ELMAN Neural Network with Modified Grey Wolf Optimizer for Enhanced Wind Speed Forecasting ()
Received 28 April 2016; accepted 15 May 2016; published 16 August 2016

1. Introduction
In recent year, wind energy is derived much more attention because of its special features such as inexhaustible, pollution free, free of availability, and renewable. Corresponding to the irregular and uncertain characteristics of wind speed, wind speed forecasting play a major role in wind farm and power system planning, scheduling, controlling and integration operation. Hence, the many researcher’s emphasis their research on the accurate wind speed forecasting in the literature: “Rough set theory and principal component analysis techniques incorporated ELMAN neural network based short-term wind speed forecasting performed by Yin, et al. [1] ”. “Olaofe [2] presented Layered recurrent neural network (LRNN) forecasting model in order to forecast 5 day wind speed and wind power”. “Hybrid wind speed forecasting approach combining empirical mode decomposition and ELMAN neural network is suggested by Wang, et al. [3] ”. “Corne, et al. [4] carried out work on Evolved neural network based short- term wind speed forecasting”. “Cao, et al. [5] Analyzed wind speed forecasting by means of the ARIMA and recurrent neural network based forecasting model; result proves superiority of the recurrent neural network than that of ARIMA”. “Junfang Li, et al. [6] performed one step ahead prediction of wind speed using ELMAN neural network”. “Madhiarasan and Deepa [7] performed different time scale forecasting of wind speed using six ANN (artificial neural network) and performance analyzed with Coimbatore region three wind farm data sets”. “Madhiarasan and Deepa [8] presented wind speed prediction for different time scale horizon using Ensemble neural network”.
An Artificial neural network is an information processing structure designed by means interlinked elementary processing devices (neurons). Feed-forward neural network and feedback neural network are the general types of artificial neural network. The feedback neural network has a profound effect on the modeling nonlinear dynamic phenomena performance and its learning capacity. Determination of hidden layer units in artificial neural network is a crucial and challenging task, over fitting and under fitting problems is caused due to random choice of hidden layer units. Therefore, previous work in determining the hidden layer neuron units: “Arai [9] found the hidden units by means of TPHM”. “Jin-Yan Li, et al. [10] Searched optimal hidden units with the help of estimation theory”. “Proper hidden units for three and four layered feed-forward neural networks are defined by Tamura and Tateishi [11] ”. “Kanellopoulas and Wilkinson [12] stated required amount hidden units”. “Osamu Fujita [13] determined feed forward neural network sufficient hidden units”. “Three layer binary neural network need hidden units are found based on set covering algorithm (SCA) by Zhaozhi Zhang, et al. [14] ”. “Jinchuan Ke and Xinzhe Liu [15] pointed out neural network proper hidden units for stock price prediction”. “Shuxiang Xu and Ling Chen [16] described feed-forward neural network optimal hidden units”. “Multilayer perceptron network sufficient hidden units are defined by Stephen Trenn [17] ”. “Katsunari Shibata and Yusuke Ikeda [18] stated large scale layered neural network sufficient hidden units and learning rate”. “David Hunter, et al. [19] Suggested the hidden units for multilayer perceptron, bridged multilayer perceptron and fully connected cascade”. “Gnana Sheela and Deepa [20] pointed out ELMAN neural network hidden units based on three input neurons”. “Guo Qian and Hao Yong [21] determined back propagation neural network hidden units”. “Madhiarasan and Deepa [22] Estimated improved back propagation network hidden units by means of novel criterion”. “Madhiarasan and Deepa [23] pointed out, recursive radial basis function network proper hidden layer neurons estimation based on new criteria”.
Optimizers have ability to give solution for a complex optimization problem and used to approximate the global optimum in order to improve the performance. Many researchers introduced new heuristic algorithms, some of the most familiar algorithms in the literature are: “Genetic Algorithm (GA) proposed by Holland [24] ”, “Evolution Strategy (ES) pointed out by Ingo Rechenberg [25] ”, “Particle Swarm Optimization (PSO) developed by Kennedy and Eberhart [26] ”, “Socha, K. and Blum [27] presented feed-forward neural network training by mean of the Ant Colony Optimization (ACO)”, “Karaboga and Basturk [28] carried out work on the Artificial Bee Colony (ABC) for numerical function optimization”, “Yang and Deb [29] suggested Cuckoo search (CS) algorithm”, “Adaptive Gbest-guided Gravitational Search Algorithm (GGSA) proposed by Mirjalili and Lewis [30] ”, “Mirjalili, et al. [31] developed Grey Wolf Optimizer (GWO)”.
This paper attempts to analyze the performance of ELMAN neural network based on the proposed 131 various criteria for proper hidden layer neurons units’ determination, Proposed new criteria estimate proper hidden neuron units in ELMAN neural network aid good forecasting result compared to other existing criteria and also proposed novel modified grey wolf optimizer (MGWO) to optimize the ELMAN neural network in order to improve the wind speed forecasting accuracy than earlier methods.
2. ELMAN Neural Network
“ELMAN neural network (ENN) is a partial recurrent network model first pointed out by ELMAN in 1990 [32] ”. ELMAN neural network comprises an input layer, hidden layer, recurrent link (feedback) layer and output layer. Recurrent layer placed in a network with one step delay of the hidden layer. ELMAN neural network is a recurrent network; recurrent links are added into the hidden layer as a feedback connection. “The ELMAN neural network dynamic characteristics are provided by internal connection; ELMAN neural network is superior to static feed- forward neural network because it does not require utilizing the states as training (or) input signal stated by Lin and Hung., Liu Hongmei, et al., Xiang Li, et al. [33] - [35] ”. ELMAN neural network widely used for different application such as time series prediction, modeling, control and speech recognition. Output is made from the hidden layer. The recurrent link layer stores the feedback and retains the memory. Hyperbolic tangent sigmoid activation function is adopted for hidden layer and the purelin activation function is used for the output layer.
Proposed ELMAN neural network based wind speed forecasting model input layer is developed by means of the six input neurons, such as Temperature (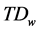 ), Wind Direction (
), Wind Direction (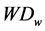 ), Relative Humidity (
), Relative Humidity (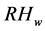 ), Precipitation of Water content (
), Precipitation of Water content (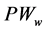 ), Air Pressure (
), Air Pressure (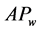 ) and Wind speed (
) and Wind speed (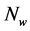 ). Higher computational complexity and computation time are caused due to neural network with many hidden layers. Hence, the single hidden layer is used for neural network design. The output layer has a single output neuron (i.e.) forecast wind speed. The goal of the proposed new criteria is to choose exact hidden layer units to get the quick convergence and the best efficacy with the lowest mean square error. The architecture of the proposed ELMAN neural network based wind speed forecasting model is presented in Figure 1.
). Higher computational complexity and computation time are caused due to neural network with many hidden layers. Hence, the single hidden layer is used for neural network design. The output layer has a single output neuron (i.e.) forecast wind speed. The goal of the proposed new criteria is to choose exact hidden layer units to get the quick convergence and the best efficacy with the lowest mean square error. The architecture of the proposed ELMAN neural network based wind speed forecasting model is presented in Figure 1.
Figure 1 represented input and output target vector pairs are defined as follows.
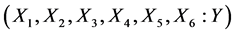 = (Temperature, Wind Direction, Relative Humidity, Precipitation of Water content, Air Pressure and Wind speed: Forecast Wind speed).
= (Temperature, Wind Direction, Relative Humidity, Precipitation of Water content, Air Pressure and Wind speed: Forecast Wind speed).
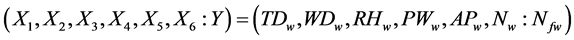 (1)
(1)
Input vector,
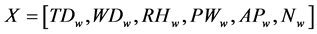 (2)
(2)
![]()
Figure 1. Architecture of the suggested wind speeds forecasting model based on ELMAN neural network.
Output vector,
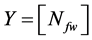 (3)
(3)
Weight vectors of input to the hidden vector,
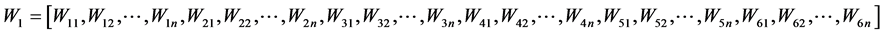 (4)
(4)
Weight vectors of recurrent link layer vector,
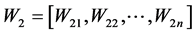 (5)
(5)
Weight vectors between context layer and input vector,
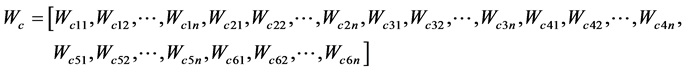 (6)
(6)
ELMAN network inputs,
 (7)
(7)
ELMAN network output,
![]() (8)
(8)
Input of recurrent link layer,
![]() (9)
(9)
Let, ![]() is the forecast wind speed,
is the forecast wind speed, ![]() is connection weights between context layer and input layer,
is connection weights between context layer and input layer, ![]() is connection weights between input layer and hidden layer,
is connection weights between input layer and hidden layer, ![]() is connection weights between hidden layer and recurrent link layer,
is connection weights between hidden layer and recurrent link layer, ![]() is the hyperbolic tangent sigmoid activation function,
is the hyperbolic tangent sigmoid activation function, ![]() is purelin activation function.
is purelin activation function.
For suggested ELMAN neural network each and every layer performs the individualistic calculations on receiving information and the calculated results are passed to the succeeding layer and to end determines the network output this fact is observed from the Figure 1. Response to the current input depending on the previous inputs.
The neural network designing process plays a vital role in the network performance. A Proposed ELMAN network designed parameters include dimensions and epochs shown in Table 1. The input ![]() is passed through the hidden layer that multiplies weights (
is passed through the hidden layer that multiplies weights (![]() ) using hyperbolic tangent sigmoid activation function. Current input
) using hyperbolic tangent sigmoid activation function. Current input ![]() plus previous state output
plus previous state output ![]() is helps the network to learn the function. The value of
is helps the network to learn the function. The value of ![]() is passed through an output layer that multiplied with weights
is passed through an output layer that multiplied with weights ![]() by means of the purelin activation function. For ELMAN neural network training process, the predecessor state information, gives back to the network. Training learned from the normalized data. Test for the stopping condition, the error coming to a very negligible value. Considered 131 various criteria are applied to ELMAN neural network one by one and verify the performance is accepted (or) not. The novel criteria are utilized to decide the proper hidden layer neuron units in ELMAN network construction and the presented approach is applied to forecast the wind speed.
by means of the purelin activation function. For ELMAN neural network training process, the predecessor state information, gives back to the network. Training learned from the normalized data. Test for the stopping condition, the error coming to a very negligible value. Considered 131 various criteria are applied to ELMAN neural network one by one and verify the performance is accepted (or) not. The novel criteria are utilized to decide the proper hidden layer neuron units in ELMAN network construction and the presented approach is applied to forecast the wind speed.
3. Hidden Layer Neuron Units Estimation
The determination of hidden layer neuron units in a neural network frame is a tough task, odd choice of hidden
![]()
Table 1. Proposed ELMAN neural network designed parameters.
layer neuron units cause either under fitting or over fitting issue. Several researchers have suggested lots of approaches to select the hidden layer neuron units in neural networks. The approaches can be categories into pruning and constructive approaches. “For pruning approach the neural network starts with bigger than the usual size and then removing superfluous neurons and weights, finally found the minimum neurons and weights, whereas on the constructive approach neural network begins with less than the usual size network and then additional hidden units are added to the neural network specified by Jin-Yan Li, et al., Mao and Guang-Bin Huang [10] [36] ”. The artificial neural network with a small number of hidden neuron units may not have the enough ability to succeed the essentials namely error precision, network capacity and accuracy. The issue related to over fitting data is occurring due to over training process in the neural network design. Hence, determination of proper hidden layer neuron units in artificial neural network construction is one of the great significance issue. Several researchers attempt to make the good network framework by tackling this problem. While on neural network modeling stage there is no other way to select the hidden layer neuron units without striving and verifying during the training stage and calculating the generalization error. If the hidden layer neuron units are large then hidden output connection weights become so small, learns easily and output neurons become unstable. If the hidden layer neuron units are small it may stuck in the local mini ma because the neural network learns very slowly so hidden units tends to unstable. Hence, determination of exact hidden layer neuron units is a significant censorious issue for neural network modeling. This article examines the appropriate determination of hidden layer neuron units for ELMAN neural network by means of the proposed new criteria. Features of the proposed criteria are as follows:
1) The proposed 131 various criteria are function of input neurons and noted to be justified based on convergence theorem.
2) Both either over fitting or under fitting problems are avoided.
3) To estimate exact hidden layer neuron units with minimal computational complexity.
All considered criteria were tested on ELMAN neural network to determine the neural network training and testing stage performance by statistical error. The implementation of the pointed out approach begins by adopting the proposed criteria to ELMAN neural network. Following implementation stage train ELMAN neural network and calculate the mean square error (MSE). The network performance is calculated based on the mean square error; Equation (10) represents the mean square error formula. Criteria with the lowest minimal MSE (mean square error) are the best criteria for determination of hidden layer neuron units in ELMAN neural network.
Error Evaluation Measure is defined as follows:
![]() (10)
(10)
where, ![]() is forecast output,
is forecast output, ![]() is actual output,
is actual output, ![]() is average actual output, N is the number of data samples.
is average actual output, N is the number of data samples.
4. Modified Grey Wolf Optimizer (MGWO)
“GWO is recently employed by Mirjalili, et al. [31] in order to achieve improved performance by mean of search the global optimum”. In this paper modified grey wolf optimizer is proposing in ELMAN neural networks for wind speed forecasting. Modified grey wolf optimizer proves with improved exploration and exploitation than that of GWO and other evolutionary strategies. Modified grey wolf optimizer replicates the social leadership and prey hunting behavior of grey wolves. The population is split into four groups alpha (![]() ), beta (
), beta (![]() ), gamma (
), gamma (![]() ) and lambda (
) and lambda (![]() ) for the proposed MGWO.
) for the proposed MGWO.
The favorable area of the search space attains by the wolves ![]() based on the direction of the first three fittest wolves such as alpha (
based on the direction of the first three fittest wolves such as alpha (![]() ), beta (
), beta (![]() ) and gamma (
) and gamma (![]() ). The wolves revise their position around
). The wolves revise their position around![]() ,
, ![]() and
and ![]() during a course of optimization stage are given as below:
during a course of optimization stage are given as below:
![]() (11)
(11)
![]() (12)
(12)
where, i―Current Epoch,![]() ―Position vector of the grey wolf,
―Position vector of the grey wolf,![]() ―Position vector of the worst grey wolf,
―Position vector of the worst grey wolf,![]() ―Position vector of the prey,
―Position vector of the prey, ![]() &
&![]() ―Coefficient vectors.
―Coefficient vectors.
Coefficient vectors are enumerated as follows:
![]() ,
, ![]() where,
where,![]() ―Set to linearly decreased from 2 to 0 during the course of epochs,
―Set to linearly decreased from 2 to 0 during the course of epochs, ![]() &
&![]() ―Random vector between 0 & 1.
―Random vector between 0 & 1.
The rest of the candidates (![]() wolves) revise their position based on the first three fitness solution such as
wolves) revise their position based on the first three fitness solution such as![]() ,
, ![]() and
and ![]() are described as follows:
are described as follows:
![]() (13)
(13)
![]() (14)
(14)
![]() (15)
(15)
![]() (16)
(16)
![]() (17)
(17)
![]() (18)
(18)
![]() (19)
(19)
where,![]() ―Position of the first best solution (
―Position of the first best solution (![]() ),
),![]() ―Position of the second best solution (
―Position of the second best solution (![]() ),
),![]() ―Posi- tion of the third best solution (
―Posi- tion of the third best solution (![]() ),
),![]() ―Current position, i―Number of epochs,
―Current position, i―Number of epochs,![]() ―Random vectors.
―Random vectors.
The relative distance between the present solution and![]() ,
, ![]() ,
, ![]() respectively, are estimated by means of the Equations (13)-(15). The eventual position of the present solution is estimated after the distance computations are expressed in Equations (16)-(19). The coefficient vectors are playing a key role for better exploration and exploitation; if
respectively, are estimated by means of the Equations (13)-(15). The eventual position of the present solution is estimated after the distance computations are expressed in Equations (16)-(19). The coefficient vectors are playing a key role for better exploration and exploitation; if ![]() it promoted exploration meanwhile
it promoted exploration meanwhile ![]() exploitation is emphases. Modified Grey Wolf Optimization (MGWO) achieves better convergence than that of GWO by means of the inclusion of the worst position.
exploitation is emphases. Modified Grey Wolf Optimization (MGWO) achieves better convergence than that of GWO by means of the inclusion of the worst position.
Steps involved in MGWO Algorithm are as follows:
Step1: Based on the variables upper and lower bounds randomly initialize a population of wolves.
Step2: Compute each wolf corresponding fitness value.
Step3: Store the first three best wolves as![]() ,
, ![]() ,
, ![]() respectively.
respectively.
Step4: Update the rest of the search agents (![]() wolves) position by means of Equations (11)-(19).
wolves) position by means of Equations (11)-(19).
Step5: Update variables such as u, H and G.
Step6: If stopping criteria is not satisfied go to Step2.
Step7: Record ![]() position as the best global optimum.
position as the best global optimum.
Proposed novel Modified Grey Wolf Optimizer (MGWO) algorithm flow chart is shown in Figure 2.
5. ELMAN Neural Network with MGWO
The highest forecasting accuracy is provided by means of the optimization techniques. Therefore, novel modified grey wolf optimizer (MGWO) is attempting to optimize the ELMAN neural network for wind speed forecasting application. Figure 3 depicts the structure of the ELMAN neural network optimization by MGWO. Mean square error (MSE) is generally used performance measure for evaluation of forecasting accuracy. MSE computed based on the Equation (10), the lowest mean square error indicates the improved forecasting accuracy. Hence, the minimization of MSE is used as an objective function for the proposed MGWO algorithm. The weights of the ELMAN neural network are provided by means of the MGWO algorithm, MGWO perform the minimization MSE based on changing weights (i.e. weight optimization). Weights changing of wolves are highly influenced based on the ![]() wolf, the best weight are searched by means of the MGWO in order to improve the convergence, accuracy and minimizes ELMAN neural network error.
wolf, the best weight are searched by means of the MGWO in order to improve the convergence, accuracy and minimizes ELMAN neural network error.
6. Result Analysis and Discussion
6.1. Data Resources and Simulation Platform
Three real-time observations are used for this analysis. Data set1 is collected from the National Oceanic and
![]()
Figure 3. ELMAN neural network optimization by MGWO.
Atmospheric Administration, United States from January 1994 to December 2014. Data set 2 and Data set 3 are observed from Suzlon Energy Private Limited from January 2010 to December 2014 with different wind mill height. All data set contains 100,000 number of data samples. The neural network based wind speed forecasting approach involves the designing, training and testing stages. Exact modeling of neural network is difficult and a tough task. The gathered input attributes used for ELMAN neural network are real-time data therefore, scaling procedure is used up to avoid the training process issues such as massive esteemed input data incline to minimize the impact of little value input data. Therefore, the min-max scaling method is used to scale the variable range of real-time data within the range of 0 to 1; scaling is computed based on the Equation (20). The scaling process helps to improve the numerical computational accuracy, so ELMAN neural network model accuracy is also enhanced.
Scaled input,
![]() (20)
(20)
where, ![]() is actual input data,
is actual input data, ![]() is minimum of actual input data,
is minimum of actual input data, ![]() is maximum of actual input data,
is maximum of actual input data, ![]() is the minimum of the target,
is the minimum of the target, ![]() is the maximum of the target.
is the maximum of the target.
The proposed ELMAN neural network is established by three real-time data sets; each acquired real-time data sets consists up of 100,000 numbers of data samples. The collected 100,000 real-time data are classified as training and testing. The collected 70% of data (70,000) are utilized for neural network training phase and 30% of the gathered data (30,000) are utilized for the testing phase of the network. Proposed neural network design and all algorithms are tested in MATLAB and simulate on an Acer computer with Pentium (R) Dual Core processor running at 2.30 GHZ with 2 GB of RAM.
6.2. Proposed Criteria Based Estimation of Hidden Layer Neuron Units
The issues related to the proper determination of hidden layer neuron units for a specific problem are to be chosen. The existing strategies utilizes trial and error rule for deciding neural networks hidden layer neuron units. This begins the network with less than the usual size of hidden layer neuron units and additional hidden neurons are included in the![]() . Limitations are there are no assurance of deciding the hidden layer neuron units and it consumes much time. Therefore, propose the new 131 criteria as a function of input neurons to determine the hidden layer neuron units in neural networks. The appropriate hidden layer neuron units in hidden layer are determined based on the best the lowest minimal error. Three real-time data sets are used for performance analysis of considered 131 various criteria for determination of the hidden layer neuron units in ELMAN neural network based on the mean square error are established in Table 2. Results obtained with the three real-time data sets proved that the proposed criteria
. Limitations are there are no assurance of deciding the hidden layer neuron units and it consumes much time. Therefore, propose the new 131 criteria as a function of input neurons to determine the hidden layer neuron units in neural networks. The appropriate hidden layer neuron units in hidden layer are determined based on the best the lowest minimal error. Three real-time data sets are used for performance analysis of considered 131 various criteria for determination of the hidden layer neuron units in ELMAN neural network based on the mean square error are established in Table 2. Results obtained with the three real-time data sets proved that the proposed criteria ![]() based hidden layer neuron unit’s estimation in ELMAN neural network achieved minimal mean square error than other considered criteria. Therefore, the proposed criteria to improve the effectiveness and accuracy for wind speed forecasting.
based hidden layer neuron unit’s estimation in ELMAN neural network achieved minimal mean square error than other considered criteria. Therefore, the proposed criteria to improve the effectiveness and accuracy for wind speed forecasting.
Justification for the Chosen Criteria
Justification for determination of hidden layer neuron units is commenced by means of the convergence theorem discussion in the Appendix. Lemma 1 confirms the convergence of the chosen criteria.
Lemma 1:
The sequence ![]() is converging and
is converging and![]() .
.
The sequence tends to have a finite limit l, if there exists constant ![]() such that
such that![]() , then
, then![]() .
.
Proof:
Lemma 1 based proof defined as follows.
Regarding to convergence theorem, the selected value (or) sequence converges to a finite limit value.
![]() , (21)
, (21)
![]() , finite limit value. (22)
, finite limit value. (22)
![]()
![]()
![]()
Table 2. ELMAN neural network statistical analysis of various criteria for determination of hidden layer neuron units.
Here 5 is the limit value of the chosen sequence as![]() . Hence, the examine sequence tends to have a finite limit so it is convergent sequence; where n is the input neuron units.
. Hence, the examine sequence tends to have a finite limit so it is convergent sequence; where n is the input neuron units.
Experimental results confirm that the chosen criteria ![]() which possess 32 hidden layer neuron units in ELMAN neural network achieved the lowest mean square error (MSE) value 2.9538e−05, 3.6592e−05 and 4.2505e−05 for wind speed forecasting tested with three real-time data sets respectively. Hence, criteria
which possess 32 hidden layer neuron units in ELMAN neural network achieved the lowest mean square error (MSE) value 2.9538e−05, 3.6592e−05 and 4.2505e−05 for wind speed forecasting tested with three real-time data sets respectively. Hence, criteria ![]() determined as the best solution for determination of hidden layer neuron units in neural network model. The proposed ELMAN neural network based wind speed forecasting revealed that the forecast wind speed is in supreme compatibility with actual wind speed, it can be noticed from experimental results. Figures 4-6 show the comparison between actual wind speed and forecast wind speed obtained from the proposed new criteria based ELMAN neural network for the data sets1, data sets2 and data sets3, respectively. Wind speed forecasting on three real-time data sets using new criteria based ELMAN neural network make consistent results with precise match with actual wind speed; it is easy to notice from Figures 4-6. Figures 7-9 depict the mean square error vs. number of data samples obtained from the proposed new criteria based ELMAN neural network for the data sets1, data sets2 and data sets3, respectively. Based on the experiments on three real-time data sets, proposed criteria
determined as the best solution for determination of hidden layer neuron units in neural network model. The proposed ELMAN neural network based wind speed forecasting revealed that the forecast wind speed is in supreme compatibility with actual wind speed, it can be noticed from experimental results. Figures 4-6 show the comparison between actual wind speed and forecast wind speed obtained from the proposed new criteria based ELMAN neural network for the data sets1, data sets2 and data sets3, respectively. Wind speed forecasting on three real-time data sets using new criteria based ELMAN neural network make consistent results with precise match with actual wind speed; it is easy to notice from Figures 4-6. Figures 7-9 depict the mean square error vs. number of data samples obtained from the proposed new criteria based ELMAN neural network for the data sets1, data sets2 and data sets3, respectively. Based on the experiments on three real-time data sets, proposed criteria ![]() is consistent with the result of lower mean square error, it is inferred from Figures 7-9. For clarity of the graph only part of result with 3000 data samples is shown. The Merits of the presented method are very effective, minimal error and easy implementation for wind speed forecasting.
is consistent with the result of lower mean square error, it is inferred from Figures 7-9. For clarity of the graph only part of result with 3000 data samples is shown. The Merits of the presented method are very effective, minimal error and easy implementation for wind speed forecasting.
Comparison with Exiting Criteria
Analysis proposed criteria effectiveness compared with the result of other existing criteria based hidden layer neuron unit’s estimation in ELMAN neural network for wind speed forecasting is presented in Table 3. The Table 3 shows, the importances of the proposed criteria get the lower mean square error. Obviously, the proposed criteria ![]() aid better winds speed forecasting performance in terms of reduced errors. The comparison confirmed that the attempting new criteria have the lowest mean square error than other existing criteria.
aid better winds speed forecasting performance in terms of reduced errors. The comparison confirmed that the attempting new criteria have the lowest mean square error than other existing criteria.
![]()
Figure 4. Comparison between actual wind speed and forecast wind speed for data set1.
![]()
Figure 5. Comparison between actual wind speed and forecast wind speed for data set2.
![]()
Figure 6. Comparison between actual wind speed and forecast wind speed for data set3.
![]()
Figure 7. MSE vs. data samples for data set1.
![]()
Figure 8. MSE vs. data samples for data set2.
![]()
Figure 9. MSE vs. data samples for data set3.
![]()
Table 3. Comparative analysis of proposed method performance with earlier various methodologies.
6.3. Proposed Modified Grey Wolf Optimizer Based ELMAN Neural Network and Comparison with Existing Algorithms
Chosen new criteria based ELMAN neural network possesses 6 input neuron units, single hidden layer with 32 hidden layer neuron units and single output optimized by means of the proposed modified grey wolf optimizer.
For substantiation of the proposed algorithm, the results are compared with some of the existing Meta heuristic algorithms. A similar wind speed forecasting and objective function is used for ELMAN neural network with the Meta heuristic algorithm in Table 4. Due to the stochastic nature of Meta heuristic algorithm, the three
![]()
Table 4. Compared algorithms initial parameters.
different wind data sets are solved over 20 runs using each algorithm in order to generate the statistical results. Statistical results are depicted in Table 5 in the form of the average and standard deviation of the MSE, the lowest average and standard deviation of MSE indicate the superior performance, proposed hybrid method (ELMAN-MGWO) achieve average and standard deviation of the MSE for three real-time data sets are 4.1379e−11 ± 1.0567e−15, 6.3073e−11 ± 3.5708e−15 and 7.5840e−11 ± 1.1613e−14 respectively. From the Table 5, it can be noticed that the proposed modified grey wolf optimizer based ELMAN neural network obtain the minimal mean square error for three real-time wind data sets than those obtained with other existing algorithms. Therefore, the proposed modified grey wolf optimizer based ELMAN neural network not only produces improved forecasting accuracy with minimal mean square error, but also improves the convergence, stability and reduce the computation time.
7. Conclusion
In this paper, a novel hybrid method (ELMAN-MGWO) is proposed for wind speed forecasting. Firstly, proper hidden layer neuron unit is estimated based on the proposed new criteria and suggested criteria are validated based on the convergence theorem. Based on the least mean square error ![]() is identified as the best criteria. ELMAN neural network with the best criteria obtain MSE of 2.9538e−05, 3.6592e−05 and 4.2505e−05 experimentation on three real-time data sets respectively. Secondly, the modified grey wolf optimizer is adopted to optimize the ELMAN neural network. Thirdly, investigating the performance of the proposed hybrid method by means of the three real-time data sets and effectiveness is evaluated based on the performance metric and computed error. Hybrid method (ELMAN-MGWO) obtains mean square error average and standard deviation as 4.1379e−11 ± 1.0567e−15, 6.3073e−11 ± 3.5708e−15 and 7.5840e−11 ± 1.1613e−14 respectively for validation on three real-time data sets. Finally, comparative analysis is performed in order to demonstrate that the proposed new criteria based hybrid method make faster convergence, robust, accurate and effective for wind speed forecasting. Hence, the proposed method is useful for wind farm and power system operation and control.
is identified as the best criteria. ELMAN neural network with the best criteria obtain MSE of 2.9538e−05, 3.6592e−05 and 4.2505e−05 experimentation on three real-time data sets respectively. Secondly, the modified grey wolf optimizer is adopted to optimize the ELMAN neural network. Thirdly, investigating the performance of the proposed hybrid method by means of the three real-time data sets and effectiveness is evaluated based on the performance metric and computed error. Hybrid method (ELMAN-MGWO) obtains mean square error average and standard deviation as 4.1379e−11 ± 1.0567e−15, 6.3073e−11 ± 3.5708e−15 and 7.5840e−11 ± 1.1613e−14 respectively for validation on three real-time data sets. Finally, comparative analysis is performed in order to demonstrate that the proposed new criteria based hybrid method make faster convergence, robust, accurate and effective for wind speed forecasting. Hence, the proposed method is useful for wind farm and power system operation and control.
![]()
Table 5. Statistical results comparison.
Acknowledgements
The authors gratefully acknowledge National Oceanic and Atmospheric Administration, United States and Suzlon Energy Private Limited for the provision of data resources. Mr. M. Madhiarasan was supported by the Rajiv Gandhi National Fellowship (F1-17.1/2015-16/RGNF-2015-17-SC-TAM-682/(SA-III/Website)).
Appendix
Considers different criteria “n” as input parameter number. All considered criteria are satisfied based on the convergence theorem. Some explanations are given as below. “The sequence is called a convergent sequence, when the limit of a sequence is finite, while the sequence is called a divergent sequence when the limit of a sequence does not gravitate to a finite number, stated by Dass [37] ”.
The convergence theorem characteristics are given as follows:
1) Convergent sequence needed condition is that it has finite limit and is bounded.
2) An oscillatory sequence may not possess a distinctive limit.
Stable network is a network which posses no modification take place in the state of the network, irrespective of working. The neural network always converges to a stable state is the formidable network property. In real-time optimization problem the convergence plays a major role, the threat of fall in local mini ma issue on a neural network is overcome by means of convergence. Due to the discontinuities in the network model, the sequence of convergence has infinite. Convergence properties are used to model real-time neural optimization solvers.
Discuss the convergence of the considered sequence as follows.
Proceeds the considered sequence
![]() (A.1)
(A.1)
Pertain convergence theorem
![]() , it has a finite value. (A.2)
, it has a finite value. (A.2)
Consequently, the terms of a sequence have a finite limit value and bounded so examine sequence is convergent sequence.
Proceeds the considered sequence
![]() (A.3)
(A.3)
Pertain convergence theorem
![]() , it has a finite value. (A.4)
, it has a finite value. (A.4)
Consequently, the terms of a sequence have a finite limit value and bounded so examine sequence is convergent sequence.
Author Biographies
Mr. M. MADHIARASAN has completed his B.E (EEE) in the year 2010 from Jaya Engineering College, Thiruninravur, M.E. (Electrical Drives & Embedded Control) from Anna University, Regional Centre, Coimbatore, in the year 2013. He is currently doing Research (Ph.D) under Anna University, TamilNadu, India. His Research areas include Neural Networks, Modeling and simulation, Renewable Energy System and Soft Computing.
Dr. S. N. Deepa has completed her B.E (EEE) in the year 1999 from Government College of Technology, Coimbatore, M.E.(Control Systems) from PSG College of Technology in the year 2004 and Ph.D.(Electrical Engineering) in the year 2008 from PSG College of Technology under Anna University, TamilNadu, India. Her Research areas include Linear and Non-linear control system design and analysis, Modeling and simulation, Soft Computing and Adaptive Control Systems.
![]()
Submit or recommend next manuscript to SCIRP and we will provide best service for you:
Accepting pre-submission inquiries through Email, Facebook, LinkedIn, Twitter, etc.
A wide selection of journals (inclusive of 9 subjects, more than 200 journals)
Providing 24-hour high-quality service
User-friendly online submission system
Fair and swift peer-review system
Efficient typesetting and proofreading procedure
Display of the result of downloads and visits, as well as the number of cited articles
Maximum dissemination of your research work
Submit your manuscript at: http://papersubmission.scirp.org/
NOTES
![]()
*Research Scholar (Ph.D.).
#Associate Professor.