monte Carlo (MCMC) techniques to generate from the posterior distributions. Finally, we will give an example to illustrate our proposed method.
3. Maximum Likelihood Estimation
Let![]() ,
, ![]() be the progressive first-failure censored order statistics from a Weibull-geometric
be the progressive first-failure censored order statistics from a Weibull-geometric
distribution, with censored scheme R, where n independent items are put on a life test with continuous identically distributed failure times![]() . Suppose further that a censoring scheme
. Suppose further that a censoring scheme ![]() is previously fixed. From (1), (2) and (3), the likelihood function is given by
is previously fixed. From (1), (2) and (3), the likelihood function is given by
![]() (8)
(8)
where C is given by (7). The logarithm of the likelihood function l may then be written as
![]() (9)
(9)
Calculating the first partial derivatives of (9) with respect to ![]() and p equating each to zero, we get the likelihood equations as in the following:
and p equating each to zero, we get the likelihood equations as in the following:
![]() (10)
(10)
![]() (11)
(11)
and
![]() (12)
(12)
Since (10-12) cannot be solved analytically for ![]() and
and![]() , some numerical methods such Newton’s method must be employed.
, some numerical methods such Newton’s method must be employed.
Approximate confidence intervals for ![]() and p can be found by to be bivariately normal distributed with mean
and p can be found by to be bivariately normal distributed with mean ![]() and covariance matrix
and covariance matrix![]() . Thus, the
. Thus, the ![]() approximate confidence intervals for
approximate confidence intervals for ![]() and p are
and p are
![]() (13)
(13)
respectively, where![]() ,
, ![]() and
and ![]() are the elements on the main diagonal of the covariance matrix
are the elements on the main diagonal of the covariance matrix ![]() and
and ![]() is the percentile of the standard normal distribution with right-tail probability
is the percentile of the standard normal distribution with right-tail probability![]() .
.
4. Bootstrap Confidence Intervals
The bootstrap is a resampling method for statistical inference. It is commonly used to estimate confidence intervals, but it can also be used to estimate bias and variance of an estimator or calibrate hypothesis tests. In this section, we use the parametric bootstrap percentile method suggested by Efron [17] [18] to construct confidence intervals for the parameters. The following steps are followed to obtain progressive first failure censoring bootstrap sample from Weibull-geometric distribution with parameters ![]() and
and ![]() based on simulated progressively first-failure censored data set.
based on simulated progressively first-failure censored data set.
Algorithm:
・ From an original data set![]() , compute the ML estimates of parameters
, compute the ML estimates of parameters ![]() and
and ![]() from Equation (9) and Equation (10);
from Equation (9) and Equation (10);
・ Use ![]() and
and ![]() to generate a bootstrap sample
to generate a bootstrap sample ![]() with the same values of
with the same values of ![]() using the algorithm of Balakrishnan and Sandhu [2] ;
using the algorithm of Balakrishnan and Sandhu [2] ;
・ As in step 1 based on ![]() compute the bootstrap sample estimates of
compute the bootstrap sample estimates of ![]() and
and ![]() say
say ![]() and
and![]() ;
;
・ Repeat steps 2 - 3 N times representing N bootstrap MLE’s of ![]() and
and ![]() based on N different bootstrap samples;
based on N different bootstrap samples;
・ Arrange all ![]() and
and ![]() in an ascending order to obtain bootstrap sample
in an ascending order to obtain bootstrap sample ![]()
![]() where (
where (![]()
![]()
![]() );
);
・ Let ![]() be cumulative distribution function of
be cumulative distribution function of![]() ;
;
・ Define ![]() for given z. The approximate bootstrap 100
for given z. The approximate bootstrap 100 ![]() confidence interval of
confidence interval of ![]() given by
given by
![]() (14)
(14)
5. Bayesian Estimation Using MCMC
In this section, we consider the Bayes estimation of the unknown parameter(s). In many practical situations, the information about the parameters are available in an independent manner. Thus, here it is assumed that the parameters are independent a priori and assumed that ![]() and
and ![]() have the following gamma prior distributions
have the following gamma prior distributions
![]() (15)
(15)
![]() (16)
(16)
Here all the hyper parameters a, b, c, d are assumed to be known and non-negative and let the NIP for parameter p which represented by the limiting form of the appropriate natural conjugate prior, the NIP for the acceleration factor p is given by
![]() (17)
(17)
Therefore, the joint prior of the three parameters can be expressed by
![]() (18)
(18)
Therefore, the Bayes estimate of any function of ![]() and p say
and p say![]() , under squared error loss function (SEL) is
, under squared error loss function (SEL) is
![]() (19)
(19)
The MCMC method to generate samples from the posterior distributions and then compute the Bayes estimator of ![]() under the SEL function.
under the SEL function.
A wide variety of MCMC schemes are available, and it can be difficult to choose among them. An important subclass of MCMC methods are Gibbs sampling and more general Metropolis-Hastings (M-H) algorithm. The advantage of using the MCMC method over the MLE method is that we can always obtain a reasonable interval estimate of the parameters by constructing the probability intervals based on the empirical posterior distribution. This is often unavailable in maximum likelihood estimation. Indeed, the MCMC samples may be used to completely summarize the posterior uncertainty about the parameters ![]() and p, through a kernel estimate of the posterior distribution. This is also true of any function of the parameters.
and p, through a kernel estimate of the posterior distribution. This is also true of any function of the parameters.
When practically possible, we give prior and posterior distributions in terms of known densities, such as the Gaussian, binomial, beta, gamma and others. The joint posterior density function of ![]() and p can be obtained by multiply the likelihood function (multivariate normal) with the prior which can be written as:
and p can be obtained by multiply the likelihood function (multivariate normal) with the prior which can be written as:
![]() (20)
(20)
We obtain the Bayes MCMC point estimate of ![]() (
(![]()
![]() and
and![]() ) as
) as
![]() (21)
(21)
where M is the burn-in period (that is, a number of iterations before the stationary distribution is achieved), and posterior variance of ![]() becomes
becomes
![]() (22)
(22)
6. Illustrative Example
To illustrative the estimation techniques developed in this article, for given hybrid parameters ![]() generate random sample of size 10, from gamma distribution the mean of the random sample
generate random sample of size 10, from gamma distribution the mean of the random sample![]() , is computed and considered as the actual population value of
, is computed and considered as the actual population value of ![]() That is, the prior parameters are selected to satisfy
That is, the prior parameters are selected to satisfy![]() , that is approximately the mean of gamma distribution (21). Also for given values
, that is approximately the mean of gamma distribution (21). Also for given values![]() , generate according the last
, generate according the last![]() , from gamma distribution. The prior parameters are selected to satisfy
, from gamma distribution. The prior parameters are selected to satisfy![]() , that is approximately the mean of gamma distribution. We have considered a progressive
, that is approximately the mean of gamma distribution. We have considered a progressive
Type II sample is generated from WG distribution with parameters (![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() and
and![]() ) using the algorithm of Balakrishnan and Sandhu [9] , the data given in by: 0.0212, 0.0463, 0.0568, 0.0686, 0.0764, 0.0832, 0.0933, 0.1031, 0.1496, 0.1485, 0.1511, 0.1536, 0.1603, 0.1685, 0.1985, 0.2097, 0.2176, 0.2643, 0.2696, 0.2809, 0.3156, 0.3744, 0.3941, 0.4196, 0.5236.
) using the algorithm of Balakrishnan and Sandhu [9] , the data given in by: 0.0212, 0.0463, 0.0568, 0.0686, 0.0764, 0.0832, 0.0933, 0.1031, 0.1496, 0.1485, 0.1511, 0.1536, 0.1603, 0.1685, 0.1985, 0.2097, 0.2176, 0.2643, 0.2696, 0.2809, 0.3156, 0.3744, 0.3941, 0.4196, 0.5236.
![]()
Table 1. Different estimates of parameters of WG distribution.
![]()
Table 2. MLE, percentile bootstrap CIs and Bootstrap-t CIs based on 500 replications.
![]()
Figure 1. Simulation number of ![]() generated by MCMC method and its histogram.
generated by MCMC method and its histogram.
![]()
Figure 2. Simulation number of ![]() generated by MCMC methodand its histogram.
generated by MCMC methodand its histogram.
![]()
Figure 3. Simulation number of p generated by MCMC methodand its histogram.
Under these data, we compute the approximate MLEs, bootstrap and Bayes estimates of ![]() and p using MCMC method results are given in Table 1 and Table 2. Note that Table 2 gives the 95%, approximate MLE confidence intervals, two bootstrap confidence intervals and approximate credible intervals based on the MCMC samples. Figures 1-3 show simulation number of WG parameters generated by MCMC method and the corresponding histogram.
and p using MCMC method results are given in Table 1 and Table 2. Note that Table 2 gives the 95%, approximate MLE confidence intervals, two bootstrap confidence intervals and approximate credible intervals based on the MCMC samples. Figures 1-3 show simulation number of WG parameters generated by MCMC method and the corresponding histogram.