Partial Time-Varying Coefficient Regression and Autoregressive Mixed Model ()
1. Introduction
Regression and autoregressive mixed models are widely used tools to study the correlation between random indicators of time series types and their influencing factors. The expression of the model is
(1)
where time series
,
, is the dependent variable; time series
, represents s covariates; with
as their regression coefficients;
is the intercept term;
, represents p autoregressive coefficients and satisfies stationary conditions; and
is a white noise series, which is independent of both the covariates
and response variable
. Model (1) has been studied extensively in classical textbooks [1] [2] . Model (1) can also be regarded as a special case of an autoregressive model with exogenous variables or an autoregressive distributed lag model [3] , which has a wide range of applications in finance, econometrics and biomedicine.
The unknown parameters in model (1) are assumed to be constant, indicating that the effects between the dependent variable and the covariates will not change with the observation time. However, in practice, complex nonlinear correlations between dependent variable and covariates are sometimes encountered. The varying-coefficient (or functional coefficient) time series model is an effective tool to handle data with such characteristics. The so-called varying-coefficient is that the parameters in the model are not constants but functions of some variables such as observation time or some delay components of time series. If the expression of the coefficient function in the model is known, it is called a parametric varying-coefficient model. Otherwise, it is a nonparametric model. It is well known that a parametric model will fit better than a nonparametric model if the coefficient function is known. However, if we make a mistake in the expression of the coefficient function, then it will cause serious deviations in the estimation and even result in misleading outcomes. In this case, the nonparametric model has more advantages. Nonparametric varying-coefficient models in time series were studied extensively, see [4] - [16] . In addition, there is a long history of models in the Bayesian realm to track the issue, where the time-variability of coefficients is (semi-) automatically shrunk to constancy in various ways [17] [18] [19] .
It is noted that many scholars have carried out research on model extension for the time-varying coefficient model (i.e., coefficients are functions of time) proposed by Robinson [4] , see [20] - [29] . Since the model in Robinson [4] is the basis of many studies and the model proposed in this article is an extension of the time-varying coefficient model of Robinson [4] and Cai [9] , we first give the model expression:
(2)
where time series
is the dependent variable; time series
, represent d covariates;
,
, are
coefficient functions of observation time whose form are completely unknown and satisfy a certain degree of smoothness; and
is an i.i.d (independent and identical distribution) series and is independent of
. It should be noted that the independent variable of the coefficient function is
instead of i. This is a constraint that we need to satisfy when deducing large-sample properties of nonparametric smooth estimators of coefficients in a time-varying coefficient model, and the specific reasons can be seen in [4] [5] [9] .
To avoid the “curse of dimensionality”, many researchers have studied nonparametric estimation methods for varying-coefficient models. For example, Robinson [4] proposed a pseudo-local maximum likelihood estimation method to study the local estimates of functional coefficients in the time-varying coefficient time series model (2). Chen and Tsay [6] and Hastie and Tibshirani [30] proposed a kernel smooth nonparametric estimation method for functional coefficients in autoregressive models. Ramsay and Silverman [31] and Brumback and Rice [32] estimated the parameters of the varying-coefficient regression model by using the B-spline method. Cai et al. [8] studied local polynomial estimates for functional-coefficient regression models. Huang et al. [33] proposed a B-spline estimation for a varying-coefficient regression model based on repeated measures data. Aneiros-Perez and Vieu [34] used Nadaraya-Watson-type weights to estimate the semi-functional partial linear regression model (SFPLR model) and derived the corresponding asymptotic properties of the estimators. Li et al. [20] and Fan et al. [22] applied local polynomial expansion techniques to explore parameter estimation for time series models with partial time dependencies. Liu et al. [10] used a local linear approach to estimate the nonparametric trend and seasonal effect functions. Cai et al. [11] adopted a nonparametric generalized method of moments to estimate a new class of semiparametric dynamic panel data models. Chen et al. [23] applied a local linear method with cross-validation bandwidth selection to estimate the time-varying coefficients of the heterogeneous autoregressive model. By combining B-spline smoothing and the local linear method, Hu et al. [27] proposed a two-step estimation method for a time-varying additive model. Tu and Wang [14] applied adaptive kernel weighted least squares to estimate functional coefficient cointegration models. Li et al. [28] used classical kernel smoothing methods to estimate the coefficient functions in nonlinear cointegrating models. Karmakar et al. [29] applied local linear M-estimation to estimate the time-varying coefficients of a general class of nonstationary time series, among others.
For time series data with complex correlations between sample components, sometimes neither the constant coefficient regression and autoregressive mixed model (1) nor the time-varying coefficient regression model (2) can fit the data well. Motivated by this, in this article, we introduce the idea of a time-varying coefficient into a simple mixed model (1) and propose a partial time-varying coefficient regression and autoregressive mixed model. The proposed model can not only estimate the constant effects of some covariates on the dependent variable but also characterize the non-constant effects of other covariates, which greatly increases the flexibility and scope of the models (1) and (2). To the best of our knowledge, explicitly introducing part of the delay terms of the dependent variable into time-varying regression models as covariates is less actively studied. However, for time series with a strong correlation between components, sometimes introducing the delay term of the dependent variable as part of covariates can make full use of the data information and improve the model fitting degree. We will study this problem from the way of Cai [9] in this article, although the Bayesian parallel stream can be incorporated and put into perspective.
The remaining parts of this article are organized as follows. In Section 2, we introduce a partial time-varying coefficient regression and autoregressive mixed model, give the estimation method of model parameters and derive the large sample properties of the proposed estimators. We conduct a simulation study in Section 3 to examine the finite-sample performances of the proposed estimators. In Section 4, we use Shasta Lake inflow data to illustrate the application value of the model. Finally, we conclude with a discussion in Section 5.
2. Model and Estimation
2.1. Proposed Model
As mentioned in Section 1, many researchers have studied different types of varying-coefficient regression models, but research on partial time-varying coefficient regression and autoregressive mixed models is less actively studied. To fill this gap and study the correlation effects of dependent variables with covariates and delay components of partial dependent variables, we propose the following partial time-varying coefficient regression and autoregressive mixed model:
(3)
where
with the superscript T as transposition,
with
,
,
,
,
,
,
,
with
as a permutation of time indicator
. For the convenience of derivation, in this article, we set
to be the order from 1 to
;
and
represent the number of regression covariates and the order of autoregression, respectively; and
is assumed to be a white noise series. Model (3) is an iterative formula for the sequence
. To make the time series
have a solution, certain constraints on the model parameters should be made, such as the autoregressive coefficient satisfies the stationary condition and
when
. Since the autoregressive coefficients in model (3) are not necessarily constant, the corresponding constraints are stricter; for example, the time series in the model satisfies the α-mixing condition. We will give the conditions that need to be satisfied in Section 2.3.
Model (3) enhances the generalizability of time series regression models and contains many existing statistical models as specials. For example, when
,
,
, model (3) is the traditional linear regression model; when
,
,
, model (3) reduces to the time-varying coefficient linear regression model; when
,
, model (3) is a partial time-varying coefficient linear regression model; when
,
,
, model (3) is the autoregressive time series model; when
,
,
, model (3) is the time-varying coefficient autoregressive time series model; when
,
, model (3) becomes the traditional constant coefficient regression and autoregressive mixed model.
Model (3) is a semi-parametric model since some of its parameters are unknown functions, and we need to apply non-parametric estimation methods, such as local polynomial expansion methods [35] and spline techniques [36] . In this article, we combine the local polynomial expansion technique with the least squares estimation method to estimate unknown model parameters.
2.2. Estimation Method
First, we briefly introduce the local polynomial expansion method. The main idea of this method is that for a function whose form is completely unknown but satisfies certain smoothness conditions at a fixed local point, we apply Taylor expansion to approximate the function as a polynomial about the local point. By using this method, the estimation of the function can be transformed into a parameter estimation problem of local polynomial coefficients. In this article, we elucidate the estimation method by using the first-order Taylor expansion. The higher-order Taylor expansion only increases the number of parameters to be estimated, and there is no essential difference in the algorithm. Specifically, the coefficient functions
and
in model (3) are assumed to have a second continuous derivative, denoted as
,
,
and
, respectively.
, by Taylor expansion, we have
Then, in the local neighborhood of
, model (3) can be approximated as follows:
where
and
We can obtain a locally weighted least squares estimate of the coefficient function in the model (3) by taking the minimum of the weighted sum of squared errors as follows:
where
is the kernel function, 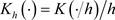 , and h is the bandwidth. Using the least squares estimation theory, it is not difficult to obtain the estimation of parameter
, denoted as
, which has the following expression:
, and h is the bandwidth. Using the least squares estimation theory, it is not difficult to obtain the estimation of parameter
, denoted as
, which has the following expression:
(4)
where
,
, and
is a
matrix with the kth row as
.
For the residual term
in model (3), its variance can be estimated locally as:
2.3. Asymptotic Normality
For the convenience of description, we introduce the following definitions and notations. Let
be a diagonal matrix of order
; the first
elements on the main diagonal are 1, and the other
elements of the main diagonal are h. Let
,
for
. Denote
,
,
and
,
,
. Define
where
, and the definition of
is provided in the Appendix.
Throughout the derivation, we impose the following conditions:
C1 The measurable functions
and
have second continuous derivatives in the interval
.
C2 The kernel function
is symmetrically bounded and has a compact support on the interval
.
C3
is a strictly stationary α-mixing process, there exists 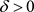 such that
, and the mixing coefficient
, where
.
such that
, and the mixing coefficient
, where
.
C4 The bandwidth satisfies
.
C5 For
, the matrix
is full rank.
C6 For
, the matrix
is positively definite.
Note that C1, C2 and C4 are the conditions that the local polynomial expansion method needs to satisfy, C3 is the condition required for the moment of random variables, and C5 and C6 are requirements to be satisfied by the large sample properties of the estimators. Conditions C1-C4 are similar to those in Robinson [4] and Cai [9] .
Theorem 1. Under Conditions C1-C6, when
and
, we have
where
and
,
.
Therefore, we obtain
where
and
.
In practice, the variance-covariance matrix of
can be calculated by using the following formula:
(5)
where
and
, are residuals of model (3). The proof of Theorem 1 is provided in the Appendix.
For constant coefficients in the model (3), the corresponding estimators obtained from (4) are not
consistent. To improve its convergence rate, we use the following formula (6) to obtain a global estimator, that is,
(6)
where the weight matrix
satisfies
, and
is an identity matrix. Typically, we choose
to be the standardized inverse covariance matrix [37] of
and
, which can be obtained from (5). Then, the finite sample variances of the global estimators
can be calculated by the following formula (7):
(7)
where
is a
matrix with
as the
th element of
; furthermore,
for
,
; otherwise,
. Definitions of
and
can be seen in the Appendix.
2.4. Selection Best Bandwidth and Order
When using estimator (4) to obtain
, bandwidth h and order p (
) must be determined. Cheng et al. [26] proposed a Bayesian approach to determine bandwidth selection for local constant estimators of time-varying coefficients, Chen et al. [23] applied the cross-validation (CV) bandwidth selection to estimate the time-varying coefficient heterogeneous autoregressive model. Inspired by the idea of the average mean squared (AMS) criterion proposed by Cai et al. [8] , we slightly modify this criterion to simultaneously select the best bandwidth h and the optimal order p of model (3). The procedure is as follows: First, we divide the sample data into m groups and denote the sample size of the qth group as
,
. Second, given the values of h and p, and based on data of removing the qth group, we estimate
by using (4), denoted as
. Third, we calculate the estimated mean square error for sample data of the qth group, denoted as
, and then we obtain the total mean squared error when q goes from 1 to m. Finally, the optimal h (i.e.,
) and p (i.e.,
) that minimize the (AMS) error has the following form:
where for
,
Note that in the second step, except for all covariates of
and
, we can also try to use subsets of
and
in
when we estimate
by using (4). Obviously, different subsets of covariates of
may result in different best combinations of h and p, and we take the combination of h and p corresponding to the minimum value of AMS for all subsets of covariates of interest as the optimal bandwidth and the order of the autoregressive part. Therefore, AMS can also be used to conduct variable selection of model (3).
3. Simulation Studies
We perform simulation studies to examine the finite-sample performances of the proposed estimators and consider the following partial time-varying coefficient regression and autoregressive mixed model:
(8)
where
,
,
,
;
follows the autoregressive moving average model with
and
, i.e., ARMA(1,1); and
is an autoregressive (AR) model of order 1, i.e., AR(1). Typically,
and
. Both
and
are standard white noise series with mean 0 and variance 1, i.e.,
and
. Also,
and that is independent of both
and
. We run 500 Monte Carlo simulations for 9 grid points at
in the time interval
and examine the average of 500 simulations of the parameters in model (8) at these 9 points. We apply the Gaussian kernel function with standard error 2 to the estimation of
. Once
is obtained by (4), then
is immediately known and its variance estimation can be calculated by (5). For constant parameter vector
and
, we obtain their global estimators
and
by using formula (6), and compute the corresponding variance estimation of
and
by (7). For each simulation, we consider the sample size as
and
, respectively. According to simulation results under sample size 300 and 800, we find that estimation results are good when bandwidth is between 0.02 and 0.08. Thus, three bandwidths of h are chosen, that is,
and 0.07. Finally, we report the following quantities under each h and n for
in Table 1 & Table 2: Monte Carlo average estimators of
, Monte Carlo standard deviation of estimates (ESD), Monte Carlo average of estimated standard errors (ASE) and coverage probability of nominal 95% confidence intervals (CP).
![]()
Table 1. Estimation results for time-varying coefficient
and
under different scenarios.
Table 1 shows that both estimators of
and
are approximate to their true values. The ASEs are close to the ESDs, which demonstrates the good performance of the variance estimation by Theorem 1. 95% confidence interval coverage probabilities are reasonably accurate, matching the nominal level. According to the estimation results from Table 2, biases of
and
can be ignored, ASEs are still approximate to the ESDs and CPs of both estimators are close to 95%, which means good variance estimation of global estimators
and
. Furthermore, when bandwidth h increases from 0.03 to 0.07, as expected, biases of
and
tend to be larger, and corresponding ASEs and ESDs tend to be smaller. When the sample size n increases from 300 to 800, the ASEs and ESDs of all estimators decrease, which indicates that increasing the sample size can improve our proposed estimators.
Figure 1 & Figure 2 present the true and estimated time-varying coefficients
![]()
Table 2. Estimation results for constant coefficients
and
under different scenarios.
![]()
Figure 1. Estimated curves of
with bandwidth
. (a) Sample size
; (b) sample size
. The solid lines are the true functions of
, the dashed lines are the estimates of
, and the dash-dotted lines are the 95% confidence intervals.
![]()
Figure 2. Estimated curves of
with bandwidth
. (a) sample size
; (b) sample size
. The solid lines are the true functions of
, the dashed lines are the estimates of
, and the dash-dotted lines are the 95% confidence intervals.
of model (8) as well as 95% pointwise confidence intervals. It can be intuitively seen that the estimated curves of
and
are very close to the true curves, which again confirms the good performance of our proposed estimators.
4. Real Data Analysis
In this Section, we use Lake Shasta inflow data [38] to illustrate the application value of our proposed model. The data includes 454 months of measured values for several climatic variables: air temperature (Temp), dew point (DewPt), cloud cover (CldCvr), wind speed (WndSpd), precipitation (Precip), and inflow (Inflow) at Lake Shasta, California, USA. We are interested in building models to predict Lake Shasta inflow based on these climate variables. We treat the lake water inflow (Inflow) as a time series, but it has both autocorrelation and heteroscedasticity through the Box-Ljung autocorrelation test and Lagrange Multiplier test. We let the dependent variable be the inflow of lake water. According to the suggestion by Shumway and Stoffer [38] , it is better to model this variable after logarithmic transformation. Therefore, we set
and then use the proposed partial time-varying coefficient regression and autoregressive mixed model (3) to model the relationship between inflows and the other five climate variables.
Before using (4) to obtain estimators, we need to determine the optimal bandwidth h, the autoregressive order p and which covariates have time-varying coefficient effects as well as which covariates have constant coefficient effects. In other words, we need to conduct variable selection. As we mentioned in Section 2.4, the criterion AMS can not only determine the optimal bandwidth h and the autoregressive order p, but also conduct variable selection. In this analysis, when choosing a combination of covariates, i.e., which variables should be put into
and which variables are put into
, as well as which lag terms of the dependent variable are put into
and
, respectively, one rule we follow is that the vectors
and
cannot be empty simultaneously. Otherwise, model (3) will reduce to the traditional regression and autoregressive mixed model. The autoregressive order p we consider starts at 1 and increases sequentially. A rough criterion for p is that there is no autocorrelation and heteroscedasticity in the residuals of the model. When p is given, we determine the optimal combination of bandwidth h with a combination of covariates according to the value of AMS. If the estimator of a constant effect covariate selected by the AMS is insignificant, then we delete this covariate and calculate AMS again. By using this strategy, we can guarantee that all covariates with constant coefficients selected by the AMS are significant.
The procedure of using the proposed model to analyze real data is as follows: First, we let Temp, DewPt, CldCvr, WndSpd and Precip be five candidate covariates. When calculating AMS, according to the suggestion of Cai et al. [8] , we choose
and
, where [ ] denotes a rounding function, and the optimal bandwidth satisfies
. Since the sample size of Shasta Lake inflow data is 454, we set the selection range of bandwidth h from 0.08 to 0.50. Combined with other rules mentioned in the previous paragraph, that is, the
and
cannot be empty simultaneously, the estimation for covariates selected by the model with constant coefficients should be significant. Then, we consider that model (3) contains only 1, 2, 3, 4 and 5 of the candidate covariates and calculate the corresponding values of AMS based on given p and h. Next, by comparing AMS under all various combinations, we find the minimum value of AMS occurring at
,
, and the covariate combination is
,
,
and
. Thus,
. Figure 3(a) shows the AMS changes with different h under this combination in model (3).
Therefore, the final model to be estimated is:
(9)
where
. Once
,
,
and
are determined, we then use (4) to obtain local estimators and (6) to get global estimators of constant coefficients. To evaluate the prediction performance of model (9), we use the first 451 sample data to estimate the unknown parameters and obtain
. The estimated time-varying coefficients
,
,
,
and
are presented in Figure 3(b), and the estimated constant coefficients
and
are reported in Table 3. Interestingly, considering the time-varying coefficient estimation results, it seems that the prediction
![]()
Figure 3. (a) AMS results under different bandwidths h for model (9); (b) time-varying coefficient estimation results of model (9).
![]()
Table 3. Constant coefficient estimation results of model (9).
effect of lag order 2 of
(i.e.,
) increases with time
while the lag order 1 of
(i.e.,
) has no such characteristic, and effect of the lag order 3 of
(i.e.,
) is close to zero. The time-varying effects from both
and
decrease with
.
The last three sample values are used to calculate the relative prediction error (RPE) defined as:
where
are predicted by model (9).
Table 4 shows the relative prediction error results of model (9) for the three forward steps. It can be seen that the average RPE of model (9) is only 2.6%. For comparison, Table 4 also shows the 3-step forward prediction results of the lake inflow based on the FAR(p) model. According to the AMS criterion of Cai et al. [8] , the optimal fitted FAR(p) model is obtained when
,
and
, that is,
(10)
In addition, we also apply classical regression and autoregressive models to analyze the lake water inflow and find that residuals have heteroskedasticity. Therefore, we combine AR (p) model with the autoregressive conditional
![]()
Table 4. 3-step forward relative prediction error of
under different models.
heteroskedasticity (ARCH) model, i.e., AR(p)-ARCH(q) model, to fit the residuals. The final optimal AR(p)-ARCH(q) model is:
(11)
By comparing the prediction results of the three models in Table 4, our proposed model (9) performs better than the other two models. Compared to model (10), model (9) takes into account the effects of covariates on lake inflow; compared to model (11), model (9) uses the advantages of the time-varying coefficient. Since our proposed model combines the strengths of the FAR(p) model and the classical regression and autoregressive mixed model, it has advantages on modeling time series data with complex correlations between sample components.
5. Conclusions and Future Works
In this article, we propose a partial time-varying coefficient regression and autoregressive mixed model, which can be regarded as an extension of traditional regression and autoregressive mixed model and time-varying coefficient regression model. The proposed model is very flexible and can handle both complex correlations between time series components and effects of other covariates, so it can improve model fitting when building relationships between complex time series and covariates. We apply the local polynomial expansion technique and the least squares estimation method to obtain local estimates of the parameter functions in the model. At the same time, we also propose a global estimator algorithm for the constant coefficients in the model. In addition, we derive the asymptotic normality of the proposed estimators and conduct simulation studies to examine their finite-sample performances, and find our proposed estimators perform well. Finally, we apply the model to analyze the relationships between the water inflow of Shasta Lake and the other five climatic variables.
As we mentioned in Section 1, local polynomial technique is widely used to estimate varying-coefficient models, including time-varying coefficient time series models. One advantage of this method is it has solid theory so that we can derive out explicit biases of corresponding estimators. Furthermore, local polynomial method is easily implemented. Based on the local estimators, we can obtain global estimators for constant coefficients by using formula (6). Note that it is needed to select the best bandwidth when using local polynomial method. However, if we apply other smooth methods such as spline approach to estimate time-varying coefficients in (3), we also need to determine some turning parameters, e.g., knots and degree.
Although we can apply the local polynomial expansion technique and the least squares estimation method to obtain the local estimators as well as corresponding variances, how to test these estimated time-varying coefficients is another important problem. For example, the AMS criterion suggests that model (9) includes five time-varying coefficients, that is,
,
,
,
and
, but Figure 3(b) shows that some estimated curves seem to be flat across time. Thus, it makes us wonder whether those estimated time-varying coefficients can be treated as constant. One way to assess this is to construct the confidence band to see whether a time-varying coefficient is a function or a constant. This method may be realized by obtaining weak Bahadur representations of estimators [29] . Another way is to develop a more objective and theoretical test following the simulation-assisted hypothesis testing procedure proposed in Zhang and Wu [21] . This will be our future research work.
Acknowledgements
Dr. Cao’s research is supported by Natural Science Foundation of Top Talent of SZTU (grant no. GDRC202135).
Appendix: Proof of Theorem 1
We first introduce some notations for the convenience. Denote
where
Define
where
Noting the definitions of
and
, it is easy to know
After a simple combination, we can obtain
(A.1)
Note that the equivalent form of formula (4) is:
(A.2)
By (A.1) and (A.2), it is easy to know
(A.3)
Next, we discuss the large sample properties of
. To facilitate the derivation, the following notation is introduced:
,
. For
,
, let
It can be seen from the above that for a stationary process
. Using a similar derivation from Cai (2007), we obtain
(A.4)
Thus, we have
. Similarly, we obtain
(A.5)
Next, we derive the properties of
. From the approximation of the Riemann summation of definite integrals, it is known that when
, we have
(A.6)
Since the kernel function
is symmetrical,
,
. Therefore,
(A.7)
when
. Combining the results of (A.3)-(A.7), it is not difficult to obtain the conclusion of Theorem 1.