1. Introduction
It is well known that the PID controllers [1] [2] [3] are still used extensively in industrial control and studied intensively in current control area because the PID control not only has exceeding simplicity and strong robustness but also can effectively deal with nonlinearity and uncertainties of dynamics and asymptotic stability can be achieved accordingly.
A major drawback of PID control is that it often suffers a serious loss of performance, that is, causes large overshoot and long settling time, even may lead to instability due to unlimited integral action. To disguise this drawback, various PID-like control laws have been proposed to improve the transient performance. For example, a saturated-P, and differential feedback plus a PI controller driven by a bounded nonlinear function of position errors [4] , a linear PD plus an integral action of a nonlinear function of position errors [5] , and a linear PD plus a double integral action driven by the positions error and the filtered position [6] are presented recently. An unconquerable drawback of PID-like controller above is that its tuning procedure is very complex, tedious and difficult to obtain the satisfied transient control performance because these PID-like controllers often produce surge and big overshoot, even may lead to instability. It is obvious that all the PID-like control laws above can only improve the control performance in some extent but the intrinsic shortcomings of PID control are not absolutely eliminated from its root.
In 2009, general integral control [7] appeared. After that various general integral control laws were presented. For example, general concave integral control [8] , general convex integral control [9] , general bounded integral control [10] and the generalization of the integrator and integral control action [11] were all developed by resorting to an ordinary control along with a known Lyapunov function. Although these general integral control laws above can effectively deal with the intrinsic shortcomings of PID control and have the better control performance; these PID-like and general integral controllers above are all unintelligent. Hence, it is very interesting and challenging to seek for PID control laws with intelligence, especially self-learning ability online.
Based on the statement above, it is obvious that the error, 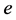 , and its derivative,
, and its derivative, 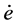 are the fundamental elements of PID control, which are the essential information used in manual control, and then the human manual control law can be described, as follows:
are the fundamental elements of PID control, which are the essential information used in manual control, and then the human manual control law can be described, as follows:
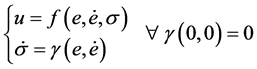 (1)
(1)
where 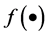 and
and 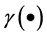 can be arbitrary linear or nonlinear function.
can be arbitrary linear or nonlinear function.
Based on the cognition above, through simulating the intelligent behavior of human manual control, this paper proposes a simple and practicable control law, named Human-Simulating Intelligent PID control (HSI-PID). The main contributions are as follows: 1) a simple and practical formulation to represent prior knowledge and experiences of manual control is developed, and then it is easy to be used to design a controller; 2) the simple and practical tuning rules with the explicit physical meaning are introduced, and then it is easy to tune a high performance controller; 3) two kinds of fire new and simple integrator and integral control action is proposed, and then the intrinsic shortcomings of PID control is removed in principle; 4) HSI-PID control not only can easily incorporate prior knowledge and experiences of experts control into the controller but also can automatically acquire knowledge of control experiences from the past control behavior to correct the control action online, and then can make the motion of system identically track the desired response. Moreover, simulation results verify our conclusions again.
The remainder of the paper is organized as follows: Section 2 describes Human-Simulating PID control law and definitions. Section 3 presents the tuning rules of human-simulating intelligent PID control. Example and simulation are provided in Section 4. Conclusions are presented in Section 5.
2. Human-Simulating PID Control Law
An experienced operator will anticipate all types of disturbances to the system. It would be very difficult to reproduce in an automatic controller the many judgments that an average person makes daily and unconsciously. So it is more realistic for us to simulate the control procedure of the human manual control in order to obtain as nearly perfect operation as possible.
A general human manual control procedure can be described as follows: 1) when the error is large and the error tends to increase, the human controller produces a largest control action, and attempt to restrain the error to increase continuously; 2) when the error decreases, the human controller will gradually reduce the control action to limit the degressive rate of error for avoiding the system out of control; 3) when the error is small and tend to zero, the human controller produces a small or even inverted control action, and attempt to prevent the overshoot; 4) when the error is large, the human controller produces an inaccuracy control action, if the error is small, the human controller produces a precise control action; 5) the amplitude of control action is determined by the size of error and tendency that the error is changing.
Based on the statements above, it is easy to see that the human manual control law is in a good agreement with the sigmoid-type function. So, the sigmoid-type function can be used to simulating the procedure of human manual control, that is, approximating Equation (1).
For the purpose of this paper, it is convenient to introduce the following definition.
Definition 1. Tow Error [12] , 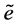
In human manual control procedure: if 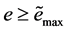 or
or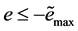 , and then
, and then 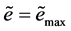 or
or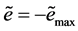 ; If
; If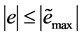 , and then
, and then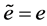 . For simulating the behavior that human deals with the information, Tow Error,
. For simulating the behavior that human deals with the information, Tow Error, 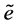 is defined by,
is defined by,
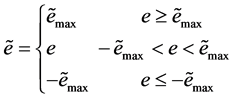 (2)
(2)
where 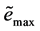 is a positive constant, maximum of Tow Error.
is a positive constant, maximum of Tow Error.
The schematic graph of Tow Error is shown in Figure 1.
Definition 2. Desired Acceleration [12] , 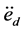
In human manual control procedure, one usually has an explicit expectation for the speed of response and overshoot. Namely, under the control action, the error, 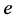 will change in conformity to the desired response. It cannot too fast, also cannot too slow, eventually the error,
will change in conformity to the desired response. It cannot too fast, also cannot too slow, eventually the error, 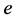 and its derivative,
and its derivative, ![]() all tend to
all tend to
zero in the meantime. In another words, there is some kinds of the cooperative relationship between the error and its rate in human manual control procedure. For simulating the behavior of human manual control, it is indispensable to introduce the concept of Desired Acceleration, ![]() , and which can be taken as the sigmoid-type function,
, and which can be taken as the sigmoid-type function,
![]() (3)
(3)
where ![]() is a positive constant, maximum of Desired Acceleration;
is a positive constant, maximum of Desired Acceleration; ![]() and
and ![]() are all positive constants.
are all positive constants.
Discussion 1. When the initial condition and parameter of Equation (3) is given, the desired velocity, ![]() , and desired error,
, and desired error, ![]() can be obtain. This shows that Equation (3) not only describes the desired response speed and desired response error of human manual control procedure but also constructs a kind of cooperative relationship between the error and its rate. So, Equation (3) can be viewed as a representation of prior knowledge and experiences of human manual control.
can be obtain. This shows that Equation (3) not only describes the desired response speed and desired response error of human manual control procedure but also constructs a kind of cooperative relationship between the error and its rate. So, Equation (3) can be viewed as a representation of prior knowledge and experiences of human manual control.
The schematic graph of Desired Acceleration is shown in Figure 2.
2.1. PD-Type Human-Simulating Intelligent Control Law
From Equation (3), if the controller output is assimilated to the force acting on the motion object, and using Newton’s laws of motion, the controller output, ![]() can be given by the following equation:
can be given by the following equation:
![]() (4)
(4)
where ![]() is a positive constant, if we carry on the motion control, and then it is the mass or inertia, if we carry on the process control, and then it is a constant like the mass.
is a positive constant, if we carry on the motion control, and then it is the mass or inertia, if we carry on the process control, and then it is a constant like the mass.
Combining Equations (2) and (3) into Equation (4) results in PD-type Human-simulating intelligent control law, as follows:
![]() (5)
(5)
Discussion 2. From Figure 2, Equation (2), and control law (5), it is easy to see that: 1) when ![]() and the direction of
and the direction of ![]() and
and ![]() is identical, the control law (5) produce a largest and inaccuracy control action,
is identical, the control law (5) produce a largest and inaccuracy control action, ![]() to restrain the error to increase continuously; 2) when
to restrain the error to increase continuously; 2) when![]() , and the direction of
, and the direction of ![]() and
and ![]() is reverse,
is reverse, ![]() will gradually decrease to limit the degressive rate of error for avoiding the system out of control; 3) when
will gradually decrease to limit the degressive rate of error for avoiding the system out of control; 3) when![]() , and the direction of
, and the direction of ![]() and
and ![]() is reverse,
is reverse, ![]() will become a small or even inverted control action to prevent the overshoot; 4) when
will become a small or even inverted control action to prevent the overshoot; 4) when ![]() and
and ![]() all tend to zero,
all tend to zero, ![]() tend to zero, too. In another words, the control action,
tend to zero, too. In another words, the control action, ![]() can make the error reduce along the desired law, eventually the error, its rate and control action all tend to zero in the meantime. These show that the PD-type Human-simulating intelligent control law; (5) is in a good agreement with the optimal procedure of manual operation.
can make the error reduce along the desired law, eventually the error, its rate and control action all tend to zero in the meantime. These show that the PD-type Human-simulating intelligent control law; (5) is in a good agreement with the optimal procedure of manual operation.
2.2. PID-Type Human-Simulating Intelligent Control Law
It is obvious that PD-type Human-simulating intelligent control law described by Equation (5) is not capable of reducing the error to zero and making the error strictly change along the desired law when a constant disturbances act on the controlled system. However, an experienced operator can automatically adjust the control output and produce an accurate control action to eliminate or reject all kinds of disturbances. This procedure can be described as follows: according to the current state of the controlled system and the former control experiences, the human controller produces a control action, if the control action just counteracts the disturbance action, and then he maintains the control action; if the control action is large, and then he decreases the control action, vice versa. In other words, through correcting the control action again and again, eventually the operator can make the error change along the desired law and stabilize the error at zero or acceptable limit, and then the control action tends to a constant or changes along with the change of disturbances.
Based on the statements above, it is easy to know that: 1) simulating the control procedure that human manual control eliminates or rejects all kinds of the disturbances is very challenging because the disturbances are often uncertain and varying-time; 2) human manual control is a procedure of automatically accumulating the control experiences, and self-adapting the action of all kinds of disturbances and uncertainties of dynamics by exploration. However, integral control just is of this kind of ability. So, for simulating the manual control behavior above, the integral action must be introduced into the control law, as follows:
![]() (6)
(6)
![]() (7)
(7)
where ![]() is a positive constant.
is a positive constant.
Discussion 3. Compared to PID-like control and general integral control laws reported by [1] - [11] , the striking features of the control laws (6) and (7) are:
1) The prior knowledge and experiences of manual control can be incorporated into the controller easily;
2) When![]() , the integrator output remains constant; if the integral action is larger than the one needed,
, the integrator output remains constant; if the integral action is larger than the one needed, ![]() consequentially increases, and then the integrator output will instantly decrease, vice versa. However, the integrator output of PID-like control [1] - [6] continues to increase unless the error passes through zero, and then for making the integral control action tends to a constant, the error is usually needed to pass through zero repeatedly. Therefore, the intrinsic shortcoming of PID control can be removed in principle;
consequentially increases, and then the integrator output will instantly decrease, vice versa. However, the integrator output of PID-like control [1] - [6] continues to increase unless the error passes through zero, and then for making the integral control action tends to a constant, the error is usually needed to pass through zero repeatedly. Therefore, the intrinsic shortcoming of PID control can be removed in principle;
3) Just as the statement above, the basic principle of the integrator in (6) and (7) is similar with the general integrator in [7] [8] [9] [10] [11] , but their main difference is that Tow error is introduced into the integrator here. Therefore, the integral control action proposed here can constraint the response rate. However, the integral control action in [7] [8] [9] [10] [11] do not place restrictions on the response rate, and then it is easy to lead to instability since the response rate could be too rapid. Therefore, two kinds of the integrator and integral action in (6) and (7) are fire new;
4) The integral control action is a compensation for the shortcoming of PD control action, or an accumulation of the past PD control action. This method to adjust integral action can be viewed as the accumulation of the past control experiences or learning from past control experiences;
5) Combining the demonstration above and Discussion 2, it is easy to see that the control laws (6) and (7) can strictly constraint the motion of system along the trajectories of desired response.
All these show that the control laws proposed here not only can easily incorporate prior knowledge and experiences of experts control into the controller but also can automatically acquire knowledge of control experiences from the past control behavior to correct the control action online, and then can make the motion of system identically track the desired response. Therefore, the control laws (6) and (7) should have more rapid adaptive or self-learning ability, better flexibility and stronger robustness, and can easily yield higher control performance. This is why it is called human-simulating intelligent PID control.
3. Tuning Controller
For practical applications in industrial control, it is very necessary and interesting to develop a simple and efficient method to tune the controller proposed here. So, the purpose of this section is to address the tuning rules of human-simulating intelligent PID control.
In the control laws (6) and (7), there are six parameters. The parameters, ![]() and
and ![]() have the explicit physical meaning, and often are all fixed constant, so easy to be determined. In practice, if
have the explicit physical meaning, and often are all fixed constant, so easy to be determined. In practice, if ![]() or
or ![]() is uncertain and the biggest control action,
is uncertain and the biggest control action, ![]() is known, the product,
is known, the product, ![]() as a whole can directly be taken as
as a whole can directly be taken as ![]() or an appropriate value in contrast to
or an appropriate value in contrast to![]() .
. ![]() is a characteristic variable, which indicates the controller should carry on a braking action when
is a characteristic variable, which indicates the controller should carry on a braking action when ![]() and
and ![]() is slightly less than
is slightly less than ![]() in order to avoid big overshoot, oscillation and instability, so
in order to avoid big overshoot, oscillation and instability, so ![]() can be determined by the experience of human manual control or be measured directly. Hence, only three parameters,
can be determined by the experience of human manual control or be measured directly. Hence, only three parameters, ![]() ,
, ![]() and
and ![]() need be determined.
need be determined.
From the control law (5), it is easy to know that: 1) when ![]() and
and![]() , the output of sigmoid-type function should amount to the maximum, and then
, the output of sigmoid-type function should amount to the maximum, and then ![]() can be obtained; 2) when
can be obtained; 2) when ![]() and
and![]() , the controller output should amount to the maximum, too, and then
, the controller output should amount to the maximum, too, and then ![]() can be determined by the following formula:
can be determined by the following formula:
![]() (8)
(8)
where ![]() is the maximum of the acceptable speed of response, it can be measured directly when the biggest control action acts on the controlled system.
is the maximum of the acceptable speed of response, it can be measured directly when the biggest control action acts on the controlled system.
The purpose that we introduce the integral action is to complete rejection of uncertain disturbances and dynamics of controlled system, and yield zero steady- state error. So, the integral action in the control laws is indispensable for most industrial control applications. This leads to that ![]() become a very key parameter, which tuning rules are very difficult, even impossible to be described by an accurate formulation. In general, if
become a very key parameter, which tuning rules are very difficult, even impossible to be described by an accurate formulation. In general, if ![]() is too small, the integral action increases the correction slowly, this easily results in a slower speed of response and a longer settling time; if
is too small, the integral action increases the correction slowly, this easily results in a slower speed of response and a longer settling time; if ![]() is too large, the integral action increases the correction more rapidly, this could cause large overshoot, even may lead to instability. The optimum response is always achieved through some sort of compromise.
is too large, the integral action increases the correction more rapidly, this could cause large overshoot, even may lead to instability. The optimum response is always achieved through some sort of compromise.
In general, the settings above are usually close to the final values. However, a realistic expectation is that some tweaking of the parameters will be required to obtain a transient performance of high control. In practice, if the overshoot is large, which means that speed of response is too rapid or maximum of Tow Error is too small, and then we can fix ![]() and increase
and increase![]() , or simultaneity increase
, or simultaneity increase ![]() and
and![]() , vice versa.
, vice versa.
4. Example and Simulation
To illustrate the effect of the control laws, a two link manipulators shown in Figure 3 is considered. Its dynamics are of the following form:
![]()
where:![]() ,
,
![]() ,
, ![]() ,
,
![]() ,
, ![]()
![]() .
.
The normal parameter values of system are selected as:![]() ,
, ![]() ,
, ![]() ,
,![]() .
.
The desired (set point) positions are chosen as:
when![]() ,
, ![]() ,
,![]() ; when
; when![]() ,
, ![]() ,
,![]() ; when
; when![]() ,
,![]() .
.
The tangent hyperbolic function, ![]() is used as the sigmoid function. The parameters of control law (6) are given as:
is used as the sigmoid function. The parameters of control law (6) are given as:![]() ,
, ![]() ,
,![]() ,
, ![]() ,
,![]() .
.
The simulations with sampling period of 1ms are implemented. Under the normal and perturbed parameters, the motion trajectories of Link1 and Link2 are shown in Figure 4 and Figure 5, respectively. The dotted lines are the simulation results under normal parameters. The real lines are the simulation results under perturbed parameters, that is, ![]() is substituted for
is substituted for ![]() when
when![]() , corresponding to moving payload of 5 kg.
, corresponding to moving payload of 5 kg.
From the simulation results, it is easy to see that: 1) the optimum response can be achieved by a set of control parameters in the whole domain of interest, even under the case that the payload is changed abruptly; 2) the motion trajectories shown in Figure 4 and Figure 5 are almost completely identical, this illustrates
![]()
Figure 3. The two link robot manipulators.
that the motion of the system can identically track the desired response, whether the controlled system has the strong nonlinearity and uncertainties of dynamics or not, even under the actions of uncertain, varying-time and strong disturbances. All these demonstrates that: 1) HIS-PID controller not only can remove the intrinsic shortcomings of PID control but also has the faster self-learning ability, better flexibility and stronger robustness with respect to uncertain nonlinear system; 2) HIS-PID control not only can effectively deal with uncertain nonlinear system but also it is a powerful and practical tool to solve the control design problem of dynamics with the nonlinear and uncertain actions.
5. Conclusions
In this paper, a novel human-simulating intelligent PID control law is founded by simulating the intelligent behavior of human manual control. The main contributions are as follows: 1) the formulation to represent prior knowledge and experiences of manual control are very simple and practical, and then it is easy to be used to design a controller; 2) the simple and practical tuning rules with the explicit physical meaning are introduced, and then it is easy to tune a high performance controller; 3) two kinds of fire new and simple integrator and integral action are proposed, and then the intrinsic shortcomings of PID control are removed in principle; 4) the control laws proposed here not only can easily incorporate prior knowledge and experiences of experts control into the controller but also can automatically acquire knowledge of control experiences from the past control behavior to correct the control action online, and then can make the motion of system identically track the desired response. Moreover, simulation results verify our conclusions again.
For HSI-PID control, this paper is only a starting point and further cooperative research is needed to make progress in this area. For example, the design theory to ensure system stability is not developed.