Numerical Methods in Financial and Actuarial Applications: A Stochastic Maximum Principle Approach ()
1. Introduction
A portfolio simulation approach to the valuation of optimal portfolio policies appears to be the only viable approach in many financial and actuarial applications.
While usually numerical methods are formulated within a dynamic programming approach to the optimization problem, we explore the possibility to state a numerical scheme that goes through the solution of the forward-backward stochastic differential equation (FBSDE, hereafter) which arises from the maximum principle formulation of the optimal control problem. We exemplify situations where the maximum principle approach to portfolio optimization jointly with the simulation approach to the backward stochastic differential equation (BSDE, hereafter) provides an efficient alternative to standard simulation methods based on direct Montecarlo simulation and produces a reliable estimate of the optimal allocation strategies.
Our computation approach relies on the least-squares Monte Carlo approach for estimating the conditional expectations made popular in financial mathematics by of Longstaff and Schwartz [1] and it was first applied to BSDEs and analyzed in this setting by Bouchard and Touzi [2] , Gobet et al. [3] and Lemor et al. [4] .
More recently, Bender and Steiner [5] focus on the least-squares Monte Carlo scheme for approximating the solution of a BSDE by using basis functions which form a system of martingales.
The paper is organized as follows. Section 2 introduces the stochastic maximum principle and the economic implications of the first-order adjoint process. Section 3 illustrates some known results on the FBSDEs. In Section 4 we analyze the simulation approach to the BSDEs. Section 5 is devoted to the discussion of some financial and actuarial applications.
2. The Stochastic Maximum Principle
We consider a finite time horizon
, and a complete probability space
with a filtration
, where
is the time variable. The filtration
is the completion of the natural filtration generated by a m-dimensional standard Brownian motion
,
. This signifies that the system noise represented by the Brownian motion is the only source of uncertainty in the problem, and the past information about the noise is available to the decision-maker. Sometimes we will use a starting point
. In this case
will be the complete filtration generated by
.
Let us consider the time evolution of the system described by a state variable
whose dynamics follow the stochastic differential equation:
(1)
where
,
, and
is a convex body of
.
The function
is the control variable representing the policy of the decision-maker at any time and it is required to be progressively measurable since the controller knows what happened up to the moment, but not able to foretell what is going to happen later on, due to the uncertainty of the system.
The objective is to minimize a given cost functional defined as:
(2)
with
and
, over the set of the admissible controls:
Of course, for any
, by standard assumptions on b, σ, ν that can be found, e.g., in Yong and Zhou ( [6] , Theorem 6.17, p. 50), the above state Equation (1) admits a unique solution
(in the sense of Yong and Zhou [6] , Definition 6.15, pp. 48-49) and
is called an admissible pair.
Then, the problem is to find an optimal control
such that:
The corresponding
and
are called optimal state trajectory and optimal pair, respectively.
Recalling that, for any given function φ,
we may also treat maximization problems with the same steps.
The Hamiltonian function associated to our problem is given by:
while the generalized Hamiltonian function is given by the following FBSDE:
The extended Hamiltonian system corresponding to the pair
is given by the following FBSDE:
where:
is the H-function.
In the extended Hamiltonian system above, the second and the third relations are clearly BSDEs and called adjoint equation of the first-order and adjoint equation of the second-order respectively, while the last relation is the so-called maximum condition.
The state variable joint with the related first-order adjoint equation are called Hamiltonian system.
Definition 2.1.
is called an optimal 6-tuple (resp. admissible) if
is an optimal pair, (resp. is an admissible pair),
is an adapted solution of the first-order adjoint equation and
is an adapted solution of the second-order adjoint equation.
We assume the following hypothesis for
.
Hypothesis 2.2. The map φ is twice continuously differentiable in
and there exist a constant
and a modulus of continuity
such that, for all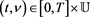 ,
,
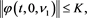
and, 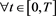 ,
, 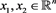 ,
, 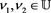 ,
,
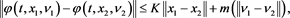
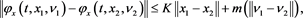
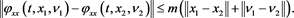
The following statement is the well-known (Pontryagin) stochastic maximum principle, which gives a set of first-order necessary condition for 6-tuple pairs.
Theorem 2.3 (stochastic maximum principle). Let Hypothesis 2.2 hold and 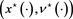 be an optimal pair. Then the optimal 6-tuple
be an optimal pair. Then the optimal 6-tuple 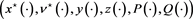 solves the above extended stochastic Hamiltonian system.
solves the above extended stochastic Hamiltonian system.
Proof. See, e.g., Yong and Zhou ( [6] , Chapter 3, pp. 123-137).
Hypothesis 2.4. The maps 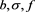 are locally Lipschitz in
are locally Lipschitz in 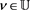 and their derivatives in
and their derivatives in 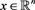 are continuous in
are continuous in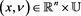 .
.
Theorem 2.5 (sufficient condition of optimality). Let Hypotheses 2.2 and 2.4 hold. Suppose that 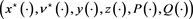 is an admissible 6-tuple,
is an admissible 6-tuple, 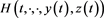 is concave P-a.s., and the maximum condition is verified, i.e.
is concave P-a.s., and the maximum condition is verified, i.e.
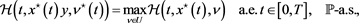
then 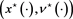 is an optimal pair.
is an optimal pair.
Proof. See, e.g., Yong and Zhou ( [6] , Chapter 3, pp. 139-140).
Economic Implications of the First-Order Adjoint Process
The first-order order adjoint process plays a very important role in economic theory that we aim to introduce.
Assume that the framework of the previous section hold, but for simplicity all the variables are scalar-valued. For any initial data![]() , consider the controlled system:
, consider the controlled system:
![]()
the set of admissible control:
![]()
and the functional:
![]()
where ![]() is the unique solution to the above state equation.
is the unique solution to the above state equation.
We have the following definition.
Definition 2.6. The following:
![]()
is called value function.
If ![]() and
and ![]() is also continuous, then:
is also continuous, then:
![]()
At any time t suppose ![]() is slightly changed to
is slightly changed to![]() , then by (3a) we obtain:
, then by (3a) we obtain:
![]()
Intuitively, the above relation shows that the value of ![]() measures the rate of variation of the value function induced by an infinitesimal increase of the level of the state variable. Accordingly, the adjoint variable is called the marginal value of the optimal state.
measures the rate of variation of the value function induced by an infinitesimal increase of the level of the state variable. Accordingly, the adjoint variable is called the marginal value of the optimal state.
Suppose the increment of the optimal state value could be purchased in the market. Thus, the adjoint variable represents the maximum price it would be worth paying an additional amount of the state. For this reason, the adjoint variable is also called the shadow price of the optimal state.
Moreover, if ![]() is the convex dual value function of V, then the following relationships apply (see, e.g., Di Giacinto et al. [7] ):
is the convex dual value function of V, then the following relationships apply (see, e.g., Di Giacinto et al. [7] ):
It is straightforward from the above relations to derive the following interesting relations:
![]()
3. FBSDEs and BSDEs
The conditions of optimality derived from the maximum principle are in general FBSDEs. In the following we review the basic results on the mathematical theory that explores existence uniqueness and solvability of these equations. In particular, we will focus on the interesting examples that will be useful in the applications when the FBSDE is decoupled, i.e. the forward component is independent from the backward one.
While for the forward component the basic properties are known from the theory of general stochastic processes, it is important to review the results about the backward component that is determined by a BSDE. Basic mathematical results on this class of equations are reviewed in the following subsection.
BSDEs
We consider the following controlled (unidimensional) BSDE:
![]()
where ![]() is the control variable
is the control variable ![]() -progressively measurable, the pair
-progressively measurable, the pair ![]() is the data, called the terminal condition and the generator (or driver), respectively. Here, x is
is the data, called the terminal condition and the generator (or driver), respectively. Here, x is ![]() -measurable and
-measurable and ![]() is
is ![]() -measurable for all
-measurable for all![]() . A solution to the above BSDE is a pair of processes
. A solution to the above BSDE is a pair of processes ![]() adapted to the given filtration.
adapted to the given filtration.
Solving an ordinary differential equation formulated as a terminal value problem or an initial value problem on the same time interval ![]() is equivalent under the time-reversing transformation
is equivalent under the time-reversing transformation![]() ,
,![]() . On the contrary, when we are looking for a solution to a BSDE that is adapted respect to the given filtration we know only the past information, but are not able to know what is going on to occur in the future. This means that it is not possible simply reverse the time to find a solution as it would remove the adaptiveness.
. On the contrary, when we are looking for a solution to a BSDE that is adapted respect to the given filtration we know only the past information, but are not able to know what is going on to occur in the future. This means that it is not possible simply reverse the time to find a solution as it would remove the adaptiveness.
The theory of BSDEs is an active domain of research due to its connections with stochastic control, mathematical finance, and partial differential equations (see, e.g., the survey elaborated by El Karoui et al. [8] ).
BSDEs were pioneered by Bismut [9] [10] [11] within the stochastic optimal control. Existence and uniqueness of adapted solutions were first proved by Pardoux and Peng [12] in a Brownian setting, with integrable terminal condition and generators that fulfill a canonical Lipschitz assumption in the space variables. These results were extended by Lepeltier and San Martín [13] to continuous drivers with linear growth. Since then, a lot of efforts have been made in order to study the well posedness of these equations.
With regards to the quadratic growth BSDEs, the proof of the existence of solutions are easily obtained under rather general framework. Conversely, the question of the uniqueness results is not trivial and requires stronger assumptions on the solutions.
In the standard framework where the terminal condition is bounded, in Kobylanski [14] obtained for the martingale case the uniqueness of the solution under some Lipschitz conditions. This seminal result has been extended in several directions, among others, by Tevzadze [15] , Morlais [16] , and Briand-Elie [17] . In Tevzadze [15] as well as in Briand-Elie [17] the proof in Kobylanski [14] was simplified in some less general cases. In particular, Tevzadze [15] showed the proof for the existence and uniqueness of a bounded solution in the Lipschitz quadratic, while Briand-Elie [17] incorporated delayed quadratic BSDEs, whose generator depends on the recent past of the component of the solution. Morlais [16] treated quadratic BSDEs driven by a continuous martingale and applied the corresponding results to study some related utility maximization problem.
Concerning the quadratic BSDEs with unbounded terminal value, Briand-Hu [18] first showed the existence of solution, while Barrieu and El Karoui [19] revisited the existence by a direct forward method that does not apply the result of Kobylanski [14] .
Barrieu and El Karoui [19] also showed some uniqueness results that require stronger assumptions comparing with the other existing literature. However, their alternative approach has other potential applications as numerical simulations of quadratic BSDEs and risk measures and their dual representations.
The uniqueness result was tackled for the first time by Briand and Hu [20] under some restrictive conditions. In particular, the authors proved the uniqueness among the solutions of quadratic BSDEs with convex generators and unbounded terminal conditions which admit every exponential moments. Delbaen et al. [21] [22] , strengthened the above result proving that uniqueness holds among solutions reducing the required order of exponential moments.
4. Simulation Approach to BSDE
The simulation approach to BSDE applying Longstaff and Schwartz [1] has been investigated the first time by Bouchard and Touzi [2] . In order to consider the numerical solution of a BSDE consider for simmplicity the simple case where the backward component is a pure martingale, i.e. the drift component is zero. Then the determination of ![]() and
and ![]() can be performed observing at time T,
can be performed observing at time T, ![]() and can be obtained simulating forward
and can be obtained simulating forward![]() .
.
Given the random variable![]() , computation of
, computation of ![]() can be performed computing a conditional expectation using the simulation approach of Longstaff and Schwartz [1] relying on a linear regression and moving backward. The exact choice of the polynomial family is relevant only for the numerical efficiency. For example, using Hermite polynomials we obtain:
can be performed computing a conditional expectation using the simulation approach of Longstaff and Schwartz [1] relying on a linear regression and moving backward. The exact choice of the polynomial family is relevant only for the numerical efficiency. For example, using Hermite polynomials we obtain:
![]()
where the standard error of the residual ![]() is of order:
is of order:
![]()
where ![]() is the conditional variance.
is the conditional variance.
Note that the approximation of ![]() can be simply derived considering a term by term differentiation
can be simply derived considering a term by term differentiation![]() :
:
![]()
We will show that in many cases, in particular in the applications that we will discuss later, the approximation to the pair:
![]()
provides an approximate solution of the BSDE that can be used to recover the optimal control strategies using the optimality conditions.
5. Applications
In the following applications we will always consider a standard Black & Scholes market, i.e. a risk free bond![]() , whose dynamics are:
, whose dynamics are:
![]()
where ![]() is the risk free rate, and a traded risky asset
is the risk free rate, and a traded risky asset ![]() (stock market index) whose dynamics are:
(stock market index) whose dynamics are:
![]()
where ![]() is the volatility,
is the volatility, ![]() is the drift, and
is the drift, and ![]() is the instantaneous risk premium, i.e. the Sharpe ratio.
is the instantaneous risk premium, i.e. the Sharpe ratio.
5.1. Classical Merton Problem
In this subsection we illustrate the application of the stochastic maximum principle to the solution of the well-known Merton’s portfolio allocation and consumption problem (see, e.g., Merton [23] ) when the utility has a constant relative risk-aversion as in Merton [24] .
The state equation describing the dynamics of wealth is given by:
![]()
where ![]() is the investment strategy representing the proportion of wealth invested in the risky asset,
is the investment strategy representing the proportion of wealth invested in the risky asset, ![]() is the consumption stategy, and
is the consumption stategy, and ![]() are the market parameters of the Black-Scholes model.
are the market parameters of the Black-Scholes model.
The preferences of the agent are given by the following utility function:
![]()
while the bequest function is:
![]()
The objective functional we aim to optimize is given by:
![]()
where the control ![]() belongs to the following set of admissible strategies:
belongs to the following set of admissible strategies:
![]()
and ![]() is the subjective discount factor.
is the subjective discount factor.
The problem we aim to solve is to find an optimal control ![]() such that:
such that:
![]()
The stochastic Hamiltonian system associated to the problem is:
![]()
while the second-order adjoint equation is:
![]()
It can be easily found that:
![]()
with:
![]()
is the only adapted solution to the second-order adjoint equation. Observe that ![]() for all
for all![]() .
.
The corresponding H-function is:
![]()
and the maximum condition is:
![]()
It is easy to show that the function ![]() is concave and has a unique maximum point on
is concave and has a unique maximum point on ![]() given by:
given by:
![]() (4)
(4)
if and only if ![]() for all
for all![]() .
.
Remark 5.1. By the stochastic maximum principle theorem a necessary conditions for ![]() to be optimal is:
to be optimal is:
![]()
Clearly the first-order adjoint process y―which represents the risk factor―plays a role in turning the convex function![]() , i.e. the Hamiltonian along the optimal state trajectory, into a concave one
, i.e. the Hamiltonian along the optimal state trajectory, into a concave one![]() , i.e. the H-function along the optimal state trajectory, previously shown.
, i.e. the H-function along the optimal state trajectory, previously shown.
By plugging (5a)-(5b) into the stochastic Hamiltonian system, we obtain:
![]()
Once we find an adapted solution ![]() of the above, a candidate for the optimal control can be deduced by (4). To this regard, suppose
of the above, a candidate for the optimal control can be deduced by (4). To this regard, suppose ![]() is an adapted solution and take the following guess function for
is an adapted solution and take the following guess function for![]() :
:
![]()
for some deterministic function![]() .
.
We would like to determine the equation that ![]() should satisfy. To this end, we differentiate the above using Itô formula:
should satisfy. To this end, we differentiate the above using Itô formula:
![]()
i.e.
![]()
Comparing the above relation with the first-adjoint equation that appears in the previous stochastic Hamiltonian system, we have:
![]()
The above (6b)-(6c) is a Bernoulli equation whose solution is:
![]() (7)
(7)
where ![]() and subject to the condition
and subject to the condition![]() , i.e.
, i.e.
![]() (8)
(8)
With the position of ![]() stated in (7) and the condition on ρ stated in (8), the pair of processes:
stated in (7) and the condition on ρ stated in (8), the pair of processes:
![]()
is the only square integrable adapted solution to the first-order adjoint equation.
The necessary condition required from the stochastic maximum principle theorem leads to the following policy:
![]() (9)
(9)
and state trajectory (simply obtained substituting the expression of the above control policy to the stochastic Hamiltonian system):
![]() (10)
(10)
as candidates to be an optimal pair.
Finally, a simple check shows that sufficient conditions of optimality are satisfied. We conclude that ![]() pointed out to (10) and (9) is an optimal pair of the classical Merton optimization problem. Therefore, the following result holds.
pointed out to (10) and (9) is an optimal pair of the classical Merton optimization problem. Therefore, the following result holds.
Proposition 5.2. There exists a unique optimal investment and consumption strategy given by:
![]()
where ![]() must satisfies the following Bernoulli ordinary differential equation:
must satisfies the following Bernoulli ordinary differential equation:
![]()
whose solution is:
![]()
under the condition:
![]()
5.2. Merton Model with a Retirement Endowment
In a standard Black & Scholes market, the dynamics of wealth are given by:
![]()
where ![]() are the usual market parameters.
are the usual market parameters.
In addition, the agent is endowed with a nontradable investment I in a pension fund whose risky component is perfectly correlated with the market index. The dynamics of the investement are given by:
![]()
where ![]() in order to avoid arbitrage opportunities.
in order to avoid arbitrage opportunities.
The preferences of the agent are described by the following constant relative risk aversion utility function:
![]()
while the bequest function is:
![]()
where, for simplicity, we set the parameter of the classical Merton problem![]() .
.
At the terminal date T, the investor receives a liquid amount determined by an initial endowment which is invested in the stock market and cannot be withdrawn until maturity. In her hedging policy, the investor must optimally take into account both the liquid investment which can be continuously traded, and the lump sum amount that she will receive at the final date T and is also exposed to stock market risk fluctuations.
Given the functional:
![]()
and the set of admissible control strategies:
![]()
our goal is to find an optimal control ![]() such that:
such that:
![]()
The agent keeps into account her investment for retirement in her optimal allocation policy of the disposable wealth x0.
The solution procedure is parallel to the standard Merton problem even though the allocation policy changes and an hedging term takes into account the stochastic opportunity set due to the presence of the investment I for retirement.
By applying the stochastic maximum principle we find the following stochastic Hamiltonian system:
![]()
The results can be tested since it is possible to evaluate the optimal proportion. As a matter of fact, due to the market completness it is possible to estimate the exact value of the optimal proportion ![]() as:
as:
![]()
Following the line applied for solving the classical Merton problem, we can also determine the optimal consumption strategy![]() , and so the optimal control
, and so the optimal control ![]() is:
is:
![]()
where the deterministic function ![]() has been previously defined in (7) in the classical Merton problem.
has been previously defined in (7) in the classical Merton problem.
Now, we show how to derive numerically the allocation exploiting the following observation: due to market completeness the dynamics of the dual variable is known and corresponds to a log-normal process with drift equal to the opposite of the risk free rate r and volatility equal to the Sharpe ratio l.
Given the above observation, the above Hamiltonian system the control variables appear only in the forward equation. By using the observation on duality and Riesz representation (see, e.g., Yong and Zhou [6] , chapter 7, p. 353) it is possible to switch the backward and forward equations. Therefore, in this latter representation the stochastic Hamiltonian system can be rewritten as:
![]()
where ![]() is determined by the condition
is determined by the condition
![]() (11)
(11)
We need to solve a FBSDE. The forward process is determined by the adjoint process, i.e. deflator ![]() whose expression is known. The backward components which must be obtained are
whose expression is known. The backward components which must be obtained are ![]() and they uniquely determine the optimal pair
and they uniquely determine the optimal pair ![]() as functions of the forward process
as functions of the forward process![]() .
.
The numerical determination of the optimal investment strategy can be obtained considering a least square regression procedure for![]() .
.
We choose the following parameters:
![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
,
![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
,
where NP stands for number of paths considered and K is the number of discretization steps. In this case, the theoretical and numerical values averaged over 50 evaluations of the extended Merton proportion are:
and the relative error is of order 2.20%.
5.3. Income Drawdown Option with Minimum Guarantee
In this subsection we consider a second interesting application of the same approach that provides a numerical way to extend the analysis carried out in Di Giacinto et al. [7] which is briefly described below. The numerical extension we explore is necessary in order to assess the impact of the running cost as defined in the model.
We consider a defined contribution pension plan for a single representative participant during the decumulation phase, i.e. after retirement. Depending on the law and the rules of the scheme in many countries the retiree is allowed:
1) to defer annuitization at some time after retirement (this option is named, e.g., in UK “income drawdown option”, in US “phased withdrawals”);
2) to withdraw periodic income from the fund;
3) to invest the rest of the fund in the period between retirement and annuitization.
Thus, the pensioner has three degrees of freedom:
1) to decide when to annuitize (if ever);
2) to decide how much of the fund to withdraw at any time between retirement and ultimate annuitization (if any);
3) to decide what investment strategy to adopt in investing the fund at her disposal.
The first choice (i.e. the optimal time of annuitization) can be tackled by defining an optimal stopping time problem. The last two choices (i.e. the optimal consumption and investment selection) represent a classical investment and consumption problem, which can be solved using, e.g., stochastic optimal control techniques.
The contribution by Di Giacinto et al. [7] is the solution in closed form of the optimal control problem with constraints regarding the third choice (i.e. the investment choice) using a quadratic loss function and by applying the dynamic programming approach.
In a standard Black & Scholes market, the state equation is given by:
![]()
where ![]() is the process representing the fund wealth of the pensioner, x0 is the fund wealth at the retirement date
is the process representing the fund wealth of the pensioner, x0 is the fund wealth at the retirement date![]() ,
, ![]() is the dollar amount invested in the risky asset, b0 is the consumption rate of the pensioner, and
is the dollar amount invested in the risky asset, b0 is the consumption rate of the pensioner, and ![]() are the usual market parameters.
are the usual market parameters.
The objective functional is given by:
![]()
where ![]() and x is the sum of the subjective discount factor ρ and of the force of mortality δ, i.e.
and x is the sum of the subjective discount factor ρ and of the force of mortality δ, i.e.![]() .
.
The loss function has the following quadratic shape:
![]()
while ![]() is the target function. We choose:
is the target function. We choose:
![]()
where![]() .
.
Constraints on the strategies and on the wealth are considered in the model. More precisely:
i) “no short selling” on the strategies:
![]()
ii) “no ruin” on the wealth:
![]()
with the “safety level” ![]() set as:
set as:
![]()
where![]() .
.
Given the set of admissible controls:
![]()
the optimal control problem to be solved is to find an optimal control ![]() such that:
such that:
![]()
We are able to express the related stochastic Hamiltonian system as:
![]()
where y0 is determined following the same procedure applied in (11).
Note that the above Hamiltonian system is linear, thus the Riesz duality can be applied to switch the forward and the backward components. While for ![]() the Hamiltonian system is represented by a decoupled FBSDE, so the previous numerical approach can be applied, for
the Hamiltonian system is represented by a decoupled FBSDE, so the previous numerical approach can be applied, for ![]() the FBSDE is coupled but still linear and therefore numerically solvable by applying a different numerical approach, e.g., the four step scheme illustrated by Ma et al. [25] .
the FBSDE is coupled but still linear and therefore numerically solvable by applying a different numerical approach, e.g., the four step scheme illustrated by Ma et al. [25] .
In the following we illustrate the simulation paths of the optimal investment strategy for ![]() and some realistic parametrization. The parameter chosen are:
and some realistic parametrization. The parameter chosen are:
![]()
![]()
where j is the retiree age, b0 is computed by applying the projected Italian males life table and NP stands for performed number of paths. The final target ![]() and the final guarantee
and the final guarantee ![]() are subjective and determined by the pensioner’s risk aversion.
are subjective and determined by the pensioner’s risk aversion.
![]()
6. Conclusions
In the above analysis, we showed how to use the stochastic maximum principle to reformulate conventional portfolio consumption models in order to explore their solution through the numerical solution of a linear stochastic hamiltonian system. We showed in a number of applications the flexibility of this methodology.
In the next future we aim to explore the performance of this method in two important extensions: a multidimensional state variable problems and in presence of optimal stopping control strategies. This last extension is particularly relevant for actuarial applications.