The Effectiveness of the Squared Error and Higgins-Tsokos Loss Functions on the Bayesian Reliability Analysis of Software Failure Times under the Power Law Process ()
1. Introduction
Reliability analysis of a software under development is a key to assess whether a desired level of a quality product is achieved. Specially, when a software package is considered, and is tested after each failure detection, and then corrected until a new failure is observed. Over the past few decades, the reliability analysis of a software package has been studied, where graphical and numerical metrics have been introduced. One of the earliest, Duane (1964) [1] , who introduced a graph to assess the reliability of a software over time using its failure times. It has the cumulative failure rate and the time on the y-axis and x-axis, respectively. In this graph, one can conclude a software reliability improvement if a negative curve is observed whereas a positive curve means the software reliability is deteriorating. On the other hand, a horizontal line indicates that the software reliability is stable. The failure numbers
in time interval
is considered a Poisson counting process after satisfying the following conditions:
1)
.
2) Independent increment (counts of disjoint time intervals are independent).
3) It has an intensity function
4) Simultaneous failures do not exist
The probability of random value
is given by:
(1)
Crow (1974) proposed a Non-Homogeneous Poisson Process (NHPP) , which is a Poisson Process with a time varying intensity function, given by:
(2)
with
and
are the shape and scale parameters, respectively. This Non-Homogeneous Poisson Process is also known as the Power Law Process (PLP).
The joint probability density function (PDF) of the ordered failure times
from a NHPP with intensity function
is given by:
(3)
where w is the so-called stopping time;
for the failure truncated case. Considering the failure truncation case, the conditional reliability function of the failure time
given
,
,
,
,
,
is a function of
.
As a numerical assessment, the estimate of the key parameter
in the
has an important role in evaluating the reliability of a software package. When the estimates of
are less and larger than 1, they indicate that the software reliability is improving and decreasing, respectively. The PLP is reduced to a homogeneous Poisson process when the estimate of
equals to 1.
The NHPP has been used for analyzing software’s failure times, and prediction of the next failure time. The subject model has been shown to be effective and useful not only in software reliability assessment [2] - [11] , but also in cyber-security; the attack detection in cloud systems [12] [13] , breast and skin cancer treatments’ effectiveness, [14] [15] [16] , respectively, finance; modeling of financial markets at the ultra-high frequency level [17] , trnasportation; modeling passengers’ arrivals [18] [19] [20] [21] [22] , and in the formulation of a software cost model [23] .
Since the conditional reliability function of the PLP is a function of the
, which includes the key parameter
. That being said updating the estimation methods for the key parameter will affect positively the
and the software reliability estimation, and therefore help the structuring of maintenance strategies. The authors [24] and [25] obtained the Bayesian estimates of the parameter
under the the squared-error and Higgins-Tsokos loss functions, respectively, and compared them to their approximate maximum likelihood estimate (MLE). They also showed the superiority of the Bayesian estimates to the MLE of the key parameter
, and the improvement in the reliability assessment under the PLP.
To perform Bayesian analysis on a real world problem, one needs to justify the applicability of such analysis. Then, the analysis process starts by identifying the probability distribution of the failure times of a software under development, the prior PDF of the key parameter
, and a loss function. The analytical tractability have made the squared-error loss function commonly used, where it places more weight on the estimates that are far from the true value than the estimates close to true value. Higgins and Tsokos [26] proposed a new loss function that maintains the analytical tractability feature and places exponentially more weight on extreme estimates of the true value.
In the present study, we investigate the effectiveness, in Bayesian Analysis, of using the commonly used squared-error (S-E) loss function versus the Higgins-Tsokos (H-T) loss function that puts the loss at the end of the process, for modeling software failure times. To accomplish this, we used the underline failure distribution to be the Power Law Process subject to using Burr PDF as a prior of the key parameter
. In addition, we utilize both loss functions to perform sensitive analysis of the prior selections. We perform parametric and non-parametric priors, namely Burr, Inverted Gamma, Jeffery, and two Kernel PDFs. Therefore, the primary objective of the study is to answer the following questions within a Bayesian framework:
1) How robust is the assumption of the squared-error loss function being challenged by the Higgins-Tsokos loss function in estimating the key parameter
of PLP for modeling software failure times?
2) Is the Bayesian estimate of the intensity function,
, of the PLP sensitive to the selections of the prior (parametric and non-parametric) and loss function (Higgins-Tsokos and S-E loss functions)?
The paper is organized as follows, Section 2 describes the theory and development of the Bayesian reliability model. Section 3 presents the results and discussion. Section 4 are the conclusions.
2. Theory and Bayesian Estimates
2.1. Review of the Analytical Power Law Process
The probability of achieving n failures of a given system in the time interval
can be written as
(4)
where
is the intensity function given by (2). The reduced expression is given by:
(5)
is the PLP that is commonly known as Weibull or Non-Homogeneous Poisson Process.
When the PLP is the underlying failure model of the failure times
and
, the conditional reliability function of
given
can be written mathematically as a function of the intensity function, given by:
(6)
since it is independent of
.
Note that the improvement in estimating the key parameter
in the
of the PLP, Equation (6), will improve the reliability estimation.
The maximum likelihood estimation (MLE) of
is a function of the largest failure time and the MLE of
is also a function of the MLE of
. Let
denote the first n failure times of the PLP, where
are measured in global time; that is, the times are recorded since the initial startup of the system. Thus, the truncated conditional probability distribution function,
, in the Weibull process is given by
(7)
With
, the Likelihood function for the first n failure times of the PLP
can be written as
(8)
The MLE for the shape parameter is given by
(9)
and for the scale parameter is
(10)
Note that the MLE of
depends on the MLE of
.
2.2. Development of the Bayesian Estimates
The authors [24] and [25] justified the applicability of Bayesian analysis to the PLP based on the Crow, [2] [27] , failure data from a system undergoing developmental testing (Table 1), by showing that the MLE of the key parameter
varies depending on the last failure time (largest time). Moreover, the authors used the Crow data (40 successive failure times) to compute the MLE of
(
), then computed the estimate considering the
is the largest failure time (
) and so on. After computing all MLEs of the key parameter
, they found that the MLEs of
follows a four-parameter Burr probability distribution,
, known as the four-parameter Burr type XII probability distribution, with a PDF given by:
(11)
where the hyperparameters
,
,
and
are being estimated using MLEs in the Goodness of Fit (GOF) test applied to the
estimates. The MLE
![]()
Table 1. Crow’s failure times of a system under development.
of the key parameter
is always affected by the largest failure, and therefore it is recommended not to consider it unknown constant. This recommendation provides the opportunity to study Bayesian analysis in the PLP with respect to various selections of loss functions and priors.
The Bayesian estimates of
will be derived using the squared-error and Higgins-Tsokos loss functions.
2.2.1. Bayesian Estimates Using Squared Error (S-E) Loss Function
The S-E loss function is given by:
(12)
The risk using the S-E loss function, where
represents the estimate of
, is given by:
(13)
By differentiating
with respect to
and setting it equal to zero we solve for
, the Bayesian estimate of
with respect to the S-E loss function and Burr probability distribution, Equation (11), given by:
(14)
where the posterior PDF of
given data (t),
, using the Bayes?? theorem, is given by:
(15)
Then, the Bayesian estimate of
, under the squared-error loss, is given by
(16)
2.2.2. Bayesian Estimates Using the Higgins-Tsokos Loss Function
The H-T loss function (1976) is given by
(17)
Higgins and Tsokos [26] showed that it places more weight on the extreme underestimation and overestimation when
and
, respectively. The risk using the H-T loss function, where
represents the estimate of
, is given by:
(18)
By differentiating
with respect to
and setting it equal to zero we solve for
, the Bayesian estimate of
with respect to the H-T loss function, given by:
(19)
The Bayesian estimate of
with respect to the Higgins-Tsokos loss function and Burr probability distribution, as the prior, has
given by
(20)
With the use of Equation (6), the conditional reliability of
, the analytical structure of the conditional Bayesian reliability estimate for the PLP that is subject to the above information is given by:
(21)
where
(22)
where
is the Bayesian estimate using
or
for the squared error or Higgins-Tsokos loss functions, respectively. We are also interested in comparing the Bayesian estimates, using Higgins-Tsokos loss function, of the subject parameter for different parametric and non-parametric priors, and with respect to its MLE given by Equation (9), assuming
has a random behavior and
as known; as well as, comparing Equation (10) with an adjusted MLE considered as a function of
.
2.3. Sensitivity Analysis: Prior and Loss Function
In this section, we seek the answer to the following question: Is the Bayesian MLE estimate of the intensity function,
, of the PLP sensitive to the selections of the prior( parametric and non-parametric) and loss function (Higgins-Tsokos and S-E loss functions)? Assuming
is a random variable, using simulated data, sensitive analysis was done for the following parametric and non-parametric priors ( [25] ):
1) Jeffreys’ prior ( [28] ): Jeffreys’ prior is proportional to the square root of the determinant of the Fisher information matrix (
). It is a non-informative prior, where the Jeffreys?? prior for the key parameter of the PLP
is scalar in this case, is given by:
(23)
2) The inverted gamma: The PLP and inverted gamma probability distributions belong to the exponential family of probability distributions, which makes the latter a logical choice for an informative parametric prior for
. The inverted gamma probability distribution is given by:
(24)
where v and
are the shape and scale parameters.
3) Kernel’ prior:
The kernel probability density estimation is a non-parametric method to approximately estimate the PDF of
using a finite data set. It is given by:
(25)
where K is the kernel function and h is a positive number called the bandwidth.
2.3.1. The Jeffreys’ Prior
Assuming Jeffreys’ PDF (23) as the prior of
and using the likelihood (8) and (15), the posterior density of
is:
(26)
Thus, the Jeffreys’ Bayesian estimate of the key parameter
under the S-E and H-T loss functions, using (14) and (19), are given by:
(27)
and
(28)
We must rely on a numerical estimation because we cannot obtain close solutions for both
and
. Also note that it depends on knowing or being able to estimate the scale parameter
.
2.3.2. The Inverted Gamma Prior
The following is an examination of the problem when the prior density of
is given by the inverted gamma (24). Using the likelihood (8), the posterior density of
is given by:
(29)
Thus, the Bayesian estimates of
under the inverted gamma with respect to the S-E and H-T loss functions, using (14) and (19), are given by:
(30)
and
(31)
Here as well, we must rely on a numerical estimation because we cannot obtain close solutions for
and
. Also note that it depends on knowing or being able to estimate the scale parameter
.
2.3.3. The Kernel Prior
Assuming Kernel density (25) as the prior of
and using the likelihood (8), the posterior density of
is:
(32)
Thus, the kernel Bayesian estimates of the key parameter
under the S-E and H-T loss functions, (14) and (19), are given by:
(33)
and
(34)
We must rely on a numerical estimation because we cannot obtain close solutions for
and
. Also note that it depends on knowing or being able to estimate the scale parameter
. In addition, the kernel function,
, and bandwidth, h, will be chosen to minimize the asymptotic mean integrated squared error (AMISE) given by:
(35)
where
and
are the estimated probability density of
and the true probability density of
respectively.
Table 2 shows the acronyms and notations used in this study.
3. Results and Discussion
3.1. Numerical Simulation
A Monte Carlo simulation was used to compare the Bayesian, under the S-E and H-T loss functions, and the MLE approaches. The parameter
of the intensity function for the PLP was calculated using numerical integration techniques in conjunction with a Monte Carlo simulation to obtain its Bayesian estimates. Substituting these estimates in the intensity function we obtained the Bayesian intensity function estimates, from which the reliability function can be estimated.
For a given value of the parameter
, a stochastic value for the parameter
was generated from a prior probability density. For a pair of values of
and
, 400 samples of 40 failure times that follow a PLP were generated. This procedure was repeated 250 times and for three distinct values of
. The procedure is based on the schematic diagram given by Algorithm 1.
![]()
Table 2. Acronyms and notations used in this study.
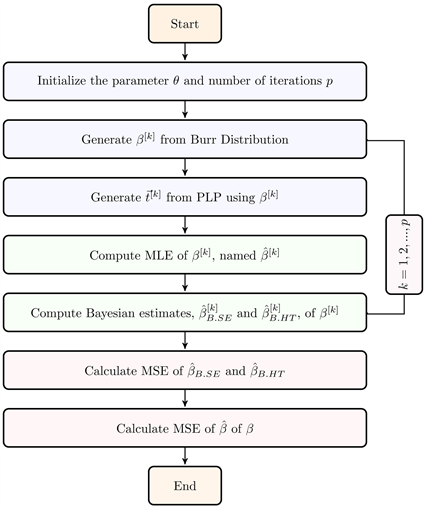
Algorithm 1. Simulation to analyze Bayesian estimates of
for a given
.
For each sample of size 40, the Bayesian estimates and MLEs of the parameter were calculated when
. The comparison is based on the mean squared error (MSE) averaged over the 100000 repetitions. The results are given in Table 3. It is observed that
and
maintain similar accuracy, where both are superior to
in estimating
.
For different sample sizes, the Bayesian estimates under S-E and H-T loss functions and the MLEs of the parameter
were calculated and averaged over 10,000 repetitions. Table 4 displays the simulated result of comparing a true value of
with respect to its MLE and Bayesian estimates for
.
It can be observed that the Bayesian estimates of
are closer to the true value than the MLE of
, where the Bayesian estimate under the H-T loss function is slightly performing better even for a very small sample size of
. A graphical comparison of the true estimate of
along with the Bayesian estimates (under both S-E and H-T loss functions) and MLE as a function of sample size is given in Figure 1.
Figure 1 shows the the excellent performance of he Bayesian estimates compared to the MLE of the key parameter
. The Bayesian estimates tend to underestimate while while the MLE estimate tends to overestimate the true value, especially for small sample sizes. The MSEs of the MLE and Bayesian estimates of
for each sample size are given below by Figure 2.
![]()
Figure 1.
estimates versus sample size.
![]()
Figure 2. MSE of
Bayesian estimates versus sample size.
![]()
Table 3. MSE for Bayesian estimates, under squared error and Higgin-Tsokos loss functions, and MLEs of
.
For the considered sample sizes, the MSEs of the Bayesian estimates of
are sufficiently smaller than the MSEs for the MLE of
. The Bayesian estimate under the H-T loss function performed slightly better than the Bayesian estimate under the S-E loss function.
![]()
Table 4. Bayesian estimates, under squared error and Higgin-Tsokos loss functions, and MLEs for the parameter
averaged over 10,000 repetitions.
Since the Bayesian estimates under both loss functions for
are superior to its MLE, Molinares and Tsokos [24] showed the improvement in the scale paramter (
) when its estimate (10) is adjusted by using the Bayesian estimate of
instead of the corresponding MLE. Therefore, we calculated the adjusted estimate of
using MLE and Bayesian estimates under S-E and H-T loss functions of
, shown in Table 5.
This proposed adjusted estimates,
and
, were averaged over the 10,000 repetitions. It can be appreciated that, based on the Bayesian influence on
,
and
are better estimates than the MLE of
(
). This also can be seen in Figure 3, which visualize the performance of
and
compared to the corresponding MLE.
Figure 3 shows the excellent performance of the adjusted estimates of
, where the adjusted estimate under the H-Twas slightly closer to the true value. The MSEs of these estimates of
are displayed in Figure 4 given below.
The MSEs of the adjusted estimates of the shape parameter (
) are significantly smaller that the MSEs of the MLE estimate. The MSEs of the adjusted estimates are then displayed alone in Figure 5 to look closer at their performance.
It can be noticed that the adjusted estimate of
under the influence of the Bayesian estimate with the H-T loss function, is better, particularly when considering small sample sizes.
We computed the adjusted estimate for the parameter
and its MSE over 10000 repetitions for different values of
and sample size
. The results are given in Table 6.
The adjusted estimate of
are were more accurate when considering small true values of
than the larger values.
![]()
Figure 3.
estimates versus sample size.
![]()
Figure 4. MSE of
Bayesian and MLE estimates versus sample size.
![]()
Figure 5. MSE of
Bayesian estimates versus sample size.
![]()
Table 5. MLE Bayesian estimates, under squared error and Higgin-Tsokos loss functions, and and MLEs for the parameter
averaged over 10,000 repetitions.
![]()
Table 6. MSE of
estimates using Bayesian estimates, under squared error and Higgin-Tsokos loss functions, and MLE of
.
The slight improvements in the estimation of the shape and scale parameters of the PLP is expected to jointly improve the estimate of the intensity function and therefore the reliability estimation of a software. For a fixed value of
and a sample size similar to the size of the collected data,
, the estimates of the intensity function
,
, and
were obtained when we use
,
, and
, respectively, in (2). That is,
(36)
(37)
(38)
Their graphs (Figure 6) reveal the superior performance of
and
.
In order to obtain Bayesian estimates of the intensity function,
and
, we substituted the Bayesian estimates of
and its corresponding
MLE in (2):
![]()
Figure 6. Graph for
and the corresponding
Bayesian estimates and MLE’s used in
,
, and
(of time t) , n = 40.
(39)
(40)
The MLE of the intensity function,
, is obtained using the MLEs of
and
. That is,
(41)
The Bayesian MLE of the intensity function under the influence of the Bayesian estimates of
, denoted by
and
, are obtained by substituting
and
with
and
, respectively, in (2):
(42)
and
(43)
To measure the robustness of
with respect to
and
, we calculated the relative efficiency (RE) of the estimate
compared to the estimate
defined by:
(44)
If
,
and
will be interpreted as equally efficient. If
,
is more efficient than
. To the contrary, if
,
is less efficient than
. Similarly, we compared
and
. Bayesian estimates and MLEs for the parameter
and
(Table 7), averaged over 10000 repetitions, are used, for
, to compare
,
and
using (44). The results are given in Table 8 and Table 9.
For the comparison of
and
, the
is less than 1, which implies that the intensity function using
and
is more efficient than the intensity function under
and
. Comparing
and
to
, we obtained a similar result, establishing the superior relative efficiency of Bayesian estimates over MLE estimates. The corresponding graphs for the intensity functions are given in Figure 7.
In addition,
and
are computed using Bayesian estimates for
and MLE estimates
, which were less efficient compare to
,
, and
. Based on the results, the Bayesian estimates under the H-T loss function will be used to analyze the real data.
![]()
Figure 7. Estimates of the intensity function (of time t) using values in Table 7, n = 40.
![]()
Table 7. Averages of the Bayesian (under the under squared error and Higgin-Tsokos loss functions) and MLE estimates of
and
.
![]()
Table 8. Intensity functions with Bayesian and MLE estimates for
and
.
![]()
Table 9. Relative efficiency of
to
and
.
3.2. Using Real Data
Using the reliability growth data from Table 1, we computed
and the adjusted estimate
in order to obtain a Bayesian intensity function under H-T loss function. We followed Algorithm 2 to obtain the Bayesian intensity function for the given real data.
For the failure data of Crow, provided in Table 1,
is approximately 0.501199 and
is approximately 2.07144. Therefore, with the use of
, the Bayesian MLE of the intensity function (
) for the data is given by:
(45)
To obtain a Bayesian MLE for the reliability function under H-T loss function, we use this Bayesian estimate for the intensity function. The analytical form for the corresponding Bayesian reliability estimate, based on the data, is given by:
(46)
Thus, the conditional reliability of the software given that the last two failure times were
and
is approximately 63%.

Algorithm 2. Estimate of the intensity function using Crow data in Table 1.
3.3. Sensitivity Analysis: Prior and Loss Function
To answer the second research question, “Is the Bayesian estimate of the intensity function,
, of the PLP sensitive to the selections of the prior (both parametric and non-parametric priors) and loss function?”, we developed a simulation procedure, Algorithm 3, given below.
The algorithm compares the Bayesian and MLE estimates of the intensity function,
, under different prior PDFs, for various sample sizes, with the H-T and S-E loss functions. The relative efficiency is used to compare these estimates of the
. The relative efficiency with a value less than 1, larger than 1, and approximately equal to 1 indicate that the Bayesian estimates under the H-T loss function are more, less, equally efficient to the Bayesian estimate under the S-E loss function and the same analysis is applied when we compared to the MLE of
, respectively. The algorithm starts by initializing the shape and scale parameters of the PLP,
and
, respectively, and the number of iterations p.
![]()
Algorithm 3. Simulation to compare Bayesian and MLE estimates of the intensity function. Notations found in Table 2.
For various sample sizes (
), random failure times (time to failures) distributed according to the PLP are simulated using the initialized values of the PLP parameters. Then, the Bayesian and MLE estimates of the key parameter
are computed and used to compute the Bayesian estimates of
, respectively. After a predetermined number of iterations, the average values of the Bayesian and MLE estimates of
and
were used to obtain the analytical forms of the
under Bayesian, for both H-T and S-E loss functions and MLE, namely
, and
, respectively. Informative parametric priors were considered such as the inverted gamma and the Burr PDFs, whereas the Jeffery prior was chosen as non-informative prior. In addition, probability kernel density function is selected as a non-parametric prior PDF. Probability kernel density estimation depends on the sample size, bandwidth, and the choice of the kernel function (
). In this study, the optimal bandwidth (
) and kernel function were chosen to minimize the asymptotic mean integrated squared error (AMISE). The simplified form of the AMISE is reduced to:
(47)
where:
.
n: sample size.
h: bandwidth.
.
is the second derivative of Burr PDF.
.
.
AMISE was numerically calculated using the optimal bandwidth, with respect to different samples sizes for each kernel function considered in this study, namely Epanechnikov, Cosine, Biweight, Triweight, Gaussian, Triangle, Uniform, Tricube, and Logistic kernel functions. The results is given by Table 10.
The minimum AMISE corresponds to the Epanechnikov kernel function (
). In addition to the Epanechnikov kernel function, the Gaussian kernel function (
) was also used in the calculation since it is commonly used for its analytical tractability.
Numerical integration techniques were used to compute the Bayesian estimates of the intensity function,
, parameters under both H-T and S-E loss functions according to the equations defined in Section 2.3, for each of the parametric and non-parametric prior PDFs. Samples of size 20, 40, 80, and
![]()
Table 10. Calculations of the AMISE with respect to different sample size, optimal bandwidth, and kernel function.
140 were generated where the parameters
and
were initialized to be 0.7054 and 1.7441, respectively. In the analytical form (17),
and
are conditioned to be positive numbers and play a big role in assigning the weight of loss depending on the estimator’s behavior, whether underestimating or overestimating. Therefore, the simulation procedure was repeated three times according to the following cases:
1)
2)
3)
The results for 1000 repetitions,
, and
, are shown in Table 11.
It can be observed that the Bayesian estimate of the
under the H-T loss function (
) and S-E loss function (
) had an outstanding efficiency compared to the MLE of the
(
) for all sample sizes and prior PDFs, with the exception of the sample sizes 20 and 40 when inverted gamma PDF was the selected prior. The
was more efficient (6% - 11% estimation improvement) compared to the
when Burr PDF is selected to be the prior. The
had similar efficiency compared to the
when Jeffrey prior is selected and for large sample sizes, whereas unsurprisingly
was more efficient for small sample sizes since Jeffrey Bayesian estimate of the key parameter
tends to overestimate and for the H-T loss function gives more exponential weight on the extreme overestimate loss than the extreme under-estimate loss when
. For Bayesian Gaussian and Epanechnikov kernel estimates, the
was more efficient compared to the
for sample sizes
and 80 with 11% - 13% of estimation improvement even though they tend to underestimate and the H-T loss function puts more exponential weight on the extreme underestimation, but tend to have similar efficiency for sample size
.
![]()
Table 11. The relative efficiency (RE) of the Bayesian estimate under H-T loss function,
when
, compared to the Bayesian estimate under S-E loss function,
, and the MLE,
, of
.
The results for 1000 repetitions,
, and
, are shown in Table 12.
Again, the Bayesian MLE estimate of the
under the H-T loss function (
) and S-E loss function (
) had an outstanding efficiency compared to the MLE of the
(
) for all sample sizes and prior PDFs. When the inverted gamma was selected as prior, the
was more efficient compared to the
for all sample sizes with an approximately 2% of estimation improvement. As expected, the
was less efficient compared to the
when Burr PDF, and Gaussian and Epanechnikov kernel densities are selected as priors for sample sizes 20 and 40, since they tend to underestimate the
parameters, and the H-T loss function tends to put more weight on the extreme overestimation than on the extreme underestimation when
. But the
and
had approximately similar efficiency for sample size
, and the
tends to be slightly more efficient for large sample size (
). The
was more efficient (4% - 24% estimation
![]()
Table 12. The relative efficiency (RE) of the Bayesian estimate under H-T loss function,
when
, compared to the Bayesian estimate under S-E loss function,
, and the MLE,
, of
.
improvement) compared to the
when Burr Jeffrey is chosen to be the prior PDF. The
had similar efficiency compared to the
for large sample sizes and when Jeffrey prior is selected, whereas unsurprisingly
was more efficient for small sample sizes since Jeffrey Bayesian estimate of the key parameter
tends to overestimate and for the H-T loss function gives more exponential weight on the extreme overestimate loss than the extreme under-estimate loss when
. For Bayesian Gaussian and Epanechnikov kernel estimates, the
was more efficient compared to the
for sample sizes
and 80 with 11% - 13% of estimation improvement even though they tend to underestimate and the H-T loss function puts more exponential weight on the extreme underestimation, but tend to have similar efficiency for sample size
.
The results for 1000 repetitions,
, and
, are shown in Table 13.
![]()
Table 13. The relative efficiency (RE) of the Bayesian estimate under H-T loss function,
when
, compared to the Bayesian estimate under S-E loss function,
, and the MLE,
, of
.
Again, the Bayesian MLE estimate of the
under the H-T loss function (
) and S-E loss function (
) had an outstanding efficiency compared to the MLE of the
(
) for all sample sizes and prior PDFs, with the exception of the sample sizes 20 and 40 when inverted gamma PDF was the selected prior. It is observed that both
and
had similar efficiency in estimation of the
for all sample sizes and priors considered in this study.
The sensitivity analysis shows that the Bayesian estimates of the intensity function of the PLP is sensitive to the prior and loss function selections. Tables 11-13 indicate the efficiency of the Bayesian estimates under the H-T loss function when compared to the Bayesian estimate under S-E loss function and to the MLE, given that the engineer should choose the values of
and
based on his/her estimator’s behaviour (underestimating and over estimating). Moreover,
is the recommended choice when the engineer selects Burr or kernel PDFs as their prior knowledge of the behavior of the key parameter
. On the other hand, if the engineer does not have a prior knowledge of the key parameter
, it is still recommended to use H-T loss function in the Bayesian calculations with
.
Thus far, we showed the more accuracy in estimating a software reliability when applying the Bayesian analysis under the H-T loss function compared to the Bayesian analysis under the S-E loss function and the MLE of the subject analysis. The performed extensive analysis requires efficiency in utilizing the existing programming languages, which therefore requires some programming experience, we developed an interactive user interface application using Wolfram language to compute and visualize the Bayesian and maximum likelihood estimates of the intensity and reliability functions of the Power Law Process for a given data.
4. Conclusions
In the present study, we developed the analytical Bayesian estimates of the key parameter
, under Higgin-Tsokos and squared-error loss functions, in the intensity function where the underlying failure distribution is the Power Law Process, that is used for software reliability assessment, among others. The reliability function of the subject model is written analytically as a function of the intensity function.
The behavior of the key parameter
is characterized by the Burr type XII probability distribution. Real data and numerical simulation were used to illustrate not only the robustness of the squared-error loss function being challenged by the assumption of the Higgins-Tsokos loss function, but also the efficiency improvement in the estimation of the intensity function of PLP under Higgins-Tsokos loss function (
). For 100,000 samples of software failure times, based on Monte Carlo simulations and sample size of 40, the Bayesian estimate of
under Higgins-Tsokos loss function (
) performed slightly better than the Bayesian estimate of
under squared-error loss function (
) with respect to three different values of
(0.5, 1.7441, 4). Even for different sample sizes (20, 30, 40, 50, 60, 70, 80, 100, 120, 140, and 160), similar results were achieved using
,
, and averaged over 10,000 samples of software failure times.
As the MLE of the second parameter in the intensity function (
) depends on the estimate of
, the adjusted estimate of
provided better performance compared to the adjusted estimate of
using the
. Moreover, the Relative Efficiency was used to compare the intensity function estimations, mainly using MLEs for both
and
(
), using Bayesian estimate of
under the squared-error loss function and Bayesian of
(
), and using Bayesian estimate of
under the Higgins-Tsokos loss function and Bayesian of
(
), showing that
is more efficient in estimating the intensity function
with about 12% estimation improvement.
With respect to the question: Is the Bayesian estimate of the intensity function,
, of the PLP sensitive to the selections of the prior, both parametric and non-parametric priors, and loss function? The parametric prior PDFs were Burr, Jeffrey, and inverted gamma probability distributions whereas the non-parametric priors were Gaussian and Epanechnikov kernel densities. The priors’ parameters were estimated using Crow failure times. Additionally, the optimal bandwidth and kernel functions were selected to minimize the asymptotic mean integrated squared error.
Using the developed algorithm, 1000 samples of software failure times with respect to four sample sizes of n (20, 40, 80, and 140) were generated from the PLP to compare the Bayesian estimates of
under the subject priors and loss functions using the Relative Efficiency among them. The simulation procedure was repeated three times for the cases when
,
, and
. The results showed the efficacy of the Bayesian estimates of H-T loss function, and the choice of the
and
values depends on the prior knowledge of the key parameter
. It is recommended to choose values where
when the engineer thinks the prior knowledge of
is best characterized by Burr or Kernel based probability distributions with a proper justification, whereas a choice of
and Jeffery’s prior is suggested when the engineer does not have a prior knowledge of
.
Thus, based on this aspect of our analysis, we can conclude that the Bayesian analysis approach under Higgins-Tsokos loss function not only as robust as the Bayesian analysis approach under squared error loss function but also performed better, where both are superior to the maximum likelihood approach in estimating the reliability function of the Power Law Process. The interactive user interface application can be used without any prior coding knowledge to compute and visualize the Bayesian and maximum likelihood estimates of the intensity and reliability functions of the Power Law Process for a given data.
Acknowledgements
We thank Majmaah University for funding the research, along with the support provided by the University of South Florida.