1. Introduction
The article’s goal is to present a comprehensive summary of deriving the distribution of the usual Kolmogorov-Smirnov test statistic, both in its exact and approximate form. We concentrate on practical aspects of this exercise, meaning that
• reaching a modest (three significant digit) accuracy is usually considered quite adequate,
• computing critical and P-values of the test is the primary objective, implying that it is the upper tail of the distribution which is most important,
• methods capable of producing practically instantaneous results are preferable to those taking several seconds, minutes, or more,
• simple, easy to understand (and to code) techniques have a great conceptual advantage over complex, black-box type algorithms.
This is the reason why our review excludes some existing results (however deep and mathematically interesting they may be); we concentrate only on the most relevant techniques (this is also the reason why our bibliography is deliberately far from complete).
1.1. Test Statistic
The Kolmogorov-Smirnov one-sample test works like this: the null hypothesis states that a random independent sample of size n has been drawn from a specific (including the value of each of its parameters, if any) continuous distribution. The test statistics (denoted
) is the largest (in the limit-superior sense) absolute-value difference between the corresponding empirical cumulative density function (CDF) and the theoretical CDF, denoted
, of the hypothesized distribution; the former is defined by
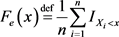 (1)
(1)
where
are the individual sample values and
is the usual indicator function (equal to 1 when
is smaller than x, equal to 0 otherwise). Note that
is a step function which starts at 0 and increases, by
at each
, until it reaches the value of 1.
To complete the test, we need to know the CDF of
under the assumption that the null hypothesis is correct. Deriving this CDF is a difficult task; there are several exact techniques for doing that; in this article, we expound only the major ones. We then derive the
limit of the resulting distribution, to serve as an approximation when n is relatively large. Since the accuracy of this limit is not very impressive (unless n is extremely large), we show how to remove the
-proportional,
-proportional, etc. error of this approximation, making it sufficiently accurate for samples of practically any size.
1.2. Transforming to
The first thing we do is to define
(2)
where
is the CDF of the hypothesized distribution; the
then constitute (under the null hypothesis) a random independent sample from the uniform distribution over the
interval, the new theoretical CDF is then simply
. It is important to realize that doing this does not change the vertical distances between the empirical and theoretical CDFs; it transforms only the corresponding horizontal scale as Figure 1 and Figure 2 demonstrate (the original sample is from Exponential distribution).
This implies that the resulting value of
(and consequently, its distribution) remains the same. We can then conveniently assume (from now on) that our sample has been drawn from
; yet the results apply to any hypothesized distribution.
1.3. Discretization
In this article, we aim to find the CDF of
, namely
(3)
only for a discrete set of n values of d, namely for
, even though
is a continuous random variable whose support is the
interval. This proves to be sufficient for any (but extremely small) n, since our discrete results can be easily extended to all values of d by a sensible interpolation.
There are technique capable of yielding exact results for any value of d (see [1] or [2]), but they have some of the disadvantages mentioned above and will not be discussed here in any detail; nevertheless, for completeness, we present a Mathematica code of Durbin’s algorithm in the Appendix.
2. Linear-Algebra Solution
This, and the next two section, are all based mainly on [3], later summarized by [4].
We start by defining
integer-valued random variables
(4)
where
,
; note that
equals the number of the
observations which are smaller than
, also note that
and
are always identically equal to 0. We can then show that
Claim 1.
if and only if at least one of the
values is equal to j or –j.
Proof. When
, then there is a value of d to the left of
such that
, implying that
; similarly, when
then there is a value of d to the right of
such that
, implying the same.
To prove the reverse, we must first realize that no one-step decrease in the
sequence can be bigger than 1 (this happens when there are no observations between the corresponding
and
); this implies that the T sequence must always pass through all integers between the smallest and the largest value ever reached by T.
Since
implies that either
has exceeded the value of j at some d, or it has reached a value smaller than −j, it then follows that at least one
has to be equal to either j or −j respectively. ■
2.1. Total-Probability Formula
Now, consider the sample space of all possible (integer) values of
, and a fixed integer J between 1 and
inclusive (we use the capital font to emphasize J’s special role in all subsequent formulas). If
is the first of the
random variables to reach the value of either J or –J, we denote the corresponding event
and
respectively (
means that none of the Tis have ever reached either J or −J);
then constitute a partition of this sample space.
By a routine application of the formula of total probability, we can write, for any k between 1 and
(
cannot happen for any other T)
(5)
We know that, given
,
could not have happened. Similarly, given
(given
),
cannot happen any earlier than at
(
). And finally,
is equal to 0 when
(we need at least J steps to reach
from
). We can thus simplify (5) to read
(6)
where
, with the understanding that an empty sum (lower limit exceeding the upper limit) equals to 0.
From (4) it is obvious that
is equivalent to having (exactly to be understood from now on)
observations smaller than
.The corresponding probability is the same as that of getting
successes in a binomial-type experiment with n trials and a single-success probability of
; we will denote it
.
Similarly,
has the same probability as
(earlier values of T becoming irrelevant), which means that, out of the remaining
observations,
must be in the
interval; this probability is equal to
.
Finally,
, which means that, out of the remaining
observations,
must be in the
interval; this probability equals to
.
2.2. Resulting Equations
We can thus simplify (6) to
(7)
(with
), where the
coefficients are readily computable. This constitutes
linear equations for the unknown values of
,
.
By the same kind of reasoning we can show that, for any k between J and
(8)
(note that the T sequence needs at least 2J steps to reach -J at
from J at
), leading to
(9)
when
.
Combining (7) and (9), we end up with the total of
linear equations for the same number of unknowns. Furthermore, these equations have a “doubly triangular” form, meaning that proceeding in the right order, i.e.
, we are always solving only for a single unknown (this is made obvious by the next Mathematica code).
Having found the solution, we can then compute (based on Claim 1)
(10)
which yields a single value of the desired CDF (or rather, of its complement) of
. To get the full (at least in the discretized sense) picture of the distribution, the procedure now needs to be repeated for each possible value of J.
The whole algorithm can be summarized by the following Mathematica code (note that instead of superscripts, interpreted by Mathematica as powers, we have to use “overscripts”).
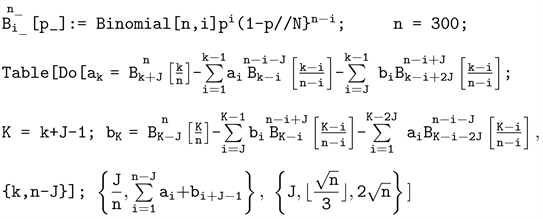
(for improved efficiency, we use only the relevant range of J values).
The program takes over one minute to execute; the results are displayed in Figure 3.
We can easily interpolate values of the corresponding table to convert it into a continuous function, thereby finding any desired value to a sufficient accuracy.
The main problem with this algorithm lies in its execution time, which increases (like most matrix-based computation) with roughly the third power of n. This makes the current approach rather prohibitive when dealing with samples consisting of thousands of observations.
In this context it is fair to mention that none of our programs have been optimized for run-time efficiency; even though some improvement in this regard is definitely possible, we do not believe that it would substantially change our general conclusions.
3. Generating-Function Solution
We now present an alternate way of building the same (discretized, but otherwise exact) solution. We start by defining the following function of two integer arguments
(11)
Note that, when
is negative (i is always positive),
is equal to 0.
Claim 2. The binomial probability
can be expressed in terms of three such
functions, as follows
(12)
Proof.
(13)
■
Note that
has the value of 0 whenever the number of successes (the subscript) is either negative or bigger than n (the superscript). Similarly,
is always equal to 1.
3.1. Modified Equations
The new function (11) enables us to express (7) and (9) in the following manner:
(14)
and
(15)
respectively.
Cancelling
in each term of (14) and multiplying by
yields
(16)
which can be written as
(17)
(for any positive integer k), by defining
(18)
and
(19)
Note that n has disappeared from (17), making
and
potentially infinite sequences (consider letting n have any positive value; in that sense
is well defined for any i from 1 to
and
for any i from J to
). Once we solve for these two sequences, converting them back to
and
for any specific value of n is a simple task; this approach thus effectively deals with all n at the same time!
Similarly modifying (15) results in
(20)
(for any
), utilizing the previous definition of
and
. The equations, together with (17), constitute an infinite set of linear equations for elements of the two sequences. To find the corresponding solution, we reach for a different mathematical tool.
3.2. Generating Functions
Let us introduce the following generating functions
(21)
where j is a non-negative integer, and
(Kronecker’s
) is equal to 1 when
, equal to 0 otherwise.
Multiplying (17) by
and summing over k from 1 to
yields
(Gj)
since
is the coefficient of
in the expansion of
, and
is the coefficient of
in the expansion of
; combining two sequences in this manner is called their convolution. Note the importance (for correctness of the
result) of including
in the definition of
.
Similarly, it follows from (20) that
(22)
3.3. Resulting Solution
The last two (simple, linear) equations can be so easily solved for
and
that we do not even quote the answer.
Going back to a specific sample size n, we now need to find the value of (10), namely
(23)
which follows from solving (18) and (19) for
and
respectively. The numerator of the last expression is clearly (by the same convolution argument) the coefficient of
in the expansion of
(24)
An important point is that, in actual computation, the G functions need to be expanded only up to and including the
term, making them long but otherwise simple polynomials.
The algorithm to find
then requires us to build
,
,
,
and
, and Taylor-expand, up to the same
term,
(25)
which is obtained by substituting the solution to (Gj) and (22) into (24), and further dividing by
;
is then provided by the resulting coefficient of
.
Note that, based on the same expansion, we can get
for any smaller n as well, just by correspondingly replacing the value of
. Nevertheless, the process still needs to be repeated with all relevant values of J.
The corresponding Mathematica code looks as follows:
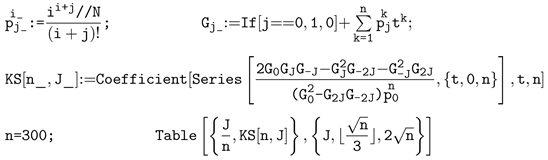
It produces results identical to those of the matrix-algebra algorithm, but has several advantages: the coding is somehow easier, it (almost) automatically yields results for any
(not a part of our code) and it executes faster (taking about 17 seconds). Nevertheless, its run-time still increases with roughly the third power of n, thus preventing us from using it with a much larger value of n.
We now proceed to find several approximate solutions of increasing accuracy, all based on (25).
4. Asymptotic Solution
As we have seen, neither of the previous two solutions is very practical (and ultimately not even feasible) as the sample size increases. In that case, we have to switch to using an approximate (also referred to as asymptotic) solution.
Large-n Formulas
First, we must replace the old definition of
, namely (11), by
(26)
Note that this does not affect (12), nor any of the subsequent formulas up to and including (25), since the various
factors always cancel out.
Also note that the definition can be easily extended to real (not just integer) arguments by using
in place of
, where
denotes the usual gamma function.
1) Laplace representation
Note that, from now on, the summations defining the G functions in (21) stay infinite (no longer truncated to the first n terms only).
Consider a (rather general) generating function
(27)
and an integer n (
may be implicitly a function of n as well as k); our goal is to find an approximation for
as n increases.
After replacing k and t with two new variables x and s, thus
(28)
becomes
(29)
Making the assumption that expanding
in powers of
results in
(30)
(and our results do have this property), then (29) is approximately equal to
(31)
which, in the
limit, yields the following (large-n) approximation to
:
(32)
Note that
is the so-called Laplace transform of
; we call it the Laplace representation of G.
To find an approximate value of the coefficient of
(i.e.
) of (27),
we need to find the so-called inverse Laplace transform (ILT) of
yielding the corresponding
then substitute 1 for x and divide by n (this is the gist of the technique of this section).
To improve this approximation,
itself and consequently
can be expanded in further powers of
(done eventually; but currently we concentrate on the
limit).
2) Approximating Gj
Let us now find Laplace representation of our
, i.e. the last line of (21), further divided by
(this is necessary to meet (30), yet it does not change (25) as long as
of that formula is divided by
as well). To find the corresponding
, we need the
limit of
(33)
To be able to reach a finite answer, j itself needs to be replaced by
; note that doing that with our J changes
to
.
It happens to be easier to take the limit of the natural logarithm of (33), namely
(34)
instead.
With the help of the following version of Stirling’s formula (ignore its last term for the time being)
(35)
and of (we do not need the last two terms as yet)
(36)
we get (this kind of tedious algebra is usually delegated to a computer)
(37)
We thus end up with
(38)
where
; this follows from (32) and the following result:
Claim 3.
(39)
when v and s are positive
Proof. Since
(40)
and
(41)
after the
substitution. Solving the resulting simple differential equation for
yields
(42)
where c is equal to
(43)
the last being a well-known integral (related to Normal distribution). ■
To find the
limit of (25), we first evaluate the right hand side of (38) with
and 2J, getting
(44)
where
(always positive).
3) Approximating GD
The corresponding Laplace representation of (25) further divided by n, let us denote it
, is then equal to
(45)
where
. This is based on substituting the right-hand sides of (44) into (25), and on the following result:
(46)
(Stirling’s formula again); the last limit also makes it clear why we had to divide (25) by n: to ensure getting a finite result again.
We now need to find the
function corresponding to (45), i.e. the latter’s ILT, and convert it to
according to (30); this yields an approximation for the coefficient of
in the expansion of (25), still divided by n. The ultimate answer to
is thus
.
Since the ILT of
(47)
(where k is a positive integer) is equal to
(48)
(this follows from (32) and (38), after replacing z by
), its contribution to
is
(49)
Applied to the last line of (45), this leads to
(50)
or, equivalently,
(51)
where
(52)
Note that the error of this approximation is of the
type, which means that it decreases, roughly (since there are also terms proportional to
,
, etc.), with
. Also note that the right hand side of (51) can be easily evaluated by calling a special function readily available (under various names) with most symbolic programming languages, for example “JacobiTheta4(0, exp(−2∙z2))” of Maple or “EllipticTheta[4, 0, Exp[−2z2]]” of Mathematica.
The last formula has several advantages over the approach of the previous two sections: firstly, it is easy and practically instantaneous to evaluate (the infinite series converges rather quickly only between 2 and 10 terms are required to reach a sufficient accuracy when
the CDF is practically zero otherwise), secondly, it is automatically a continuous function of z (no need to interpolate), and finally, it provides an approximate distribution of
for all values of n (the larger the n, the better the approximation).
But a big disappointment is the formula’s accuracy, becoming adequate only when the sample size n reaches thousands of observations; for smaller samples, an improvement is clearly necessary. To demonstrate this, we have computed the difference between the exact and approximate CDF when
; see Figure 4, which is in agreement with a similar graph of [2].
We can see that the maximum possible error of the approximation is over 1.5% (when computing the probability of
); errors of this size are generally not considered acceptable.
5. High-Accuracy Solution
Results of this section were obtained (in a slightly different form, and building on previously published results) by [5] and further expounded by a more accessible [6]; their method is based on expanding (in powers of
) the matrix-algebra solution. Here we present an alternate approach, similarly expanding the generating-function solution instead; this appears an easier way of deriving the individual
and
-proportional corrections to (50). We should mention that the cited articles include the
-proportional correction as well; it would not be difficult to extend our results in the same manner, if deemed beneficial.
To improve accuracy of our previous asymptotic solution, (34) and, consequently, (38) have to be extended by extra
and
-proportional terms (note that (35) and (36) were already presented in this extended form), getting
(53)
where the
sign corresponds to a positive (negative)
, respectively. The corresponding tedius algebra is usually delegated to a computer (it is no longer feasible to show all the details here), the necessary integrals are found by differentiating each side of the equation in (38) with respect to z2, from one up to four times.
The last expression represents an excellent approximation to the G functions of (44), with the exception of
(54)
![]()
Figure 4. Error of asymptotic solution (n = 300).
which now requires a different approach.
Claim 4.
(55)
Proof. The following elegant proof has been suggested by [7].
It is well known that the value of Lambert
function is defined as a solution to
, and that its Taylor expansion is given by
(56)
implying that
(57)
■
Differentiating
(58)
with respect to
, cancelling
, and solving for
yields
(59)
implying that
(60)
where u (being equal to
) is now the solution of
(61)
rather than (58). Solving the last equation for
and expanding the answer in powers of u results in
(62)
Inverting the last power series (which can be easily done to any number of terms) yields the following expansion:
(63)
Similarly expanding
, replacing
by
and further dividing by
proves our claim.
Having achieved more accurate approximation for all our G functions, and with the following extension of (46)
(64)
we can now complete the corresponding refinement of (45) by substituting all these expansions into (25), further divided by n. This results in
(65)
The last formula consists of two types of corrections: replacing E by
(66)
in its leading term removes the
-proportional error of (45); the remaining terms similarly represent the
-proportional correction; the error of (65) is thus of the
type.
Note that
(67)
enables us to express (65) in terms of E only; this is needed for its explicit verification (something we leave to a computer).
What we must do now is to convert (65) to the corresponding
, thus approximating the coefficient of
in the expansion of (25). We already possess the answer for the first two terms of (65), which are both identical to (45), except that
needs to be replaced by
in the first case, and divided by 12 in the second one.
To convert the remaining terms of (65) to their
contribution, we must first expand them in powers of E, then take the ILT of individual terms of these expansions, and finally set x equal to 1; the following table helps with the last two steps:
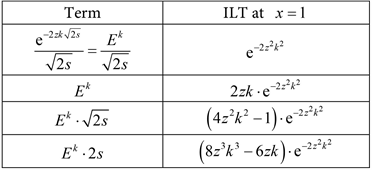 (68)
(68)
(the first row has already been proven; the remaining three follow by differentiating both of its sides with respect to zk (taken as a single variable), up to three times).
This results in the following replacement
(69)
where all three series are still fast-converging. Note that the binomial coefficient of the last sum equals to
.
We can then present our final answer for
in the manner of the following Mathematica code; the resulting KS function can then compute (practically instantaneously) this probability for any n and z.
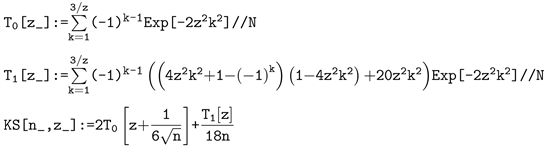
The resulting improvement in accuracy over the previous, asymptotic approximation is quite dramatic; Figure 5 again displays the difference between the exact and approximate CDF of
.
This time, the maximum error has been reduced to an impressive 0.0036%, this happens when computing
; note that potential errors become substantially smaller in the right hand tail (the critical part) of the distribution. Most importantly, when the same computation is repeated with
, the corresponding graph indicates that errors of the new approximation
![]()
Figure 5. Error of high-accuracy solution (n = 300).
can never exceed 0.20%; such an accuracy would be normally considered quite adequate (approximating Student’s
by Normal distribution can yield an error almost as large as 1%).
As mentioned already, the approximation of
can be made even more accurate by adding, to the current expansion, the following extra
-proportional correction
(70)
At
, this reduces the corresponding error by a factor of 4; nevertheless, from a practical point of view, such high accuracy is hardly ever required. Furthermore, the new term reduces the maximum error of the
result from the previous 0.17% only to 0.10%; even though this represents an undisputable improvement, it is achieved at the expense of increased complexity. Note that adding higher (
-proportional, etc.) terms of the expansion would no longer (at
) improve its accuracy, since the expansion starts diverging (a phenomenon also observed with, and effectively inherited from, the Stirling expansion); this happens quite early when n is small (and, when n is large, higher accuracy is no longer needed).
When simplicity, speed of computation, and reasonable accuracy are desired in a single formula, the next section presents a possible solution.
Final Simplification
We have already seen that the
-proportional error is removed by the following trivial modification of (50)
(71)
Note that this amounts only to a slight shift of the whole curve to the left, but leaves us with a full
-type error.
When willing to compromise, [8] has taken this one step further: it is possible to show that, by extending the argument of
to
(72)
yields results which are very close to achieving the full
-proportional correction of (65) as well; this is a fortuitous empirical results which can be easily verified computationally (when
, the maximum error of the last approximation increases to 0.27%, for
it goes up to 0.0096% still practically negligible).
6. Conclusions and Summary
In this article, we hope to have met two goals:
• explaining, in every possible detail, the traditional derivations (two of them yielding exact results, several of them being approximate) of the
distribution,
• proposing the following simple modification of the commonly used formula:
(73)
making it accurate enough to be used as a practical substitute for exact results even with relatively small samples. Furthermore, the right hand side of this formula can be easily evaluated by computer software (see the comment following (52)).
Appendix
The following Mathematica function computes the exact
for any value of d; using it to produce a full graph of the corresponding CDF will work only for a sample size not much bigger than 700, since the algorithm’s computational time increases exponentially with not only n, but also with increasing values of d.
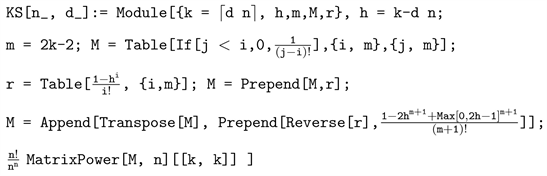
Nevertheless, computing only a single value of this function (such as a P value of an observed
) becomes feasible even for a substantially bigger sample size; for example: typing KS[3000, 0.031467] results in 0.994855, taking about 13 seconds on an average computer. Increasing n any further would necessitate switching to one of the (at that point, extremely accurate) approximations of our article.