1. Introduction
Many neuro-physiological experiments indicate that the information processing character of the biological nerve system mainly includes the following eight aspects: the spatial aggregation, the multi-factor aggregation, the temporal cumulative effect, the activation threshold characteristic, self-adaptability, exciting and restraining characteristics, delay characteristics, conduction and output characteristics [1] . From the definition of the M-P neuron model, classical ANN preferably simulates voluminous biological neurons’ characteristics such as the spatial weight aggregation, self-adaptability, conduction and output, but it does not fully incorporate temporal cumulative effect because the outputs of ANN depend only on the inputs at the moment regardless of the prior moment. In the process of practical information processing, the memory and output of the biological neuron not only depend on the spatial aggregation of input information, but also are related to the temporal cumulative effect. Although the ANN in Refs. [2] -[5] can process temporal sequences and simulate delay characteristics of biological neurons, in these models, the temporal cumulative effect has not been fully reflected. Traditional ANN can only simulate point-to-point mapping between the input space and output space. A single sample can be described as a vector in the input space and output space. However, the temporal cumulative effect denotes that multiple points in the input space are mapped to a point in the output space. A single input sample can be described as a matrix in the input space, and a single output sample is still described as a vector in the output space. In this case, we claim that the network has a sequence input.
Since Kak firstly proposed the concept of quantum-inspired neural computation [6] in 1995, quantum neural network (QNN) has attracted great attention by the international scholars during the past decade, and a large number of novel techniques have been studied for quantum computation and neural network. For example, Ref. [7] proposed the model of quantum neural network with multilevel hidden neurons based on the superposition of quantum states in the quantum theory. In Ref. [8] , an attempt was made to reconcile the linear reversible structure of quantum evolution with nonlinear irreversible dynamics of neural network. Ref. [9] presented a novel learning model with qubit neuron according to quantum circuit for XOR problem and described the influence to learning by reducing the number of neurons. In Ref. [10] , a new mathematical model of quantum neural network was defined, building on Deutsch’s model of quantum computational network, which provides an approach for building scalable parallel computers. Ref. [11] proposed the neural network with the quantum gated nodes, and indicated that such quantum network may contain more advantageous features from the biological systems than the regular electronic devices. Ref. [12] proposed a neural network model with quantum gated nodes and a smart algorithm for it, which shows superior performance in comparison with a standard error back propagation network. Ref. [13] proposed a weightless model based on quantum circuit. It is not only quantum-inspired but also actually a quantum NN. This model is based on Grover’s search algorithm, and it can both perform quantum learning and simulate the classical models. However, from all the above QNN models, like M-P neurons, it also does not fully incorporate temporal cumulative effect because a single input sample is either irrelative to time or relative to a moment instead of a period of time.
In this paper, in order to fully simulate biological neuronal information processing mechanisms and to enhance the approximation and generalization ability of ANN, we proposed a quantum-inspired neural network model with sequence input, called QNNSI. It’s worth pointing out that an important issue is how to define, configure and optimize artificial neural networks. Refs. [14] [15] make deep research into this question. After repeated experiments, we opt to use a three-layer model with a hidden layer, which employs the Levenberg-Mar- quardt algorithm for learning. Under the premise of considering approximation ability and computational efficiency, this option is a relatively ideal. The proposed approach is utilized to the time series prediction for Mackey-Glass, and the experimental results indicate that, under a certain condition, the QNNSI is obviously superior to the common ANN.
2. Qubit and Quantum Gate
2.1. Qubit
In the quantum computers, the “qubit” has been introduced as the counterpart of the “bit” in the conventional computers to describe the states of the circuit of quantum computation. The two quantum physical states labeled as 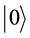 and
and 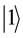 express 1 bit information, in which
express 1 bit information, in which 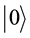 corresponds to the bit 0 of classical computers, while
corresponds to the bit 0 of classical computers, while 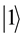 bit 1. Notation of “
bit 1. Notation of “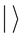 ” is called the Dirac notation, which is the standard notation for the states in the quantum mechanics. The difference between bits and qubits is that a qubit can be in a state other than
” is called the Dirac notation, which is the standard notation for the states in the quantum mechanics. The difference between bits and qubits is that a qubit can be in a state other than 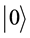 and
and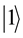 . It is also possible to form the linear combinations of the states, namely superpositions:
. It is also possible to form the linear combinations of the states, namely superpositions:
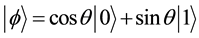 (1)
(1)
An n qubits system has 2n computational basis states. For example, a 2 qubit system has basis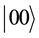 ,
, 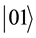 ,
, 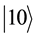 ,
,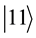 . Similar to the case of a single qubit, the n qubits system may form the superposition of 2n.
. Similar to the case of a single qubit, the n qubits system may form the superposition of 2n.
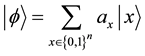 (2)
(2)
where 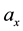 is called probability amplitude of the basis states
is called probability amplitude of the basis states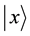 , and
, and ![]() means the set of strings of length two with each letter being either zero or one. The condition that these probabilities can sum to one is expressed by the normalization condition.
means the set of strings of length two with each letter being either zero or one. The condition that these probabilities can sum to one is expressed by the normalization condition.
![]() (3)
(3)
2.2. Quantum Rotation Gate
In quantum computation, the logic function can be realized by applying a series of unitary transform to the qubit states, which the effect of the unitary transform is equal to that of the logic gate. Therefore, the quantum services with the logic transformations in a certain interval are called the quantum gates, which are the basis of performing quantum computation.
The definition of a single qubit rotation gate is written as
![]() (4)
(4)
2.3. Quantum NOT Gate
The NOT gate is defined by its truth table, in which ![]() and
and![]() , that is, the 0 and 1 states are interchanged. In fact, the quantum NOT gate acts linearly, that is, it takes the state
, that is, the 0 and 1 states are interchanged. In fact, the quantum NOT gate acts linearly, that is, it takes the state ![]() to the corresponding state in which the role of
to the corresponding state in which the role of ![]() and
and ![]() have been interchanged,
have been interchanged,![]() . There is a convenient way of representing the quantum NOT gate in matrix form, which follows directly from the linearity of quantum gates. Suppose we define a matrix
. There is a convenient way of representing the quantum NOT gate in matrix form, which follows directly from the linearity of quantum gates. Suppose we define a matrix ![]() to represent the quantum NOT gate as follows
to represent the quantum NOT gate as follows
![]() (5)
(5)
The notation X for the quantum NOT is used for historical reasons. If the quantum state ![]() and
and ![]() is written in a vector notation as
is written in a vector notation as![]() , then the corresponding output from quantum NOT gate is
, then the corresponding output from quantum NOT gate is![]() .
.
2.4. Multi-Qubits Controlled-Not Gate
In a true quantum system, a single qubit state is often affected by a joint control of multi-qubits. A multi-qubits controlled-not gate ![]() is a kind of control model. The multi-qubits system is also described by the wave function
is a kind of control model. The multi-qubits system is also described by the wave function![]() . In an (n + 1)-bits quantum system, when the target bit is simultaneously controlled by n input bits, the dynamic behavior of the system can be described by multi-qubits controlled-not gate in Figure 1.
. In an (n + 1)-bits quantum system, when the target bit is simultaneously controlled by n input bits, the dynamic behavior of the system can be described by multi-qubits controlled-not gate in Figure 1.
In Figure 1(a), suppose we have n + 1 qubits, and then we define the controlled operation ![]() as follows
as follows
![]() (6)
(6)
![]() (a) (b)
(a) (b)
Figure 1. Multi-qubits controlled-not gate. (a) Type 1 control; (b) Type 0 control.
Suppose that the ![]() are the control qubits, and the
are the control qubits, and the ![]() is the target qubit. From Equation (6), the output of
is the target qubit. From Equation (6), the output of ![]() is written by equation
is written by equation
![]() (7)
(7)
It is observed from Equation (7) that the output of ![]() is in the entangled state of n + 1 qubits, and the probability of the target qubit state
is in the entangled state of n + 1 qubits, and the probability of the target qubit state![]() , in which
, in which ![]() is observed, equals to
is observed, equals to
![]() (8)
(8)
In Figure 1(b), the operator X is applied to last a qubit if the first n qubits are all equal to zero, and otherwise, nothing is done. The controlled operation ![]() can be defined by the equation
can be defined by the equation
![]() (9)
(9)
The probability of the target qubit state![]() , in which
, in which ![]() is observed, equals to
is observed, equals to
![]() (8)
(8)
At this time, after the joint control of the n input bits, the target bit ![]() can be defined as follows
can be defined as follows
![]() (9)
(9)
3. QNNSI Model
3.1. Quantum-Inspired Neuron Model
In this section, we first propose a quantum-inspired neuron model with sequence input, as shown in Figure 2. This model consists of quantum rotation gates and multi-qubits controlled-not gate. The ![]() defined in time domain interval [0, T] denote the input sequences. The output is the probability amplitude of the target state in
defined in time domain interval [0, T] denote the input sequences. The output is the probability amplitude of the target state in![]() . The control parameters are the rotation angles
. The control parameters are the rotation angles![]() .
.
Let![]() ,
,![]() . In this paper, we define the output of the quantum neuron as the probability amplitude of the corresponding state, in which
. In this paper, we define the output of the quantum neuron as the probability amplitude of the corresponding state, in which ![]() is observed. According to the definition of quantum rotation gate and multi-qubits controlled-not gate, the output of quantum neuron can be written as
is observed. According to the definition of quantum rotation gate and multi-qubits controlled-not gate, the output of quantum neuron can be written as
![]() (10)
(10)
where![]() ,
, ![]() , for Figure 2(a),
, for Figure 2(a), ![]() ,
,
![]()
Figure 2. The model of quantum-inspired neuron with sequence input. (a) Type 1 control; (b) Type 0 control.
for Figure 2(b),![]() .
.
3.2. Quantum-Inspired Neural Network Model
In this paper, the QNNSI model is shown in Figure 3, where the hidden layer consists of quantum-inspired neurons with sequence input, and the output layer consists of classical neurons. The ![]() denote the input sequences, the
denote the input sequences, the ![]() denote the hidden output, the
denote the hidden output, the ![]() denotes the connection weights in output layer, and the
denotes the connection weights in output layer, and the ![]() denote the network output. The Sigmoid function is used in output layer.
denote the network output. The Sigmoid function is used in output layer.
Unlike ANN, each input sample of QNNSI is described as a matrix instead of a vector. For example, the l-th sample can be written as
![]() (11)
(11)
Let![]() ,
, ![]() , According to the input/
, According to the input/
output relationship of quantum-inspired neuron, in interval![]() , the spatial and temporal aggregation results of the j-th quantum-inspired neuron in hidden layer can be written as
, the spatial and temporal aggregation results of the j-th quantum-inspired neuron in hidden layer can be written as
![]() (12)
(12)
The j-th output in hidden layer (namely, the spatial and temporal aggregation results in [0, T]) is given by
![]() (13)
(13)
The k-th output in output layer can be written as
![]() (14)
(14)
4. QNNSI Algorithm
4.1. Pretreatment of Input and Output Samples
Suppose the l-th sample in n-dimensional input space![]() , where
, where![]()
![]() ,
,![]() . Let
. Let
![]()
Figure 3. The model of quantum-inspired neural network with sequence input.
![]() (15)
(15)
![]() (16)
(16)
These samples can be converted into the quantum states as follows
![]() (17)
(17)
where![]() .
.
Similarly, suppose the ![]() output sample
output sample![]() , where
, where![]() . Let
. Let
![]() (18)
(18)
then, these output samples can be normalized by the following equation
![]() (19)
(19)
4.2. QNNSI Parameters Adjustment
In QNNSI, the adjustable parameters include the rotation angles of quantum rotation gates in hidden layer, and the weights in output layer. Suppose ![]() denote the normalized desired outputs of the l-th sample, and
denote the normalized desired outputs of the l-th sample, and ![]() denote the corresponding actual outputs. The evaluation function is defined as follows
denote the corresponding actual outputs. The evaluation function is defined as follows
![]() (20)
(20)
Let
![]() (21)
(21)
According to the gradient descent algorithm in Ref. [16] , the gradient of the rotation angles of the quantum rotation gates can be calculated as follows
![]() (22)
(22)
where![]() .
.
The gradient of the connection weights in output layer can be calculated as follows
![]() (23)
(23)
Because gradient calculation is more complicated, the standard gradient descent algorithm is not easy to converge. Hence we employ the Levenberg-Marquardt algorithm in Ref. [16] to adjust the QNNSI parameters.
Let P denote the parameter vector, e denote the error vector, and J denote the Jacobian matrix. p, e, and J are respectively defined as follows
![]() (24)
(24)
![]() (25)
(25)
![]() (26)
(26)
According to Levenberg-Marquardt algorithm, the QNNSI iterative equation is written as follows
![]() (27)
(27)
where ![]() denotes the iterative steps,
denotes the iterative steps, ![]() denotes the unit matrix, and
denotes the unit matrix, and ![]() is a small positive number to ensure the matrix
is a small positive number to ensure the matrix ![]() invertible.
invertible.
4.3. Stopping Criterion of QNNSI
If the value of the evaluation function E reaches the predefined precision within the preset maximum of iterative steps, then the execution of the algorithm is stopped, else the algorithm is not stopped until it reaches the predefined maximum of iterative steps.
5. Simulations
To examine the effectiveness of the proposed QNNSI, the time series prediction for Mackey-Glass is used to compare it with the ANN with a hidden layer in this section. In this experiment, we implement and investigate the QNNSI in Matlab (Version
7.1.0
.246) on a Windows PC with 2.19 GHz CPU and 1.00 GB RAM. Our QNNSI has the same structure and parameters as the ANN in the simulations, and the same Levenberg-Mar- quardt algorithm [16] is applied in two models.
Mackey-Glass time series can be generated by the following iterative equation [17]
![]() (28)
(28)
where ![]() and
and ![]() are integers,
are integers, ![]() ,
, ![]() ,
, ![]() , and
, and![]() .
.
From the above equation, we may obtain the time sequence![]() . We take the first 800 as the training
. We take the first 800 as the training
set, and the remaining 200 as the testing set. Our prediction schemes is to employ n data adjacent to each other to predict the next one data. Namely, in our model, the sequence length equals to n. Therefore, each sample consists of n input values and an output value.
Hence, there is only one output node in QNNSI and ANN. In order to fully compare the approximation ability of two models, the number of hidden nodes are respectively set to![]() . The predefined precision is set to 0.05, and the maximum of iterative steps is set to 100. The QNNSI rotation angles in hidden layer are initialized to random numbers in
. The predefined precision is set to 0.05, and the maximum of iterative steps is set to 100. The QNNSI rotation angles in hidden layer are initialized to random numbers in![]() , and the connection weights in output layer are initialized to random numbers in (−1, 1). For ANN, all weights are initialized to random numbers in (−1, 1), and the Sigmoid functions are used as the activation functions in hidden layer and output layer.
, and the connection weights in output layer are initialized to random numbers in (−1, 1). For ANN, all weights are initialized to random numbers in (−1, 1), and the Sigmoid functions are used as the activation functions in hidden layer and output layer.
Obviously, ANN has n input nodes, and an ANN’s input sample can be described as a n-dimensional vector. For the number of input nodes of QNNSI, we employ the following nine kinds of settings shown in Table 1. For each of these settings in Table 1, a single QNNSI input sample can be described as a matrix.
It is worth noting that, in QNNSI, an ![]() matrix can be used to describe a single sequence sample. In general, ANN cannot deal directly with a single
matrix can be used to describe a single sequence sample. In general, ANN cannot deal directly with a single ![]() sequence sample. In ANN, an
sequence sample. In ANN, an ![]() matrix is usually regarded as
matrix is usually regarded as ![]() dimensional vector samples. For fair comparison, in ANN, we have expressed the
dimensional vector samples. For fair comparison, in ANN, we have expressed the ![]() sequence samples into the
sequence samples into the ![]() dimensional vector samples. Therefore, in Table 1, the sequence lengths for ANN are not changed. It is clear that, in fact, there is only one kind of ANN in Table 1, namely, ANN36.
dimensional vector samples. Therefore, in Table 1, the sequence lengths for ANN are not changed. It is clear that, in fact, there is only one kind of ANN in Table 1, namely, ANN36.
Our experiment scheme is that, for each kind of combination of input nodes and hidden nodes, one ANN and nine QNNSIs are respectively run 10 times. Then we use four indicators, such as average approximation error, average iterative steps, average running time, and convergence ratio, to compare QNNSI with ANN. Training result contrasts are shown in Tables 2-5, where QNNSIn_q denotes QNNSI with n input nodes and q sequence length.
From Tables 2-5, we can see that when the input nodes take 6, 9, and 12, the performance of QNNSIs are
![]()
Table 1. The input nodes and the sequence length setting of QNNSIs and ANN.
![]()
Table 2. Training result contracts of average approximation error.
![]()
Table 3. Training result contracts of average iterative steps.
![]()
Table 4. Training result contracts of average running time (s).
![]()
Table 5. Training result contracts of convergence ratio (%).
obviously superior to that of ANN, and the QNNSIs have better stability than ANN when the number of hidden nodes changes.
Next, we investigate the generalization ability of QNNSI. Based on the above experimental results, we only investigate three QNNSIs (QNNSI6_6, QNNSI9_4, and QNNSI12_3). Our experiment scheme is that three QNNSIs and one ANN train 10 times on the training set, and the generalization ability is immediately investigated on the testing set after each training. The average results of the 10 tests are regarded as the evaluation indexes. For convenience of description, let ![]() denote the average of the maximum prediction error,
denote the average of the maximum prediction error, ![]() denote the average of the prediction error mean, and
denote the average of the prediction error mean, and ![]() denote the average of prediction error variance.
denote the average of prediction error variance.
Taking 30 hidden nodes for example, the evaluation indexes contrast of QNNSIs and ANN are shown in Table 6. The experimental results show that the generalization ability of three QNNSIs is obviously superior to that of corresponding ANN.
These experimental results can be explained as follows. For processing of input information, QNNSI and ANN take different approaches. QNNSI directly receives a discrete input sequence. In QNNSI, using quantum information processing mechanism, the input is circularly mapped to the output of quantum controlled-not gates in hidden layer. As the controlled-not gate’s output is in the entangled state of multi-qubits, therefore, this mapping is highly nonlinear, which make QNNSI have the stronger approximation ability. In addition, QNNSI’s each input sample can be described as a matrix with n rows and q columns. It is clear from QNNSI’s algorithm that, for the different combination of n and q, the output of quantum-inspired neuron in hidden layer is also different. In fact, The number of discrete points q denotes the depth of pattern memory, and the number of input nodes n denotes the breadth of pattern memory. When the depth and the breadth are appropriately matched, the QNNSI shows excellent performance. For the ANN, because its input can only be described as a nq-dimensional vector, it is not directly deal with a discrete input sequence. Namely, it only can obtain the sample characteristics by way of breadth instead of depth. Hence, in the ANN information processing, there exists inevitably the loss of sample characteristics, which affects its approximation and generalization ability.
It is worth pointing out that QNNSI is potentially much more computationally efficient than all the models referenced above in the Introduction section. The efficiency of many quantum algorithms comes directly from quantum parallelism that is a fundamental feature of many quantum algorithms. Heuristically, and at the risk of over-simplifying, quantum parallelism allows quantum computers to evaluate a function f(x) for many different values of x simultaneously. Although quantum simulation requires many resources in general, quantum parallelism leads to very high computational efficiency by using the superposition of quantum states. In QNNSI, the input samples have been converted into corresponding quantum superposition states after preprocessing. Hence, as far as a lot of quantum rotation gates and controlled-not gates used in QNNSI are concerned, information processing can be performed simultaneously, which greatly improves the computational efficiency. Because the above experiments are performed in classical computer, the quantum parallelism has not been explored. However, the efficient computational ability of QNNSI is bound to stand out in future quantum computer.
6. Conclusion
This paper proposes quantum-inspired neural network model with sequence input based on the principle of quantum computing. The architecture of the proposed model includes three layers, where the hidden layer consists of quantum-inspired neurons and the output layer consists of classical neurons. An obvious difference from classical ANN is that each dimension of a single input sample consists of a discrete sequence rather than a single value. The activation function of hidden layer is redesigned according to the principle of quantum computing. The Levenberg-Marquardt algorithm is employed for learning. With application of the information processing mechanism of quantum rotation gates and controlled-not gates, the proposed model can effectively obtain the sample
![]()
Table 6. The average prediction error contrasts of QNNSIs and ANN.
characteristics by ways of breadth and depth. The experimental results reveal that a greater difference between input nodes and sequence length leads to a lower performance of proposed model than that of classical ANN; on the contrary, it obviously enhances approximation and generalization ability of proposed model when input nodes are closer to sequence length. The following issues of the proposed model, such as continuity, computational complexity, and improvement of learning algorithm, are subjects of further research.
Acknowledgements
This work was supported by the National Natural Science Foundation of China (Grant No. 61170132), Natural Science Foundation of Heilongjiang Province of China (Grant No. F2015021), Science Technology Research Project of Heilongjiang Educational Committee of China (Grant No. 12541059), and Youth Foundation of Northeast Petroleum University (Grant No. 2013NQ119).
NOTES
*Corresponding author.