User Preferences-Based and Time-Sensitive Location Recommendation Using Check-In Data ()
1. Introduction
Location based on services applications, such as Foursquare, Facebook Place and Whrrl, becomes popular among more and more users. Such applications allow users to check in their own Point of Interests (POIs), share activities and post comments about their experiences, so that they can share their real-life with their friends. For example, a user checks in his visit to a fast food or theater in Foursquare, and at the same time posts his comment about it, then the friends can refer to his comment to choose their favorite food or theater. The check-in data reflect users’ interests and habits and can help social networks to better understand the intent of their behavior. A check-in data usually contains timestamps, geographic information expressed by latitude and longitude generally and even textual information. It is a popularity research using those data to recommend suitable path and POIs to users [1] [2] .
The timestamp of check-in records the activities of the user for a period of one day or a point of time. Figure 1 shows two locations’ check-in data frequency distribution at different time point of all days which the locations are randomly selected from our check-in data. From these two plots we know that the numbers of users to visit these locations are very much different at different time. The recommended system should aware these diversities and recommend appropriate locations according to the user’s current time. For instance, the time is 15:00 now and a user will visit a venue, then the system should recommend for him of location 153,505 instead of location 14,710.
Figure 2 is check-in distributions of two different users in different locations. From the figure we can observe that for most locations, the user may only visit for a day or two, but some locations user check-in frequently. The recommended system should recommend the locations of their interests.
As above discussion, in this paper, we argue that a high quality location recommendation has to simultaneously consider the following factors.
The first is the popularity of the location. Location popularity depicts the ability of a location to attract the users to visit it. The higher the popularity of a location, the more users check-in in it. The second is user preferences. We mine user’s preferences through analyzing the check-in data from the users’ history, and then recommend them with their favorite venue. For example, if a user often visits location l where has lower popularity, This indicate the user may visit this location again based on his preferences. The third is the time of user visits and the time feature of locations. From the above analysis, we know that the number of days The duration for a user visiting the same location varies a lot, and each location the day at different time users visited vary a great deal. How to recommend a reasonable location according the both time is a problem to be solved in the paper. The fourth is current location of a user. In the mobile Internet, most users will want to visit the venue where is near to their present location, but not far away venue of thousands of miles, when they expect the system recommended a location for them. Taking account of a hunger user who is now in Beijing wanting to visit a noodle house, if the system recommends all the noodle houses in New York, the user should not be satisfied. The fifth is the views of the user’s friends.
![]()
Figure 1. The check-in distributions of (a) location 153,505, (b) location 14,710.
![]()
Figure 2. The number of date (a) user 1251 visited, (b) user 2 visited.
If many of the user’s friends have visited a location, it is likelihood that the user will visit this location. Or if two users are not friends, but they often visit the same location, their preferences may be the similarity.
2. Related Work
2.1. Filtering-Based Recommended Systems
Collaborative filtering-based methods make use of the check-in histories of a group of similar users or a set of similar locations to generate location recommendations [3] .
Leung et al. [3] propose a Collaborative Location Recommendation framework (CLR) for location recommendation. CLR employs a dynamic clustering algorithm to cluster the trajectory data into groups of similar users, similar activities and similar locations efficiently for new update in order to improve the efficiency of CLR. Zheng et al. [1] [4] mine the knowledge of location feature, activity-activity and location-activity correlations from history GPS data, and then apply a collective matrix factorization method to mine interesting locations and activities, and use them to recommend to the users where they can visit if they want to perform some specific activities and what they can do if they visit some specific places. Zheng et al. [5] employ a hierarchical-graph- based similarity measurement (HGSM) to uniformly model each individual’s location history and effectively measure the similarity among users. Then incorporate a content-based method into a user-based collaborative filtering algorithm, which uses HGSM as the user similarity measure, to estimate the rating of a user on an item. Ye et al. [6] develop a collaborative recommendation algorithm fusing geographical influence and social influence.
In [7] [8] , they merge a data from activity-activity and location-feature with location-activity and then fuse matrix factorization with geographical and social influence for POI recommendation in LBSNs. Huang et al. [9] [10] annotate user profiles with context, measuring similarities between contexts and similarities between users, and incorporating context information into the CF process for POI recommendation. Gao et al. [11] [12] employ the social network information with geo-social correlation model to capture social correlations on LBS to recommend venue to users.
2.2. Personalized Location Recommendations
Bao et al. [13] model each individual’s personal preferences with a weighted category hierarchy and infer the expertise of each user in a city with respect to different category of locations according to their location histories using an iterative learning model in offline part. And then in online part selects candidate local experts in a geospatial range to recommend locations to users. In [14] , Ying et al. integrate user preferences and location properties simultaneously for recommending users urban POIs, and in [15] , they take into account the user movements, online texting and social information to discover the relationship between users’ information needs and provided information for followee recommendation. Hsieh et al. [16] try to recommend users time-sensitive route, but they didn’t consider users oneself preferences and the influence of user’s friends for recommendation. Gao et al. [17] explore the effects of temporal features on location recommendation, and offer an overview of personalized location recommendation with location based social networks [18] . Chen et al. [19] develop a greedy algorithm to optimize the point-of-interest recommendation by information coverage for location category.
3. Location Recommending Models
3.1. Popularity and Temporal Characteristics of Location
The higher the popularity of the location, the more people to visit this location, accordingly, the more users check-in in the location in the data. Most users prefer to choose the popularity locations of the recommended results because the locations which have high popular can provide a better service, and more worthy of trust. According to the popularity of the location 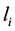 to recommend user
to recommend user 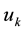 defined as follows:
defined as follows:
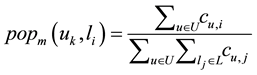 (1)
(1)
where U and L are the set of users and locations in the data, 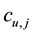 is the check-in counts of user u in location
is the check-in counts of user u in location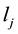 . Such a way to measure the popularity of a location has a case, namely although a location (i.e. home) check-in frequency but all of them are check-in by a few or even a single user, the actually the popularity of the location is lower. We user the entropy to compute the location popularity to avoid the aforementioned case, the definition as follows:
. Such a way to measure the popularity of a location has a case, namely although a location (i.e. home) check-in frequency but all of them are check-in by a few or even a single user, the actually the popularity of the location is lower. We user the entropy to compute the location popularity to avoid the aforementioned case, the definition as follows:
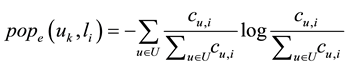 (2)
(2)
From the above analysis, we know that the system should consider the visiting time of users when recommending location for them. If the user’s current time is not in the period of the location popularity, then it should not be recommended to the user, or recommended probability should be minimal. So, we using the visiting time of user modify the equation as following:
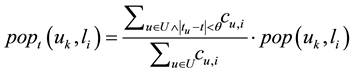 (3)
(3)
where t is the time of the user, 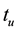 is the check-in time of the user u,
is the check-in time of the user u, 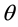 is a threshold.
is a threshold. 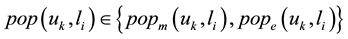 . It is difficult to determine the value of the
. It is difficult to determine the value of the 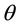 for each location due to the difference of them. So, we use the following formula instead:
for each location due to the difference of them. So, we use the following formula instead:
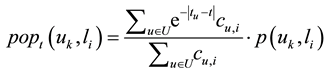 (4)
(4)
According to the nature of the exponential function 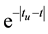 we know that the more closer from the user visiting time, the higher similarity for them.
we know that the more closer from the user visiting time, the higher similarity for them.
3.2. User Preference
The users’ historical check-in data implied their interests. We learn the users’ preferences from their history check-ins in order to recommend their appropriate location.
Figure 3(a) and Figure 3(b) are the check-in probability distribution of the two users who are randomly selected from the data and the probability distribution of all these locations. From the figure we can see that in some locations the two users’ check-in frequency, but the other users check-in fewer, while in other locations, the situation is opposite. Accordingly, we use “TF-IDF” to characterize the user’s preferences, defined as follows:
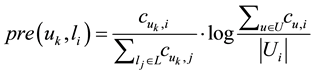 (5)
(5)
where the ![]() is the set of users who have checked in at this location
is the set of users who have checked in at this location![]() . Through statistical users’ histories check-in we found that 26.7% of users will visit the same location at least twice in one day. If a user visits a lo-
. Through statistical users’ histories check-in we found that 26.7% of users will visit the same location at least twice in one day. If a user visits a lo-
![]()
Figure 3. The distribution of (a) user 0 and all other users in location which user 0 visited, (b) user 273 and other users in location which user 273 visited.
cation very frequency in a short period, we could not determine the user must be interested in this location. Conversely, if a user visits one location in a long period, it is likely that he is interested in that location. So we fuse the time factor into user preferences, namely:
![]() (6)
(6)
where ![]() is the count of day the user
is the count of day the user ![]() check-in in the location
check-in in the location![]() .
.
3.3. Social Influences of Friends
Friends usually have the same preferences and habits and they may check-in in the same location at the same time, and also may use others experience for reference to visit a location. The similarity of the two users is defined using meet/min coefficient [20] :
![]() (7)
(7)
where the ![]() is the set of friends of the user u. The standard meet/min coefficient counts the number of common friends of the two users and scales by the size of the friends of at least one of two users whose friends are smaller.
is the set of friends of the user u. The standard meet/min coefficient counts the number of common friends of the two users and scales by the size of the friends of at least one of two users whose friends are smaller.
There is a unique relationship between friends of the check-in data, namely the two users may check-in in the same location. This situation is better able to show the two users have the same preferences. So we calculate the similarity of the two users using their common check-ins as following:
![]() (8)
(8)
where the ![]() is the check-in set of the user u.
is the check-in set of the user u.
Adamic et al. [21] measure the two users’ similarity though the items which are shared by them. We will use it to calculate the similarity between two users who are check-in in the same location. It calculates by the inverse log frequency of their common check-in locations:
![]() (9)
(9)
Friend-based recommendation uses collaborative filtering algorithm [6] :
![]() (10)
(10)
where ![]() ,and
,and ![]() .
.
3.4. Fusing Model
It can improve the performance of the system if using variety features [3] [6] [14] . So we integrated all of features which mentioned above and select the best algorithm in each feature to recommend. Before fusion, we normalize each score of the feature using maximum score respectively. The fusion function is as following:
![]() (11)
(11)
where the two weighting parameters ![]() and
and ![]() are in the range of [0, 1] and
are in the range of [0, 1] and![]() .
.
4. Experiments and Analysis
4.1. Experimental Data
We employ the Gowalla dataset [22] of half year check-ins which has been used for location-based analysis as an experimental data. The Gowalla dataset contains 4,396,820 check-in records from May to Oct. of 2010. We only use the locations which more than one check-in in it because if the location have only one check-in that such location we can’t use any of the methods to recommend. So in actually the dataset contains 86,802 users, 612,544 locations and 3,908,034 check-ins. We randomly select the 10,000 users from the Gowalla dataset as the test users and their last check-in to estimate, all of the remaining data are training data. Our goal is to recommend the location of the user expecting to visit according to the users’ history check-ins.
4.2. Evaluated Recommendation Approaches
We want to observe the performance of each recommended method through the experiment. Simultaneously, looking at while it can improve the recommendation accuracy or not when we consider the user’s visiting time and the time characteristics of the locations. In LBS applications, user accepting the recommendation list is real-time, and most of them hope that the recommended locations are nearby them and they can arrive in a short time. Therefore, we refer to literature [21] just utilizing the locations which are 5 kilometers away from the user’s current location as a candidate recommendation set. We compared the method proposed in our paper with the baseline of presenting in [6] , and meanwhile compared influence of the methods between the within time feature and without time factor.
USG: It is a collaborative recommendation algorithm which fuses the social influence and geographic influence base on naïve Baycsian [6] . LPm: using the popularity of the location which it is calculated by the users’ check-in frequency recommend; LPe: the popularity of location is calculated using the entropy; LPmt/LPet: considering the visiting time of the users and the time feature of the location to recommend when using the popularity of the location; UP: according to the user’s preferences to recommend that learned from the users’ history check-in data; UPt: considering the number of the day which user check-in in the location when using the preferences of user to recommend; Cf: recommending location for user according to the collaborative filtering of friends of the user; Cl: recommending location for user according to the collaborative filtering of friends who are check-in at least one same location with the user; Clog: the fewer users of one location check-in which of two users visit, the higher similarity of the two users; LUt: fusing the popularity of a location, the preferences of user and time features to recommend; LUCt: fusing the popularity of a location, the preferences of user, and the influence of the friends of user and time features to recommend.
4.3. Performance Comparison and Analysis
In this section we evaluate and compare the performance of each method. First, let’s look at the two methods LPm and LPe which base the popularity of the location, the performance of LPe which measures the popularity of a location using the entropy is not as good as the method of LPm which measures the popularity of a location using the location popular. We observer the results and find that some location are the private location (i.e. home), when using the entropy to recommend, the similarity is zero. When considering the time feature of a location, the performance of the LPet is lower than the LPe. The reason is that in some location, there are several users check-in in them and the time of check-ins is scattered, if consider the time in these location, the evaluation precision is decline. However, the performance of the LPmt is increasing because of many locations’ active time is inconsistent with the user’s visiting time, when taking into account the time feature, these locations are filtered. Similarly, the performance of the method based user preferences also can improve in some extend when augments the time factor.
In the user-based collaborative filtering recommendation, the methods of Cl and Clog which recommend using the friends that check-in in the same location with the user are better than the method Cf which recommends using all of the user’s friends. Intuitively, the friends who visited the same locations with the user are likely having the same interests for user. However, the performance of all the user-based CF are not as good as the methods of based location popularity, because many of the candidate location are not check-ined by the one of the user’s friends, and the similarity is zero.
In all the methods of based the one feature to recommend, the performance of the user preferences of UP and UPt is the best. The results stated that the majority of the users’ interests unchanged for a long time, they are more likely to visit the location which they have visited.
Continue to observe Figure 4 we can find that considering the user preferences and the popularity of the location at the same time, the precision and the recall are better than any single feature method and the performance
![]()
Figure 4. (a) Precision and (b) recall of the experimental results for all the methods.
improved on average by 25%. And once again fusing the user-based CF, the performance of the system increases a small, but computational complexity will increase a lot.
Finally, the performance of the method of LUPt which are proposed in this paper is outperformance than the baseline method of USG which is presented in [6] . The reason is the USG didn’t consider the user’s preference, time feature of the user and the current location of the user, however, we consider all of influence factors.
4.4. The Influence of the Recommendation Range
In general, the current location of the user is impact on whether the user will visit the recommendation location and users are more inclined to visit the location where is closer to the current location [6] [13] . We study the performance of the different methods in different distance from the user current location. Observing Figure 5 we find that the precision and recall are reduced monotonically as the distance increasing except the baseline method of USG which don’t consider the user’s current location. When the distance increasing to 10 km, the performance of the methods of based the popularity of location and the user-based CF is lower than the baseline of USG, the preference of fusing models of LUt and LUCt decreases more because of the popularity factor of the location, but it still better than the baseline of the USG.
4.5. The Impact of the Number of the User’s Check-Ins
The number of the user’s history check-ins has an important impact on the recommendation system. We divide
![]()
Figure 5. The range impact of (a) precision and (b) recall for recommendation.
the users into nine intervals according to the number of their check-ins, the fewer the check-in numbers, the more users, and then the interval is smaller. Observing Figure 6, first of all, we see the greatest changed methods of the USG, UP and UPt. When the number of the users’ check-in is lower than ten, the performance of the baseline of USG is better than all of the methods except the fusing methods of LUt and LUCt. The performance achieved the best when the number of the user’s check-in in the range of two to five hundreds, if the number of the check-ins continue to increase, the precision and the recall are decline. There have two reasons for the phenomenon: the one is that it is difficult to capture the preferences of users when their check-ins is a lot because of a wide range of their interests.
5. Conclusion
In this paper, we present user preferences and time sensitive recommender systems to recommend an appropriate location for user in location-based social networks. We primarily consider five factors to recommend location for user. According to the experimental results, our approach significantly outperforms the baseline of USG and the other recommendation methods, including the collaborative filtering method and user’s preferences method. The results show that the performance of the recommender system can improve when considering the time feature of the location and the user visiting time.
Acknowledgements
This work is partially supported by grant from the Natural Science Foundation of China (No. 61277370), Natu-
![]()
Figure 6. The check-in count impact of (a) precision and (b) recall.
ral Science Foundation of Liaoning Province, China (No. 201202031, 2014020003), State Education Ministry and The Research Fund for the Doctoral Program of Higher Education (No. 20090041110002).