A Subspace Iteration for Calculating a Cluster of Exterior Eigenvalues ()
1. Introduction
In this paper we present a new subspace iteration for calculating a cluster of k exterior eigenvalues of a given symmetric matrix,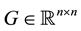 . Other names for such eigenvalues are “peripheral eigenvalues” and “extreme eigenvalues”. As with other subspace iterations, the method is best suited for handling large sparse matrices in which a matrix-vector product needs only
. Other names for such eigenvalues are “peripheral eigenvalues” and “extreme eigenvalues”. As with other subspace iterations, the method is best suited for handling large sparse matrices in which a matrix-vector product needs only 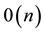 flops. Another underlying assumption is that
flops. Another underlying assumption is that 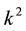 is considerably smaller than n. Basically there are two types of subspace iterations for solving such problems. The first category regards “block” versions of the Power method that use frequent orthogonalizations. The eigenvalues are extracted with the Rayleigh-Ritz procedure. This kind of method is also called “orthogonal iterations” and “simultaneous iterations”. The second category uses the Rayleigh-Ritz process to achieve approximation from a Krylov subspace. The Restarted Lanczos method turns this approach into a powerful tool. For detailed discussions of these topics see, for example, [1] -[19] .
is considerably smaller than n. Basically there are two types of subspace iterations for solving such problems. The first category regards “block” versions of the Power method that use frequent orthogonalizations. The eigenvalues are extracted with the Rayleigh-Ritz procedure. This kind of method is also called “orthogonal iterations” and “simultaneous iterations”. The second category uses the Rayleigh-Ritz process to achieve approximation from a Krylov subspace. The Restarted Lanczos method turns this approach into a powerful tool. For detailed discussions of these topics see, for example, [1] -[19] .
The new iteration applies a Krylov subspace method to collect information on the desired cluster. Yet it has an additional flavor: it uses an interlacing theorem to improve the current estimates of the eigenvalues. This enables the method to gain speed and accuracy.
If G happens to be a singular matrix, then it has zero eigenvalues, and any orthonormal basis of Null (G) gives the corresponding eigenvectors. However, in many practical problems we are interested only in non-zero eigenvalues. For this reason the coming definitions of the term “a cluster of k exterior eigenvalues” do not include zero eigenvalues. Let r denote the rank of G and assume that k < r. Then G has r non-zero eigenvalues that can be ordered to satisfy
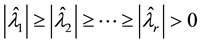 (1.1)
(1.1)
or
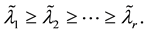 (1.2)
(1.2)
The new algorithm is built to compute one of the following four types of target clusters that contain k extreme eigenvalues.
A dominant cluster
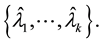 (1.3)
(1.3)
A right-side cluster
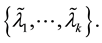 (1.4)
(1.4)
A left-side cluster
 (1.5)
(1.5)
A two-side cluster is a union of a right-side cluster and a left-side cluster. For example, 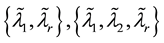 , and so forth.
, and so forth.
Note that although the above definitions refer to clusters of eigenvalues, the algorithm is carried out by computing the corresponding k eigenvectors of G. The subspace that is spanned by these eigenvectors is called the target space. The restriction of the target cluster to include only non-zero eigenvalues means that the target space is contained in Range(G). For this reason the search for the target space is restricted to Range(G).
Let us turn now to describe the basic iteration of the new method. The qth iteration,  , is composed of the following five steps. The first step starts with a matrix
, is composed of the following five steps. The first step starts with a matrix 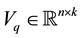 that contains “old” information on the target space, a matrix
that contains “old” information on the target space, a matrix 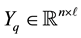 that contains “new” information, and a matrix
that contains “new” information, and a matrix 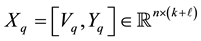 that includes all the known information. The matrix Xq has
that includes all the known information. The matrix Xq has  orthonormal columns. That is
orthonormal columns. That is
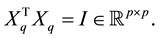
(Typical values for 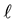 are
are ![]() or
or![]() .)
.)
Step 1: Eigenvalues extraction. First compute the Rayleigh quotient matrix
![]()
Then compute k eigenpairs of Sq which correspond to the target cluster. (For example, if it is desired to compute a right-side cluster of G, then compute a right-side cluster of Sq.) The corresponding k eigenvectors of Sq are assembled into a matrix
![]()
which is used to compute the related matrix of Ritz vectors,
![]()
Step 2: Collecting new information. Compute a matrix ![]() that contains new information on the target space. The columns of Bq are forced to stay in Range(G).
that contains new information on the target space. The columns of Bq are forced to stay in Range(G).
Step 3: Discard redundant information. Orthogonalize the columns of Bq against the columns of![]() . There are several ways to achieve this task. In exact arithmetic the resulting matrix, Zq, satisfies the Gram-Schmidt formula
. There are several ways to achieve this task. In exact arithmetic the resulting matrix, Zq, satisfies the Gram-Schmidt formula
![]()
Step 4: Build an orthonormal basis. Compute a matrix,
![]()
whose columns form an orthonormal basis of![]() . This can be done by a QR factorization of Zq (if
. This can be done by a QR factorization of Zq (if ![]() is smaller than
is smaller than![]() , then
, then ![]() is redefined as
is redefined as![]() ).
).
Step 5: Define ![]() by the rule
by the rule
![]()
which ensures that
![]()
The above description is aimed to clarify the purpose of each step. Yet there might be better ways to carry out the basic iteration. The restriction of the search to Range(G) is important when handling low-rank matrices. However, if G is known to be a non-singular matrix, then there is no need to impose this restriction.
The plan of the paper is as follows. The interlacing theorems that support the new method are given in the next section. Let![]() , and denote the Ritz values which are computed at Step 1 of the qth iteration. Then it is shown that each iteration gives a better approximation of the target cluster. Moreover, the sequence
, and denote the Ritz values which are computed at Step 1 of the qth iteration. Then it is shown that each iteration gives a better approximation of the target cluster. Moreover, the sequence ![]() proceeds monotonously toward the desired eigenvalue of G. The rate of convergence depends on the information matrix Bq. Roughly speaking, the better information we get, the faster the convergence is. Indeed, the heart of the algorithm is the computation of Bq. It is well-known that a Krylov subspace which is generated by G gives valuable information on peripheral eigenvalues of G, e.g., [4] [5] [7] [13] [15] . The basic scheme of the new method uses this observation to define Bq, see Section 3. Difficulties that arise in the computation of non-peripheral clusters are discussed in Section 4. The fifth section considers the use of acceleration techniques; most of them are borrowed from orthogonal iterations. Another related iteration is the Restarted Lanczos method. The links with these methods are discussed in Sections 6 and 7. The paper ends with numerical experiments that illustrate the behavior of the proposed method.
proceeds monotonously toward the desired eigenvalue of G. The rate of convergence depends on the information matrix Bq. Roughly speaking, the better information we get, the faster the convergence is. Indeed, the heart of the algorithm is the computation of Bq. It is well-known that a Krylov subspace which is generated by G gives valuable information on peripheral eigenvalues of G, e.g., [4] [5] [7] [13] [15] . The basic scheme of the new method uses this observation to define Bq, see Section 3. Difficulties that arise in the computation of non-peripheral clusters are discussed in Section 4. The fifth section considers the use of acceleration techniques; most of them are borrowed from orthogonal iterations. Another related iteration is the Restarted Lanczos method. The links with these methods are discussed in Sections 6 and 7. The paper ends with numerical experiments that illustrate the behavior of the proposed method.
2. Interlacing Theorems
In this section we establish a useful property of the proposed method. We start with two well-known interlacing theorems, e.g., [6] [7] [19] .
Theorem 1 (Cauchy interlace theorem) Let ![]() be a symmetric matrix with eigenvalues
be a symmetric matrix with eigenvalues
![]() (2.1)
(2.1)
Let the symmetric matrix ![]() be obtained from G by deleting
be obtained from G by deleting ![]() rows and the corresponding
rows and the corresponding ![]() columns. Let
columns. Let
![]() (2.2)
(2.2)
denote the eigenvalues of H. Then
![]() (2.3)
(2.3)
and
![]() (2.4)
(2.4)
In particular, for ![]() we have the interlacing relations
we have the interlacing relations
![]() (2.5)
(2.5)
Corollary 2 (Poincaré separation theorem) Let the matrix ![]() have k orthonormal columns. That is
have k orthonormal columns. That is![]() . Let the matrix
. Let the matrix ![]() have the eigenvalues (2.2). Then the eigenvalues of H and G satisfy (2.3) and (2.4).
have the eigenvalues (2.2). Then the eigenvalues of H and G satisfy (2.3) and (2.4).
The next theorem seems to be new. It sharpens the above results by removing zero eigenvalues.
Theorem 3 Assume that the non-zero eigenvalues of G satisfy (1.2) where![]() . Let the matrix
. Let the matrix ![]() satisfy
satisfy
![]() (2.6)
(2.6)
Let the matrix ![]() has the eigenvalues (2.2). Then the eigenvalues of G and H satisfy the inequalities
has the eigenvalues (2.2). Then the eigenvalues of G and H satisfy the inequalities
![]() (2.7)
(2.7)
and
![]() (2.8)
(2.8)
Proof. Let the matrix ![]() be obtained by completing the columns of V to be an orthonormal basis of
be obtained by completing the columns of V to be an orthonormal basis of![]() . Then
. Then ![]() is a full rank symmetric matrix whose eigenvalues are the non-zero eigenvalues of
is a full rank symmetric matrix whose eigenvalues are the non-zero eigenvalues of ![]() which are given in (1.2). Since the first k columns of Y are the columns of V, the matrix
which are given in (1.2). Since the first k columns of Y are the columns of V, the matrix ![]() is obtained by deleting from
is obtained by deleting from ![]() the last
the last ![]() rows and the last
rows and the last ![]() columns. Hence the inequalities (2.7) and (2.8) are direct corollary of Cauchy interlace theorem.
columns. Hence the inequalities (2.7) and (2.8) are direct corollary of Cauchy interlace theorem. ![]()
Let us return now to consider the qth iteration of the new method,![]() . Assume first that the algorithm is aimed at computing a cluster of k right-side eigenvalues of G,
. Assume first that the algorithm is aimed at computing a cluster of k right-side eigenvalues of G,
![]()
and let the eigenvalues of the matrix
![]()
be denoted as
![]()
Then the Ritz values which are computed at Step 1 are
![]()
and these values are the eigenvalues of the matrix
![]()
Similarly,
![]()
are the eigenvalues of the matrix
![]()
Therefore, since the columns of ![]() are the first k columns of
are the first k columns of![]() ,
,
![]()
On the other hand from Theorem 3 we obtain that
![]()
Hence by combining these relations we see that
![]() (2.9)
(2.9)
for ![]() and
and![]() .
.
Assume now that the algorithm is aimed at computing a cluster of k left-side eigenvalues of G,
![]()
Then similar arguments show that
![]() (2.10)
(2.10)
for![]() , and
, and![]() .
.
Recall that a two-sides cluster is the union of a right-side cluster and a left-side one. In this case the eigenvalues of Sq that correspond to the right-side satisfy (2.9) while eigenvalues of Sq that correspond to the left-side satisfy (2.10). A similar situation occurs in the computation of a dominant cluster, since a dominant cluster is either a right-side cluster, a left-side cluster, or a two-sides cluster.
3. The Krylov Information Matrix
It is left to explain how the information matrices are computed. The first question to answer is how to define the starting matrix X1. For this purpose we consider a Krylov subspace that is generated by the vectors
![]() (3.1)
(3.1)
where ![]() is a “random” vector. That is, a vector whose entries are uniformly distributed between −1 and 1. Then X1 is defined to be a matrix whose columns provide an orthonormal basis for that space. This definition ensures that
is a “random” vector. That is, a vector whose entries are uniformly distributed between −1 and 1. Then X1 is defined to be a matrix whose columns provide an orthonormal basis for that space. This definition ensures that ![]() is contained in range(G). The actual computation of X1 can be done in a number of ways.
is contained in range(G). The actual computation of X1 can be done in a number of ways.
The main question is how to define the information matrix
![]() (3.2)
(3.2)
which is needed in Step 2. Following the Krylov subspace approach, the columns of ![]() are defined by the rule
are defined by the rule
![]() (3.3)
(3.3)
where ![]() is some vector norm. In this way
is some vector norm. In this way ![]() is determined by the starting vector
is determined by the starting vector![]() .
.
The ability of a Krylov subspace to approximate a dominant subspace is characterized by the Kaniel-Paige- Saad (K-P-S) bounds. See, for example, ([5] , pp. 552-554), ( [7] , pp. 242-247), ( [13] , pp. 272-274), and the references therein. One consequence of these bounds regards the angle between ![]() and the dominant subspace: The smaller the angle, the better approximation we get. This suggests that
and the dominant subspace: The smaller the angle, the better approximation we get. This suggests that ![]() should be defined as the sum of the current Ritz vectors. That is,
should be defined as the sum of the current Ritz vectors. That is,
![]() (3.4)
(3.4)
where vector of ones.
Another consequence of the K-P-S bounds is that a larger Krylov subspace gives better approximations. This suggests that using (3.2)-(3.3) with a larger ![]() is expected to result in faster convergence, since
is expected to result in faster convergence, since
![]() (3.5)
(3.5)
A different argument that supports the last observation comes from the interlacing theorems: Consider the use of (3.2)-(3.3) with two values of ![]() say
say![]() , and let
, and let ![]() and
and ![]() denote the corresponding orthonormal matrices. Then the first
denote the corresponding orthonormal matrices. Then the first ![]() columns of
columns of ![]() can be obtained from the columns of
can be obtained from the columns of![]() . Therefore, a larger value of
. Therefore, a larger value of ![]() is likely to give better approximations. However, the use of the above arguments to assess the expected rate of convergence is not straightforward.
is likely to give better approximations. However, the use of the above arguments to assess the expected rate of convergence is not straightforward.
4. Treating a Non-Peripheral Cluster
A cluster of eigenvalues is called peripheral if there exists a real number, ![]() , for which the corresponding eigenvalues of the shifted matrix,
, for which the corresponding eigenvalues of the shifted matrix, ![]() , turn out to be a dominant cluster. The theory developed in Section 2 suggests that the algorithm can be used to compute certain types of non-peripheral clusters (see the coming example). However, in this case it faces some difficulties. One difficulty regards the rate of convergence, as the K-P-S bounds tell us that approximations of peripheral eigenvalues are better than those of internal eigenvalues. Hence when treating a non-peripheral cluster we expect a slower rate of convergence.
, turn out to be a dominant cluster. The theory developed in Section 2 suggests that the algorithm can be used to compute certain types of non-peripheral clusters (see the coming example). However, in this case it faces some difficulties. One difficulty regards the rate of convergence, as the K-P-S bounds tell us that approximations of peripheral eigenvalues are better than those of internal eigenvalues. Hence when treating a non-peripheral cluster we expect a slower rate of convergence.
A second difficulty comes from the following phenomenon. To simplify the discussion we concentrate on a left-side cluster of a positive semi-definite matrix that has several zero eigenvalues. In this case the target cluster is composed from the k smallest non-zero eigenvalues of G. Then, once the columns of ![]() become close to eigenvectors of G, the matrices Bq and Zq turn out to be ill-conditioned. This makes
become close to eigenvectors of G, the matrices Bq and Zq turn out to be ill-conditioned. This makes ![]() vulnerable to rounding errors in the following manner. The orthogonality of
vulnerable to rounding errors in the following manner. The orthogonality of ![]() is kept, but now
is kept, but now ![]() may fail to stay in Range(G). The same remark applies to
may fail to stay in Range(G). The same remark applies to![]() , since
, since ![]() is part of
is part of![]() . In this case, when
. In this case, when ![]() contains some vectors from Null(G), the smallest eigenvalues of the matrix
contains some vectors from Null(G), the smallest eigenvalues of the matrix ![]() may be smaller than the smallest non-zero eigenvalue of G. Consequently the algorithm may converge toward zero eigenvalues of G. Hence it is necessary to take a precaution to prevent this possibility. (Similar ill-conditioning occurs when calculating a peripheral cluster, but in this case it does no harm.)
may be smaller than the smallest non-zero eigenvalue of G. Consequently the algorithm may converge toward zero eigenvalues of G. Hence it is necessary to take a precaution to prevent this possibility. (Similar ill-conditioning occurs when calculating a peripheral cluster, but in this case it does no harm.)
One way to overcome the last difficulty is to force ![]() to stay inside Range(G). This can be done by the following modification of Step 3.
to stay inside Range(G). This can be done by the following modification of Step 3.
Step 3*: As before, the step starts by orthogonalizing the columns of ![]() against the current Ritz vectors (the columns of
against the current Ritz vectors (the columns of![]() ). This gives us an
). This gives us an ![]() matrix
matrix![]() . Then the matrix
. Then the matrix ![]() is orthogonalized against the Ritz vectors, giving
is orthogonalized against the Ritz vectors, giving![]() .
.
A second possible remedy is to force ![]() to stay inside Range(G). This can be done by correcting Step 5 in the following way.
to stay inside Range(G). This can be done by correcting Step 5 in the following way.
Step 5*: Compute the matrices ![]() and
and![]() . Then
. Then ![]() is defined to be a matrix
is defined to be a matrix
whose columns form an orthonormal basis of![]() . This can be done by a QR factorization of
. This can be done by a QR factorization of![]() .
.
In the experiments of Section 8, we have used Step 3* to compute a left-side cluster of Problem B, and Step 5* was used to compute a left-side cluster of Problem C. However the above modifications are not always helpful, and there might be better ways to correct the algorithm.
5. Acceleration Techniques
In this section we outline some possible ways to accelerate the rate of convergence. The acceleration is carried out in Step 2 of the basic iteration, by providing a “better” information matrix,![]() . All the other steps remain unchanged.
. All the other steps remain unchanged.
5.1. Power Acceleration
In this approach the columns of ![]() are generated by replacing (3.3) with the rule
are generated by replacing (3.3) with the rule
![]() (5.1)
(5.1)
where ![]() is a small integer. Of course in practice the matrix
is a small integer. Of course in practice the matrix ![]() is never computed. Instead
is never computed. Instead ![]() is computed by a sequence of m matrix-vector multiplications and normalizations. The above acceleration is suitable for calculating a dominant cluster. In other exterior clusters it can be used with a shift. The main benefit of (5.1) is in reducing the portion of time that is spent on orthogonalizations and the Rayleigh-Ritz procedure (see Table 4).
is computed by a sequence of m matrix-vector multiplications and normalizations. The above acceleration is suitable for calculating a dominant cluster. In other exterior clusters it can be used with a shift. The main benefit of (5.1) is in reducing the portion of time that is spent on orthogonalizations and the Rayleigh-Ritz procedure (see Table 4).
5.2. Using a Shift
The shift operation is carried out by replacing (5.1) with
![]() (5.2)
(5.2)
where ![]() is a real number. It is well known that Krylov subspaces are invariant under the shift operation. That is, for
is a real number. It is well known that Krylov subspaces are invariant under the shift operation. That is, for ![]() the Krylov space that is generated by (5.2) equals that of (3.3), e.g., ([7] , p. 238). Hence the shift operation does not accelerate the rate of convergence. Yet, it helps to reduce the deteriorating effects of rounding errors.
the Krylov space that is generated by (5.2) equals that of (3.3), e.g., ([7] , p. 238). Hence the shift operation does not accelerate the rate of convergence. Yet, it helps to reduce the deteriorating effects of rounding errors.
Assume first that G is a positive definite matrix and that we want to compute a left-side cluster (a cluster of the smallest eigenvalues). Then (5.1) is replaced by (5.2), where ![]() is an estimate for the largest eigenvalue of G. Observe that the required estimate can be derived from the eigenvalues of the matrices
is an estimate for the largest eigenvalue of G. Observe that the required estimate can be derived from the eigenvalues of the matrices![]() .
.
A similar tactic is used for calculating a two-sides cluster. In this case the shift is computed by the rule
![]()
In other words, the shift estimates the average value of the largest and the smallest (algebraically) eigenvalues of G. A more sophisticated way to implement the above ideas is outlined below.
5.3. Polynomial Acceleration
Let the eigenvalues of G satisfy (2.1) and let the real numbers
![]()
define the monic polynomial
![]()
Then the eigenvalues of the matrix polynomial
![]()
are determined by the relations
![]()
Moreover, the matrices G and ![]() share the same eigenvectors: An eigenvector of G that corresponds to
share the same eigenvectors: An eigenvector of G that corresponds to ![]() is an eigenvector of
is an eigenvector of ![]() that corresponds to
that corresponds to![]() , and vice versa. In polynomial acceleration the basic scheme (3.3) is replaced with
, and vice versa. In polynomial acceleration the basic scheme (3.3) is replaced with
![]() (5.3)
(5.3)
The idea here is to choose the points ![]() in a way that enlarges the size of
in a way that enlarges the size of ![]() when
when ![]() belongs to the target cluster, and/or diminishes
belongs to the target cluster, and/or diminishes ![]() when
when ![]() is outside the target cluster.
is outside the target cluster.
As with orthogonal iterations, the use of Chebyshev polynomials enables effective implementation of this idea. In this method there is no need in the numbers![]() . Instead we have to supply the end points of the diminishing interval. Then the matrix-vector product
. Instead we have to supply the end points of the diminishing interval. Then the matrix-vector product ![]() is carried out by the Chebyshev recursion formula. See ([7] , p. 294) for details. In our iteration the end points of the diminishing interval can be derived from the current Ritz values (the eigenvalues of
is carried out by the Chebyshev recursion formula. See ([7] , p. 294) for details. In our iteration the end points of the diminishing interval can be derived from the current Ritz values (the eigenvalues of![]() ).
).
5.4. Inverse Iterations
This approach is possible only in certain cases, when G is invertible and the matrix-vector product ![]() can be computed in
can be computed in ![]() flops. In this case (3.3) is replaced with
flops. In this case (3.3) is replaced with
![]() (5.4)
(5.4)
In practice ![]() is almost never computed. Instead the linear system
is almost never computed. Instead the linear system ![]() is solved for
is solved for![]() . For this purpose we need an appropriate factorization of G.
. For this purpose we need an appropriate factorization of G.
The use of (5.4) is helpful for calculating small eigenvalues of a positive definite matrix. If other clusters are needed then ![]() should be replaced with
should be replaced with![]() , where
, where ![]() is a suitable shift. This is possible when the shifted system
is a suitable shift. This is possible when the shifted system ![]() is easily solved, as with band matrices.
is easily solved, as with band matrices.
6. Orthogonal Iterations
In this section we briefly examine the similarity and the difference between the new method and the Orthogonal Iterations method. The last method is also called Subspace Iterations and Simultaneous Iterations, e.g., [1] [4] [5] [7] -[10] [13] -[15] . It is aimed at computing a cluster of k dominant eigenvalues, as defined in (1.3). The simplest way to achieve this goal is, perhaps, to apply a “block” version of the Power method on an ![]() matrix. In this way the Power method is simultaneously applied on each column of the matrix. The Orthogonal Iterations method modifies this idea in a number of ways. First, as its name says, it orthogonalizes the iteration matrix, which keeps it a full rank well-conditioned matrix. Second, although we are interested in k eigenpairs, the iteration is applied on a larger matrix that has p columns, where
matrix. In this way the Power method is simultaneously applied on each column of the matrix. The Orthogonal Iterations method modifies this idea in a number of ways. First, as its name says, it orthogonalizes the iteration matrix, which keeps it a full rank well-conditioned matrix. Second, although we are interested in k eigenpairs, the iteration is applied on a larger matrix that has p columns, where![]() . This leads to faster convergence (see below). As before,
. This leads to faster convergence (see below). As before,
![]()
where ![]() is a small multiple of k. The qth iteration of the resulting method,
is a small multiple of k. The qth iteration of the resulting method, ![]() , is composed of the following three steps. It starts with a matrix
, is composed of the following three steps. It starts with a matrix ![]() that has orthonormal columns.
that has orthonormal columns.
Step 1: Compute the product matrix
![]()
Step 2: Compute the Rayleigh quotient matrix
![]()
and its k dominant eigenvalues
![]()
Step 3: Compute a matrix ![]() whose columns provide an orthonormal basis of
whose columns provide an orthonormal basis of![]() . This can be done by a QR factorization of
. This can be done by a QR factorization of![]() .
.
Let the eigenvalues of G satisfy (1.1). Then for ![]() the sequence
the sequence![]() , converges to zero at the same asymptotic rate as the sequence
, converges to zero at the same asymptotic rate as the sequence![]() . See, for example, ([4] , p. 157) or ([5] , p. 368). Therefore, the larger p is, the faster is the convergence. Moreover, let the spectral decomposition of
. See, for example, ([4] , p. 157) or ([5] , p. 368). Therefore, the larger p is, the faster is the convergence. Moreover, let the spectral decomposition of ![]() have the form
have the form
![]()
where
![]()
If at the end of Step 2 the matrix ![]() is replaced with
is replaced with ![]() then the columns of
then the columns of ![]() converge toward the corresponding eigenvectors of G. However, in exact arithmetic both versions generate the same sequence of Ritz values. Hence the retrieval of eigenvectors can wait to the final stage. The practical implementation of orthogonal iterations includes several further modifications, such as skipping Steps 2 - 3 and “locking”. For detailed discussions of these options, see [1] [7] -[10] .
converge toward the corresponding eigenvectors of G. However, in exact arithmetic both versions generate the same sequence of Ritz values. Hence the retrieval of eigenvectors can wait to the final stage. The practical implementation of orthogonal iterations includes several further modifications, such as skipping Steps 2 - 3 and “locking”. For detailed discussions of these options, see [1] [7] -[10] .
A comparison of the above orthogonal iteration with the new iteration shows that both methods need about the same amount of computer storage, but the new method doubles the computational effort per iteration. The adaptation of orthogonal iterations to handle other peripheral clusters requires the shift operation. Another difference regards the rate of convergence. In orthogonal iterations the rate is determined by the ratio![]() . The theory behind the new method is not that decisive, but our experiments suggest that it is quite faster.
. The theory behind the new method is not that decisive, but our experiments suggest that it is quite faster.
7. Restarted Lanczos Methods
The current presentation of the new method is carried out by applying the Krylov information matrix (3.2)-(3.4). This version can be viewed as a “Restarted Krylov method”. The Restarted Lanczos method is a sophisticated implementation of this approach that harnesses the Lanczos algorithm to reduce the computational effort per iteration. As before, the method is aimed at computing a cluster of ![]() exterior eigenpairs, new information is gained from an
exterior eigenpairs, new information is gained from an ![]() -dimensional Krylov subspace, and
-dimensional Krylov subspace, and
![]()
The qth iteration, ![]() , of the Implicitly Restarted Lanczos method (IRLM) is composed of the following four steps. It starts with a tridiagonal matrix,
, of the Implicitly Restarted Lanczos method (IRLM) is composed of the following four steps. It starts with a tridiagonal matrix, ![]() , and the related matrix of Lanczos vectors,
, and the related matrix of Lanczos vectors,
![]()
which have been obtained by applying ![]() steps of Lanczos method on G.
steps of Lanczos method on G.
Step 1: Compute the eigenvalues of![]() . Let
. Let
![]()
denote the computed eigenvalues, where the first ![]() eigenvalues correspond to the target cluster.
eigenvalues correspond to the target cluster.
Step 2: Compute a ![]() matrix with orthonormal columns,
matrix with orthonormal columns,
![]()
such that ![]() equals an invariant subspace of
equals an invariant subspace of ![]() which corresponds to
which corresponds to ![]() The computation of
The computation of ![]() is carried out by conducting a QR factorization of the product matrix
is carried out by conducting a QR factorization of the product matrix
![]()
Step 3: The above QR factorization is used to build a new ![]() tridiagonal matrix,
tridiagonal matrix, ![]() , and the matrix
, and the matrix
![]()
This pair of matrices has the property that it can be obtained by applying ![]() steps of Lanczos algorithm on
steps of Lanczos algorithm on![]() , starting from some (unknown) vector.
, starting from some (unknown) vector.
Step 4: Continue ![]() additional steps of Lanczos algorithm to obtain
additional steps of Lanczos algorithm to obtain ![]() and
and![]() .
.
The IRLM iterations are due to Sorensen [11] . The name “Implicitly restarted” refers to the fact that the starting vector (which initiates the restarted Lanczos process) is not computed. For detailed description of this iteration, see ( [1] , pp. 67-73), and [11] . See also [13] [15] .
A different implementation of the Restarted Lanczos idea, the Thick-Restarted Lanczos (TRLan) method, was proposed by Wu and Simon [17] . The qth iteration, ![]() , of this method is composed of the following five steps, starting with
, of this method is composed of the following five steps, starting with ![]() and
and ![]() as above.
as above.
Step 1: Compute ![]() eigenpairs of
eigenpairs of ![]() which correspond to the target cluster. The corresponding
which correspond to the target cluster. The corresponding ![]() eigenvectors of
eigenvectors of ![]() are assembled into a matrix
are assembled into a matrix
![]()
which is used to compute the related matrix of Ritz vectors,
![]()
Step 2: Let![]() , and
, and ![]() denote the computed Ritz pairs. The algorithm uses these pairs to compute a vector
denote the computed Ritz pairs. The algorithm uses these pairs to compute a vector ![]() and scalars,
and scalars, ![]() , that satisfy the equalities
, that satisfy the equalities
![]()
and
![]()
Step 3: The vector ![]() is used to initiate a new sequence of Lanczos vectors. The second vector,
is used to initiate a new sequence of Lanczos vectors. The second vector, ![]() , is obtained by orthogonalizing the vector
, is obtained by orthogonalizing the vector ![]() against
against ![]() and the columns of
and the columns of![]() .
.
Step 4: Continue ![]() additional steps of the Lanczos process that generate
additional steps of the Lanczos process that generate![]() . At the end of this process we obtain an
. At the end of this process we obtain an ![]() matrix
matrix
![]()
that has mutually orthonormal columns and satisfy
![]()
where ![]() is nearly tridiagonal: The
is nearly tridiagonal: The ![]() principal submatrix of
principal submatrix of ![]() has an “arrow-head” shape,
has an “arrow-head” shape,
with![]() , on the diagonal, and
, on the diagonal, and![]() , on the sides.
, on the sides.
Step 5: Use a sequence of Givens rotations to complete the reduction of ![]() into a
into a ![]() tridiagonal matrix
tridiagonal matrix![]() . Similarly
. Similarly ![]() is updated to give
is updated to give![]() .
.
For detailed description of the above iteration see [17] [18] . Both IRLM and TRLan are carried out with reorthogonalization of the Lanczos vectors. The TRLan method computes the Ritz vectors while IRLM avoids this computation. Yet the two methods are known to be mathematically equivalent.
One difference between the new method and the Restarted Lanczos approach lies in the computation of the Rayleigh quotient matrix. In our method this computation requires additional ![]() matrix-vector products, which doubles the computational effort per iteration.
matrix-vector products, which doubles the computational effort per iteration.
A second difference lies in the starting vector of the ![]() dimensional Krylov subspace that is newly generated at each iteration. In our method this vector is defined by (3.4). In TRLan this vector is
dimensional Krylov subspace that is newly generated at each iteration. In our method this vector is defined by (3.4). In TRLan this vector is![]() . Yet it is difficult to reckon how this difference effects the rate of convergence.
. Yet it is difficult to reckon how this difference effects the rate of convergence.
A third difference arises when using acceleration techniques. Let us consider for example the use of power acceleration with ![]() replacing
replacing![]() . In this case the Restarted Lanczos methods compute a tridiagonal reduction of
. In this case the Restarted Lanczos methods compute a tridiagonal reduction of![]() , and Ritz values of
, and Ritz values of![]() , while our method computes Ritz eigenpairs of
, while our method computes Ritz eigenpairs of![]() . (Power acceleration allows us to use smaller
. (Power acceleration allows us to use smaller ![]() and reduces the portion of time that is spent on the Rayleigh-Ritz procedure. See the next section.) A similar remark applies to the use of Polynomial acceleration.
and reduces the portion of time that is spent on the Rayleigh-Ritz procedure. See the next section.) A similar remark applies to the use of Polynomial acceleration.
The new method can be viewed as generalization of the Restarted Lanczos approach. The generalization is carried out by replacing the Lanczos process with standard orthogonalization. This simplifies the algorithm and clarifies the main reasons that lead to fast rate of convergence. One reason is that each iteration builds a new Krylov subspace, using an improved starting vector. A second reason comes from the orthogonality requirement: The new Krylov subspace is orthogonalized against the current Ritz vectors. It is this orthogonalization that ensures successive improvement. (The Restarted Lanczos algorithms achieve these tasks in implicit ways.)
8. Numerical Experiments
In this section we describe some experiments that illustrate the behavior of the proposed method. The test matrices have the form
![]() (8.1)
(8.1)
where ![]() is a random orthonormal matrix,
is a random orthonormal matrix, ![]() , and
, and ![]() is a diagonal matrix,
is a diagonal matrix,
![]() (8.2)
(8.2)
The term “random orthonormal” means that ![]() is obtained by orthonormalizing the columns of a random matrix,
is obtained by orthonormalizing the columns of a random matrix, ![]() , whose entries are random numbers from the interval
, whose entries are random numbers from the interval![]() . The random numbers generator is of uniform distribution. All the experiments were carried out with
. The random numbers generator is of uniform distribution. All the experiments were carried out with ![]() and
and![]() . The values of
. The values of ![]() are specified in the coming tables. (The diagonal entries of
are specified in the coming tables. (The diagonal entries of ![]() are the eigenvalues of
are the eigenvalues of![]() . Hence the structure of
. Hence the structure of ![]() is the major factor that effects convergence. Other factors, like the size of the matrix or the sparsity pattern, have minor effects.) The computations were carried out with MATLAB. We have used the following four types of test matrices:
is the major factor that effects convergence. Other factors, like the size of the matrix or the sparsity pattern, have minor effects.) The computations were carried out with MATLAB. We have used the following four types of test matrices:
Type A matrices, where
![]() (8.3)
(8.3)
Type B matrices, where
![]() (8.4)
(8.4)
Type C matrices, where
![]() (8.5)
(8.5)
Type D matrices, where
![]() (8.6a)
(8.6a)
and
![]() (8.6b)
(8.6b)
The difference between the computed Ritz values and the desired eigenvalues of ![]() is computed as follows. Let
is computed as follows. Let ![]() denote the
denote the ![]() eigenvalues of
eigenvalues of ![]() which constitute the desired cluster. Let
which constitute the desired cluster. Let![]() , denote the corresponding Ritz values which are computed at the qth iteration,
, denote the corresponding Ritz values which are computed at the qth iteration,![]() . Then the average difference between the corresponding eigenvalues is
. Then the average difference between the corresponding eigenvalues is
![]() (8.7)
(8.7)
The figures in Tables 1-4 provide the values of![]() . They illustrate the way
. They illustrate the way ![]() converges to zero as
converges to zero as ![]() increases.
increases.
The new method is implemented as described in Section 3. It starts by orthonormalizing a random Krylov matrix of the form (3.1). The information matrix, ![]() , is defined by (3.2)-(3.4). The Orthogonal iterations method is implemented as in Section 6. It starts from a random orthonormal matrix, which is a common default option, e.g., ([1] , p. 55) and ( [13] , p. 60).
, is defined by (3.2)-(3.4). The Orthogonal iterations method is implemented as in Section 6. It starts from a random orthonormal matrix, which is a common default option, e.g., ([1] , p. 55) and ( [13] , p. 60).
![]()
Table 1. Computing a dominant cluster with the new iteration.
![]()
Table 2. Computing a dominant cluster with orthogonal iterations.
![]()
Table 3. Computing a left-side cluster with the new iteration.
![]()
Table 4. The use of Power acceleration to compute a dominant cluster of Type A matrix.
Table 1 describes the computation of dominant clusters with the new method. The reading of this table is simple: We see, for example, that after performing 6 iterations on a Type B matrix, ![]() for
for![]() , and
, and ![]() for
for![]() . (The corresponding values of
. (The corresponding values of ![]() are
are ![]() and
and![]() , respectively.) Table 2 describes the computation of the same dominant clusters with orthogonal iterations. A comparison of the two tables suggests that the new method is considerably faster than Orthogonal iterations.
, respectively.) Table 2 describes the computation of the same dominant clusters with orthogonal iterations. A comparison of the two tables suggests that the new method is considerably faster than Orthogonal iterations.
Another observation stems from the first rows of these tables: We see that a random Krylov matrix gives a better start than a random starting matrix.
The ability of the new method to compute a left-side cluster is illustrated in Table 3. Note that the Type B matrix and the Type C matrix are positive semidefinite matrices, in which the left-side cluster is composed from the smaller non-zero eigenvalues of![]() . Both matrices have several zero eigenvalues. In the Type B matrix the eigenvalues in the left-side cluster are much smaller than the dominant eigenvalues, but the new method is able to distinguish these eigenvalues from zero eigenvalues.
. Both matrices have several zero eigenvalues. In the Type B matrix the eigenvalues in the left-side cluster are much smaller than the dominant eigenvalues, but the new method is able to distinguish these eigenvalues from zero eigenvalues.
The merits of Power acceleration are demonstrated in Table 4. On one hand it enables us to use a smaller![]() , which saves storage. On the other hand it reduces the portion of time that is spent on orthogonalizations and the Rayleigh-Ritz process.
, which saves storage. On the other hand it reduces the portion of time that is spent on orthogonalizations and the Rayleigh-Ritz process.
9. Concluding Remarks
The new method is based on a modified interlacing theorem which forces the Rayleigh-Ritz approximations to move monotonically toward their limits. The current presentation concentrates on the Krylov information matrix (3.2)-(3.4), but the method can use other information matrices. The experiments that we have done are quite encouraging, especially when calculating peripheral clusters. The theory suggests that the method can be extended to calculate certain non-peripheral clusters, but in this case we face some difficulties due to rounding errors. Further modifications of the new method are considered in [3] .