Received 14 June 2016; accepted 22 July 2016; published 25 July 2016

1. Introduction
Mixture regression is a special situation in regression problem. Rather than getting samples in one distribution, the data of mixture regression are from multiple distributions (the information of which distribution every observation from is unknown), which will make a bad effect in parameter estimation. The mixture regression problem can be described as follows [1] :
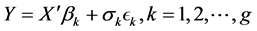 (1)
(1)
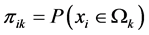 (2)
(2)
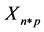 is independent observation matrix with n observations with p variables.
is independent observation matrix with n observations with p variables. 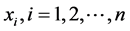 means ith observation vector from n observations. The length of
means ith observation vector from n observations. The length of 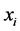 is p.
is p. 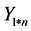 is response variable from observation data with the length of n.
is response variable from observation data with the length of n. 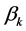 and
and 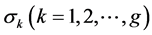 is the unknown parameters (weight) of the variable and scale parameter in different models.
is the unknown parameters (weight) of the variable and scale parameter in different models. 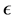 is a random error independent from
is a random error independent from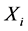 .
.  is the probability of ith observation is from the kth distribution
is the probability of ith observation is from the kth distribution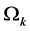 . (i.e.
. (i.e.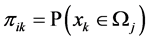 ). To solve the mixture regression problem, it need two parts. Firstly, confirming which model every sample is from is required. Secondly, parameters in each model should be estimated. That is the reason to call mixture regression model as model-based clustering [2] [3] .
). To solve the mixture regression problem, it need two parts. Firstly, confirming which model every sample is from is required. Secondly, parameters in each model should be estimated. That is the reason to call mixture regression model as model-based clustering [2] [3] .
For all the mixture regression problem, 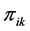 is unknown which has:
is unknown which has: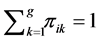 .
.
Furthermore, ![]() is defined as classification matrix of mixture regression. Every element of classification matrix is the estimator of
is defined as classification matrix of mixture regression. Every element of classification matrix is the estimator of![]() :
:![]() . And
. And ![]() shows the information of ith observation is from kth distribution or not (
shows the information of ith observation is from kth distribution or not (![]() means ith observation is from kth distribution). Classification matrix is one of the most important results in mixture regression problem. If we know the true Z, we can simply split the data into different linear regression and get the parameter estimation.
means ith observation is from kth distribution). Classification matrix is one of the most important results in mixture regression problem. If we know the true Z, we can simply split the data into different linear regression and get the parameter estimation.
Parameter estimation can be obtained by EM algorithm. Fraley et al., [4] [5] state the EM algorithm in ordinary mixture regression model which means every model in it is an ordinary linear regression. EM algorithm of ordinary mixture regression is as follows:
Column vector ![]() in classification matrix Z can be considered as a multinomial distribution. The probability of this multinomial distribution is
in classification matrix Z can be considered as a multinomial distribution. The probability of this multinomial distribution is![]() . When
. When ![]() is fixed, probability distribution function(PDF) of
is fixed, probability distribution function(PDF) of
![]() is
is![]() . And complete-data likelihood is:
. And complete-data likelihood is:
![]() (3)
(3)
E-step in mixture regression model can be obtained by:
![]() (4)
(4)
When ![]() is fixed, M-step is finished by maximizing
is fixed, M-step is finished by maximizing ![]() and
and ![]() by Formula (3). For a normal mixture regression problem,
by Formula (3). For a normal mixture regression problem, ![]() of E-step can be replaced by PDF of normal distribution function
of E-step can be replaced by PDF of normal distribution function![]() :
:
![]() (5)
(5)
As every observation is independent, covariance matrix can be defined as![]() , parameter of E-step can be calculated quickly in M-step by:
, parameter of E-step can be calculated quickly in M-step by:
![]() (6)
(6)
Song et al., [6] has finished EM algorithm with robust mixture regression. Q Wu et al., [7] proposed EM algorithm in quantile regression. Furthermore D. Lang et al., [8] explained a fast iteration method for mixture regression problem which can solve mixture regression when random error in different distributions.
Moreover, all the algorithms mentioned below is considering the quantity of models g is known. However this will not happened in every condition. The number of models g need to be chosen before the algorithm. When X is a low dimension matrix, a scatter plot can be drawn for choosing g. To get the true quantity of models, watching scatter plot and giving a conclusion is not suitable for a high-dimension situation. It was meaningful to discussing how to create a proper method choosing the right quantity of models in a mixture regression problem.
The rest of the paper is organized as follows. Section 2 will discuss the equivalence between mixture regre- ssion and ordinary regression when classification matrix is fixed. We extend a method based on information criterion in Section 3. Section 4 is the data simulation of different information criterions. Proof of theorem is in the Appendix section.
2. Equivalence of Linear Regression
Unsupervised learning has its method to choose the quantity of clusters, like GAP statics in K-means [9] . Mixture regression can be regards as a model based clusting including judging which cluster every observation should be grouped as well as the parameter estimation.
To find a proper method for choosing the quantity of models, we need to find the relationships between mixture regression and other algorithms. In some conditions, such as classification matrix Z is fixed and random error has the same variance, mixture regression can be written as a linear regression.
Theorem 1 (Equivalence between Mixture Regression and Linear Regression) If the estimater of![]() , classification
, classification ![]() is fixed, mixture regression can be written as
is fixed, mixture regression can be written as
![]() (7)
(7)
When random error in every model is independent and identically distributed from a normal distribution (![]() ). Random error in mixture regression is from a normal distribution, either.
). Random error in mixture regression is from a normal distribution, either.
![]()
The proof can be found in the Appendix.
After proofing this theorem, we can use the evaluation methodology from regression to solve the quantity choosing in mixture regression.
3. Information Criterion for Quantity of Clusters Choosing
3.1. Information Criterion
For a regression problem, Akaike information criterion (AIC) or Bayesian information criterion (BIC) [10] is always used for evaluating a regression model [11] . Information criterion is based on information theory, it shows the information lost in a specify model. A trade-off between goodness of fitting and the complexity of the model is considered in information criterion:
![]() (8)
(8)
![]() (9)
(9)
The best model is the one with the minimum AIC (BIC). L is the likelihood function which states the goodness of fitting (expression (3)). k is the penalty of the information criterion standing for the number of unknown parameters in the model. In linear regression, k means the number of dependent variables. As for BIC, the penalty is larger, weight of penalty comes to ![]() from 2.
from 2.
3.2. Information Criterion in Mixture Regression
In mixture regression, parameters in classification matrix should be considered as part of the estimator variables. Despite these variables, the model will tend to choosing a larger quantity of models which is also an overfitting problem.
For every observation, ![]() variable with the number of
variable with the number of ![]() can ensure classification among g models. For example, if
can ensure classification among g models. For example, if![]() , for the ith observation,
, for the ith observation, ![]() can complete determinate ith observation is from which cluster(model). As for the situation of
can complete determinate ith observation is from which cluster(model). As for the situation of![]() ,
, ![]() are requested to determinate the ith observation. k value (number of unknown parameters in the model) in information criterion of mixture regression should be:
are requested to determinate the ith observation. k value (number of unknown parameters in the model) in information criterion of mixture regression should be:
![]() (10)
(10)
Akaike information criterion for Mixture regression(AICM) and Bayesian information criterion for mixture (BICM) regression is:
![]() (11)
(11)
![]() (12)
(12)
AICM and BIC can be used for the quantity selecting in mixture regression problem. However, penalty weight for g in BICM is![]() , rather than 2n in AICM which will lead to an underfitting result when g is larger. We will see the details of this point in next section.
, rather than 2n in AICM which will lead to an underfitting result when g is larger. We will see the details of this point in next section.
4. Data Simulation
In order to validating the rationality of the model, we designed numeric simulations and generated sample data![]() :
:
• Simulation I: 100 samples from 2 distributions. (![]() ).
).
• Simulation II:200 samples from 2 distributions. (![]() ).
).
• Simulation III:150 samples from 3 distributions. (![]() ).
).
4.1. Simulation I
Models from simulation I is:
![]() (13)
(13)
where ![]() and
and![]() . Every distribution has 50 observations. See Figure 1 to see the results when
. Every distribution has 50 observations. See Figure 1 to see the results when![]() . We repeated the simulation for 100 times, use Mixreg package in R [12] to got the answer in Table 1.
. We repeated the simulation for 100 times, use Mixreg package in R [12] to got the answer in Table 1.
![]()
Table 1. Simulation I of selecting quantity of models.
4.2. Simulation II
The models in simulation II is same as simulation I. While, the samples in simulation II is 100 for each distribution.
![]() (14)
(14)
Figure 2 can be found in Appendix for simulation 2. Table 2 below is results for repeating 100 simulation.
4.3. Simulation III
Simulation III has three distributions with 50 samples in each distribution.
![]() (15)
(15)
See Figure 3 for simulation III in Appendix, and result is shown in Table 3.
![]()
Table 2. Simulation II of selecting quantity of models.
![]()
Table 3. Simulation III of selecting quantity of models.
5. Conclusion
According to the results in three simulations, we can see AICM and BICM show a good result in small g (![]() ) which choose the true quantity of models at a rate over 98%. While, ordinary AIC and BIC cannot point out the right quantity even once. In large samples, AICM and BICM perform well in simulation II. In small samples, simulation I, AICM tends to overfit the quantity and BICM tend to underfit the quantity in low probability of 2%. Simulation III shows an interesting results when
) which choose the true quantity of models at a rate over 98%. While, ordinary AIC and BIC cannot point out the right quantity even once. In large samples, AICM and BICM perform well in simulation II. In small samples, simulation I, AICM tends to overfit the quantity and BICM tend to underfit the quantity in low probability of 2%. Simulation III shows an interesting results when![]() ; BICM is too underfitting, which means the weight of penalty is too large for selecting the quantity. AICM choose correctly for 97 times among 100 times. That validates the information we gave in Section 3.
; BICM is too underfitting, which means the weight of penalty is too large for selecting the quantity. AICM choose correctly for 97 times among 100 times. That validates the information we gave in Section 3.
Appendix
Proof of theorem 1
Proof. Linear regression has the form of:
![]()
To proof this theorem, mixture regression need to be written as the form above. And when every random error has the same variance, random error in mixture regression is also a normal distribution.
![]()
In mixture regression problem, ith observation ![]() can be written as:
can be written as:
![]()
We have:
![]()
Because ith observation can be written as a product of vectors, population of observation can be written as![]() . Where
. Where ![]() has:
has:
![]()
![]()
For the observation ![]() is samed as ith single observation above. In this way, a mixture regression can be written as
is samed as ith single observation above. In this way, a mixture regression can be written as![]() . As for the distribution of random error
. As for the distribution of random error ![]() has:
has:
![]() (16)
(16)
![]() is from a multivariate distribution, probablity of
is from a multivariate distribution, probablity of ![]() is
is![]() :
:
![]() (17)
(17)
In the distribution of variable![]() , for any k has:
, for any k has:
![]()
so ![]()
![]()
Submit your manuscript at: http://papersubmission.scirp.org/