A Model to Estimate the Impact of Thresholds and Caps on Coverage Levels in Community-Based Health Insurance Schemes in Low-Income Countries ()
1. Introduction
Most healthcare spending in developing countries is borne by healthcare-seekers out-of-pocket (OOP). India is a good example: 70% of health spending is private, 86% of which is OOP [1] [2] . Households in India frequently finance such OOP spending, not only for inpatient care but also for outpatient care and even for maternity-related costs, by borrowing money with interest or selling assets [3] . This inequitable and inefficient health financing situation persists in other low-income countries as well [4] . The solution proposed by WHO and other international bodies has been to strive toward universal health coverage, notably through prepayment and risk pooling mechanisms in lieu of payments at the point and time of service delivery [5] [6] . Yet, penetration of health insurance in most low-income countries remains very low [7] ; in India, insurance uptake is below 5% [8] . One possible explanation for low insurance uptake is that poorer individuals in the informal sector doubt their own ability to enforce contracts with insurance companies. A solution to the problem is for people to own and run community-based health insurance (CBHI) schemes at village level [9] -[13] .
Typically, CBHI schemes do not benefit from premium subsidy. Therefore, these stand-alone schemes must ensure that benefit expenditures would be limited to premium income (reflecting willingness-to-pay levels).This can be done through the application of a threshold (the predetermined amount above which the insurance reimburses the rest of the bill) and/or a cap (the predetermined amount up to which the insurance reimburses the bill). For premium calculations, information is needed on the probability of healthcare utilization by insured persons and the cost of that utilization. The consequences of applying thresholds and/or caps on the expected average pay-out of insurance, and thus on the premium, can be calculated only when the distribution of the costs of healthcare utilization is known. It is self-explanatory that when low caps are applied, the effective protection of insured persons for costs above the cap is diminished. The lower the cap, the more likely the situation of reduced insurance cover, which could lead to a perception that the insurance will not provide the protection the clients seek. Such perception could greatly dampen willingness to affiliate. It is recalled that the actual assessment of the effects of caps on the protection provided by the insurance can be known in advance only if the distribution of costs is known.
Our study builds on previous research, which confirmed the imperative need to obtain information locally [14] because locations differ significantly in the number and type of illness episodes [15] , cost of healthcare [16] and the willingness-to-pay (WTP) for health insurance [17] -[19] . Location-specific data cannot be extracted accurately from national data; one source would be actual claims data (fixing premiums based on such information is called “experience rating”), but this can apply only to schemes already in operation. Projections for new schemes must rely on household surveys. Indeed, a number of experiments with CBHI have relied on baseline data collection (mainly household surveys) to obtain reliable local estimates required for package design and pricing [20] -[25] . However, the time and money required to obtain information through household surveys prior to launching CBHI impede the replication of new CBHIs. To reduce these impediments preceding the launch of CBHI, we have developed faster and cheaper methods to estimate morbidity and healthcare utilization through a quick intervention method we called “Illness Mapping” [26] , as well as estimates of WTP [18] . This article deals with estimating the distributions of healthcare costs, which is the third piece of information needed.
The purpose of this paper is to develop a method for premium calculation of locally relevant health insurance packages that apply a threshold and/or a cap to benefits, and to show that this can be done even without cumbersome and expensive data collection efforts in each location where CBHI is implemented.
2. Data and Methods
2.1. Setting and Sampling
The study is based on data obtained from 11 household surveys conducted in the following periods and locations: 2008, in Warangal and Karimnagar districts, Andhra Pradesh, India; 2009, in Kalahandi, Khorda and Malkangiri districts, Odisha, India; and in Dhading and Banke districts, Nepal; and 2010, in Kanpur Dehat and Pratapgarh districts, Uttar Pradesh, India; and Vaishali and Gaya districts, Bihar, India.
All locations were selected purposively, in agreement with local Non-Government Organizations (NGOs, listed in the acknowledgement) implementing a development project among their members, for which these surveys formed part of the baseline study.
We followed a two-stage sampling procedure: in stage one, villages were selected; 8 were selected in Warangal, 12 in Karimnagar and 42, 15 and 34 villages respectively in Kanpur Dehat, Pratapgarh and Vaishali (from a list given by the local NGO); 27, 22, 31, 9 and 17 villages were randomly sampled in Kalahandi, Khorda, Malkangiri, Dhading and Banke respectively (from lists provided by the local NGOs); and 50 villages were selected randomly in Gaya (from lists provided by the local NGO) plus 50 villages that were selected randomly from the Census 2001 registry of villages. In stage two, households were sampled randomly in each selected village by applying the “four winds” (or “line sampling”) technique [27] (except in Kanpur Dehat, Pratapgarh and Vaishali). The households were sampled in two cohorts of equal size: member and non-member households. Households were defined as “Members” if at least one person participated in a Self-Help-Group linked to partner-NGOs; other households were “Non-members”. We aggregated the two sub-cohorts for the purpose of the analysis reported here. In Kanpur Dehat, Pratapgarh and Vaishali stage two entailed inclusion of all member households, rather than sampling.
Sample sizes were 625 households (2464 individuals) in Warangal, 1089 (4384) in Karimnagar, 1805 (8258) in Kalahandi, 1758 (9110) in Khorda, 1597 (7448) in Malkangiri, 1000 (5275) in Dhading, 1008 (5741) in Banke, 1751 (10,220) in Kanpur Dehat, 1541 (9374) in Pratapgarh, 1922 (10,286) in Vaishali and 2006 households (13,320 individuals) in Gaya. It is noted that sampling was intended to represent the target population for the CBHI programme rather than the entire population in either state or district. 100% of the sampled households were rural. The overall response rate was 100% because there was always a willing adult respondent in the household.
The survey questionnaire was translated from English into the local languages (Telugu, Oriya, Hindi and Nepali, respectively for AP, Odisha, UP and Bihar, and Nepal), back translated for verification, and pre-tested among 80 households per language. Surveyors fluent in local dialects conducted the interviews. These surveyors were hired through local survey companies. The interviews were conducted orally at the houses of the sampled respondents as the respondents mostly were illiterate. The answers provided were recorded by the interviewers. Informed consent of the respondents was obtained and recorded prior to interviews. Participants’ names were kept confidential in data recording and analysis. The research tools were reviewed for ethical compliance by an ad-hoc advisory committee composed of scholars and senior scholars from India and other countries that held a two-day workshop in New Delhi in 2006 in preparation of the study, and discussed ethical compliance of the study. It is recalled that at the time of the rollout of the survey there was no local ethics committee in place in India or Nepal.
2.2. Data We queried about general demographics and socio-economic status of households. Respondents to the household survey were asked, among others, to report the age, gender, education and economic activity of every household member. For our “income-proxy” we followed the method as adopted by the Indian National Sample Survey Organization [28] to note expenditures on many items of household consumption. Our income-proxy does not include health expenditure as recommended in previous studies related to determinants of health expenditure [29] [30] .
Besides demographics and socio-economic status, we also queried about hospital admissions (exceeding 24 hours) in the year preceding the survey, as well as the direct medical costs related to each admission. These expenditures included the hospital bill, and other consumables from outside sources used during the hospitalization and directly related to it e.g. expenditures for medicines or tests. We also queried about costs of diagnostic tests performed in an outpatient setting in the month preceding the survey.
2.3. Method
We define the following variables:
X = the costs per event of an insurance benefit, such as hospitalization or tests;
f(x) = the density function of X;
t = threshold value, c = cap value, we assume t < c;
 = the expected costs of an insurance benefit;
= the expected costs of an insurance benefit;
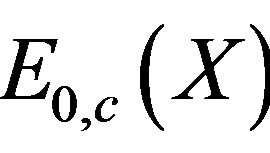 = the expected pay-out by an insurer for a policy covering the costs of an insurance benefit up to cap c;
= the expected pay-out by an insurer for a policy covering the costs of an insurance benefit up to cap c;
 = the expected pay-out by an insurer for a policy covering the costs of an insurance benefit above threshold t;
= the expected pay-out by an insurer for a policy covering the costs of an insurance benefit above threshold t;
 = the expected pay-out by an insurer for a policy covering the costs of an insurance benefit above threshold t and below cap c.
= the expected pay-out by an insurer for a policy covering the costs of an insurance benefit above threshold t and below cap c.
We assume the density function of healthcare expenditures to be a continuous distribution describing the healthcare expenditures per cost generating event. Previous research has shown that the distribution of positive healthcare expenditures per person per year can be approximated by a lognormal model [31] -[34] . We therefore investigate in this article to what extent a lognormal model can be used to approximate the distribution of the healthcare costs per event. The density function of a lognormal distribution f(x) is:
1) 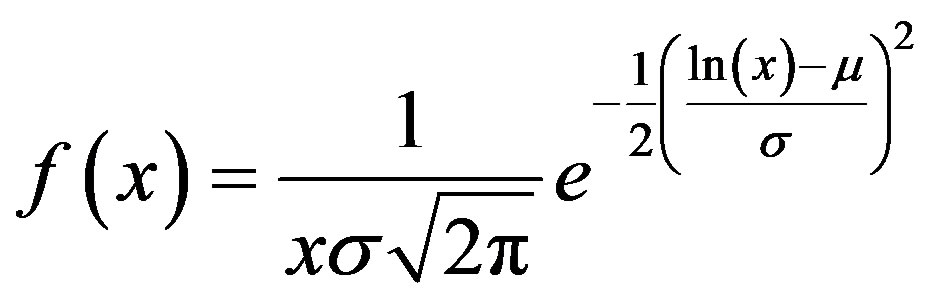
If X follows a lognormal distribution with parameters µ and σ, the natural logarithm of X (ln(X)) follows a normal distribution with parameters µ and σ and consequently, the variable  follows the standard normal distribution.
follows the standard normal distribution.
Given a certain sample we first estimate the values for parameters µ and σ of the lognormal distribution. For this, we only need the mean costs of the benefit and its standard deviation. We denote the mean costs by  and the standard deviation by S. Then the parameters µ and σ of the lognormal distribution are estimated as:
and the standard deviation by S. Then the parameters µ and σ of the lognormal distribution are estimated as:
2) 
3) 
Insurance companies commonly introduce thresholds and/or caps for reimbursement to assure their long-term survival. We can also calculate the expected pay-out by the insurer with a certain cap or threshold (or both), after we have estimated the parameters µ and σ. Subsequently,  ,
,  and
and  would be calculated as follows:
would be calculated as follows:
4)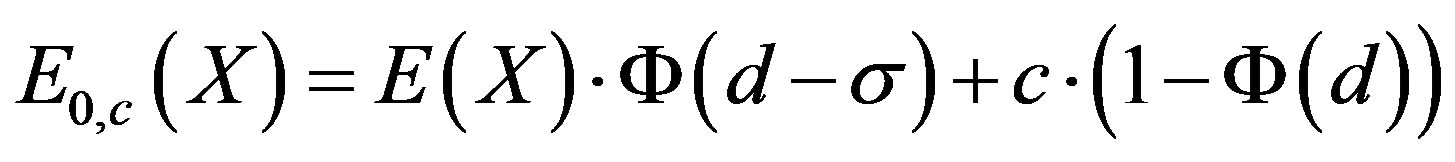 5)
5) 
where d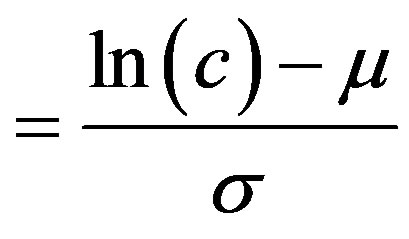 ,
,  and Φ(z) is the cumulative density function of the standard normal distribution [33] [34] .
and Φ(z) is the cumulative density function of the standard normal distribution [33] [34] .
In Formula (4), the first part equals the expected pay-out by the insurer when the costs of the insurance benefit was lower than the cap value; the second part equals the expected pay-out when the costs of the benefit was equal to the cap, or above it. The first part of Formula (5) equals the expected pay-out by the insurer when the benefit costs exceed the threshold. The second part of the formula equals the costs that are excluded from the insurance policy.
Subsequently we can calculate 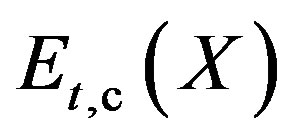 as:
as:
6) 
The design of an insurance product with a cap and/or threshold requires understanding of the quantitative consequences of these measures. We use two outcome measures to assess the quantitative consequences of caps and/or thresholds. The first is the percentage of the total costs that is reimbursed by the insurance (Formula (7)). This indicates the income required by the insurance company, assuming an actuarially fair premium, in order to break even.
7) Percentage of costs covered:
a) Situation with only a cap: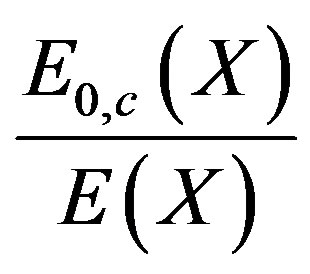 ;
;
b) Situation with only a threshold: ;
;
c) Situation with both a threshold and a cap: .
.
The second outcome measure is the percentage of bills covered by the insurance (i.e. percentage of bills below cap, above threshold and between threshold and cap in the situation with only a cap, only a threshold and both a threshold and a cap respectively, Formula (8)). This second outcome measure can serve as an indicator of the satisfaction of prospective clients.
8) Percentage of bills covered:
a) Situation with only a cap: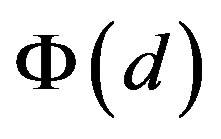 ;
;
b) Situation with only a threshold: ;
;
c) Situation with both a threshold and a cap: .
.
2.4. Analysis
The unit of analysis is individual cases of hospitalizations and tests.
The analysis is based on hospitalizations with non-zero costs (95% of all hospitalizations reported) as those are the ones relevant for insurance payouts. For the analysis of tests, all outpatient tests had costs and were included.
We used STATA version 11 and MS Excel (version 2010).
All amounts, reported in Indian Rupee (INR) during the surveys were converted into international dollars (purchasing power parity, PPP$) using the exchange rate of PPP$1 = INR 16.130 for the survey conducted in 2008, INR 16.692 for the 2009 survey and 18.073 for the 2010 survey [35] . The amounts reported in Nepalese Rupee (NPR) were converted into PPP$ using the exchange rate of PPP$1 = NPR 29.222 [35] .
3. Results
3.1. Socio-Economic Status of Studied Populations
The studied populations are characterized by low income and low educational levels (Table 1). The income-proxy of the population varies from PPP$ 1.0 to PPP$ 2.6 per person per day; and more than 40% of persons aged 15 years or more had no or very little education (below Class 5). At the same time, the percentage of people with higher education differed markedly across locations. Most people were engaged in self-employment in agriculture, daily wage labour and self-employment in business/trade.
3.2. Reported Costs for Hospitalizations and Tests
Information about expenditures for hospitalizations and tests is self-reported (Table 2). The incidence of hospitalizations ranges from 0.02 to 0.15, and for tests the range was between 0.02 and 0.10. The mean costs of hospitalizations and tests also differ markedly across the locations studied: a 6-fold difference in the mean costs of hospitalizations (from PPP$109 in Malkangiri to PPP$685 in Karimnagar) and a 5-fold difference in mean costs of tests (ranging from PPP$6 in Malkangiri to PPP$29 in Karimnagar). This large variation in healthcare costs across locations is in line with our previous findings in five other rural locations in India [16] .
In this study, we want to examine whether the distributions of costs, not just cost levels, differ across locations. This could be done when the mean of the distributions could be standardized while maintaining the shape of each distribution. We “standardized” the costs by dividing reported costs in each location by that location’s av

Table 1. Socio-economic profile of the studied populations.
aIncome is proxied as monthly per capita consumer expenditure through questions on many items of household expenditure and expressed in Purchasing Power Parity International Dollar.
Table 2. Socio-economic profile of the studied populations.
aPPP$ = Purchasing Power Parity International Dollar.
erage cost, obtaining the same mean cost of one in all locations, while the Coefficient of Variation (CV) of each distribution remained unchanged. These standardized distributions are shown in Figure 1 (for hospital expenditures) and in Figure 2 (for expenditures on tests).
To our surprise, the standardized distributions of hospital expenditures in the 11 locations were really similar; the same clear similarity across locations was also observed with the distributions of expenditures on tests.
We then proceeded to elaborate a model describing the best-fit for all distributions. It is recalled that previous research has successfully used the lognormal distribution as a good approximation for empirical distributions of

Figure 1. Distributions of hospital costs.
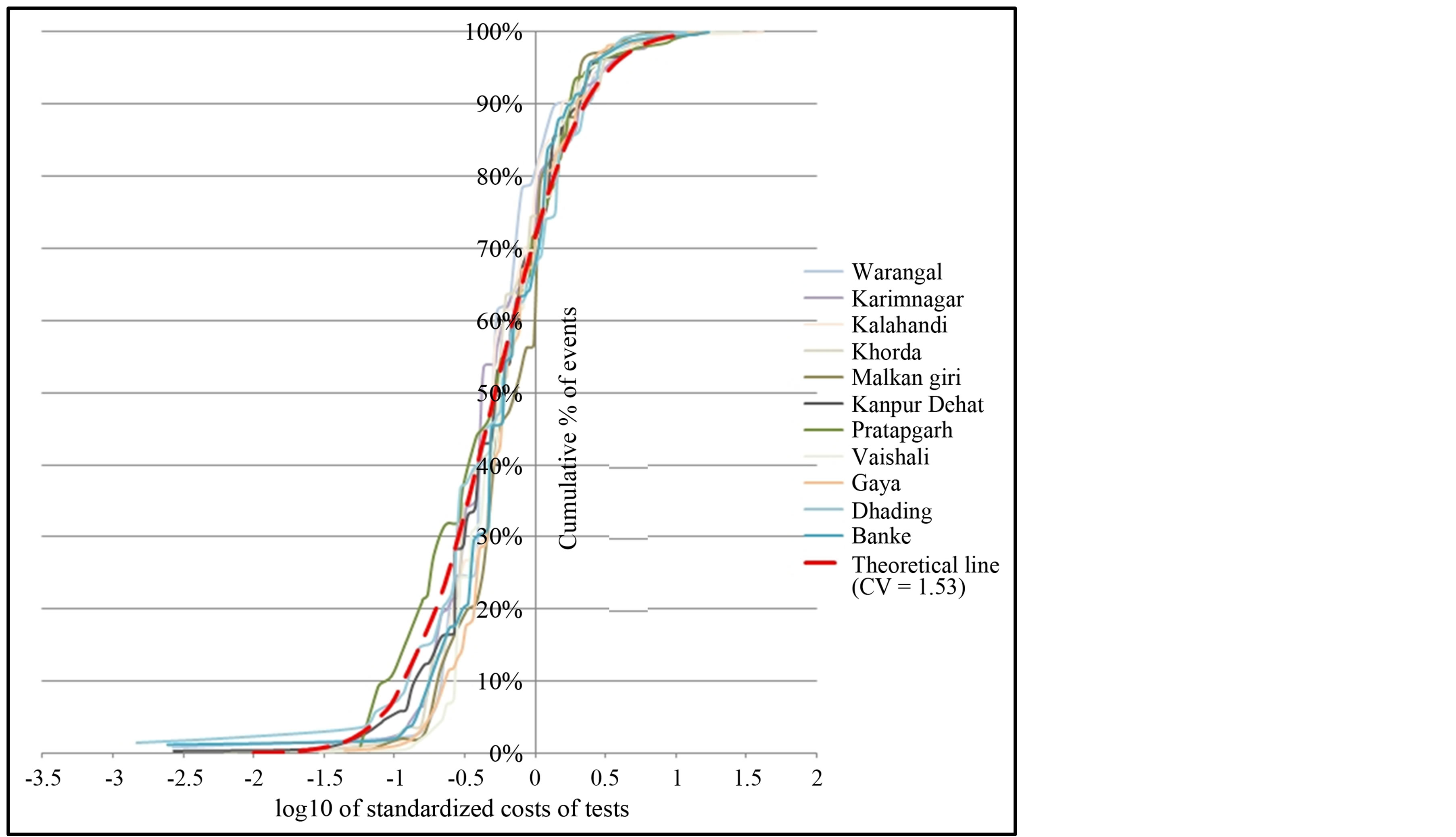
Figure 2. Distributions of costs on diagnostic tests.
healthcare costs [31] -[34] . We therefore created a theoretical lognormal curve (Equation (1)) with mean of one and a CV which is the arithmetic average for the 11 locations (1.65 for hospital costs and 1.53 for tests, Table 2). The resulting theoretical curve is plotted in Figure 1 for hospitalization expenditures and in Figure 2 for expenditures on tests.
3.3. Outcome Measures as Predicted by the Theoretical Model and Compared with Empirical Data
The model needs to predict the financial performance of CBHI schemes functioning with different levels of caps and thresholds. We observed the consequences of different levels of caps and thresholds on 1) the percentage of over all costs that the insurance would reimburse; and 2) the percentage of bills covered by the insurance.
As a reminder, all bills and all costs are reimbursable fully only when neither threshold nor cap apply. Moreover, most insured persons do not claim at all (and these would not be shown in the distributions); and many bills entail low costs, with only very few very high cost bills. Both a threshold and a cap will be effective in reducing the average reimbursement per insured. In many cases, the insurance product is limited both by a threshold and by a cap.
Tables 3 and 4 contain both the results obtained by applying our theoretical model and those obtained by applying the same caps/thresholds to the empirical data derived from the household surveys in all 11 locations. It should be noted that these caps/thresholds are per event (i.e. hospitalization or test).
We observe marked similarity between the theoretical model and the empirical data in the prediction of the percentage of total costs that the insurance needs to cover. For instance, when the cap is assumed to equal 100% of the mean, the predicted outcome was less than 10% different from the empirical outcome (“good agreement”) in 8 out of the 11 locations (Table 3). In two more examples (when the cap was assumed to be 0.5 times the mean, and when the cap was assumed to be 2 times the mean), we observed good agreement in 9 out of the 11 locations. And, the theoretical and empirical values were in good agreement in all locations when comparing the effect of introducing a threshold without a cap (two examples shown: thresholds of 10% or 20% of the mean).
A comparison of predicted versus empirical data on the % of bills also yielded a marked similarity when the caps were set at 100% or 200% of the mean (good agreement in 9 and 11 cases out of 11, respectively). On the other hand, the agreement was lower, with only 5 out of 11 locations in good agreement, when the cap was assumed to be 50% of the mean. With a threshold of 10% of the mean, 10 out of 11 cases were in good agreement and a threshold of 20% of the mean 7 out of 11 were in good agreement.
A similar pattern was observed when comparing the theoretical model with the empirical data relating to tests (Table 4).
4. Discussion
This article deals with developing a model to estimate insurance coverage under CBHI. If a threshold and/or a cap limits the payout of any benefit then the evaluation of coverage can be done only when the distribution of the expected costs is known. Because thresholds and caps are not rare but a standard feature of benefit packages, we are keen to develop a method to predict the distribution in each case. A predictive method has particularly important ramifications in the context of introducing health insurance to rural poor persons in low income countries, where data is usually missing and collection of the required data entails high cost, which often cannot be borne as part of implementation costs in these settings.
In this study, we examine the distributions of the costs of two benefits (hospitalizations and diagnostic tests) derived from eleven household surveys conducted prior to launching CBHI schemes (nine in India and two in Nepal). As the mean cost of the benefits differed significantly across the locations, we wished to study the shape of the distributions independently of the mean costs. The shape of the distribution is determined by the relative frequency of small bills versus high/outlier bills: for two data series with the same mean costs but with very different ratios of small bills to large bills, the consequences of applying the same threshold and/or cap could be completely different in terms of insurance coverage.
We were not surprised to find in this study large differences across locations in incidence/prevalence of illness, utilization of healthcare, its cost and different levels of WTP for health insurance (Table 2), as this corroborated previous relevant research [15] -[17] . On the other hand, when―in our search for a theoretical model of the distributions―we “standardized” the eleven data series by dividing costs reported in each location by that loca
Table 3. Theoretical model vs. empirical data for hospitalizations.