Fault Identification of Power Grid Based on Wide-Area Differential Current and K-Means Clustering ()
1. Introduction
With the increasingly complex structure and the continuously extended scale of power grid, the traditional backup protection based on local information can not satisfy requirements of complex and various operation modes of power grid. The rapid development of computer technologies and the wide-area measurement technologies make global information being introduced into protection possible. In recent years, extensive researches on wide-area backup protection have carried on at home and abroad, mainly concentrating in tripping strategies and fault areas identification of wide-area protection, etc. [1] [2] [3] [4].
The wide-area relay protection system given in reference [5] is based on the current differential principle, and problems such as protection domain division rules for wide-area protection are discussed in the reference. A wide-area current differential protection principle based on multi Agent is proposed in the reference [6], where an expert system is used to realize the area division of current differential protection, and the wide-area differential protection is achieved through coordination between protection Agents.
In order to further study the application of artificial intelligence algorithm in wide-area backup protection and improve the accuracy of fault identification with wide-area information under different working conditions, a new method for identifying failure areas of power grid based on k-means clustering according to wide-area positive sequence fault component differential current information is proposed on the basis of previous studies.
2. K-Means Clustering
The K-means clustering algorithm is to cluster based on the objective function of a prototype. In the algorithm, the sum of distances from data to corresponding clustering centers is the optimized objective function and adjusting rules for iterative operations are obtained by finding the extremum solution of the function. The mean value of data samples of each cluster subset is selected as the clustering center of the corresponding cluster. The main idea of the algorithm is to divide data into different classes through iteration processes, and makes the clustering criterion function used to evaluate the clustering performance to achieve its optimum, so that each cluster generated can be compact inside and independent to others. The number k of clusters and a database contains n objects are needed to be input first of all, and then n objects are divided into k clusters, which can make the minimum square error criterion [7] [8]. For a given data set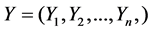 , processes of K-means clustering algorithm are as follows [8] [9]:
, processes of K-means clustering algorithm are as follows [8] [9]:
1) Select K initial clustering centers: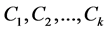 .
.
2) Calculate the distance d from every data to each clustering center, and divide the data to the corresponding cluster 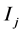 with the minimum distance d.
with the minimum distance d.
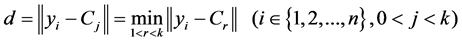 .
.
3) Calculate the new clustering center vector 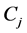 of each cluster,
of each cluster,
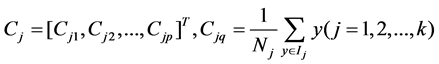
In which, q is the attribute number of data, 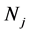 is the number of data that the j-th cluster
is the number of data that the j-th cluster 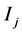 included.
included.
4) Repeat processes 2 and 3, until each cluster is no longer changes.
3. Fault Domain Identification Based on K-Means
3.1. The Analysis of Clustering Objects
Node IEDs of power grid are installed at substation nodes, corresponding to substations. Each node IED has the same status, whose works are mainly to collect electric information sent from related line IEDs, and upload them to wide-area decision center after preliminary processing. Line IEDs mainly acquire positive sequence current fault component information at installation places, and upload the information to the corresponding grid node IEDs. Fault domains of power grid can be identified by the fault recognition algorithm to process the data uploaded by node IEDs. The associated domain of node IED is defined in this paper. As shown in Figure 1, the domain surrounded by dotted line 2 is the associated domain of the node IEDB2, which consists of line L1, L2 and bus B2 with two boundary IEDs, IED1 and IED4. Similarly, associated domains of other nodes are domains surrounded by dotted lines 1, 3, 4, 5.
The positive sequence fault component differential current of the node IED associated domain is defined as the sum of phasors of all positive sequence fault current components measured at boundary line IEDs. For example, at the node IEDB2, the positive sequence fault component differential current 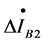 of the node associated domain is
of the node associated domain is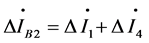 . Any fault occurs in the associated domain, the value of
. Any fault occurs in the associated domain, the value of 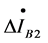 which is the total positive sequence fault current component will be very large and associated domain ② is the fault associated domain for the moment. When normal operation or external fault of the associated domain, the positive sequence fault component differential current
which is the total positive sequence fault current component will be very large and associated domain ② is the fault associated domain for the moment. When normal operation or external fault of the associated domain, the positive sequence fault component differential current 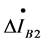 whose ideal value is zero is actually an unbalanced current with small value. Thus, when a short-circuit fault occurs at K1 point in the Figure 1, domains ①, ④ and ⑤ are non-fault domains, domains ② and ③ are fault domains and corresponding fault nodes are B2 and B3. Therefore, it can be assured that the fault domain is the overlapped part of two node IEDs associated domains (as the shaded part shown in Figure 1), that is the line L2.
whose ideal value is zero is actually an unbalanced current with small value. Thus, when a short-circuit fault occurs at K1 point in the Figure 1, domains ①, ④ and ⑤ are non-fault domains, domains ② and ③ are fault domains and corresponding fault nodes are B2 and B3. Therefore, it can be assured that the fault domain is the overlapped part of two node IEDs associated domains (as the shaded part shown in Figure 1), that is the line L2.
When a fault occurs at bus B3 in the Figure 1, for domain ① we have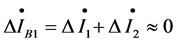 , for domain ② we have
, for domain ② we have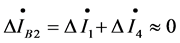 , for domain ③ we have
, for domain ③ we have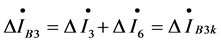 , for domain ④ we have
, for domain ④ we have
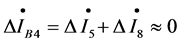 , for domain ⑤ we have
, for domain ⑤ we have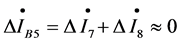 . It can be
. It can be
![]()
Figure 1. IED associated domain analysis.
assured that the domain ③ is the fault associated domain. Hence, when a single independent fault associated domain appears, the bus in the associated domain is thought to be failed.
Clustering status characteristic values selected in this paper are the RMS ![]() in the first cycle and the RMS
in the first cycle and the RMS ![]() in second cycle of the positive sequence fault component differential current at the node IED associated domain after the fault, that is, the status information vector for the i-th node IED is
in second cycle of the positive sequence fault component differential current at the node IED associated domain after the fault, that is, the status information vector for the i-th node IED is![]() . If there are n substations (n nodes) in power grid, the wide-area information matrix A
. If there are n substations (n nodes) in power grid, the wide-area information matrix A ![]() could be
could be
![]()
Row vectors of the matrix A correspond to node IED status information, that is clustering objects of K-means.
3.2. The Fault Domain Identification of Power Grid Based on K-Means
The wide-area information matrix A of power grid is the input of K-means clustering for the clustering analysis of the associated domain of each grid node. Still the circuit in Figure 1, for example, the wide-area information matrix A is
![]()
where, nodes corresponded to fault domains are IEDB2 and IEDB3, nodes corresponded to non-fault domains are IEDB1, IEDB4 and IEDB5. Characteristic information of associated node IEDs in fault domains are all the whole fault current at fault points in domains with similar vector information. And all characteristic information of associated node IEDs in non-fault domains are merely unbalanced currents with small values and their vector information are similar. But vectors information are different vigorously between node IEDs of fault domain s and non-fault domain. Based on a large number of simulations, wide-area information samples acquired by node IEDs are divided into two groups: the IED class of fault domain associated nodes and the IED class of non-fault domain associated nodes.
In a large multi-station power system, the principle of minimum fault area is satisfied, based on which, the cluster with the least node IED number in clustering results is chosen as the associated node IED class of fault domains in this paper. In the class, the overlapped domain of associated fault domains of each node IED is thought as the fault domain. If there is no overlapped domain, bus failure at associated node is thought to happen in corresponding fault domain. The process of the fault identification based on K-means algorithm is shown in Figure 2.
4. Example Analysis
As shown in Figure 3, simulations with the fault identification method based on K-means are carried on IEEE-3 machine 9-node system. Several typical fault situations are analyzed and tested on this paper.
![]()
Figure 2. Fault domain identification flow based on K-means.
According to the definition above, the positive sequence fault component differential current of the node IED associated domain is referred as the sum of current phasors measured by boundary line IEDs in the associated domain. Calculations of positive sequence fault component differential currents for node IED associated domains of the IEEE-3 machine 9-node system are as shown in Table 1.
After calculating all positive sequence fault component differential currents of the node IED associated domains, the RMS value ∆Ii1 in first circle and the RMS value ∆Ii2 in second circle of differential currents after fault are selected as wide-area information vector for the i-th node IEDBi. Hence, the node IED wide-area information matrix A ![]() of IEEE-3 machine 9-node system is represented as
of IEEE-3 machine 9-node system is represented as
![]()
4.1. A Fault Occurs at Line L9
Assume three-phase short circuit fault occurs at line L9, the wave of positive sequence fault component differential currents measured at part node IEDs is shown in Figure 4.
The RMS values ∆Ii1 in first circle and the RMS values ∆Ii2 in second circle of positive sequence fault component differential currents in the associated domain of each node IED are as shown in Table 2.
Therefore, the wide-area information matrix A ![]() of the IEEE-3 machine 9-node system is represented as
of the IEEE-3 machine 9-node system is represented as
![]()
Table 1. Calculations of positive sequence fault component differential currents.
![]()
Table 2. The RMS values of positive sequence fault component differential currents at each node IED.
![]() (a)
(a)![]() (b)
(b)
Figure 4. The wave of positive sequence fault component differential currents at some node IEDs. (a) The wave of positive sequence fault component differential currents at node IEDB1. (b) The wave of positive sequence fault component differential currents at node IEDB4.
![]()
Row vectors of the matrix are objects analyzed according to K-means clustering algorithm. The dimension of sample characteristic values is m =2, the number of data samples is n = 9, and the initial cluster number is h = 2. Select randomly the 1-th and 6-th rows as initial clustering centers, the class centroid coordinate matrix C of two classes is
![]()
The distance sum vector in classes is SUMD = [0.00039 0.0008]
The distance matrix D of each data to their class center is
![]()
The outline of K-means clustering is as shown in Figure 5.
Clustering results are as shown in Table 3.
![]()
Figure 5. The outline of K-means clustering.
![]()
Table 3. K-means classification for L9 fault.
According clustering results, the wide-area information of 9 node IEDs are divided into two classes, in which the one with least nodes are identified as the node IED class of fault associated domains according to the algorithm proposed. As in Table 3, class 1 is the node IED class of fault associated domains. The overlapped domain of node IEDs associated domains is where faults occur. If there is no overlapped domain, a bus fault occurs in the domain. In the class 1, the associated domains of IED7 and IED4 are overlapped at line L9, then line L9 is the domain where the fault happens.
4.2. A Fault Occurs at Bus B2
Assume AC two-phase to ground fault occurs at bus B2, the node IED wide-area information matrix A ![]() obtained accordingly is
obtained accordingly is
![]()
Clustering results are as shown in Table 4. The class 1 with least associated IED number is the node class of the fault associated domain with only one node IED, that is one independent fault associated domain. According to the algorithm, no overlapped area exists, the fault occurs at the bus in the fault associated domain, that is at bus B2.
4.3. Clustering Analysis under Other Fault Conditions
To test accuracy of the identification algorithm based on K-means, clustering analysis are carried on when faults occur under other fault conditions, results seen in Table 5. Experiments shown that the algorithm proposed in this paper can identify fault domains when power grid operates under different modes and with different topology structures.
![]()
Table 4. K-means classification for bus B2 fault.
![]()
Table 5. Simulation analysis of the fault domain identification based on K-means for different faults.
5. Conclusions
A new method for fault domain identification based on wide-area positive sequence fault component differential currents and K-means algorithm is proposed in this paper. Wide-area information of node IEDs are clustered by K-means according to the fault domain minimum principle to assure the class with least node IEDs to be the associated node class of fault associated domains. The fault identification can be realized by finding the overlapped area of fault associated domains of those node IEDs.
Simulation results show that fault domains can be identified correctly when the operational mode of power grid changes, such as one line or one source is not in operation. Fault domain identification based on wide-area status information and the intelligent algorithm are discussed in this paper, which provides a new way to diagnose faults in grid.
Acknowledgements
The research work was financially supported by the artificial intelligence key laboratory of Sichuan province ( 2014RYY05,2015RYY01).