Bayesian Prediction of Future Generalized Order Statistics from a Class of Finite Mixture Distributions ()
1. Introduction
Let the random variable (rv) T follows a class including some known lifetime models; its cumulative distribution function (CDF) is given by
 (1)
(1)
and its probability density function (PDF) is given by
 (2)
(2)
where  is the derivative of
is the derivative of  with respect to t and
with respect to t and  is a nonnegative continuous function of t and α may be a vector of parameters, such that
is a nonnegative continuous function of t and α may be a vector of parameters, such that
 as
as  and
and  as
as .
.
The reliability function (RF) and hazard rate function (HRF) are given, respectively, by
 (3)
(3)
 (4)
(4)
where 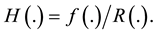
The general problem of statistical prediction may be described as that of inferring the value of unknown observable that belongs to a future sample from current available information, known as the informative sample. As in estimation, a predictor can be either a point or an interval predictor. The problem of prediction can be solved fully within Bayesian framework [1] .
Prediction has been applied in medicine, engineering, business and other areas as well. For details on the history of statistical prediction, analysis, application and examples see for example [1] [2] .
Bayesian prediction of future order statistics and records from different populations has been dealt with by many authors. Among others, [3] predicted observables from a general class of distributions. [4] obtained Bayesian prediction bounds under a mixture of two exponential components model based on type I censoring. [5] obtained Bayesian predictive survival function of the median of a set of future observations. Bayesian prediction bounds based on type I censoring from a finite mixture of Lomax components were obtained by [6] . [7] obtained Bayesian predictive density of order statistics based on finite mixture models. [8] obtained Bayesian interval prediction of future records. Based on type I censored samples, Bayesian prediction bounds for the sth future observable from a finite mixture of two component Gompertz life time model were obtained by [9] . [10] considered Bayes inference under a finite mixture of two compound Gompertz components model. Bayesian prediction of future median has been studied by, among others, they were [5] [11] [12] .
Recently, [13] introduced the generalized order statistics (GOS’S). Ordinary order statistics, ordinary record values and sequential order statistics were, among others, special cases of GOS’S. For various distributional properties of GOS’S, see [13] . The GOS’S have been considered extensively by many authors, among others, they were [14] -[33] .
Mixtures of distributions arise frequently in life testing, reliability, biological and physical sciences. Some of the most important references that discuss different types of mixtures of distributions are a monograph by [34] -[36] .
The PDF, CDF, RF and HRF of a finite mixture of two components of the class under study are given, respectively, by
 (5)
(5)
 (6)
(6)
 (7)
(7)
 (8)
(8)
where, for![]() , the mixing proportions
, the mixing proportions ![]() are such that
are such that ![]() and
and ![]() are given from (1), (2), (3) after using
are given from (1), (2), (3) after using ![]() and
and ![]() instead of
instead of ![]() and
and![]() .
.
The property of identifiability is an important consideration on estimating the parameters in a mixture of distributions. Also, testing hypothesis, classification of random variables, can be meaning fully discussed only if the class of all finite mixtures is identifiable. Idenifiability of mixtures has been discussed by several authors, including [37] -[39] .
This article is concerned with the problem of obtaining Bayesian prediction intervals (BPI) for the future GOS’S from a mixture of two general components based on doubly type II censored sample. One- and two-sam- ple prediction cases are treated in Sections 2 and 3, respectively. Bayesian prediction intervals for the median of future sample of GOS’S having odd and even sizes are obtained in Sections 4. A mixture of two Gompertz components is given as an application in Section 5. Finally, numerical computations are given in Section 6.
2. One Sample Prediction
Let ![]() be the
be the ![]() GOS’S drawn from a mixture of two com-
GOS’S drawn from a mixture of two com-
ponents of the class (2). Based on this doubly censored sample, the likelihood function can be written (see [27] ) as
![]() (9)
(9)
where![]() ,
, ![]() ,
, ![]() is the parameter space, and
is the parameter space, and
![]()
For definition and various distributional properties of GOS’S, see [13] .
By substituting Equations (1) and (5) in Equation (9), we get
for![]() ,
,
![]() (10)
(10)
And for![]() ,
,
![]() (11)
(11)
We shall use the conjugate prior density, that was suggested by [3] , in the following form
![]() (12)
(12)
where ![]() is the hyper parameter space.
is the hyper parameter space.
Then the posterior PDF of![]() ,
, ![]() , is given by
, is given by
![]() (13)
(13)
Substituting from Equations (10) and (12) in Equation (13), for![]() , the posterior PDF
, the posterior PDF ![]() takes the form
takes the form
![]() (14)
(14)
where ![]()
For![]() , using Equations (11) and (12) in Equation (13), the posterior PDF can be written as
, using Equations (11) and (12) in Equation (13), the posterior PDF can be written as
![]() (15)
(15)
Now, suppose that the first ![]() GOS’S
GOS’S ![]() have been formed and
have been formed and
we wish to predict the future GOS’S ![]() Let
Let![]() ,
, ![]() , the
, the
conditional PDF of the ![]() future GOS given the past observations
future GOS given the past observations![]() , can be written (see [27] ) as
, can be written (see [27] ) as
![]() (16)
(16)
where ![]()
When![]() , substituting from Equations (1) and (5) in Equation (16), the conditional PDF takes the form
, substituting from Equations (1) and (5) in Equation (16), the conditional PDF takes the form
![]() (17)
(17)
In the case when![]() ; the conditional PDF takes the form
; the conditional PDF takes the form
![]() (18)
(18)
The predictive PDF of ![]() given the past observations
given the past observations ![]() is obtained from Equations (13), (17) and (18) and written as
is obtained from Equations (13), (17) and (18) and written as
![]() (19)
(19)
where for![]() ,
,
![]() (20)
(20)
where
![]()
Also, for![]() ,
,
![]() (21)
(21)
It then follows that the predictive survival function is given, for the ![]() future GOS, by
future GOS, by
![]() (22)
(22)
A ![]() BPI for
BPI for ![]() is then given by
is then given by
![]()
where ![]() and
and ![]() are obtained, respectively, by solving the following two equations
are obtained, respectively, by solving the following two equations
![]() , (23)
, (23)
![]() . (24)
. (24)
3. Two Sample Prediction
Suppose that![]() .
.
Be a doubly type II censored random sample drawn from a population whose CDF, ![]() and PDF,
and PDF,![]() and let
and let![]() .
.
Be a second independent generalized ordered random sample (of size N) of future observations from the same distribution. Based on such a doubly type II censored sample, we wish to predict the future GOS ![]() in the future sample of size N.
in the future sample of size N.
It was shown by [32] that the PDF of GOS ![]() is in the form
is in the form
![]() (25)
(25)
where ![]() and
and ![]()
Substituting from Equations (1) and (5) in (25), we have
![]() (26)
(26)
The predictive PDF of ![]() given the past observation t is obtained from Equations (14), (15) and (26), and written as
given the past observation t is obtained from Equations (14), (15) and (26), and written as
![]() (27)
(27)
where for ![]()
![]() , (28)
, (28)
where
![]()
Also for ![]()
![]() . (29)
. (29)
Bayesian prediction bounds for![]() ,
, ![]() are obtained by evaluating
are obtained by evaluating
![]() (30)
(30)
A ![]() BPI for
BPI for ![]() is then given by
is then given by
![]()
where ![]() and
and ![]() are obtained, respectively, by solving the following two equations
are obtained, respectively, by solving the following two equations
![]() , (31)
, (31)
![]() . (32)
. (32)
4. Bayesian Prediction for the Future Median
The median of N observations, denoted by![]() , is defined by
, is defined by
![]() ,
,
where ![]() is a positive integer,
is a positive integer,![]() .
.
4.1. The Case of Odd Future Sample Size
The PDF of future median ![]() takes the form (26) with
takes the form (26) with ![]() and
and![]() .
.
Substituting ![]() in Equation (27), we obtain the predictive PDF
in Equation (27), we obtain the predictive PDF ![]() of the median of
of the median of ![]()
observations.
A ![]() BPI for
BPI for ![]() is then given by
is then given by
![]()
where ![]() and
and ![]() are obtained, respectively, by solving the following two equations
are obtained, respectively, by solving the following two equations
![]() , (33)
, (33)
![]() , (34)
, (34)
where, for ![]() is predictive survival function, given by Equation (30) with
is predictive survival function, given by Equation (30) with ![]() and
and![]() .
.
4.2. The Case of Even Future Sample Size
The joint density function of two consecutive GOS ![]() and
and ![]() is given by
is given by
![]() , (35)
, (35)
where
![]()
And
![]() .
.
Expanding ![]() binomially and applying the transformation
binomially and applying the transformation ![]() and
and
![]() , the Jacobian of transformation is 2, we obtain
, the Jacobian of transformation is 2, we obtain
![]() . (36)
. (36)
By substituting Equations (2), (4) and (5) in Equation (36) and integrating out z, yields the density function of![]() , in the case of
, in the case of![]() , as
, as
![]() (37)
(37)
In the case![]() , we have
, we have
![]() (38)
(38)
The predictive density function of the future median of ![]() observations is given by
observations is given by
![]() (39)
(39)
where ![]() and
and ![]() are given by Equations (13) and (37), (38), respectively. It then follows
are given by Equations (13) and (37), (38), respectively. It then follows
that the predictive survival function is given, for![]() , by
, by
![]() (40)
(40)
The lower and upper bound of ![]() BPI for
BPI for ![]() can be obtained by solving Equations (33) and (34), numerically.
can be obtained by solving Equations (33) and (34), numerically.
5. Example
Gompertz Components
Suppose that, for ![]() and
and ![]() so
so![]() .
.
In this case, the ![]() subpopulation is Gompertz distribution with parameter
subpopulation is Gompertz distribution with parameter![]() . Let
. Let ![]() and
and ![]() are independent random variables such that
are independent random variables such that ![]() and for
and for![]() ,
, ![]() to follow a left truncated exponential density with parameter
to follow a left truncated exponential density with parameter ![]() (LTE(dj)), as used by [40] . A joint prior density function is then given by
(LTE(dj)), as used by [40] . A joint prior density function is then given by
![]() (41)
(41)
where ![]() and
and![]() .
.
5.1.1. One Sample Prediction
For ![]() substituting
substituting![]() ,
,![]() .
.
And Equation (41) in Equation (22) and solving, numerically, Equations (23) and (24) we can obtain the lower and upper bounds of BPI.
Special Cases
1) Upper order statistics
The predictive PDF (19), when ![]() and
and ![]() becomes
becomes
![]() , (42)
, (42)
where
![]()
Substituting from Equation (42) in Equation (22) and solving Equations (23) and (24), numerically, we can obtain the bounds of BPI.
2) Upper record values
When![]() , the predictive PDF (19) becomes
, the predictive PDF (19) becomes
![]() , (43)
, (43)
where
![]()
Substituting from Equation (43) in Equation (22) and solving Equations (23) and (24), numerically, we can obtain the bounds of BPI.
5.1.2. Two Sample Prediction
For ![]() and
and ![]() and
and![]() , substituting
, substituting![]() ,
, ![]() and Equation (41) in Equation (30) and solving, numerically, Equations (31) and (32) we can obtain the lower and upper bounds of BPI.
and Equation (41) in Equation (30) and solving, numerically, Equations (31) and (32) we can obtain the lower and upper bounds of BPI.
Special Cases
1) Upper order statistics
Substituting ![]() and
and ![]() in Equation (27), we have
in Equation (27), we have
![]() , (44)
, (44)
where
![]()
To obtain ![]() BPI for
BPI for![]() , we solve Equations (31) and (32), numerically.
, we solve Equations (31) and (32), numerically.
2) Upper record values
In Equation (27), by putting![]() , the predictive PDF of
, the predictive PDF of ![]() takes the form
takes the form
![]() , (45)
, (45)
where
![]()
Substituting from Equation (45) in Equation (30) and solving Equations (31) and (32), numerically, we can obtain the bounds of BPI.
5.1.3. Prediction for the Future Median (the Case of Odd N)
Special Cases
1) Upper order statistics
Substituting![]() ,
, ![]() ,
, ![]() and
and ![]() in Equation (27) with
in Equation (27) with ![]() and
and ![]() and by putting
and by putting ![]() and
and![]() , we have
, we have
![]() , (46)
, (46)
where
![]()
To obtain ![]() BPI for
BPI for![]() , we solve Equations (33) and (34), numerically.
, we solve Equations (33) and (34), numerically.
2) Upper record values
The predictive PDF (27), when![]() , becomes
, becomes
![]() , (47)
, (47)
where
![]()
To obtain ![]() BPI for
BPI for![]() , we solve Equations (33) and (34), numerically.
, we solve Equations (33) and (34), numerically.
5.1.4. Prediction for the Future Median (the Case of Even N)
Special Cases
1) Upper order statistics
The predictive PDF and survival function of ![]() can be obtained by substituting
can be obtained by substituting ![]() and
and ![]() in Equations (39) and (40), respectively.
in Equations (39) and (40), respectively.
2) Upper record values
The predictive PDF and survival function of ![]() can be obtained by substituting
can be obtained by substituting ![]() in Equations (39) and (40), respectively.
in Equations (39) and (40), respectively.
To obtain ![]() BPI for future median of ordinary order statistics or ordinary upper record values.
BPI for future median of ordinary order statistics or ordinary upper record values.
We solve Equations (33) and (34), numerically.
6. Numerical Computations
In this section, 95% BPI for future observations from a mixture of two![]() , components are obtained by considering one sample and two sample schemes.
, components are obtained by considering one sample and two sample schemes.
6.1. One Sample Prediction
In this subsection, we compute 95% BPI for![]() , in the two cases ordinary order statistics and ordinary upper record values according to the following steps:
, in the two cases ordinary order statistics and ordinary upper record values according to the following steps:
1) For a given values of the prior parameters ![]() generate a random value p from the
generate a random value p from the ![]() distribution.
distribution.
2) For a given values of the prior parameters![]() , for
, for ![]() generate a random value
generate a random value ![]() from the
from the ![]() distribution.
distribution.
3) Using the generated values of ![]() and
and![]() , we generate a random sample from a mixture of two
, we generate a random sample from a mixture of two ![]() components,
components, ![]() as follows:
as follows:
・ generate two observations ![]() from
from![]() ;
;
・ if![]() , then
, then ![]() otherwise
otherwise![]() ;
;
・ repeat above steps n times to get a sample of size n;
・ the sample obtained in above steps is ordered.
4) Using the generated values of ![]() and
and![]() , we generate upper record values of size
, we generate upper record values of size ![]() from a mixture of two
from a mixture of two![]() , components.
, components.
5) The 95% BPI for the future observations are obtained by solving numerically, Equations (23) and (24) with![]() . Different sample size n and the censored size are considered.
. Different sample size n and the censored size are considered.
6.2. Two Sample Prediction
In this subsection, we compute 95% BPI for two sample prediction in the two cases ordinary order statistics and ordinary upper record values according to the following steps:
1) For a given values of the prior parameters ![]() generate a random value p from the
generate a random value p from the ![]() distribution.
distribution.
2) For a given values of the prior parameters for ![]() generate a random value
generate a random value ![]() from the
from the ![]() distribution.
distribution.
3) Using the generated values of ![]() and
and![]() , we generate a doubly type II sample from a mixture of two
, we generate a doubly type II sample from a mixture of two ![]() components.
components.
4) The 95% BPI for the observations from a future independent sample of size N are obtained by solving numerically, Equations (31) and (32) with![]() .
.
5) Generate 10,000 samples each of size N from a mixture of two ![]() components, then calculate the coverage percentage of
components, then calculate the coverage percentage of![]() .
.
6) Different sample sizes n and N are considered.
6.3. Prediction for the Future Median
In this subsection, 95% BPI for the median of N future observations are obtained when the underlying population distribution is a mixture of two Gompertz components in the two cases ordinary order statistics and ordinary upper record values according to the following steps:
1) For a given values of the prior parameters ![]() generate a random value p from the
generate a random value p from the ![]() distribution.
distribution.
2) For a given values of the prior parameters![]() , for
, for ![]() generate a random value
generate a random value ![]() from the
from the ![]() distribution.
distribution.
3) Using the generated values of ![]() and
and![]() , we generate a doubly type II sample from a mixture of two
, we generate a doubly type II sample from a mixture of two ![]() components.
components.
4) The 95% BPI for the median of N of future observations are obtained by solving numerically, Equations (33) and (34) with ![]() for different values of N, when
for different values of N, when ![]() is odd and
is odd and ![]() is even.
is even.
5) Generate 10,000 samples each of size N from a mixture of two ![]() components, then calculate the coverage percentage of
components, then calculate the coverage percentage of![]() .
.
6) The prediction are conducted on the basis of a doubly type II censored samples and type II censored samples.
The computational (our) results were computed by using Mathematica 6.0. When the prior parameters chosen as b1 = 1.5, b2 = 2, d1 = 1, d2 = 2 which yield the generated values of ![]()
![]() In Tables 1-4, 95% BPI for future observations are computed in case of the one and two
In Tables 1-4, 95% BPI for future observations are computed in case of the one and two
sample predictions, respectively. In Table 5 and Table 6, 95% BPI for the medians of future samples with odd or even sizes are computed. Our results are specialized to ordinary order statistics and ordinary upper record values.
6.4. Conclusions
1) Bayes prediction intervals for future observations are obtained using a one-sample and two-sample schemes based on a finite mixture of two Gompertz components model. Our results are specialized to ordinary order statistics and ordinary upper record values.
2) Bayesian prediction intervals for the medians of future samples with odd or even sizes are obtained based on a finite mixture of two Gompertz components model. Our results are specialized to ordinary order statistics and ordinary upper record values.
3) It is evident from all tables that the lengths of the BPI decrease as the sample size increase.
4) In general, if the sample size n and censored size r are fixed the lengths of the BPI increase by increasing s.
5) For fixed sample size n, censored size r and s, the lengths of the BPI increase by increasing a or b.
6) The percentage coverage improves by the use of a large number of observed values.