1. Introduction
The study of life length of organisms, structures, materials, etc., is very important in the biological and engineering sciences. A substantial part of such study is devoted to modeling the lifetime data by a failure distribution. The exponential, Rayleigh, and Weibull distributions are the most commonly used distributions in reliability and life testing. These distributions have several desirable properties and nice physical interpretations. Unfortunately, however, the exponential and Rayleigh distributions have constant and increasing failure rates, respectively. The Weibull distribution generalizes both these distributions which may have increasing, constant, or decreasing failure rates.
Multi-parameter distributions to model lifetime data have been introduced by compounding a continuous lifetime and power series distributions. The exponential geometric (EG), exponential Poisson (EP) and exponential logarithmic distributions were introduced and studied by (Adamidis and Loukas [1]), (Kus [2]) and (Tahmasbi and Rezaei [3]), respectively. Recently, (Chahkandi and Ganjali [4]) introduced the exponential power series (EPS) distributions, which contain these distributions.
Situations where the failure rate function decreases with time have been reported by several authors. Indicative examples are business mortality (Lomax [5]), failure in the air-conditioning equipment of a fleet of Boeing 720 aircrafts or in semiconductors from various lots combined (Proschan [6]) and the life of integrated circuit modules (Saunders and Myhre [7]). In general, a population is expected to exhibit decreasing failure rate (DFR) when its behavior over time is characterized by “work hardening” (in engineering terms) or “immunity” (in biological terms); sometimes the broader term “infant mortality” is used to denote the DFR phenomenon. The resulting improvement of reliability with time might have occurred by means of actual physical changes that caused self-improvement or simply it might have been due to population heterogeneity. Indeed, (Proschan [6]) provided that the DFR property is inherent to mixtures of distributions with constant failure rate (see also (McNolty et al. [8]) for other properties of exponential mixtures and (Gleser [9]) demonstrated the converse for any gamma distribution with shape parameter less than one. In addition, (Gurland and Sethuramm [10]) give examples illustrating that such results may hold for mixtures of distributions with rapidly increasing failure rate. A mixture of truncated geometric distribution and exponential with DFR was introduced by (Adamidis and Loukas [11]). The exponential-Poisson (EP) distribution was proposed by (Kus [2]), and generalized by (Hemmati et al. [12]) using Wiebull distribution and the exponential-logarithmic distribution was discussed by (Tahmasbi and Rezaei [3]). (Silvia et al. [13]) did a new distribution with decreasing, increasing and upside down bathtub failure rate. A twoparameter distribution family with decreasing failure rate arising by mixing power-series distribution has been introduced by (Chahkandi and Ganjali [4]). A Weibull power series class of distributions with Poisson was presented by (Morais and Barreto-Souza [14]). (Morais [15]) in a master degree thesis presented a class of generalized Beta distributions, Pareto power series and Weibull power series. Lately, (Alkarni and Oraby [16]) and (Alkarni [17]) obtained a class of truncated Poisson and logarithmic distributions with any continuous lifetime distribution.
A further exponentiated type distribution has been introduced and studied in the literature. The exponentialWeibull (EW) distribution was proposed by (Mudholkar and Srivastava [18]) to extend the GE distribution. This distribution was also studied by (Mudholkar et al. [19]), (Mudholkar and Hutson [20]) and (Nassar and Eissa [21]). (Nadarajah and Kotz [22]) introduced four more exponentiated type distributions: the exponentiated gamma, exponentiated Weibull, exponentiated Gumbel and exponentiated Fréchet distributions by generalizing the gamma, Weibull, Gumbel and Fréchet distributions in the same way that the GE distribution extends the exponential distribution. (Barreto-Souza and Cribari-Neto [23]) introduced the generalized exponential-Poisson distribution which extends the exponential-Poisson distribution in the same way that the GE distribution extends the exponential distribution.
In this paper we generalize the work of (Bakouchetal. [24]) to a class of several lifetime continuous distributions and hence any mixture of continuous lifetime with truncated binomial distribution such as exponential, Weibull, pareto becomes a special case of this class. This paper is organized as follow. In Section 2, the new class of binomial lifetime distributions with its probability and distribution functions is introduced. In Section 3, the corresponding survival and hazard rate functions with some of their properties are derived. In Section 4, maximum likelihood estimate of the unknown parameters is obtained based on a random sample via EM algorithm. In Section 5, the entropy for the binomial lifetime distributions class is discussed.
2. The Class
Given  let
let  be independent and identically distributed (iid) random variables with probability density function (pdf) given by
be independent and identically distributed (iid) random variables with probability density function (pdf) given by
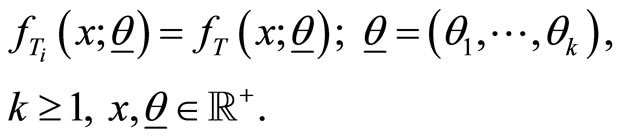
Here,  is a zero truncated binomial random variable with probability mass function given by
is a zero truncated binomial random variable with probability mass function given by
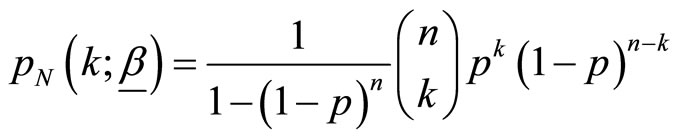
where  with
with ,
,  and
and 
 are independent. Let
are independent. Let  then, the pdf of the random variable
then, the pdf of the random variable  is obtained as
is obtained as
 (1)
(1)
And hence the cumulative distribution function (cdf) of  is
is
 (2)
(2)
The proof of the results in (1) and (2) are presented in the following theorem.
Theorem 2.1 Suppose  with
with
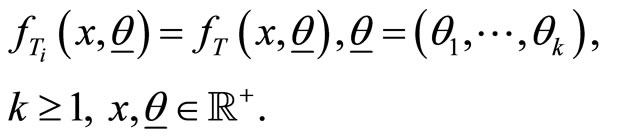
and  is a zero truncated binomial random variable with probability mass function
is a zero truncated binomial random variable with probability mass function
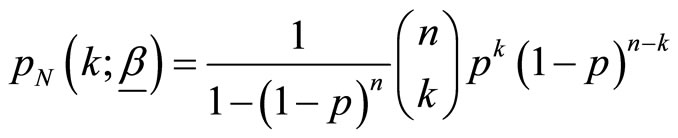
and  with
with  where
where  and
and  are independent. If
are independent. If  then the pdf and cdf of
then the pdf and cdf of  are
are
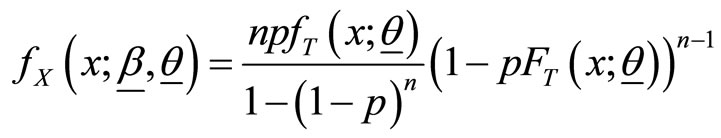
and
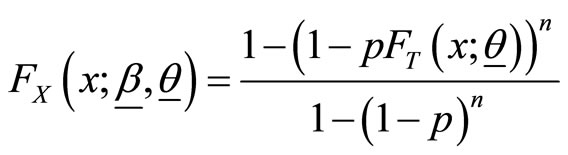
respectively.
Proof: By definition, the pdf of  given
given  is
is
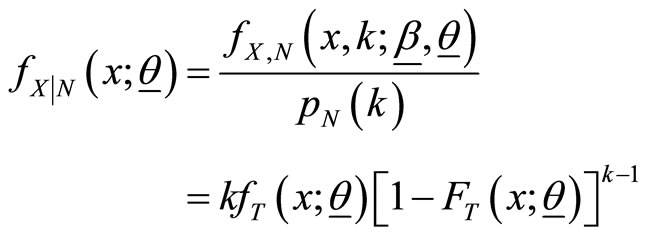
and hence the joint pdf of  and
and  is obtained as
is obtained as
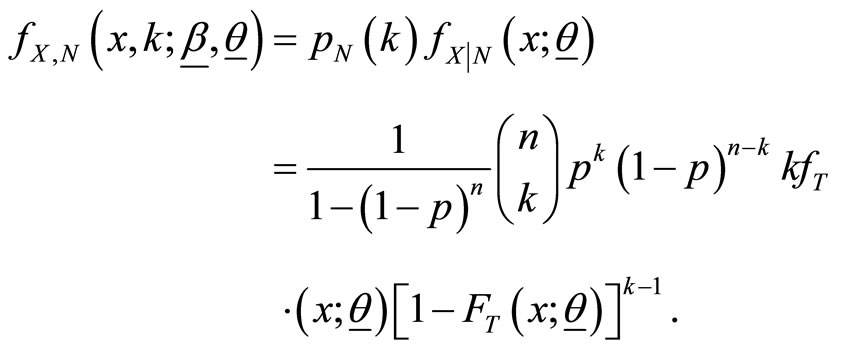
The marginal pdf and cdf of are given by
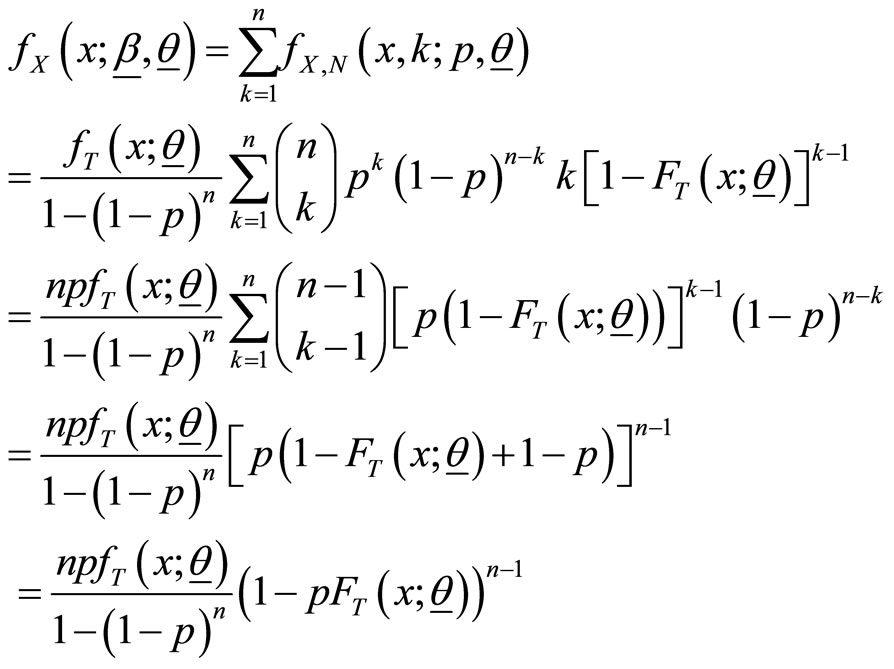
and
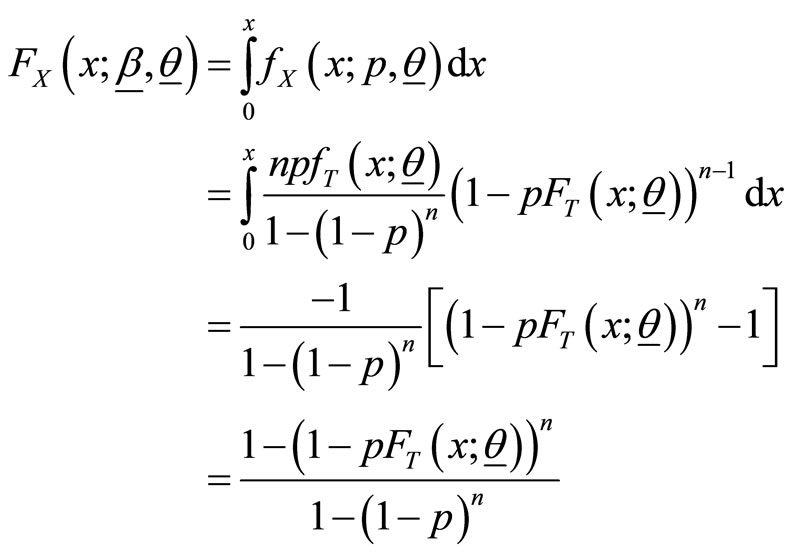
respectively.
We denote a random variable  with pdf and cdf (1) and (2) by
with pdf and cdf (1) and (2) by . This new class of distributions generalizes several distributions which have been introduced and studied in the literature. For instance using the probability density and its distribution function of exponential distribution in (1), we obtain the binomial exponential distribution (Bakouch et al. [24]) and using Wiebull probability density and its distribution function gives binomial Wiebull distribution (Morais and BarretoSouza ([14]). The model is obtained under the concept of population heterogeneity (through the process of compounding). An interpretation of the proposed model is as follows: a situation where failure (of a device for example) occurs due to the presence of an unknown number,
. This new class of distributions generalizes several distributions which have been introduced and studied in the literature. For instance using the probability density and its distribution function of exponential distribution in (1), we obtain the binomial exponential distribution (Bakouch et al. [24]) and using Wiebull probability density and its distribution function gives binomial Wiebull distribution (Morais and BarretoSouza ([14]). The model is obtained under the concept of population heterogeneity (through the process of compounding). An interpretation of the proposed model is as follows: a situation where failure (of a device for example) occurs due to the presence of an unknown number,  of initial defects of same kind (a number of semiconductors from a defective lot, for example). The Ts represent their lifetimes and each defect can be detected only after causing failure, in which case it is repaired perfectly (Adamidis and Loukas [1]). Then, the distributional assumptions given earlier lead to any of the BL distributions for modeling the time to the first failure
of initial defects of same kind (a number of semiconductors from a defective lot, for example). The Ts represent their lifetimes and each defect can be detected only after causing failure, in which case it is repaired perfectly (Adamidis and Loukas [1]). Then, the distributional assumptions given earlier lead to any of the BL distributions for modeling the time to the first failure .
.
Table 1 shows the probability function and the distribution function for some lifetime distributions.
Some lifetime distributions are excluded from this table such as Gamma and lognormal distribution stable since they do not have closed forms. They still can be applied in this class numerically.
The  quantile
quantile  of the BL distribution, the inverse of the distribution function
of the BL distribution, the inverse of the distribution function  is the same as the inverse of the distribution function
is the same as the inverse of the distribution function
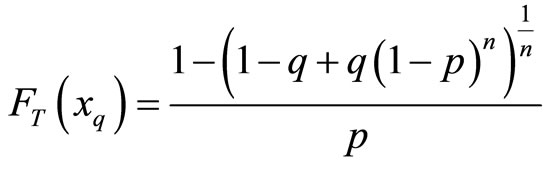
for any continuous lifetime with distribution function 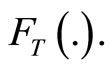
3. Survival and Hazard Functions
Since the BL is not part of the exponential family, there is no simple form for moments see for instant (Kus [2]) for the exponential case. Survival function (also known reliability function) (sf) and hazard function (known as failure rate function) (hf) for the BL class are given in the following theorem.
Theorem 3.1 Suppose that  with
with


Table 1. Probability and distribution functions.
and  is a zero truncated binomial random variable with probability mass function
is a zero truncated binomial random variable with probability mass function
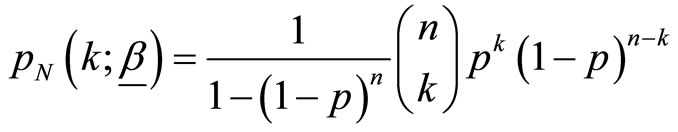
and 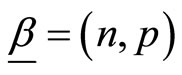 with
with  where
where  and
and  are independent. If
are independent. If  then the sf and hf of
then the sf and hf of  are
are
 , (3)
, (3)
and
 , (4)
, (4)
Respectively.
Proof: Using (1) and (2), survival function (also known reliability function) and hazard function (known as failure rate function) for the BL class are given respectively by
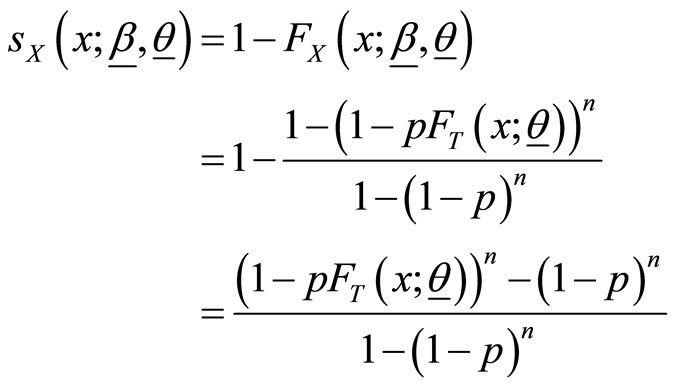
and

Table 2 summarizes the survival functions and hazard rate functions for some distributions of the class.
The hazard function for BL class is decreasing because the DFR property follows from the result of (Barlow et al. [25]) on mixtures.
4. Estimation
In what follows, we discuss the estimation of the BL class parameters. Let,  be a random sample with observed values
be a random sample with observed values  from a BL distributions with parameters
from a BL distributions with parameters  and
and . Let
. Let  be the parameters vector. The log-likelihood function based on the observed random sample size of
be the parameters vector. The log-likelihood function based on the observed random sample size of  is obtained by
is obtained by
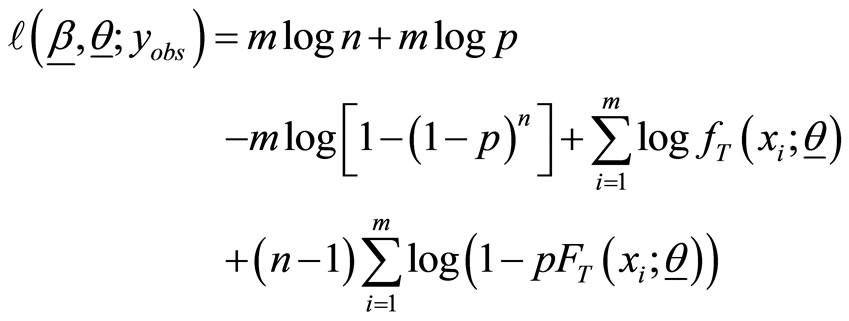
and the associated score function is given by
 where
where
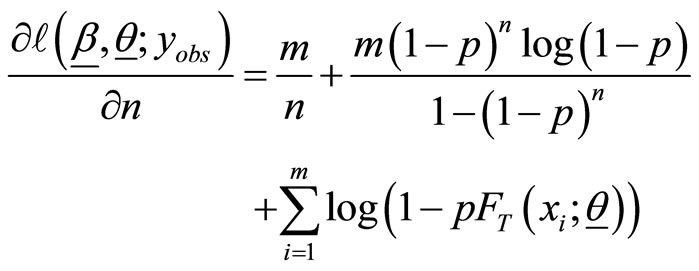 (5)
(5)
 (6)
(6)
and
 (7)
(7)
For 
The maximum likelihood estimates(MLE) of , say
, say , is obtained by solving the nonlinear system
, is obtained by solving the nonlinear system  The solution of this nonlinear system of equations has not a closed form, but can be found numerically by using software such as MATHEMATICA, MAPLE, Ox and R.
The solution of this nonlinear system of equations has not a closed form, but can be found numerically by using software such as MATHEMATICA, MAPLE, Ox and R.
For interval estimation and hypothesis tests on the model parameters, we require the information matrix. The  information matrix is
information matrix is  where the elements of
where the elements of  are the second partial derivatives of (5), (6) and (7). Under the regular conditions stated in (Cox and Hinkley [26]), that are fulfilled for our model whenever the parameters are in the interior of the parameter space, we have that the asymptotic distribution of
are the second partial derivatives of (5), (6) and (7). Under the regular conditions stated in (Cox and Hinkley [26]), that are fulfilled for our model whenever the parameters are in the interior of the parameter space, we have that the asymptotic distribution of  is multivariate normal
is multivariate normal
 , where
, where  is the unit information matrix.
is the unit information matrix.

Table 2. Survival and hazard functions.
EM Algorithm
Based on the underline distribution, the maximum likelihood estimation of the parameters can be found analytically using an EM algorithm. Newton-Raphson algorithm is one of the standard methods to determine the MLEs of the parameters. To employ the algorithm, second derivatives of the log-likelihood are required for all iteration. EM algorithm is a very powerful tool in handling the incomplete data problem (Dempster et al., [27]; McLachlan and Krishnan, [28]). It is an iterative method by repeatedly replacing the missing data with estimated values and updating the parameter estimates. It is especially useful if the complete data set is easy to analyze. As pointed out by (Little and Rubin [29]), the EM algorithm will converge reliably but rather slowly (as compared to the Newton-Raphson method) when the amount of information in the missing data is relatively large. Recently, EM algorithm has been used by several authors such as (Adamidis and Loukas [1]), (Adamidis [30]), (Ng et al. [31]), (Karlis [32]) and (Adamidis et al. [11]).
To estimate , EM algorithm is a recurrent method such that each step consists of an estimate of the expected value of a hypothetical random variable and later maximizes the log-likelihood of the complete data. Let the complete data be
, EM algorithm is a recurrent method such that each step consists of an estimate of the expected value of a hypothetical random variable and later maximizes the log-likelihood of the complete data. Let the complete data be  with observed values
with observed values  and the hypothetical random variable
and the hypothetical random variable . The joint probability function is such that the marginal density of
. The joint probability function is such that the marginal density of  is the likelihood of interest. Then, we define a hypothetical complete-data distribution for each
is the likelihood of interest. Then, we define a hypothetical complete-data distribution for each 
With a joint probability function in the form
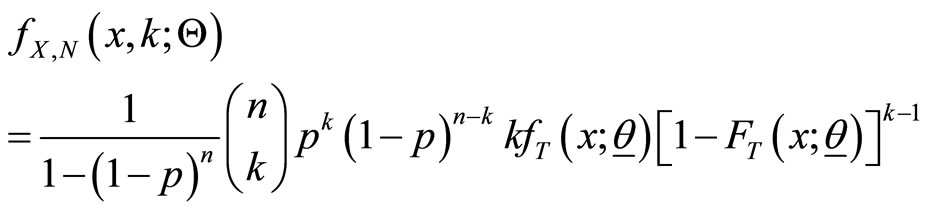
With  and
and . Thus, it is straight forward to verify that the E-step of an EM cycle requires the computation of the conditional expectation of
. Thus, it is straight forward to verify that the E-step of an EM cycle requires the computation of the conditional expectation of , where
, where  is the current estimate (in the rth iteration) of
is the current estimate (in the rth iteration) of . The EM cycle is completed with M-step, which is complete data maximum likelihood over
. The EM cycle is completed with M-step, which is complete data maximum likelihood over , with the missing N’s replaced by their conditional expectations
, with the missing N’s replaced by their conditional expectations  (Adamidis and Loukas [1]), where
(Adamidis and Loukas [1]), where
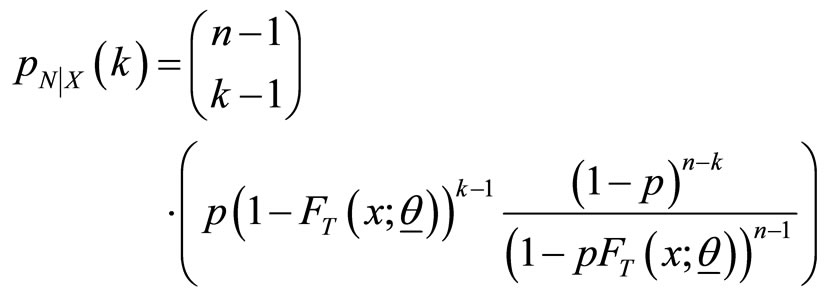
and its expected value is
 .
.
5. Entropy for the Class
If  is a random variable having an absolutely continuous cumulative distribution function
is a random variable having an absolutely continuous cumulative distribution function  and probability distribution function
and probability distribution function  then the basic uncertainty measure for distribution
then the basic uncertainty measure for distribution  (called the entropy of
(called the entropy of ) is defined as
) is defined as
 (8)
(8)
Statistical entropy is a probabilistic measure of uncertainty or ignorance about the outcome of a random experiment, and is a measure of a reduction in that uncertainty. Since Shannon’s [33] pioneering work on the mathematical theory of communication, entropy (8) has been used as a major tool in information theory and in almost every branch of science and engineering. Numerous entropy and information indices, among which there is the Renyi entropy, have been developed and used in various disciplines and contexts. Information theoretic principles and methods have become integral parts of probability and statistics and have been applied in various branches of statistics and related fields.
6. Acknowledgements
The author is highly grateful to the deanship of scientific research at King Saud University represented by the research center at college of business administration for supporting this research financially.