An Improvement of Pedestrian Detection Method with Multiple Resolutions ()
1. Introduction
Pedestrian detection has been a hotspot in computer vision research [1] . The corresponding detection algorithm has been developed towards high precision and instantaneity [2] [3] . For a driverless automobile, the usage of which has become popular nowadays, its intelligent system should be able to detect the locations and quantities of pedestrians ahead, to analyze the road conditions, and to guarantee the safety of these pedestrians [4] . For such cases, the pedestrian detection is an inevitable procedure. The pedestrian detection problem is difficult because that the target people often have various characteristics and the surrounding environments also change frequently [5] .
The pedestrian sizes in real world are different from each other. Besides the height diversity of different people, many imaging differences are incurred by the different distances between people and the camera. Figure 1 shows a high resolution corresponds to the large pedestrian scale and a low resolution corresponds to the small pedestrian scale in the process of pedestrian detection.
Pedestrians contain rich information in the case of high resolution [6] , and it is more likely for them to be detected. Even if they are locally overlapped, many algorithms have the capability to detect these targets [7] . However, in the case low resolution, the pedestrians which contain a small amount of information cannot be detected easily. Meanwhile, low resolution pedestrians are very vulnerable to the interferences of the surrounding environments. In most cases, a detection algorithm has a much better detection result for the high resolution pedestrians than that for the low resolution pedestrians. Dalal and Triggs [8] proposed a HOG detector. If the detection window is fixed to 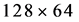 pixels during training and detection, this detector can generate good effects at the time of detecting pedestrians with pixels greater than
pixels during training and detection, this detector can generate good effects at the time of detecting pedestrians with pixels greater than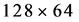 . However, when the target pedestrians are smaller than
. However, when the target pedestrians are smaller than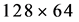 , the detector almost fails to detect any pedestrian. Although the target can be increased to larger than
, the detector almost fails to detect any pedestrian. Although the target can be increased to larger than 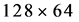 pixels by means of interpolation, the detection accuracy is still brought down. The DPM pedestrian detector makes use of a root filter and several part filters to describe the pedestrians. Information in the pedestrians of high resolution is sufficient.
pixels by means of interpolation, the detection accuracy is still brought down. The DPM pedestrian detector makes use of a root filter and several part filters to describe the pedestrians. Information in the pedestrians of high resolution is sufficient.
Figure 2(a) and Figure 2(b) are results obtained by utilizing a standard DPM
![]()
Figure 1. The pedestrians with Multiple resolution in a sample picture.
![]()
![]() (a) (b)
(a) (b)
Figure 2. The detection result of standard DPM. (a) The part filter and root filter in DPM (b) The detection result of standard DPM.
detector to detect pedestrians in Figure 1. It is obvious that the small-scale pedestrians cannot be detected successfully. Therefore, the overall detection effect can be improved if we can improve the detection effect for low resolution pedestrians and prevent affecting the detection effect for high resolution pedestrians.
In this paper, we propose a multi-resolution DPM pedestrian detection algorithm, which takes advantage of the standard DPM framework in training the pedestrian with the resolution factor as a hidden variable. For the high resolution pedestrians, the response can be figured out in the first place. And its location can be estimated with the combination of this high resolution response and the response under a corresponding low resolution. However, for the low resolution pedestrians, the judgment over possible locations of these targets is carried out by only calculating the responses under the low resolution. High resolution and low resolution are only intuitive concepts in the common sense. In addition, resolution is closely associated with the heights of pedestrian samples.
Structure of this paper is as follows. In section 2, we thoroughly illustrate the DPM model for pedestrian detection, depicts the DPM learning algorithm, and describe the parameter initialization and the training procedures. In section 3, we illustrate the improved DPM algorithm in case of multi-resolution targets, by analyzing the features of pedestrian detection under multi-resolution, and describing the improved multi-resolution DPM pedestrian detection algorithm in detail. In Section 4, we apply this improved algorithm to a general dataset to comparatively analyze the experimental results.
2. Overview of Related Theory
2.1. Deformable Part Model
The deformable part model (DPM) consists of a root filter and several part filters to describe the pedestrians. Specifically, the root filter describes each pedestrian as a whole, while each part filters describe a part of the pedestrian, such as the head and hand [9] . In this way, the constructed model can effectively capture the pedestrian information, and adapt well to the changes of body posture and dressing of the pedestrian [10] .
The DPM pedestrian detection is a x-resolution detection method. However, to some extent the algorithm is able to adapt to different resolutions, because of the following three reasons.
Firstly, the DPM features are based on the image pyramid HOG features [11] , which are adaptable to the scale variation within a certain range. Secondly, because the available data sets often consist of a large number of pedestrian samples, we have enough information for training a DPM model. For example, over 84% positive samples in the Caltech pedestrian database are over 30 pixels in height, over 16% positive samples are more than 80 pixels in height, and around 69% positive samples are between 30 pixels and 80 pixels in height.
2.2. Hard Example Mining (SVM)
In the training procedure, there are usually more negative samples than the available positive samples. Taking pedestrian detection for example, the images of pedestrians are positive samples, and the images without pedestrian are negative samples. In this case, 105 samples can be generated from an image, most of which are negative samples. It is almost impossible to take all negative samples into consideration. Therefore, we select the positive samples and the hard examples for constructing a training set. The hard examples are referred to those which are incorrectly classified at the first time. The Bootstrapping classification algorithm is employed for training an initial negative sample set. The algorithm collects the incorrectly classified samples at the first time, add these samples to the negative sample set to form the hard samples. The process is repeated for several times until a good classification result is achieved. We define the hard example and easy sample as follows:
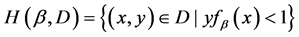 (1)
(1)
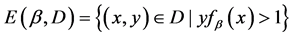 (2)
(2)
where,  denotes the incorrectly classified samples at the first time or the samples located within the classification boundary
denotes the incorrectly classified samples at the first time or the samples located within the classification boundary  denote the correctly classified samples. The samples on the classification boundary do not belong to
denote the correctly classified samples. The samples on the classification boundary do not belong to 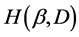 or
or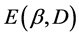 .
.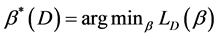 .
.
Because 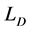 is strictly convex,
is strictly convex, 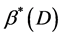 is the single result of the optimized problem. Given a sample library
is the single result of the optimized problem. Given a sample library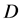 , we want to find a small sample set
, we want to find a small sample set 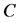 with
with ![]() and
and![]() . To solve this problem, we firstly define an initial set which contains all the training samples. We train an LSVM model, and renew the previous set by removing the simple samples and by adding the new hard examples.
. To solve this problem, we firstly define an initial set which contains all the training samples. We train an LSVM model, and renew the previous set by removing the simple samples and by adding the new hard examples.
2.3. Hard Example Mining with LSVM
For the LSVM, mining hard examples is equivalent to optimize ![]() rather than
rather than![]() . This constraint turns the whole optimization problem to a convex optimization problem.
. This constraint turns the whole optimization problem to a convex optimization problem.
As for the hard example mining with SVM, we define an set with samples in the form of![]() , in which
, in which![]() . In the real application, the set consists of
. In the real application, the set consists of ![]() rather than
rather than![]() . We define a vector set
. We define a vector set![]() , in which i denotes sample index, and
, in which i denotes sample index, and ![]() with
with![]() . Because the hidden variable
. Because the hidden variable ![]() is not fixed, for each sample
is not fixed, for each sample![]() , there may be multiple corresponding
, there may be multiple corresponding![]() . Then we define
. Then we define ![]() as the index of vectors in the vector set
as the index of vectors in the vector set![]() , and dene the target function for
, and dene the target function for ![]() with the feature vectors in
with the feature vectors in![]() :
:
![]() (3)
(3)
![]() can be optimized with the gradient-descent algorithm. We use
can be optimized with the gradient-descent algorithm. We use ![]() as the set of feature factors
as the set of feature factors![]() .
.
The gradient-descent algorithm is described as follows.
1. ![]() is the learning rate for iteration
is the learning rate for iteration![]() .
.
2. ![]() is the index for samples in
is the index for samples in![]() .
.
3. ![]() .
.
4. If![]() , then
, then![]() .
.
5. Otherwise,![]() .
.
We set ![]() and try to find
and try to find ![]() in a sample set
in a sample set ![]() of small size.
of small size.
As for the hard example mining with standard SVM, we define the feature vectors for hard and simple example in training set ![]() as follows.
as follows.
![]()
![]() (4)
(4)
We find the hard examples by calculating![]() .
. ![]() is defined as the initial feature vector set.
is defined as the initial feature vector set.
The LSVM hard example mining algorithm is given below:
1. Train model with![]() .
.
2. If![]() , stop the iteration and return
, stop the iteration and return![]() .
.
3. Remove the simple samples by![]() , where
, where![]() .
.
4. Add new hard examples by![]() , where
, where![]() .
.
In the 3rd step simple samples are removed from the training set, while in the 4th step new hard examples are added to the training set. The entire iteration procedure terminates when there are no hard examples to add.
3. Pedestrian Detection with Multi-Resolution DPM
3.1. Fixed Resolution Model
Let ![]() represent an image window, and
represent an image window, and ![]() represent the image feature. As many slide window detection algorithms, we have
represent the image feature. As many slide window detection algorithms, we have
![]() (5)
(5)
in which ![]() is marked as pedestrian. We train the above model with the positive and negative samples of the training set
is marked as pedestrian. We train the above model with the positive and negative samples of the training set![]() , in which
, in which![]() . The commonly available training algorithms include SVM and boosting, and we employ the linear SVM for training the parameter
. The commonly available training algorithms include SVM and boosting, and we employ the linear SVM for training the parameter ![]()
![]() (6)
(6)
in which ![]() is assumed to be of a fixed size during training and testing. We define a feature vector
is assumed to be of a fixed size during training and testing. We define a feature vector ![]() to deal with the windows of different sizes.
to deal with the windows of different sizes.
3.2. Models with Fixed Resolutions
If an image contains objects of different resolutions at the same time, the detector of a fixed resolution usually cannot detect all different objects simultaneously. Because we can describe the different distances of pedestrians in an image, for each window ![]() we can dene a binary variable s to represent the distance of a pedestrian. We use
we can dene a binary variable s to represent the distance of a pedestrian. We use ![]() to represent the distant target pedestrians, and use
to represent the distant target pedestrians, and use ![]() to denote the close target pedestrian. Our classifier is the same as the previous one.
to denote the close target pedestrian. Our classifier is the same as the previous one.![]() ,
,
![]() (7)
(7)
where ![]() and
and ![]() denote the features at different scales, such as a pedestrian of 50 pixels and a pedestrian of 100 pixels.
denote the features at different scales, such as a pedestrian of 50 pixels and a pedestrian of 100 pixels.
3.3. Multi-Scale Multi-Resolution Model
For the close target pedestrians with s = 1, we can transform a model for high- resolution targets to two models for different resolution targets. For instance, we can transform a 100 pixels window into two windows of 50 pixels, and calculate the features at the small window scale. In this way, we can transform a model for high-resolution target to two models for different resolution targets:
![]() (8)
(8)
With the above formula we can transform the object features at a fixed resolution into features at different resolutions. However, because ![]() is different at different resolutions, the linear SVM is not suitable for training models.
is different at different resolutions, the linear SVM is not suitable for training models.
3.4. Multi-Resolution DPM Algorithm for Pedestrian Detection
A significant feature of the above method is that a rigid template is used for object detection at both large and small scales. The description operators at low levels (e.g., HOG feature) are adaptable to small image deformation [12] . However, such method is not applicable in case of large scales. For example, HOG feature detector is invariant to different postures of a 50 pixels height pedestrian, but not invariant to the 100 pixels height pedestrians. If we are to detect a large- scale target, we can choose a low-resolution template. And if we hope to gain more information, we can select a high-resolution template. For a good adaptability to the deformation at a large scale, we adopt a DPM model. As a hidden parameter ![]() is defined in the DPM model, we use
is defined in the DPM model, we use ![]() as the combination of HOG feature and the deviation.
as the combination of HOG feature and the deviation.
![]() (9)
(9)
The classifier passes through all the hidden variables at last, and calculates
![]() :
:
![]() (10)
(10)
![]() is transformed into a standard linear template for calculating the response at a low resolution. For calculating the response at a high resolution,
is transformed into a standard linear template for calculating the response at a low resolution. For calculating the response at a high resolution, ![]() would need to search all part models to nd the model which makes the maximum response. Suppose the distances between different parts and the root filter are independent from each other, the following formula can be calculated with the
would need to search all part models to nd the model which makes the maximum response. Suppose the distances between different parts and the root filter are independent from each other, the following formula can be calculated with the ![]() algorithm:
algorithm:
![]() (11)
(11)
in which ![]() denotes the location of part
denotes the location of part![]() ,
, ![]() denotes the template of part
denotes the template of part![]() ,
, ![]() denotes the deformable model of part
denotes the deformable model of part ![]() and
and![]() , and
, and ![]() denotes the boundary.
denotes the boundary. ![]() represents the HOG feature at location
represents the HOG feature at location![]() , and
, and ![]() represents the deformation difference between part
represents the deformation difference between part ![]() and part
and part![]() . For a given training set
. For a given training set![]() , we can employ the LSVM algorithm for training the model parameter
, we can employ the LSVM algorithm for training the model parameter![]() .
.
At the stage of model training, we set ![]() if the training sample has a large scale
if the training sample has a large scale![]() , in which
, in which ![]() is no longer a hidden variable. And we set
is no longer a hidden variable. And we set ![]() if the training sample has a small scale
if the training sample has a small scale![]() , in which
, in which ![]() is not a hidden variable, either. If the training sample has a medium scale
is not a hidden variable, either. If the training sample has a medium scale![]() , the training sample can be considered as both a high resolution object and a low resolution object. In this case,
, the training sample can be considered as both a high resolution object and a low resolution object. In this case, ![]() becomes a hidden variable, which can be added to the set of hidden variables of the LSVM model for training. The rough procedure consists of the random initialization of variables
becomes a hidden variable, which can be added to the set of hidden variables of the LSVM model for training. The rough procedure consists of the random initialization of variables ![]() and
and![]() , the calculation of model parameter
, the calculation of model parameter ![]() in model training, and the acquisition of value for the hidden variable in accordance to the maximum response which would be taken into the next iteration.
in model training, and the acquisition of value for the hidden variable in accordance to the maximum response which would be taken into the next iteration.
4. Experiment Process and Dataset
4.1. Overview of the Algorithm
Our proposed multi-resolution DPM is similar to a hybrid deformable model with two target models. But there are also big differences between these methods. Firstly, many parameters are shared in our deformable model, while all parameters in the hybrid deformable model are independent from each other. Secondly, our multi-resolution deformable model consist a different procedure for the variable![]() . At the training state,
. At the training state, ![]() is a hidden variable, while at the test state
is a hidden variable, while at the test state ![]() would become a visible variable. The procedure of pedestrian detection by multi-resolution DPM is shown in Figure 3.
would become a visible variable. The procedure of pedestrian detection by multi-resolution DPM is shown in Figure 3.
First, DPM parameters ![]() and
and ![]() are initialized by the initialization method as illustrated before.
are initialized by the initialization method as illustrated before. ![]() is the model parameter at a low resolution, while
is the model parameter at a low resolution, while ![]() is the model parameter at a high resolution. At the training state, we set the value of
is the model parameter at a high resolution. At the training state, we set the value of ![]() by considering the height
by considering the height ![]() of a trained sample, for which
of a trained sample, for which ![]() if
if ![]() and
and ![]() if
if![]() . For the samples with
. For the samples with![]() , LSVM can be used to train a standard DPM model, which renders the model parameter
, LSVM can be used to train a standard DPM model, which renders the model parameter![]() . For the samples with
. For the samples with![]() , a linear SVM can be used to train a DPM model (no hidden variable is involved), which renders the model parameter
, a linear SVM can be used to train a DPM model (no hidden variable is involved), which renders the model parameter![]() . For the samples with height
. For the samples with height![]() , we add
, we add ![]() to the set of hidden variables, and
to the set of hidden variables, and
![]()
Figure 3. The processing steps of pedestrian detection on multiple resolutions.
train the model with the LSVM algorithm.
4.2. Evaluation Method
Whole Image Evaluation
The detection result for an image consist of a set of bounding boxes ![]() and a corresponding confidence score [13] . If the detection result
and a corresponding confidence score [13] . If the detection result ![]() and the standard result
and the standard result ![]() has a great extent of overlapping, we consider the detection result matches the standard result. We define that a detection result matches the standard result if they have over 50% parts overlapped:
has a great extent of overlapping, we consider the detection result matches the standard result. We define that a detection result matches the standard result if they have over 50% parts overlapped:
![]() (12)
(12)
Each ![]() can match to at most one
can match to at most one![]() , which means that every detected
, which means that every detected ![]() can only match one
can only match one ![]() but not multiple
but not multiple![]() . Therefore, if a detection result
. Therefore, if a detection result ![]() could match multiple
could match multiple ![]() we only select the
we only select the ![]() with the highest confidence as the final detection result. If a
with the highest confidence as the final detection result. If a ![]() is not matched with any
is not matched with any![]() , it is labeled as false positive. And if a
, it is labeled as false positive. And if a ![]() is not matched with any
is not matched with any![]() , it is labeled as false negatives as well.
, it is labeled as false negatives as well.
4.3. Experiment Dataset
1. INRIA
The INRIA data set is a static pedestrian detection database which has been widely employed in recent researches. The training set consists of 614 positive samples (containing 2416 pedestrians) and 1218 negative samples. The test set consists of 288 positive samples (containing 1126 pedestrians) and 453 negative samples. Images in the INRIA data set are mainly collected from google, GRAZ- 01 and personal photographs.
2. Caltech Pedestrian Database
The Caltech Pedestrian Database is a large scale database. It consists of videos of 640 × 480 pixel with 30 frames per second, captured by in-vehicle cameras for about 10 hours. Within these videos, 250,000 frames (around 137 minutes), 350,000 bounding boxes, and 2300 pedestrians are manually annotated by human experts. The data set is divided into 10 sets, among which sets 00 - 05 are used for training, and sets 06 - 10 are used for testing. In our experiment, we also employ sets 00 - 05 for training and sets 06-10 for testing.
Pillor [14] divide samples in the Caltech Pedestrian Library into distant![]() , medium
, medium ![]() and near
and near ![]() types, according to the heights
types, according to the heights ![]() of pedestrians.
of pedestrians.
The model feature of DPM is based on the HOG feature of the image pyramid, and DPM has good adaptability to a certain range of scale changes. Usually the pedestrian samples in our data set are not too small, so there is enough information for building the DPM model.
In the Caltech pedestrian database, the average height of the samples is 48 pixels. More than 84% of the positive samples have height greater than 30 pixels, more than 16% of the positive samples have height greater than 80 pixels, and about 69% of the positive samples have height from 30 to 80 pixels. In the case of high-resolution![]() , the DPM model show very good results in traditional DPM model tests. In this work we defined targets with height
, the DPM model show very good results in traditional DPM model tests. In this work we defined targets with height ![]() as the high resolution target, targets with height
as the high resolution target, targets with height ![]() as the low resolution targets, and targets with height
as the low resolution targets, and targets with height ![]() as the unknown resolution targets in which case the resolution factor is treated as a hidden variable.
as the unknown resolution targets in which case the resolution factor is treated as a hidden variable.
5. Results and Discuss
5.1. The Result in INRIA
There are nearly one thousand pictures in INRIA pedestrian database. Our model is trained on the INRIA training set, and evaluated on the INRIA test set. The multi-resolution DPM-based pedestrian detection algorithm acquires a precision of 87.2% on INRIA pedestrian database, which is slightly better than 86.9% as the precision of the standard DPM. This is mainly because that there are too few picture samples in this data set, and the pedestrian scale is too big in the pictures. Only a few pictures contain the small-scale pedestrians, in which case the multi-resolution DPM detector cannot change the detection method at the high resolution. Therefore, the detection result is almost the same as the standard DPM result.
5.2. The Result in Caltech Database
Training our model on the Caltech pedestrian database is more challenging than on the INRIA dataset. The number of samples in the Caltech pedestrian dataset is large, which is much larger than the number of samples in the INRIA dataset. The Caltech pedestrian dataset consists samples of ![]() pixel resolution, in which many pedestrian targets of small scales are included.
pixel resolution, in which many pedestrian targets of small scales are included.
In this section, set0 to set5 in Caltech database are employed for training, and set6 to set11 are chosen for testing. Figures 4(a)-(d) show the detection results for all-distance, near-distance, middle-distance and far-distance samples, respectively. Specifically, the near-distance corresponds to pedestrians with height ![]() pixel, the middle-distance corresponds to pedestrians with height
pixel, the middle-distance corresponds to pedestrians with height ![]() but
but![]() , and the far-distance corresponds to pedestrian with height
, and the far-distance corresponds to pedestrian with height![]() .
.
The experiment result suggests that the multi-resolution DPM algorithm renders better detection results than that the standard DPM in terms of all testing sets, Figure 4(a) shows the result based on all test samples. The multi-reso- lution DPM-based pedestrian detection algorithm achieves a missing rate of 52% (1FPPI), which is much better than the missing rate 59% (1FPPI) achieved by the DPM pedestrian detection algorithm. This result suggesting that multi-reso- lution DPM has better detection effect than the standard DPM. In terms of the large-scale samples (![]() ) in Caltech database, the multi-resolution DPM- based detection algorithm renders a missing rate of 18% (1FPPI), while the standard DPM-based detection algorithm renders a missing rate of 26% (1FPPI),
) in Caltech database, the multi-resolution DPM- based detection algorithm renders a missing rate of 18% (1FPPI), while the standard DPM-based detection algorithm renders a missing rate of 26% (1FPPI),
![]()
Figure 4. The result on Caltech pedestrian data set by different distance. (a) The result on all-distance samples; (b) The result on near-distance; (c) The result on middle-distance; (d) The result on far-distance samples.
which suggests that the multi-resolution DPM also outperforms the standard DPM for large-scale targets. For small-scale samples, the difference in both models is not as obvious as shown in Figure 4(b), which is mainly because, that the useful information at small scales is very limited (the objects at less than 30 pixels are known as small-scale objects). At this point, the detection algorithm cannot acquire enough information for detection.
5.3. The Result in Part of Caltech Database
In order to better explain the experiment result, we further select 3000 pictures from the standard Caltech database for evaluation. This experiment is conducted to compare the detection effects of the detection algorithm at a high resolution (corresponding to the standard DPM algorithm), the detection algorithm at a low resolution (corresponding to merely the root filter-based DPM algorithm), and the proposed multi-resolution DPM algorithm.
The experiment result is shown in Figure 5, in which LR represents the low- resolution detection algorithm, HR represents the high-resolution detection al-
![]()
Figure 5. The results of different-scale targets on the subset of the Caltech pedestrian data set. (a) Large-scale target; (b) Small-scale target.
gorithm, and MR represents the multi-resolution detection algorithm.
The results of large-scale target ![]() detection as shown in Figure 5(a), the multi-resolution DPM algorithm achieves similar performance as the standard DPM algorithm. Both algorithms are better than the low-resolution detector.
detection as shown in Figure 5(a), the multi-resolution DPM algorithm achieves similar performance as the standard DPM algorithm. Both algorithms are better than the low-resolution detector.
Figure 5(b) shows the terms of the small-scale target ![]() detection, we find that the detection effect of the standard DPM algorithm drops quickly as the target scale grows small. The detection effect of the multi-resolution DPM algorithm is slightly lower than that of the rigid template.
detection, we find that the detection effect of the standard DPM algorithm drops quickly as the target scale grows small. The detection effect of the multi-resolution DPM algorithm is slightly lower than that of the rigid template.
According to the overall comparison is shown in Figure 6, the multi-resolu- tion DPM algorithm is better than the high-resolution detection algorithm on the testing set. We find that the missing rate on test set is 52% with a rigid template. This is lower than 59%, which is the missing rate with the standard DPM algorithm. This is because most of the pedestrian samples are with height![]() , and even the high-resolution algorithm cannot detect the small- scale targets. The standard DPM algorithm achieves a good detection effect for the large-scale targets.
, and even the high-resolution algorithm cannot detect the small- scale targets. The standard DPM algorithm achieves a good detection effect for the large-scale targets.
6. Conclusion
In this paper we proposed a Pedestrian Detection Method at Multiple Resolution. Especially during pedestrian detection under the high resolution, such an algorithm can generate very significant effects. However, targets in images acquired in the real world are under diverse resolutions in most cases. Considering this, the standard DPM is subjected to great limitations. Here, a multi-resolution DPM algorithm based on the standard DPM algorithm is presented. In this way, pedestrian detection is fixed to different resolutions. For example, pedestrians under the high resolution can be detected through a deformable part model, while those under the low resolution are detected based on the rigid template. In
![]()
Figure 6. The result on the subset of the Caltech pedestrian data set.
Caltech, omission ratio of a multi-resolution DPM detector was 52% (1FPPI); comparatively, it became 59% (1FPPI) as far as a standard DPM detector was concerned. In the large-scale sample set of Caltech, omission ratio of the multi- resolution and the standard DPM detectors were 18% (1FPPI) and 26% (1FPPI) respectively. The general results of proposed method are better than the standard DPM.
Acknowledgements
This research was partially supported by JSPS KAKENHI Grant Numbers 15K00425, 15K00309.