The Computational Theory of Intelligence: Applications to Genetic Programming and Turing Machines ()
1. Introduction
In this work, we carry on the ideas proposed in [1] [2] . In [1] , we posited some very basic assumptions as to what intelligence means as a mapping. Using our analysis, we formulated some axioms based on entropic analysis. In the paper that followed [2] we talked about how ideas or memes can aggregate together to form more complex constructs.
Here, we extend the concept of intelligence as a computational process to computational processes themselves, in the classic Turing sense.
The structure of this paper is as follows. In Section 2, we provide deeper insights as to different types of Computational Intelligence, specifically in the light of executable code, Section 3 the qualities of reproduction, virility, and nested programs. Section 4 presents some experimental results, and Sections 5 and 6 discuss applications. In the conclusion, we recapitulate and discuss future work.
2. Extending Concepts
Consider the definition of computational intelligence from [1] . Given the two sets 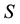 and
and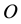 , which represent input and output sets, respectively, we introduce the mapping
, which represent input and output sets, respectively, we introduce the mapping
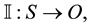 (1)
(1)
where 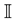 essentially makes a prediction based on the input. The disparity between a prediction and reality can then be used to update
essentially makes a prediction based on the input. The disparity between a prediction and reality can then be used to update 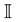 in such a way that it can climb the gradient of the learning function
in such a way that it can climb the gradient of the learning function 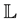 so as to improve future performance. Although we touched upon the application of this framework to Genetic Algorithms [1] , it will be insightful to revisit it in more detail.
so as to improve future performance. Although we touched upon the application of this framework to Genetic Algorithms [1] , it will be insightful to revisit it in more detail.
2.1. Active, Passive, and Hybrid Computational Intelligence
Let us clarify the terminology. By Genetic Algorithm (GA), we mean a collection or population 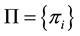 of potential solutions to a particular task, which evolves as time progresses according to some fitness function,
of potential solutions to a particular task, which evolves as time progresses according to some fitness function,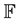 . The function
. The function 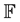 is synonymous with learning function
is synonymous with learning function 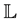 from our previous formulation. It evaluates the quality of
from our previous formulation. It evaluates the quality of 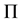 as a solution to the task. Specifically, if our task or program
as a solution to the task. Specifically, if our task or program 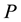 is a function of
is a function of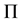 , then the fitness function
, then the fitness function 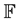 is nothing more than
is nothing more than
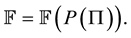
Note that the population  is not only our input set
is not only our input set ![]() but also our output set
but also our output set ![]() in the Equation 1. Furthermore, the mapping
in the Equation 1. Furthermore, the mapping ![]() is nothing but a collection of mutation operations to update the
is nothing but a collection of mutation operations to update the ![]() at iteration
at iteration ![]() to iteration
to iteration![]() . That is,
. That is,
![]()
Some common mutation operations of genetic algorithms are [3] :
1) Reproduction: selecting individuals within a population and copying them without alteration into the new population.
2) Crossover: produces new offspring from elements of two other parents.
3) Mutation: one of the central concepts of genetic algorithms. Mutation perturbs the population or its constituents in some way. This includes altering the elements of the population directly, or changing their placement in the population in some way such as swapping their indices.
4) Editing: a manner in which more complicated functionality can be reduced to simpler algebraic rules.
5) Adding/Deleting: the ability to add a new element to a population or remove an existing element from the population.
6) Encapsulating: the process of creating a new element that represents an aggregate of functionality from one or more other elements in the population.
Some consideration should be given to the statement
![]()
from [1] . For this equation to make sense, not only must the algebraic operation “![]() ” be meaningfully defined, but the gradient operator implies that
” be meaningfully defined, but the gradient operator implies that ![]() is differentiable. The gradient operation makes sense only if the domain of
is differentiable. The gradient operation makes sense only if the domain of ![]() is a Banach space. In this context, we cannot make such a claim. Thus Equation (4) becomes
is a Banach space. In this context, we cannot make such a claim. Thus Equation (4) becomes
![]()
where![]() . Observe that although the mathematical formulation is different, the intent still holds. The “
. Observe that although the mathematical formulation is different, the intent still holds. The “![]() ” operator communicates the number of permutations proportional to
” operator communicates the number of permutations proportional to![]() .
.
Since the information is retained in the population, and only improved through evolutionary perturbations, we consider this an example of Passive Computational Intelligence, (PCI). This stands in contrast to Active Computational Intelligence (ACI), where we are updating the mapping itself. Any combination of the two methods can be considered a form of Hybrid Computational Intelligence (HCI).
2.2. Genetic Algorithms
Recall the entropic considerations from [1] , where we specified that Computational intelligence is a process that locally minimizes and globally maximizes entropy.
Since the population ![]() is the output set, it is the entropy of the population that must be minimized by the intelligence process. Equivalently, we can say that as the amount of iterations becomes sufficiently large, the difference between
is the output set, it is the entropy of the population that must be minimized by the intelligence process. Equivalently, we can say that as the amount of iterations becomes sufficiently large, the difference between ![]() and
and ![]() becomes increasingly negligible. In other words, assuming the subtraction operation is meaningfully defined, we have
becomes increasingly negligible. In other words, assuming the subtraction operation is meaningfully defined, we have
![]()
This makes sense, for we expect that as time increases, the fitness of our solution reaches an optimum, so that eventually there is no need to update. In other words, our population becomes more consistent over time.
Of course, the typical considerations regarding genetic algorithms such the necessity of avoiding local optima, the proper choice of a fitness function, the complexity of the algorithm itself, among others, still hold [3] .
As for global entropy considerations, we must consider the role of the population in its realization under its program![]() . As mentioned before, the total entropy
. As mentioned before, the total entropy ![]() of a system can be written as:
of a system can be written as:
![]()
where ![]() represent each respective source of entropy. In particular, under the considerations of this section, we have
represent each respective source of entropy. In particular, under the considerations of this section, we have
![]()
where ![]() and
and ![]() represent the entropy due to the population itself and the entropy from the program
represent the entropy due to the population itself and the entropy from the program![]() , respectively. To calculate the entropy, we used the Renyi entropy of order
, respectively. To calculate the entropy, we used the Renyi entropy of order![]() , where
, where ![]() and
and ![]() defined as
defined as
![]()
where ![]() is the probability associated with state
is the probability associated with state![]() .
.
2.3. Turing Machines
Let us consider the discussions of the previous sections in terms of code that is executable in the Turing sense. We will apply the formulations we have considered thus far and make improvements to refine the theory in this light.
Recall that a Turing machine ![]() is a hypothetical device that manipulates symbols on a tape, called a Turing tape, according to a set of rules. Despite its simplicity, the Turing machine analogy can be used to describe certain aspects of modern computers [4] , and more [5] .
is a hypothetical device that manipulates symbols on a tape, called a Turing tape, according to a set of rules. Despite its simplicity, the Turing machine analogy can be used to describe certain aspects of modern computers [4] , and more [5] .
The Turing tape has some important characteristics. The tape contents, called the alphabet, encode a given table of rules. Using these rules the machine manipulates the tape. It can write and read to and from the tape, change the configuration, or state ![]() of the machine, and move the tape back and forth [6] .
of the machine, and move the tape back and forth [6] .
Typically, the instructions on the Turing tape consist of at least one instruction that tells the machine to begin computation, or a START instruction, and one to cease computation, called a STOP or HALT instruction [6] . Other instructions might include MOVE, COPY, etc., or even instructions that encode no operation at all. Such instructions are commonly called NOOP’s (NO Operation). The total number of instructions depends on the situation and the application at hand, but for the purposes of this paper, we will consider only tape of finite length for which the instruction set is also finite and contains at least the START and STOP instructions. In fact, for our purposes, the minimum amount of opcodes a program needs to run, or to be executable, are the START and STOP instructions.
Now, consider the set of all instructions available to a particular![]() . To be consistent with our notation thus far, we will denote this set as
. To be consistent with our notation thus far, we will denote this set as![]() , where
, where
![]()
From this set, a particular sequence of instructions ![]() can be formed. Although many synonymous terms abound for this sequence of instructions, including a code segment, executable, or tape, we will refer to it simply as the code. We consider the execution or implementation
can be formed. Although many synonymous terms abound for this sequence of instructions, including a code segment, executable, or tape, we will refer to it simply as the code. We consider the execution or implementation ![]() to be the execution of the code on the Turing machine
to be the execution of the code on the Turing machine![]() , which produces could produce another code segment, and change the machine state. Expressed in notation:
, which produces could produce another code segment, and change the machine state. Expressed in notation:
![]()
where ![]() and
and ![]() represent the set of all code and machine states, respectively. For the majority of this paper, it is the code that is of primary concern, and thus we can omit the machine state to simplify the notation when this context is understood:
represent the set of all code and machine states, respectively. For the majority of this paper, it is the code that is of primary concern, and thus we can omit the machine state to simplify the notation when this context is understood:
![]()
Our fitness function ![]() is a measure the efficaciousness of the implementation of our program by some predefined standard.
is a measure the efficaciousness of the implementation of our program by some predefined standard.
We are still free to think of the intelligence mapping ![]() as a perturbation mapping. The only difference is the physical interpretation of the term “population”. This case concerns machine code instructions. As with genetic algorithms, perturbing code may advance or impede the fitness of the program. In fact, it may even destroy the ability to execute at all, if one either the START or STOP operations are removed.
as a perturbation mapping. The only difference is the physical interpretation of the term “population”. This case concerns machine code instructions. As with genetic algorithms, perturbing code may advance or impede the fitness of the program. In fact, it may even destroy the ability to execute at all, if one either the START or STOP operations are removed.
A final note should be made as to the entropic considerations of the Turing Machine. In this light, we must take into account all the workings of the machine and thus we may now express the entropy as
![]()
where ![]() is the entropy incurred by the Turing Machine, which includes its state
is the entropy incurred by the Turing Machine, which includes its state![]() .
.
3. Reproduction, Viruses, and Nested Programs
In this section, we will continue the above analysis, and discussed some qualities that emerge based on our assumption.
3.1. Formalisms of Code and Other Qualities
We can apply set theoretic formalisms in the usual sense. For example, consider a code ![]() and an instruction,
and an instruction,![]() . Then the notation
. Then the notation ![]() communicates the fact that
communicates the fact that ![]() is an instruction in
is an instruction in![]() . Further, set theoretic operations follow naturally. Let
. Further, set theoretic operations follow naturally. Let![]() ,
,![]() . In the case of the union operation, we have
. In the case of the union operation, we have
![]()
which is a set containing the two programs ![]() and
and![]() . Similarly, with the intersection operation, we have
. Similarly, with the intersection operation, we have
![]()
or the set of all contiguous code segments ![]() that are contained by both
that are contained by both ![]() and
and![]() . Note that this code segment need not be executable. Also, if it is of particular utility in the program it may be degenerate in that it may appear multiple times throughout the code.
. Note that this code segment need not be executable. Also, if it is of particular utility in the program it may be degenerate in that it may appear multiple times throughout the code.
For set inclusion, we say that
![]()
Proper containment evolves naturally if![]() .
.
3.2. Metrics and Neighborhoods
The differences between code and real numbers or sets in conventional mathematics make it at first difficult to form a distance metric ![]() on them. Still, some have been explored such as the Levenshtein distance [7] , Damerau-Levenshtein distance [8] , Hamming distance [9] , and the Jaro-Winkler distance [10] .
on them. Still, some have been explored such as the Levenshtein distance [7] , Damerau-Levenshtein distance [8] , Hamming distance [9] , and the Jaro-Winkler distance [10] .
Given a metric![]() , we can form an open ball [11] , or neighborhood
, we can form an open ball [11] , or neighborhood ![]() centered at some code
centered at some code ![]() consisting of all programs
consisting of all programs ![]() such that for some real number
such that for some real number![]() ,
,![]() . In other words
. In other words
![]()
We can utilize the developments above to relax the definition of set inclusion with respect to the metric,![]() . Specifically, define
. Specifically, define
![]()
Of course, similar considerations can be extended to proper containment. Such code segments that lie suitably close to each other with respect to ![]() will be referred to as polymorphic with respect to
will be referred to as polymorphic with respect to![]() .
.
3.3. Reproduction
Our discussion in Section 3.2 has many applications and is of great importance especially to society as of the past five years. We can draw examples in real estate, financial markets, and population growth. Indeed this mathematics may be used to identify sustainable growth, or bubbles, periods of extraordinary inflationary growth followed by abject collapse.
For example, consider the well-studied behavior exhibited in the growth of bacterial colonies. There is an initial lag phase as the RNA of the bacteria start to copy, followed by an explosion of exponential growth called the growth phase, followed by a brief period of stability before the bacteria exhaust their resources resulting in an expedient decay.
3.4. Viruses
Thus far, we have been considering only predefined programs. But a well-known concept from nature concerns when external code is injected into a host program, or otherwise hijacks the computational resources of the system [12] . One key characteristic of viruses is their ability to proliferate. Consider ν such that
![]()
If the viral code, ![]() is executable, we will call the virus
is executable, we will call the virus![]() ―executable. If the viral code also can reproduce, that is
―executable. If the viral code also can reproduce, that is![]() , we will call this quality
, we will call this quality![]() ―reproductive. Finally, it is often the case that viral code is not reproductive or executable. Its task is to merely copy or install some payload [13] , here denoted by
―reproductive. Finally, it is often the case that viral code is not reproductive or executable. Its task is to merely copy or install some payload [13] , here denoted by![]() . In this case,
. In this case,
![]()
Viral code most often is pernicious, though this is not necessarily the case. For example, up to 8% of the human genome derives from retroviruses [14] . To determine the nature of the effect of the virus, we look at the change in fitness before and after its influence.
The influence of viral code on program fitness falls into three categories. Consider![]() ,
, ![]() , and
, and![]() ,
, ![]() ,
,![]() . In other words,
. In other words, ![]() code in the presence of a virus, from the otherwise pristine
code in the presence of a virus, from the otherwise pristine![]() . The three cases are
. The three cases are![]() ,
, ![]() , and
, and![]() . These cases are of enough significance that they deserve their own nomenclature. We will refer to these cases as commensalistic, symbiotic, and parasitic, respectively, out of consistency with their counterparts from biological sciences.
. These cases are of enough significance that they deserve their own nomenclature. We will refer to these cases as commensalistic, symbiotic, and parasitic, respectively, out of consistency with their counterparts from biological sciences.
3.5. Nested Programs
One final case to be considered is when a program or multiple programs can contribute to produce aggregate programs of greater complexity. In such a case, the program, when executed, would not only alter machine state and produce code but will also contain a product code segment, and product code machine state,
![]()
Introduce the program
![]()
Of course, we could nest this process and define
![]()
with ![]() from 24 denoted as
from 24 denoted as![]() , we could write
, we could write
![]()
where the superscript indicates the level of nesting of the program.
Just as we discussed programs producing multiple progeny, we can also let them produce multiple product code. We will denote each copy with a subscript![]() . Thus the above becomes
. Thus the above becomes
![]()
To determine the total entropy, simply sum over all product code.
![]()
This time we see that the entropy of the code varies exponentially with product and copy code.
4. Experimentation
Consider the following scenario. We have a set of instructions, and a construct for a tape that encodes them. In the following experiments, the code is created randomly. We apply a GA to the code to achieve interesting results. The code involved had no write-back capabilities, and thus the experiment was purely passive.
4.1. Genetics and Codons
A major focus for future work is the application of this research to computational molecular biology. Hence, we chose to implement the instruction set that nature has chosen for genetics in the following experiments.
For the base instruction alphabet, we will choose that of RNA [15] . This instruction set is composed of the “bits” Adenine (A), Uracil (U), Guanine (G), and Thymine (T). Each instruction can be represented as three of these quaternary bits, for a total of 64 possible outcomes. We have chosen this quaternary codon formulation to be the basis of our tape.
In both experiments, the choice of operational codes, or opcodes, are taken directly from these 64 quaternary bit codons. The choice to represent an opcode by a particular codon is completely arbitrary. All codons appear with the same probability in experiment, with the exception of the STOP opcode, as we will see in Section 4.2.
We present two instructions sets, and two different experiments. In the first experiment, we determine how many iterations our genetic algorithm takes to produce code that is executable, and code that reproduces itself. In the second experiment, we compare the amount of reproductions of code with the total entropy incurred by the simulation.
4.2. First Instruction Set
For the first experiment we constructed a robust instruction set consisting of the following:
1) START (AAA): Commences program execution.
2) STOP (AUA, ATC, ATG): Halts program execution. Observe that there are three STOP codons, but only one START codon. This mirrors the amount of codons in RNA and DNA observed in nature [16] .
3) BUILD_FR (CUC): Copies to product code, starting from the next respective instruction to that which comes before the BUILD_TO (GCG) instruction.
4) COND (UUC, UUA, GAA): Sets an internal variable in the Turing machine state called a flag. A flag can be thought of as an internal Boolean variable. Every time one of the COND opcodes is encountered the sign of the flag is switched, that is COND = ¬COND.
5) IF (AAU): Only executes the following instruction if the COND flag has been set.
6) COPY_ALL (AAG): Copies the entire tape to progeny.
7) COPY_FR (CCC): Copies to progeny code (as in [Section reference]), starting from the next respective instruction to that which comes before the COPY_TO (GGG) instruction.
8) JUMP_FAR_FR, (CUU) and JUMP_NEAR_FR, (AGA): both require a JUMP_TO, (CAC, GUG) instruction. The JUMP family of instructions is designed to continue program execution at the index of the JUMP_TO instruction. The former will find the JUMP_TO address that is farthest away, while the JUMP_NEAR finds the closest JUMP_TO instructions. If there is no multiplicity in the JUMP_TO instruction, then JUMP_FAR_FR, (CUU) and JUMP_NEAR_FR will produce the same result.
9) REM_FR, (GCU) and REM_TO, (UAA): Removes all code in between these instructions.
4.3. Second Instruction Set
Although the code of the previous section was robust, it was redundant. For example, the functionality of the code to copy itself to progeny should be a desirable trait of the code itself, not just an opcode that accomplishes the task in one step. Further, the remove operations can be handled via mutation operations (albeit far less efficiently) in the genetic algorithm itself.
Note that in Experiment 1, most operations have a partner or conjugate opcode. The necessity of conjugate pairs of instructions follows from the fact that two pieces of information are required to complete the instruction, as shown below:
[instruction]......[instruction dual].
We will call such instructions dual. By using the concept of addressing we can mitigate the necessity for a predefined conjugate opcode. Instead of conjugate opcodes, the instruction immediately following the dual can be thought of as an argument. The machine uses this address (unless the address is represents opcode) as a manner of locating the conjugate to the dual and thus reducing the instruction set. Specifically:
[instruction ][address]... ...[address].
Under these considerations (and omitting the ability to build to a product), we have need for only six instructions: START, STOP, IF, COND, COPY, and JUMP. The first four instructions are exactly the same as in Experiment 1. The COPY instruction concatenates section of the tape to progeny, and the JUMP instruction continues program execution at a specified address. These final two are conjugates, the duals of which are handled via the addressing method entailed above. Notice although the lexicon is different, they have the same functionality as their respective counterparts in the first instruction set.
4.4. Experiment 1: Code Execution and Reproduction
The goal of the first instruction set was to produce code that was executable, and code that could reproduce. A GA perturbed the code randomly. That is, no fitness function was used in the perturbation of the code strings. Each epoch of the simulation terminated once an executable or reproducible code was discovered. For each experiment, a maximum of 1,000,000 computational iterations were allowed.
The results of the first experiment using the first instruction set are shown in Table 1. The results of the first experiment using the second instruction set are summarized in Table 2. Observe that the number iterations in the first instruction set was much less than that of the second, which is likely due to the disparity in robustness between the two. Also note how wildly the results vary especially in terms of the reproductive capabilities of the second instruction set as demonstrated by the large standard deviation in results.
![]()
Table 1. Results: Experiment 1, instruction set 1.
![]()
Table 2. Results: Experiment 1, instruction set 2.
4.5. Experiment 2: Reproduction and Entropy
Upon answering the basic questions like the amount of computational iterations necessary to produce executable and reproductive code, the next experiment focused on the total entropy incurred by a given code segment and its offspring. Here, recall that we are considering the entropy produced by not only a given tape, but its progeny as well. We will continue with the alphabets of Experiment 1 and 2, respectively.
We bounded the total computational iterations per experimental run at 1,000,000. The maximum progeny allowed was 50. Mutations were applied by the GA according to a fitness function that evaluated the quality of the code with respect to its Renyi Entropy (of order![]() ).
).
The results are summarized in Table 3. Observe that the entropy and the amount of reproductions appear to be correlated as demonstrated by the r-values in Table 3 and in the correlation maps in Figure 1. Note that some programs appear to have achieved reproductive qualities without substantially increasing entropy but the converse is not true.
Although the actual data summarized in Table 3 was one of the primary goals of this experiment, the operational characteristics of the code itself were also of interest. The graphics in Figure 2 represent some interesting code behaviors. In the graphs below, a number in the following represented each opcode in the following manner: START = 0, COPY = 1, JUMP = 2, IF = 3, COND = 4, STOP = 5. With these numeric values we can visualize program behavior graphically.
Although a myriad of behaviors were observed, in Figure 2 we have selected some graphs of the different behaviors. Of specific interest were the non-terminating programs. Each of these selections also exhibited reproductive capabilities. Observe that although towards the beginning of program execution, a variety of instructions were executed, eventually the programs under consideration converged to some sort of periodic behavior to which we will refer as asymptotic periodicity.
![]()
Figure 1.Graphs of reproductive iterations plotted against the total entropy of the simulation, for the first and second instruction sets, respectively.
![]()
Table 3. Results: Reproduction and entropy.
![]()
Figure 2.Graphical representations of samples that exhibited the quality of reproduction. Observe the periodic nature of their behaviors.
The graphs selected not only demonstrated asymptotic periodicity but also reproduced continuously in the sense that the progeny produced reached the maximum allowable threshold.
5. Applications to Biology
Readers familiar with genetics will notice a strong correlation between our computational formulations and genetics. In fact, genetics has been an inspiration for this research, specifically with regard to passive and hybrid forms of CTI. Recent research has been devoted to the crossover between genetics and computer science. In fact, it has been demonstrated in [5] that DNA computing is Turing complete. This has grand implications for the very nature of the definition of life itself.
The definition of life has always been somewhat controversial. In [17] , life is defined as a characteristic that distinguishes objects with self-sustaining processes from those that do not. From the vantage point of Biology, life is defined as a characteristic of organisms that exhibit all or most of the following characteristics: homeostasis, organization, metabolism, growth, adaptation, response to stimuli, and reproduction [18] . Many sources stress the chemical nature of life, and mandate that living things contain Carbon, Hydrogen, Nitrogen, Oxygen, Phosphorous and Sulfur [19] .
In this paper, we introduce a definition for life as a self-sustaining passive or hybrid CTI process. Embedded in this definition are well-known assumptions regarding qualities one commonly associates with living things. It is known that the purpose of life is to survive, a fact that is redundant in the light of CTI. The fact that life is fitness maximizing, and increases entropy follows directly from the framework of CTI as well. Homeostasis follows naturally from the entropy-minimizing portion of the fundamental axiom of CTI. If an organism is in homeostasis, this implies that the internal state space is ordered and transitions can be predicted with high probability that implies lower entropy. Further, note the similarities with asymptotic periodicity from the samples shown in Figure 2. Of course, no discussion about life would be complete without mentioning reproduction, which we showed in this paper, follows as a natural consequence of CTI.
As far as we know, Earth is the only planet in the universe known to sustain life. However, recent advances in planetary sciences have discovered the possibility of habitable zones in other solar systems. This coupled with the observed robustness of life on Earth in extreme environments, has raised interest the application of biological concepts to the search for life beyond the confines of Earth. The vastness of these environments forces us to rethink and generalize what we know as life itself. One fantastic example of such an esoteric formulation of life is the discovery of arsenic based life right here on Earth. In December of 2010, NASA unveiled a discovery of a bacterium that integrated Arsenic into its cellular structure and even its DNA. They found that the bacterium was able to substitute arsenic for phosphorous, one of the six essential ingredients of life. This challenges conventional notions of life and seems to encourage a more general definition. In this paper, we advocate a computational approach to the definition of life over a chemical one.
6. Applications to Computer Science and Cyber Security
Applications to cyber security abound as well. In the past, computer viruses typically served little more than the entertainment of the author. Now, malicious software, or malware, is a commoditized industry. Patrons will hire teams of programmers to create specialized malware for end goals such as espionage, ransom, or identity theft. As such, mitigating these threats has become a priority in most industries and even an interest in national security. For example, the US Defense Advanced Research Projects Agency (DARPA) has issued a “Cyber Grand Challenge” offering up to $2 million for designs of a fully automated software defense system, capable of mitigating software exploitation in real time [20] . This is just one example of increased efforts in this area. In fact, the US president is proposing to increase the cyber defense budget to $14 billion in 2014, more than a billion dollar increase from that of the previous year [21] .
How might this research be of merit in this field? Currently, most anti-malware software (AM) stores hashes of actual malware samples against which to compare new potential threats. This has multiple disadvantages in that it ties users to a provider that may be an issue if Internet connectivity is a problem. Frequently such hashes fail with polymorphic code.
Recently, much research has been conducted looking at a behavioral approach to malware classification. While this is an exciting area of research, approaches of this nature are typically burdened with false positives rendering the solutions impractical.
This research offers the potential to view executable code in a new light offering insights into two key areas of interests: the nature of viruses, and the executable code itself, offering a new paradigm to the software industry. Software serves a purpose. It has solid attainable goals to suit the end user. Concurrently, it must function within a specified range of parameters to preserve privacy, security, and even safety. The effectiveness of a program under these guidelines can be viewed as its fitness.
Regardless of whether we are analyzing virus behavior or developing code that optimizes its fitness, we need a reliable indicator as to its behavior. One of the first successful defenses of malware was to attack the very functions the AM product would call to detect it! This is akin to asking the burglar if he is in your house. Thus behavior-detecting components must function at a “lower” level than those to which the malware may have access. Insuring this can be quite challenging. Nevertheless, if such a framework were in place, the advantages have enormous potential. In terms of viruses and payload detection, we could apply analysis from Section 3.4. Equivalently, we could monitor program performance to scan for points of inadequacy. Moreover, in the event of a breach or infection, we could employ the methods of CTI as a means by which the code could heal itself. Again, this necessitates a proper fitness function to evaluate the “health status” of the executable, and trusted behavioral data from the system.
Of course, there is a wide rift between the musings of theory and the result of implementation, but this framework seems to provide a promising direction for future efforts in this arena.
7. Conclusions
To recapitulate, in this paper, we extended the CTI framework presented in [1] [2] to include genetic algorithms and Turing machines. We defined classes of CTI including active, passive and hybrid. Finally, we demonstrated that reproduction emerges as a consequence of the axioms of CTI, both theoretically, and experimentally.
The concepts we presented have great potential for development in future work. As far as the theoretical concepts of this paper are concerned, we have a lot to do in terms of exploring the potential of passive, active, and hybrid processes. It remains the stance of this paper that hybrid CTI processes are present optimal solutions but this remains to be shown. We would also like to further explore simulation and programming using reproductive nested code. Further, we would like to repeat the experiments of Section 4 with different instruction sets, and observe not only the behaviors, but also the phenotypes of the solutions in general, to observe overarching patterns among diverse coding alphabets that achieve the same result.
In terms of multidisciplinary studies we have only scratched the surface of the relationship between these concepts and Computational Molecular Biology, Computer Science, and Cyber Security.
Further, there is much to do in the way of advancing the theoretical framework of CTI itself. In the next paper, we will visit the ramifications of adding feedback into the intelligence process. Another paper will focus on the global properties of intelligent agent.