1. Introduction
Quantum coherence, together with the superposition principle, gives rise to the parallelism concept for which processing a single state is like acting simultaneously on all states that participate in the superposition [1,2]. It is also known that a key role in speeding up quantum algorithms is played by multi-particle entanglement [3]. These entanglement and parallelism concepts enable quantum algorithms such as Shor’s factoring, which provide options for very fast computers [4].
In addition, quantum superposition of coherence qubits has the advantage of maintaining enormous databases by a single state. It is shown that this superposition of qubits can be applied to an efficient database-finding algorithm and in particular the Grover algorithm that defines a possibility for an efficient search engine [5-7]. The advantage of using quantum memory is shown in [8-10] with the definition of a model for which binary pat- terns of n-bits are stored in the quantum superposition of the appropriate subset of the computational basis of n-qbits.
The grover algorithm divides the Hilbert space into two segments: the requested query (denoted by the state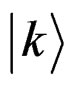 )
)
and all the other records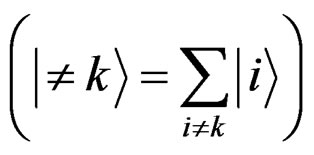 . The initial state is a maximal unsorted state
. The initial state is a maximal unsorted state 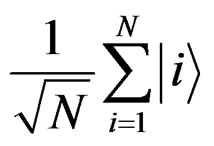 while the Grover Oracle is a unitary transformation (logical gate)
while the Grover Oracle is a unitary transformation (logical gate)
that rotates the unsorted state until after a relatively small number of iteration . The probability of detecting the requested query is almost one. Then, a measurement terminates a successful search.
. The probability of detecting the requested query is almost one. Then, a measurement terminates a successful search.
The selection of the 2-D basis  and
and  yields that each search has to be associated with an exclusive 2-D representation such that preparing the appropriate representation corresponds with a primary knowledge about the searched state. In that sense, the Grover algorithm is not a pure search algorithm. Actually, it’s more likely an “inverting a function” meaning that if we have a function
yields that each search has to be associated with an exclusive 2-D representation such that preparing the appropriate representation corresponds with a primary knowledge about the searched state. In that sense, the Grover algorithm is not a pure search algorithm. Actually, it’s more likely an “inverting a function” meaning that if we have a function  that can be evaluated on a quantum computer, this algorithm allows us to calculate
that can be evaluated on a quantum computer, this algorithm allows us to calculate  when given
when given  [11]. If we consider the
[11]. If we consider the  and
and  as vectors, the algorithm corresponds with rotating the
as vectors, the algorithm corresponds with rotating the  state with respect to the
state with respect to the  state. This is an equivalent way to represent the constrain of a primary knowledge concerning the searched state
state. This is an equivalent way to represent the constrain of a primary knowledge concerning the searched state  [12]. In order to overcome this obstacle, we introduce a parallel space (like another memory component) which is also spanned by the records states type
[12]. In order to overcome this obstacle, we introduce a parallel space (like another memory component) which is also spanned by the records states type  (the subscript
(the subscript  stand for the observer which determines the searched item) but unlike the register state (which belongs to what we refer to a r-space) that is occupied with the unsorted state, this o-space represents the observer search selection of a definite single record state, say,
stand for the observer which determines the searched item) but unlike the register state (which belongs to what we refer to a r-space) that is occupied with the unsorted state, this o-space represents the observer search selection of a definite single record state, say, . Thus, eventually, the searched item is well defined but only among the observer parallel space and definitely not to the other search component. We will present a scheme which shows that by correlating the observer state with the unsorted state, the later will be represented in the appropriate 2D representation. Once the unsorted state is prepared, we introduce a rapid search algorithm.
. Thus, eventually, the searched item is well defined but only among the observer parallel space and definitely not to the other search component. We will present a scheme which shows that by correlating the observer state with the unsorted state, the later will be represented in the appropriate 2D representation. Once the unsorted state is prepared, we introduce a rapid search algorithm.
2. Concepts Formulation
Searching a record corresponds with introducing the search machine with a query. A successful search ends with the presentation of the related data. In our approach the query is introduced thorough a state while the related data output is associated with an operator-eigenvalues rather than eigenstates.
To be more specific, suppose that the search machine possesses N states  where each state presents a possible query. The measurement output is associated with the projective operator:
where each state presents a possible query. The measurement output is associated with the projective operator:
 (1)
(1)
with the corresponding eigenvalues .
.
A measurement result is the readable content, namely the eigenvalues rather than the eigenstates. Therefore, we propose that while the query request is introduced through a state, the relevant record information is expressed through the eigenvalues.
There are few possibilities to represent a data. It can be presented numerically or through a string of symbols. Indeed the current mathematical formulation allows us to introduce a symbolic eigenvalues-eigensymbols, that is, a string of symbols instead of a numeric value as shown in the following example:
Suppose that we search for information concerning Albert Einstein from an N number of records. The request is then coded into a state . We can present the 2D-projective-operator:
. We can present the 2D-projective-operator:
 (2)
(2)
If  is the input state then the result will be the
is the input state then the result will be the
 , that is
, that is
 (3)
(3)
All other states of the orthogonal basis,  , will yields the string
, will yields the string :
:
 (4)
(4)
Note that this mathematical formalism allows us to present the output with many ways. For example the output can be a link to a relevant computer site. For that case the link can be represented by a Links-Operator-  such that:
such that:
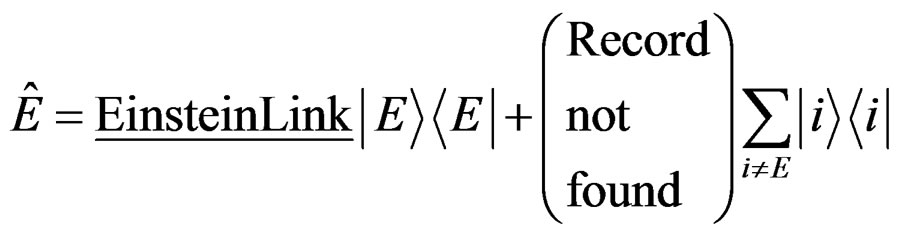 (5)
(5)
If the observer query is , then we obtain
, then we obtain
 (6)
(6)
Once the machine recognize the  state it activates the link operator
state it activates the link operator  to present or link to the relevant site. For other cases the observer receive the text massage “Record not found”.
to present or link to the relevant site. For other cases the observer receive the text massage “Record not found”.
3. The Machine Processor
3.1. The Observer Input
As in the grover algorithm [6] the register is occupied with an  unsorted records state:
unsorted records state:
 (7)
(7)
where states that are related to the register component are denoted by the subscript .
.
The Grover search algorithm shrinks the  -records basis into a 2-D space, spanned by the states
-records basis into a 2-D space, spanned by the states —the state under the search and the state
—the state under the search and the state —a superposition of all the other states. Consequently each search is associated with an exclusive 2-D representation such that preparing the appropriate representation corresponds with a primary knowledge about the searched state. In that sense the Grover algorithm is not a pure search algorithm. Actually it more accurate to describe the Grover algorithm as “inverting a function” meaning that if we have a function y = f(x) that can be evaluated on a quantum computer, this algorithm allows us to calculate x when given y [11].
—a superposition of all the other states. Consequently each search is associated with an exclusive 2-D representation such that preparing the appropriate representation corresponds with a primary knowledge about the searched state. In that sense the Grover algorithm is not a pure search algorithm. Actually it more accurate to describe the Grover algorithm as “inverting a function” meaning that if we have a function y = f(x) that can be evaluated on a quantum computer, this algorithm allows us to calculate x when given y [11].
If we consider the  and
and  as vectors, the algorithm corresponds with rotating the
as vectors, the algorithm corresponds with rotating the  state with respect to the
state with respect to the 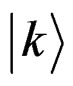 state. This is an equivalent way to represent the constrain of a primary knowledge concerning the searched state
state. This is an equivalent way to represent the constrain of a primary knowledge concerning the searched state 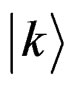 as nicely described in ref. [12]:
as nicely described in ref. [12]:
“Each Classical Walk step is almost Target-blind; meaning that it does not depend on what the searched target is, except in deciding whether to stop or go on with the search. It’s as if we were moving from some original binary code 0000 to the searched target in a dark room, taking small blind steps, until we hit the target. Once we hit the target, we recognize it as such and stop.
Now note that each Grover step is NOT an almost Target-blind; in fact, each Grover step is a rotation by a small angle 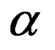 in the plane that contains the unsorted state vector
in the plane that contains the unsorted state vector  and the target state
and the target state , where
, where  depends on the angle between
depends on the angle between  and
and . So the Grover steps are not almost Target-blind. Far from it.”
. So the Grover steps are not almost Target-blind. Far from it.”
As mentioned before, transforming the algorithm into a real search engine corresponds with introducing a parallel space, that is, an additional memory component. Likewise the records space it is spanned by the records states type  (the subscript
(the subscript  stand for the observer which determine the searched item) but unlike the rspace, this o-space represents the observer search selection of a definite single record state
stand for the observer which determine the searched item) but unlike the rspace, this o-space represents the observer search selection of a definite single record state . Thus, eventually, the searched item is well know but only in the observer parallel space and definitely not by the other search component.
. Thus, eventually, the searched item is well know but only in the observer parallel space and definitely not by the other search component.
Suppose that by searching a  -record, the observer defines the state
-record, the observer defines the state . The searching machine first step is to correlate between the observer state
. The searching machine first step is to correlate between the observer state  with the processor unsorted state
with the processor unsorted state  yielding:
yielding:
 (8)
(8)
with  being the unsorted state of Equation (7).
being the unsorted state of Equation (7).
Assuming that the machine processor is fed with the observer selection. In response the machine processor exhibit the register state of Equation (7) in the associated representation:
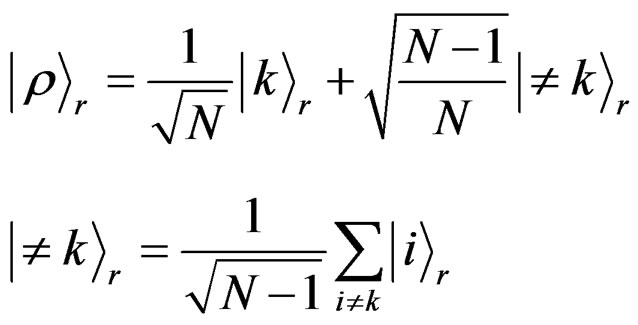 (9)
(9)
We refer this representation as the k-basis-representation. The question we address is how does the observer  -selection can be followed by the r-space such that the unsorted state
-selection can be followed by the r-space such that the unsorted state  will be represented by the
will be represented by the  - basis?
- basis?
Suppose that  is the operator that operates within the
is the operator that operates within the  -space and can be coupled to any observer selection
-space and can be coupled to any observer selection . Clearly there are
. Clearly there are  operators of the kind. The global processor task is to associate each operator with its compatible
operators of the kind. The global processor task is to associate each operator with its compatible  -state. This operation is activated by the following
-state. This operation is activated by the following  -operator:
-operator:
 (10)
(10)
Once the observer select his query, say, the state  and after the states are correlated as shown in Equation (8), the processor operation provides us with the output:
and after the states are correlated as shown in Equation (8), the processor operation provides us with the output:
 (11)
(11)
meaning that among all other possibilities the r-processor is now operating within the 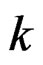 -representation only. We note that
-representation only. We note that  can be regarded as an “eigenoperator” [13,14].
can be regarded as an “eigenoperator” [13,14].
3.2. The  Operator
Operator
A simple measurement of the record k can be represented with the following projective operator:
 (12)
(12)
Applying the operator  on the unsorted state
on the unsorted state 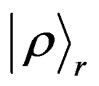 (see Equation (9)) and considering this operation by means of conducting a macroscopic measurement, we will probably obtain a
(see Equation (9)) and considering this operation by means of conducting a macroscopic measurement, we will probably obtain a 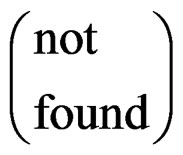 output and consequently the remaining state will be the
output and consequently the remaining state will be the  -state. Therefore in order to improve the odds of detecting the required
-state. Therefore in order to improve the odds of detecting the required  associated data, we apply the Pauli gate that switches between the
associated data, we apply the Pauli gate that switches between the 
 -states while leaving the “eigensymbols” unchanged.
-states while leaving the “eigensymbols” unchanged.
This improved operator is:
 (13)
(13)
where the Pauli gate is
 (14)
(14)
This yields:
 (15)
(15)
This eigenstates switching causes the high probability state  to possess the required eigensymbol data
to possess the required eigensymbol data
 with the high probability
with the high probability . Thusnot only we defined a pure searching algorithm by defining the observer query separately from the search engine, we also introduced a very rapid algorithm which composed mainly of two steps: The Pauli gate and a macroscopic measurement.
. Thusnot only we defined a pure searching algorithm by defining the observer query separately from the search engine, we also introduced a very rapid algorithm which composed mainly of two steps: The Pauli gate and a macroscopic measurement.
4. Summary
We summarize this paper with the following flowchart that shows our proposed algorithm:
