The Equivalence between Orthogonal Iterations and Alternating Least Squares ()
1. Introduction
The alternating least squares (ALS) method has several important applications, e.g., [1] - [54]. The origin of the method lies in the field of statistical Principal Components Analysis, e.g., [37] [47] [52] [53]. In the modern era, it is widely used in problems where standard SVD methods are not applicable. These problems include, for example, nonnegative matrix factorization [6] [17] [28] [35] [36], matrix completion problems [5] [14] [15] [20] [23] [24] [30] [54], and tensor approximations [12] [18] [29] [48] [49] [50]. In this note, we consider the ALS method as means for calculating low-rank approximations of large sparse matrices. Let
be a given large sparse matrix, let k be a given integer (the desired matrix rank) which is considerably smaller than
, and let
denote the set of all the real
matrices whose rank is at most k. Then the term “low-rank approximation” refers to a matrix
that approximates A. More precisely, we seek a matrix that solves the problem
(1.1)
where
denotes the Frobenius matrix norm. Recall that a rank-k truncated SVD of A provides a solution of (1.1). However, when A is a large sparse matrix, a standard SVD of A can be “too expensive”. This motivates the use of “cheaper” methods which are able to exploit the sparsity of A. The ALS algorithm is aimed at solving the problem
(1.2)
Note that (1.1) and (1.2) are equivalent in the sense that a solution of one problem provides a solution to the other problem. The idea behind the ALS algorithm is rather simple. The
iteration,
is composed of the following two steps.
Step 1: Given
compute
to be a solution of the least squares problem
(1.3)
Step 2: Given
, compute
to be a solution of the least squares problem
(1.4)
The details of the ALS iteration are discussed in the next section.
The orthogonal iterations method has different aim and different motivation. Let
be a given symmetric matrix. Then this method is aimed at computing k dominant eigenvectors of G. It is best suited for handling large sparse matrices in which a matrix-vector product needs only
flops. It is also assumed that k is considerably smaller than n. Other names of this method are “subspace iterations”, “simultaneous iterations” and “block-Power method”, e.g., [3] [4] [11] [16] [19] [39] [40] [41] [42] [44] [46]. The idea behind this method is to use a block version of the Power method that includes frequent orthogonalizations. The
iteration,
, is composed of the following two steps. It starts with a matrix
that has orthonormal columns. The column space of
approximates the desired invariant subspace of G.
Step 1: Given
, compute the matrix
(1.5)
Step 2: Compute
to be a matrix whose columns constitute an orthonormal basis of
. In practice
is obtained by applying a QR factorization of
.
Using the Rayleigh-Ritz procedure it is possible to extract from
the corresponding estimates of the desired eigenpairs of G. The details are discussed in Section 3.
The aim of this note is to show that ALS is closely related to “orthogonal iterations”. To see this relation we assume that
. In this case the two methods generate the same sequence of subspaces, and the same sequence of low-rank approximations. The proof is given in Section 4.
The equivalence relations that we derive provide important insight into the behavior of both methods. In particular, as explained in Section 3, the rate of convergence of orthogonal iterations is determined by ratios between certain eigenvalues of G. This implies that the rate of convergence of the ALS method obeys a similar rule. Moreover, there are several ways to accelerate orthogonal iterations, and these methods can be adapted to accelerate the ALS method. Conversely, being a minimization method the objective function of the ALS method is monotonic decreasing. This suggests that the orthogonal iterations method has an analogous property.
The relation between ALS and the block-Power method was recently observed by Jain et al. [24] in the context of matrix completion algorithms. A further discussion of this relation is given in Hardt [21] [22]. However, the observations made in these works are using several assumptions on the data matrix. For example, it is assumed that A has missing entries, and that the locations of the missing entries (or the known entries) satisfy certain statistical conditions. It is also assumed that the singular vectors of A satisfy a certain coherence requirement, that A is a low-rank matrix, and in [21] [22] it is assumed to be symmetric. In contrast, our analysis makes no assumption on A. Consequently, the algorithms considered in [21] [22] [24] are quite different from the classic versions that are discussed below, which yield different results. Anyway, an important consequence made in [21] [22] [24] is that the convergence properties of orthogonal iterations can be used to understand the behavior of ALS when applied to matrix completion problems. The equivalence relations that we derive in the next sections help to achieve this goal.
2. The Alternating Least Squares (ALS) Method
In this section we describe two versions of the ALS iteration. The basic scheme solves the linear systems by using a QR factorization that is followed by a back substitution process, while the modified scheme avoids back substitution. This reduces the computational effort per iteration and helps to see the relation with orthogonal iterations.
The first step of the basic iteration requires the solution of (1.3). Let
, denote the ith row of A, and let
, denote the ith row of
. Then, by comparing
against
we see that
solves the linear least squares problem
(2.1)
where
denotes the Euclidean vector norm. The solution of (2.1) is carried out by applying a QR factorization of
of the form
(2.2)
where
,
, and
is an upper triangular matrix.
Similar arguments enable us to solve (1.4). Let
, denote the jth column of A, and let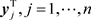 , denote the jth row of
, denote the jth row of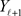 . Then by comparing
. Then by comparing 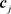 against
against 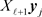 we see that
we see that 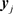 solves the linear least squares problem
solves the linear least squares problem
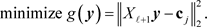 (2.3)
(2.3)
The computation of 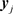 is carried out by applying a QR factorization of
is carried out by applying a QR factorization of 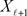 that has the form
that has the form
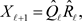 (2.4)
(2.4)
where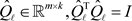 , and
, and 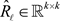 is an upper triangular matrix.
is an upper triangular matrix.
Assume for simplicity that the matrices 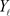 and
and 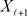 have full column rank, which means that
have full column rank, which means that  and
and 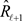 are invertible matrices. This enables us to express the solutions of Problem (2.1) and (2.3) as
are invertible matrices. This enables us to express the solutions of Problem (2.1) and (2.3) as
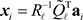 (2.5)
(2.5)
and
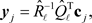 (2.6)
(2.6)
respectively. In practice, a matrix-vector product of the form  is computed by solving the system
is computed by solving the system ![]() via back substitution. In matrix notations the above equalities are summarized as
via back substitution. In matrix notations the above equalities are summarized as
![]() (2.7)
(2.7)
and
![]() (2.8)
(2.8)
Below we describe a modified scheme which save the multiplications by ![]() and
and![]() . (That is, it avoids the back substitution processes.)
. (That is, it avoids the back substitution processes.)
The modified scheme is based on the following observations. Let ![]() be any invertible matrix, then
be any invertible matrix, then
![]() (2.9)
(2.9)
The last equality allows us to replace ![]() with
with![]() , which turns (1.3) into the form
, which turns (1.3) into the form
![]() (2.10)
(2.10)
while the last problem has explicit solution,
![]() (2.11)
(2.11)
Similarly, it is possible to replace ![]() with
with![]() , which turns (1.4) into the form
, which turns (1.4) into the form
![]() (2.12)
(2.12)
while the last problem has explicit solution,
![]() (2.13)
(2.13)
The modified ALS iteration is summarized in the following two steps.
Step 1: Given ![]() compute the QR factorization (2.2) and obtain
compute the QR factorization (2.2) and obtain ![]() from (2.11).
from (2.11).
Step 2: Given ![]() compute the QR factorization (2.4) and obtain
compute the QR factorization (2.4) and obtain ![]() from (2.13).
from (2.13).
Let![]() , denote the rank-k approximations that are generated by the basic ALS iterations (2.7) - (2.8). Then, in exact arithmetic, the modified scheme generates the same sequence of approximations. Consequently since (2.7) - (2.8) are repeatedly solving (1.3) and (1.4), the sequence
, denote the rank-k approximations that are generated by the basic ALS iterations (2.7) - (2.8). Then, in exact arithmetic, the modified scheme generates the same sequence of approximations. Consequently since (2.7) - (2.8) are repeatedly solving (1.3) and (1.4), the sequence![]() , has the decreasing property
, has the decreasing property
![]() (2.14)
(2.14)
Moreover, as we now show, both versions satisfy
![]() (2.15)
(2.15)
Consider first the iteration (2.7) - (2.8). Then combining (2.4) and (2.7) yields
![]() (2.16)
(2.16)
and
![]() (2.17)
(2.17)
while substituting the last expression for ![]() into (2.8) gives
into (2.8) gives
![]() (2.18)
(2.18)
Thus, in exact arithmetic (2.15) holds. Similarly, in the modified scheme (2.4) and (2.11) give
![]() (2.19)
(2.19)
while from (2.13) we obtain
![]() (2.20)
(2.20)
In the next sections we shall see that orthogonal iterations share a similar property.
Observe that the modified ALS iteration is not using the matrices ![]() and
and![]() . This feature helps to overcome a possible rank deficiency of
. This feature helps to overcome a possible rank deficiency of ![]() or
or![]() . In classical Gram-Schmidt orthogonalization rank deficiency may cause a gradual loss of orthogonality, but this can be avoided by reorthogonalization and column pivoting, or by using Householder QR with column pivoting. For detailed discussions of the QR factorization see [7] [8] [9] [13] [19] [45]. The modified ALS iteration has recently been considered in Oseledets et al. [38] under the name “simultaneous orthogonal iterations”. It is shown there that the modified version is equivalent to ALS and, therefore, has the same rate of convergence.
. In classical Gram-Schmidt orthogonalization rank deficiency may cause a gradual loss of orthogonality, but this can be avoided by reorthogonalization and column pivoting, or by using Householder QR with column pivoting. For detailed discussions of the QR factorization see [7] [8] [9] [13] [19] [45]. The modified ALS iteration has recently been considered in Oseledets et al. [38] under the name “simultaneous orthogonal iterations”. It is shown there that the modified version is equivalent to ALS and, therefore, has the same rate of convergence.
3. Orthogonal Iterations
Let ![]() be a real symmetric matrix with eigenvalues
be a real symmetric matrix with eigenvalues
![]() (3.1)
(3.1)
Then the orthogonal iterations method is aimed at calculating the k largest eigenvalues of G, ![]() , and the corresponding eigenvectors. The
, and the corresponding eigenvectors. The ![]() iteration,
iteration, ![]() , is composed of the following two steps.
, is composed of the following two steps.
Step 1: Given a matrix![]() , compute a QR factorization of
, compute a QR factorization of![]() :
:
![]() (3.2)
(3.2)
Step 2: Compute ![]() from the rule
from the rule
![]() (3.3)
(3.3)
The approximation of the desired eigenpairs is achieved by applying the Rayleigh-Ritz procedure. For this purpose the basic iteration is extended with the following three steps.
Step 3: Compute the related Rayleigh-quotient matrix
![]() (3.4)
(3.4)
Step 4: Compute a spectral decomposition of![]() :
:
![]() (3.5)
(3.5)
where![]() , and
, and ![]() is a diagonal matrix such that
is a diagonal matrix such that
![]() (3.6)
(3.6)
(The diagonal entries of ![]() are called “Ritz values”.)
are called “Ritz values”.)
Step 5: If desired compute the related matrix of k “Ritz vectors”,
![]() (3.7)
(3.7)
It is important to note that Steps 3 - 5 are not essential for the computation of![]() . Hence it is possible to defer these steps. The orthogonal iterations method and its convergence properties are derived in the pioneering works of Bauer [4], Jennings [25] [26], Stewart [44], Rutishauser [40] [41], and Clint and Jennings [11]. In these papers the method is called the simultaneous iteration. See also the discussions in ( [3], pp. 54-55), ( [16], pp. 156-159), ( [19], pp. 367-368) and ( [39], pp. 288-299). It is shown there that the computed Ritz values in (3.4) - (3.7) converge toward the corresponding eigenvalues of G. Assume that
. Hence it is possible to defer these steps. The orthogonal iterations method and its convergence properties are derived in the pioneering works of Bauer [4], Jennings [25] [26], Stewart [44], Rutishauser [40] [41], and Clint and Jennings [11]. In these papers the method is called the simultaneous iteration. See also the discussions in ( [3], pp. 54-55), ( [16], pp. 156-159), ( [19], pp. 367-368) and ( [39], pp. 288-299). It is shown there that the computed Ritz values in (3.4) - (3.7) converge toward the corresponding eigenvalues of G. Assume that![]() , then for
, then for![]() , the sequence
, the sequence![]() , converges toward
, converges toward![]() , and the asymptotic rate of convergence is determined by the ratio
, and the asymptotic rate of convergence is determined by the ratio
![]() (3.8)
(3.8)
In other words, the sequence![]() , converges to zero at about the same speed as the sequence
, converges to zero at about the same speed as the sequence![]() . Furthermore, if
. Furthermore, if ![]() is a simple eigenvalue then the jth Ritz vector converges toward the jth eigenvector of G and the rate of convergence is determined by the ratio (3.8).
is a simple eigenvalue then the jth Ritz vector converges toward the jth eigenvector of G and the rate of convergence is determined by the ratio (3.8).
The last observations open the gate for accelerating the basic orthogonal iteration. Below we mention a number of ways to achieve this task.
Increasing the subspace dimension. In this approach the number of columns in the matrix ![]() is increased to be
is increased to be ![]() where
where ![]() is a small integer. (Typical values of q are k or 2k.) The advantage of this modification is that the convergence ratio changes to
is a small integer. (Typical values of q are k or 2k.) The advantage of this modification is that the convergence ratio changes to
![]() (3.9)
(3.9)
and it can be much smaller than (3.8). The price paid for this gain is that the storage requirements and the computational efforts per iteration are increased. The next acceleration attempts to avoid this penalty.
Power acceleration. In this iteration the updating of ![]() in Step 2 is changed to
in Step 2 is changed to
![]() (3.10)
(3.10)
where ![]() is a small integer. The advantage of this modification is that now the convergence ratio is reduced to
is a small integer. The advantage of this modification is that now the convergence ratio is reduced to
![]() (3.11)
(3.11)
Thus one iteration of this kind has the same effect as p iterations of the basic scheme. The main saving is, therefore, a smaller number of orthogonalizations. In practice p is often restricted to stay smaller than 10. The reason lies in the following difficulty. Assume for a moment that![]() . In this case G has a unique dominant eigenvector. Then, as p increases the columns of the matrix
. In this case G has a unique dominant eigenvector. Then, as p increases the columns of the matrix ![]() tend toward the dominant eigenspace of G, and
tend toward the dominant eigenspace of G, and ![]() becomes highly rank-deficient. Other helpful modifications include polynomial acceleration (which is often based on Chebyshev polynomials), and locking (a type of deflation), e.g., [3] and [39].
becomes highly rank-deficient. Other helpful modifications include polynomial acceleration (which is often based on Chebyshev polynomials), and locking (a type of deflation), e.g., [3] and [39].
4. Equivalence Relations
In this section we derive equivalence relations between the ALS method and the orthogonal iterations method. To see these relations we make the assumption that
![]() (4.1)
(4.1)
and use the following notations. Let![]() , denote the sequence of
, denote the sequence of ![]() matrices that are generated by the orthogonal iteration method, and let
matrices that are generated by the orthogonal iteration method, and let
![]() (4.2)
(4.2)
denote the related QR factorization of![]() . Similarly, let the
. Similarly, let the ![]() matrices
matrices![]() ,
, ![]() , be obtained by the ALS method, and let
, be obtained by the ALS method, and let
![]() (4.3)
(4.3)
denote the related QR factorization of![]() . Then Step 2 of the orthogonal iteration method gives
. Then Step 2 of the orthogonal iteration method gives
![]() (4.4)
(4.4)
while from (2.15) we obtain
![]() (4.5)
(4.5)
These equalities lead to the following conclusion.
Theorem 1. Assume that the initial matrices satisfy
![]() (4.6)
(4.6)
Then in exact arithmetic we have
![]() (4.7)
(4.7)
and
![]() (4.8)
(4.8)
for![]() . In other words, the two methods generate the same sequence of subspaces!
. In other words, the two methods generate the same sequence of subspaces!
Proof. The proof is a direct consequence of (4.4) and (4.5) using induction on![]() . □
. □
We have seen that the matrix ![]() solves (2.10). Hence the rank-k approximation of A that corresponds to
solves (2.10). Hence the rank-k approximation of A that corresponds to ![]() has the form
has the form
![]() (4.9)
(4.9)
Similarly, the rank-k approximation of A that corresponds to ![]() has the form
has the form
![]() (4.10)
(4.10)
The next theorem shows that these approximations are equal.
Theorem 2 (Rank-k approximations). Using the former assumptions and notations we have the equality
![]() (4.11)
(4.11)
In other words, the two methods generate the same sequence of rank-k approximations.
Proof. Let ![]() be some vector in
be some vector in![]() . Then from (4.8) we see that the projection of
. Then from (4.8) we see that the projection of ![]() on Range (
on Range (![]() ) equals the projection of
) equals the projection of ![]() on Range (
on Range (![]() ). That is,
). That is,
![]() (4.12a)
(4.12a)
and
![]() (4.12b)
(4.12b)
while the last equality implies (4.11).
Corollary 3 (The decreasing property). Recall that the ALS method has the decreasing property (2.14). Now (4.11) implies that this property is also shared by the orthogonal iteration method.
The next lemma helps to convert the decreasing property into an equivalent increasing property.
Lemma 4. Let ![]() and
and ![]() be as above. Then
be as above. Then
![]() (4.13)
(4.13)
Proof. Let us complete the columns of ![]() to be an orthonormal basis of
to be an orthonormal basis of![]() . This gives us an
. This gives us an ![]() orthonormal matrix
orthonormal matrix
![]() (4.14)
(4.14)
where ![]() is an
is an ![]() matrix that satisfies
matrix that satisfies
![]() (4.15)
(4.15)
and O denotes a null matrix. Observe that the structure of Z implies the equality
![]() (4.16)
(4.16)
On the other hand, since the Frobenius norm is unitarily invariant,
![]()
Corollary 5. Since the sequence ![]() is monotonic decreasing, equality (4.13) implies that the sequence
is monotonic decreasing, equality (4.13) implies that the sequence ![]() is monotonic increasing. That is,
is monotonic increasing. That is,
![]() (4.17)
(4.17)
for![]() .
.
Observe also that
![]()
where ![]() is the Rayleigh-quotient matrix (3.4), and
is the Rayleigh-quotient matrix (3.4), and![]() , are the corresponding Ritz values. This relation leads to the following conclusion, which appears to be a new property of the orthogonal iteration method.
, are the corresponding Ritz values. This relation leads to the following conclusion, which appears to be a new property of the orthogonal iteration method.
Corollary 6 (A trace increasing property). Let G be a symmetric positive semidefinite matrix and let the matrices![]() , be generated by the orthogonal iterations method. Then
, be generated by the orthogonal iterations method. Then
![]() (4.18)
(4.18)
for![]() . □
. □
We have seen in Section 3 that the rate of convergence of the orthogonal iterations method depends on the ratio (3.8). Now the equivalence relations that we have proved suggest that the ALS method behaves in a similar way. To state this result more precisely we need the following notations. Let
![]() (4.19)
(4.19)
denote the singular values of A, and let
![]() (4.20)
(4.20)
denote the singular values of![]() ,
,![]() . Then, clearly,
. Then, clearly,
![]() (4.21)
(4.21)
Similarly, since![]() , the singular values of
, the singular values of ![]() satisfy
satisfy
![]() (4.22)
(4.22)
These relations lead to the following observation, which seems to be a new property of the ALS method.
Theorem 7. Assume that![]() , then for
, then for![]() , the sequence
, the sequence
![]() (4.23)
(4.23)
converges to zero at the same asymptotic rate as the sequence
![]() (4.24)
(4.24)
Proof. From (4.21) and (4.22) we conclude that the sequence
![]() (4.25)
(4.25)
converges to zero at the same asymptotic rate as the sequence (4.24). Yet, since
![]() (4.26)
(4.26)
the sequence (4.23) shares this property. □
The last theorem implies that the rate of convergence of ALS can be improved by increasing the subspace dimension (See Section 3).
The fact that the two methods converge at the same speed raises the question of which iteration is more efficient to use. One advantage of the orthogonal iterations method is that it stores and updates only (estimates for) the right singular vectors of A. This halves the storage requirements and the number of orthogonalizations. The orthogonal iterations method achieves one QR factorization per iteration, while ALS requires two QR factorizations per iteration. The computation of the left singular vectors and the related low-rank approximation of A is deferred to the end of the iterative process. A further saving can be gained by applying Power acceleration.
However, being a variant of the Block Power method, the orthogonal iteration is expected to be slower than Krylov subspace methods that are based on Lanczos algorithm. See, for example, the comparisons in ( [19], pp. 554-555), ( [39], pp. 250-252), and ( [46], pp. 272-275). Recent Krylov methods are using implicitly restarted Lanczos schemes, e.g., [10] [43] [51], and this approach is considerably faster than orthogonal iterations. Consequently the ALS method is expected to be slower than restarted Krylov methods for low-rank approximations, e.g., [1] [2] [33] [34]. This drawback is, perhaps, the reason that the use of ALS has been moved to problems in which it is difficult to apply a standard SVD algorithm or a restarted Krylov method.
5. Concluding Remarks
As noted in the introduction, the relations between ALS and the block-Power method were recently observed in the context of matrix completion algorithms. However, the related matrix completion algorithms differ substantially from the classic versions discussed in this paper. Indeed, the equivalence between ALS and orthogonal iterations is somewhat surprising, as these methods are well known for many years, and the basic ALS iteration, which uses back-substitutions, is quite different from the orthogonal iteration. The modified version avoids back substitutions, which helps to see the similarity between the two methods.
The equivalence relations bring important insight into the behavior of both methods. One consequence is that the convergence properties of ALS are identical to those of orthogonal iterations. This means that the rate of convergence of the ALS method is determined by the ratios in (4.24), which appears to be a new result. Similarly, the descent property of ALS implies a trace increasing property of the orthogonal iteration method.
The orthogonal iterations method needs less storage requirements, and less QR factorizations per iteration. In addition, it has a number of useful accelerations. These advantages suggest that replacing ALS with orthogonal iterations might be helpful in some applications. On the other hand, the ALS method can be modified to handle problems that other methods cannot handle, such as non-negative matrix factorizations (NMF), matrix completion problems, and tensor decompositions. The ALS iteration that is implemented in these problems is often quite different from the basic iteration (2.7) - (2.8). Yet in some cases it has a similar asymptotic behavior. This happens, for example, in NMF problems when (nearly) all the entries in the converging factors are positive. Another example is the proximal-ALS algorithm in matrix completion, see ( [14], p. 134). In such cases the new results provide important insight into the asymptotic behaviour of the algorithm.