Assessments of Some Simultaneous Equation Estimation Techniques with Normally and Uniformly Distributed Exogenous Variables ()
1. Introduction
A simultaneous equation system is a regression equation system where two types of variables (the endogenous, the predetermined or exogenous variable) appear with disturbance terms. [1] defined simultaneous equation as the process of modeling more than one equation at a time; a multi-equation modeling. It is proposed to solve the problem of correlation.
In a multi-equation model, the dependent variable Y appears as endogenous variable in one equation and as explanatory variable in another equation of the model. The X variable appears as the explanatory variable in the equations. This creates problems of equation identification, multicollinearity and choice of estimation techniques among others.
Identification problem which creates estimation problems has the same features with multicollinearity [2] . Correlation between the pairs of exogenous or independent variables is an important problem in econometrics especially in single equation estimation. The impact of multicollinearity is less serious when attention is focused on predicting or forecasting values of the endogenous variables than when the analyst is interested in estimating the parameters [3] .
Econometric variables are often non-negative and can exhibit violation against the normality assumption of classical models which inevitably influences the performances of the estimation techniques. This study therefore examines the performances of four (4) common estimation techniques namely; Ordinary Least squares (OLS), Two-stage Least squares (2SLS), Three-stage Least squares (3SLS) and Full Information Maximum Likelihood Estimators under both normally and uniformly distributed exogenous variables for different equation identification status. Here it is assumed that there is no form of correlation in the simultaneous equation model.
Most economic data are often positive [4] and correlated [5] . However, various works done in the recent time especially on correlation studies on simultaneous equation model have being with normally distributed exogenous variables, exhibiting both positive and negative values [6] [7] .
2. Methodology
The methodology followed in this research work is as follows:
The Model and Its Description
Consider the simultaneous Equation model of the for
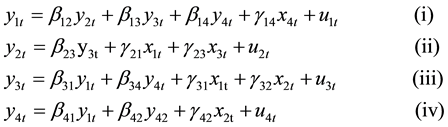 (1)
(1)
where 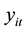 is an endogenous variable,
is an endogenous variable,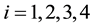 ;
;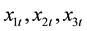 and
and 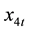 are the exogenous variables
are the exogenous variables
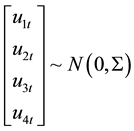
where 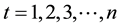 and
and 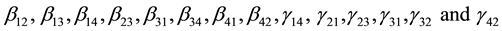 are the structural parameters of the model. Equations (i) and (iii) are exactly identified while Equations (ii) and (iv) were over identified by both order and rank condition.
are the structural parameters of the model. Equations (i) and (iii) are exactly identified while Equations (ii) and (iv) were over identified by both order and rank condition.
For the simulation study, Equation (1) was expressed as follows:
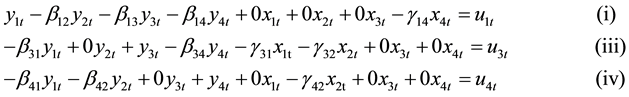 (4)
(4)
This can be written in matrix form as:
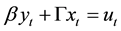 (5)
(5)
where
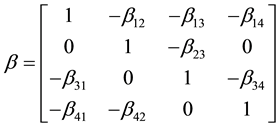 ,
,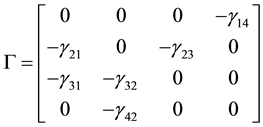 ,
,
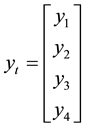 ,
,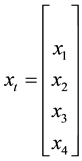 and
and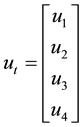
Now, from (5),
![]()
![]() (6)
(6)
Equation (6) was used to generate the endogenous variables by taking the true value of the parameters as:
![]()
![]()
Monte Carlo experiments were performed 5000 times for seven sample sizes (n = 10, 20, 30, 50, 100, 250 and 500) when there is no correlation of any form among exogenous variables and the error terms. The two forms of exogenous variables are generated to follow normal and uniform distribution.
3. Data Generation of Exogenous Variables
The generation was done as follows:
1) Normally Distributed Exogenous Variables
The exogenous were generated to be normal with mean zero and variance unity i.e. ![]() and
and ![]() is the value of correlation between the two variables i and j, [8] . In this study,
is the value of correlation between the two variables i and j, [8] . In this study, ![]() , was adopted as a situation with no forms of any correlation between the exogenous variables.
, was adopted as a situation with no forms of any correlation between the exogenous variables.
2) Correlated Uniformly Distributed Variables
Using the generated normally distributed exogenous variables above, ![]() , I = 1, 2, 3, 4; we further utilize the properties of random variables that cumulative distribution function of normal distribution produces U(0, 1) without affecting the correlation among the variables to generate correlated uniformly distributed exogenous variables,
, I = 1, 2, 3, 4; we further utilize the properties of random variables that cumulative distribution function of normal distribution produces U(0, 1) without affecting the correlation among the variables to generate correlated uniformly distributed exogenous variables, ![]() , I = 1, 2, 3, 4; [9] .
, I = 1, 2, 3, 4; [9] .
3) Generation of Correlated Error Terms
Equation provided by [8] was modified when the mean of the error terms are zero and variance is unit (1). Also, ![]() is the value of correlation between the two error terms i and j. In this study,
is the value of correlation between the two error terms i and j. In this study, ![]() , was adopted as no form of correlation between the error terms.
, was adopted as no form of correlation between the error terms.
4) Method of Generating the Data of Endogenous Variables
Equation (6) was used to generate the endogenous variables by taking the true value of the parameters as:
![]()
5) Criteria Used for Assessment of the Estimators
To assess the performance of the estimators, the finite properties were used (Bias, Absolute bias, Variance and Mean Square Error):
Mathematically, MSE is the addition of the Bias squared to the variance. For any estimator ![]() of
of ![]() in model (1),
in model (1),
![]() ,
,![]()
![]()
where R = 5000
![]()
as a measure of dispersion.
![]()
![]()
In this paper, ![]() is used to represent any of the parameters in (1).
is used to represent any of the parameters in (1).
4. Results and Discussion
4.1. Performance of the Estimator Based on the Bias Criterion
The performances of the estimators was examined, ranked and summed over all the parameters in each equation, having examined and summed the rank of the bias of each parameter over all the parameters in each equation the outcome is given in Table 1.
The preferred estimators for different identification status differ. The preferred estimators are also slightly affected by the two exogenous variables.
In the exact identified equation with normally distributed exogenous variables, OLS or 2SLS or both are generally preferred except for very large samples sizes![]() . At this instance, 3SLS is preferred. Also, with uniformly distributed exogenous variables, OLS or 2SLS estimators are generally preferred.
. At this instance, 3SLS is preferred. Also, with uniformly distributed exogenous variables, OLS or 2SLS estimators are generally preferred.
In the over identified equation with normally distributed exogenous variable, 2SLS estimator is generally preferred except when ![]() and when
and when![]() . At these instances, FIML estimator is preferred.
. At these instances, FIML estimator is preferred.
Also, with uniformly distributed exogenous variable 2SLS estimator is generally preferred except at very large sample sizes when ![]() and when
and when![]() . At these instances, the FIML estimator is preferred.
. At these instances, the FIML estimator is preferred.
4.2. Performances of the Estimators Based on Absolute Bias Criterion
The performances of the estimators was examined, ranked and summed over all the parameters in each equation, having examined and summed the rank of absolute bias of each parameter over all the parameters in each equation the outcome is given in Table 3.
From Table 3, at each level of sample size the sum rank were further added over the equations and preferred estimator under both exact and over identification model with the two exogenous variables were bolded. Table 4 gives the summary of the findings as follows:
The preferred estimators differ in term of identification status. The preferred estimators are slightly affected
![]()
Table 1. Summary of the total ranks of the parameter based on bias criterion when there is no correlation.
Source: Computed from simulated results of bias criterion.
by the two exogenous variables. In the exact identified equation with normally distributed exogenous variables under the absolute bias criterion the OLS estimators is preferred when ![]() and the 2SLS estimator when
and the 2SLS estimator when![]() .
.
With uniformly distributed exogenous variables the OLS estimator is generally preferred.
In the over identified equation with normally distributed exogenous variables under the absolute bias criterion, the OLS estimator is preferred when the sample size is small![]() ; 2SLS estimator when
; 2SLS estimator when![]() ; and FIML when
; and FIML when![]() .
.
With uniformly distributed exogenous variables the 2 SLS estimator is preferred over all the sample sizes. Thus, the preferred estimators are more stable in performance with uniformly distributed exogenous variables than the normally distributed exogenous variables.
4.3. Performances of the Estimators Based on Variance Criterion
The performances of the estimators was examined, ranked and summed over all the parameters in each equation, having examined and summed the rank of the variance of each parameter over all the parameters in each equation the outcome is given in Table 5.
From Table 5, at each level of sample size the sum rank were further added over the equations, and preferred estimator under both exact and over identification model with the two exogenous variables were bolded. Table 6 gives the summary of the findings as follows:
From Table 6, the following are observed about the preferred estimators under the variance criterion.
The preferred estimators differ in term of identification status. The preferred estimators are slightly affected by the two exogenous variables.
In the exact identified equation, the OLS estimator is generally preferred in all the sample sizes for both exogenous variables. In the over identified equation with normally distributed exogenous variables, OLS or 2SLS estimator are preferred when![]() ; but for
; but for![]() , the OLS or FIML estimator are preferred. With uniformly distributed exogenous variables the OLS or 2SLS estimators are generally preferred. Moreover, the 3SLS estimator replaces the 2SLS when the sample sizes is very large,
, the OLS or FIML estimator are preferred. With uniformly distributed exogenous variables the OLS or 2SLS estimators are generally preferred. Moreover, the 3SLS estimator replaces the 2SLS when the sample sizes is very large,![]() .
.
4.4. Performances of the Estimators Based on Mean Squared Error Criterion
The performances of the estimators was examined, ranked and summed over all the parameters in each equation, having examined and summed the rank of the mean squared error of each parameter over all the parameters in each equation the outcome is given in Table 8.
From Table 8 the following are observed about the preferred estimators under the mean squared error criterion.
The preferred estimators differ in term of identification status. The preferred estimators are slightly affected by the two exogenous variables. In the exact identified equation with normally distributed exogenous variables, the OLS estimator is generally preferred except when the sample size is large![]() . At these instances 2SLS is generally preferred. With uniformly distributed exogenous variables, the OLS estimator is generally preferred. In the over identified equation with normally distributed exogenous variables, the OLS estimators is preferred when
. At these instances 2SLS is generally preferred. With uniformly distributed exogenous variables, the OLS estimator is generally preferred. In the over identified equation with normally distributed exogenous variables, the OLS estimators is preferred when![]() ; 2SLS when
; 2SLS when![]() , and FIML when
, and FIML when![]() . With uniformly distributed exogenous variables the OLS estimators is preferred except when the sample size is large,
. With uniformly distributed exogenous variables the OLS estimators is preferred except when the sample size is large,![]() . At these instances, the 2SLS estimator is generally preferred. The performance of the preferred estimators is more stable with uniformly distributed exogenous variables than the normally distributed exogenous variables.
. At these instances, the 2SLS estimator is generally preferred. The performance of the preferred estimators is more stable with uniformly distributed exogenous variables than the normally distributed exogenous variables.
4.5. Performances of the Estimators Based on All the Criteria
From Table 10, the following are observed about the preferred estimators under the overall criteria.
The preferred estimators differ in term of identification status. The preferred estimators are slightly affected by the two exogenous variables.
In the exact identified equation with normally distributed exogenous variables the OLS estimator is generally preferred except when the sample size is large when![]() . At these instances, 2SLS is preferred. With uniformly distributed exogenous variable, the OLS estimator is preferred for all sample sizes.
. At these instances, 2SLS is preferred. With uniformly distributed exogenous variable, the OLS estimator is preferred for all sample sizes.
In the over identified equation with normally exogenous variables the OLS estimators is preferred when the samples sizes is small![]() ; 2SLS when
; 2SLS when![]() , and
, and![]() ; 3SLS when
; 3SLS when ![]() and FIML estimator with
and FIML estimator with![]() .
.
With uniformly distributed exogenous variable, the 2SLS estimator is preferred except when the sample sizes is large![]() . At this instance the 3SLS estimator is preferred.
. At this instance the 3SLS estimator is preferred.
From Table 1, at each level of sample size the sum rank were further added over the equations, and preferred estimator under both exact and over identification model with the two exogenous variables were bolded. Table 2 gives the summary of the preferred estimators.
From Table 3, at each level of sample size, the sum rank were further added over the equations, and preferred estimator under both exact and over identification model with the two exogenous variables were bolded. Table 4 gives the summary of the preferred estimators.
From Table 5, at each level of sample size the sum rank were further added over the equations. The preferred
![]()
Table 2. Summary of the preferred estimators based on bias criterion.
Source: Table 1.
![]()
Table 3. Performances of the estimator based on absolute bias criterion.
Source: Computed from simulated results of Absolute bias criterion.
![]()
Table 4. Summary of the preferred estimators based on absolute bias criterion.
Source: Table 3.
![]()
Table 5. Performances of the estimators based on variance criterion.
Source: Computed from simulated results of variance criterion.
estimators under both exact and over identification model with the two exogenous variables were made bold. Table 6 gives the summary of the preferred estimators.
From Table 7, at each level of sample size the sum rank were further added over the equations and preferred
![]()
Table 6. Summary of the preferred estimators under variance criterion.
Source: Table 5.
![]()
Table 7. Performances of the estimators based on mean squared error criterion.
Source: Computed from simulated results of Mean squared error criterion.
estimator under both exact and over identification model with the two exogenous variables were bolded. Table 8 gives the summary of the preferred estimators.
4.6. Overall Examination of the Model Parameters
The overall summary of the performances of the estimators having examined and obtained by adding the total ranks over all the criteria is given in Table 9.
From Table 9, at each level of sample size the sum of the rank were further added over all the criteria and preferred estimator under both exact and over identification model with the two exogenous variables were bolded. Table 10 gives the summary of the preferred estimators.
![]()
Table 8. Summary of the preferred estimators when there is no correlation under mean squared error criterion.
Source: Table 7.
![]()
Table 9. Overall performances of the estimators based on all criteria.
Source: Computed from Table 1, Table 3, Table 5 and Table 7.
![]()
Table 10. Overall summary of the best estimators on the basis of all criteria.
Source: Table 4 and Table 9.
5. Conclusions
The performances of the estimators are affected by the distribution of the exogenous variables. The best estimators are more stable over the levels of sample size with uniformly distributed exogenous variables than the normally distributed exogenous variables.
In exact identified equation with normally distributed exogenous variables the following were observed.
For low sample sizes, OLS is the best performed estimator. In medium sample sizes, OLS or 2SLS is the best performed estimator and 2SLS estimator is the best performed in the large sample sizes. Whereas with uniformly distributed exogenous variables, OLS is the best performed estimator in the entire sample sizes category.
In over identified equation with normally distributed exogenous variables, the following are observed.
For low sample sizes, OLS or 2SLS is the best performed estimator, in medium sample sizes 2SLS\3SLS is the best performed estimator and FIML estimator performed best in the large sample sizes. Whereas with uniformly distributed exogenous variables, 2SLS is the best in low and medium sample sizes category, but 2SLS/ 3SLS estimator is the best in large sample sizes category.
Hence, when there is no correlation of any form in the model the performances of the estimators are affected by the distribution of the exogenous variables in simultaneous equation models.