Functionally Incremental Sentence Processing and Reanalysis Difficulty in Head-Final Agglutinative Language ()
1. Introduction: Garden-Path and Reanalysis Cost
Many researchers have been interested in the fact that the usually very fast and efficient human sentence processing breaks down in some sentences. Garden-path sentences are among the sentences where the breakdown occurs, one of which is (1) by Bever (1970) .
(1) The horse raced past the barn fell.
The reason for the breakdown in (1) is generally understood to be the reanalysis required in the latter half of the sentence. It is not the case, however, that all reanalyses cause processing breakdown. The syntactic structure of (2) is the same with (1) and a reanalysis is assumed after found. However, the reanalysis in (2) is processable and the severe processing difficulty is absent.
(2) The bird found in the room died. ( Pritchett, 1988 )
The cognitively well-designed sentence processing model thus should predict the presence or the absence of breakdown for a reanalysis, and garden-path has served as a test for the empirical validity of the processing model. Many researchers have proposed sentence processing models and have discussed the syntactic environment to properly characterize the reanalyses with heavy load causing breakdown ( Pritchett, 1988, 1992 ; Gibson, 1991 ; Weinberg, 1993 ; Gorrell, 1995 ; Sturt & Crocker, 1996 ; Fodor & Inoue, 1998 ; Lewis, 1998 ). Here a reanalysis is categorized to be processable or unprocessable. It was already known in the early studies on garden- path, however, that some garden-path sentences were more costly than others ( Frazier & Rayner, 1982 ; Abney, 1989 ). For garden-path sentences in (3), for example, Fodor and Ferreira (1998) judge (3a) to be “easy to recover” while (3b) is “extremely difficult to recover”.
(3) a. Sandra bumped into the busboy and the waiter told her to be carefully.
b. The daughter of the king’s son admires himself.
Currently, it is widely known that the processing cost in garden-path sentences is graded, and the difference of reanalysis cost is often attributed to non-syntactic factors, namely, length of locally ambiguous string, semantic naturalness and frequency in use of words, etc. We can find few researches that explain the degree of reanalysis cost by syntactic constraints. It is not the case, however, that the syntactic property of reanalysis is irrelevant to processing cost. Sturt, Pickering and Crocker (1999) performed a self-paced reading experiment for sentences as in (4), where non-syntactic factors were strictly controlled, and they demonstrated that the reanalysis assumed at had is more costly in (4b) than that in (4a).
(4) a. The Australian woman saw the famous doctor had been drinking quite a lot.
b. Before the woman visited the famous doctor had been drinking quite a lot.
The famous doctor in (4) is reanalyzed from the main object to the subordinate subject in (4a) and from the subordinate object to the main subject in (4b). Sturt et al. (1999) thus claimed that the type of structural change was an important determinant of reanalysis cost.
2. Reanalysis in Japanese Sentence and Factors Relevant to Its Difficulty
Mazuka and Itoh (1995) was one of the earliest studies that pointed out the processing breakdown in some Japanese relative clause structures, as in (5).
(5) Yooko-ga kodomo-o [S koosaten-de mikaketa] takusii-ni noseta.
name-nom child-accintersection-loc found taxi-datput in
“Yooko put a child in the taxi she had found at the intersection”.
When we assume that input string is incrementally processed at least to some extent, the most dominant interpretation at mikaketa (found) will be the clause with Yooko and kodomo (child) as the subject and the object of mikaketa respectively, as in (6).
(6) [SYooko-ga kodomo-o koosaten-de mikaketa]
“Yooko found a child at an intersection”.
However, Yooko and kodomo in (5) must be interpreted as the subject and the object of noseta (put in). A reanalysis is thus assumed after mikaketa, and the great processing cost in (5) is understood to be due to this reanalysis. Mazuka and Itoh (1995) also pointed out that not all reanalyses in Japanese relative clauses caused processing breakdown. (7) is much easier to process than (5) in spite of their similar syntactic structures.
(7) Yooko-ga[S kodomo-o koosaten-de mikaketa] onnanoko-ni koe-o kaketa.
name-nom child-acc intersection-Loc found girl-datcalled
“Yooko called the girl who had found a child at the intersection”.
The difference of processing cost between (5) and (7) is generally attributed to the different syntactic properties of the reanalyses in them. That is, while the reanalysis in (5) involves the subject Yooko-ga and the object kodomo-o, the one in (7) involves only the subject. Mazuka and Itoh (1995) claimed that the reanalysis cost rose as more elements were involved in a reanalysis. A sentence where a reanalysis of relative subject and object is assumed as in (5) is generally called “subject-object reanalysis sentence” (SOR), and a sentence only with a reanalysis of relative subject as in (7) “subject reanalysis sentence” (SR).1
We should note that the reanalyses in the examples of Mazuka and Itoh (1995) can be confounded with non- syntactic factors. Hirose and Inoue (1998) and Hirose (2002) demonstrated experimentally that the thematic ambiguity of the head noun of a relative clause raised the reanalysis cost. The head noun bengoshi (lawyer) in (8a,c) is locally thematically ambiguous between THEME or AGENT of sagashidashita (found), and this ambiguity cannot be resolved until the end of the sentence. The head noun kashikinko (rental safe) in (8b), on the other hand, functions as THEME unambiguously.
(8) a. Yamaoka-ga kakushiisan-o [S anotekonotede sagashidashita] mogurino bengoshi-ni
name-nom hidden fortune-acc after great effort discovered unlicensed lawyer-dat
yamunaku azuketa.
unwillingly entrusted
“Yamaoka unwillingly entrusted his/her hidden fortune to the unlicensed lawyer whom he/she
had discovered after great effort”.
b. Yamaoka-ga kakushiisan-o [S anotekonotede sagashidashita] mogurino kashikinko-ni
name-nom hidden fortune-acc after great effort discovered unlicensed rental safe-dat
yamunaku azuketa.
unwillingly entrusted
“Yamaoka unwillingly entrusted his/her hidden fortune to the unlicensed rental safe that
he/she had discovered after great effort”.
c. Yamaoka-ga [S kakushiisan-o anotekonotede sagashidashita] mogurino bengoshi-ni
name-nom hidden fortune-acc after great effort discovered unlicensed lawyer-dat
yamunaku ayamatta.
unwillingly apologized
“Yamaoka unwillingly apologized to the unlicensed lawyer who had discovered his/her
hidden fortune after great effort”.
Hirose and Inoue (1998) observed shorter reading time (RT) in (8b) than in (8a,c). Since (8a,b) is an example of SOR and (8c) are of SR, the thematic ambiguity of head noun can overcome the effect assumed for syntactic difference of reanalysis. This thematic ambiguity of head noun is true of SR and SOR of Mazuka and Itoh (1995) . That is, takushii in (5) and onnanoko-ni (girl-dat) in (7) are locally ambiguous between THEME and AGENT of mikaketa (found) (metaphorically for takushii).
Hirose (2003) claimed that two successive sentence-initial accented phrases constructed a prosodically major phrase in Japanese, and that its boundaries could ease or hinder reanalysis. Yuujintachi (friends) in (9) is locally ambiguous between the subject and the object of shiNyooshita (trusted). Relevant accent positions are represent- ed here by apostrophes and the prosodic boundaries by curly brackets.
(9) a. {Mori’shita-ga [S shi’Nyaku-o}{kokorokara shiNyooshita] yuujintachi-ni shohoosen-o
name-nom new medicine-acc truly trusted friends-datprescription-acc
okutta.
sent
“Morishita sent the prescription to the friends who truly trusted the new medicine”.
b. {Hoso’kawa-to Mori’shita-ga} [S {shi’Nyaku-o kokorokara shiNyooshita] yuujintachi-ni
name-and name-nom new medicine-acctruly trusted friends-dat
shohoosen-o okutta.
prescription-acc sent
“Hosokawa and Morishita sent the prescription to the friends who truly trusted the new
Medicine”.
The local ambiguity of yuujintachi will be resolved at shohoosen-o (prescription-acc) as the relative subject since no Japanese predicate can take two o-marked NPs as its arguments. In the self-paced reading experiment for (9), the RT at shohoosen-o was shorter in (9b) than in (9a). Hirose (2003) claimed that this was because the prosodic major and the clausal boundaries coincided in (9b) while they did not in (9a). This prosodic factor was not controlled in Mazuka and Itoh (1995) .
As for the comparison of SR and SOR, Miyamoto (2002) performed RT experiments and claimed that SOR was more costly than SR. It cannot be said, however, that his stimulus sentences were well-controlled syntactically and semantically. One of the main flaws of the sentences of Miyamoto (2002) is the thematic ambiguity of head noun. All the head nouns in his SR are locally thematically ambiguous between THEME and AGENT. The difference of processing costs between SR and SOR is thus still to be examined exactly with thematically unambiguous head nouns.
Mazuka and Itoh (1995) also discussed (10), where a reanalysis is assumed in (10a).
(10) a. Nakamura-ga [PP[S chuuko-no pasokon-o katta] toki] shuuri-shite-kureta.
name-nom second-hand-Gen personal computer-acc bought when repaired gave (to me)
“Nakamura, when I bought a second-hand personal computer, repaired it for me”.
b. [PP[S Nakamura-ga chuuko-no pasokon-o katta] toki]
name-nom second-hand-Gen personal computer-acc bought when
shuuri-shite-yatta.
repaired gave (to the third person)
“When Nakamura bought a second-hand personal computer, I repaired it for him/her”.
Kureru (the root form of kureta) and yaru/ageru (the roots of yatta/ageta) behave as subsidiary verbs to mean the receiving and the giving of benefit respectively.2 The receiver of benefit is the speaker in (10a) and Nakamura in (10b).3 The benefactor is the main subject (Nakamura) in (10a) and the speaker in (10b). At the input of toki (when), the subject of katta (bought) will be interpreted as Nakamura as in (11).
(11) [PP[S Nakamura-ga chuuko-no pasokon-o katta] toki].
“When Nakamura bought a second-hand personal computer”
The subject of katta thus will be reanalyzed from Nakamura to the speaker in (10a). In (10b), on the other hand, since the main subject is the speaker, the dependency relation in (11) is maintained and the reanalysis in (10a) is unnecessary. (10a) is thus expected to be more costly than (10b) since a reanalysis is assumed only for the former. Mazuka and Itoh (1995) , however, observed no conscious difference of processing difficulty between them. We should note here for (10) that shuuri-suru (repair) is a two-place verb and its object (secondhand personal computer) is phonetically null. Japanese arguments can be phonetically null when the referents can be specified by the context. However, since anaphoric processing will be involved in sentences with phonetically null arguments as a confounding factor, the difference of processing costs due to the presence and the absence of reanalysis in (10) should be examined in sentences with phonetically overt main objects. Further, the cost difference of Mazuka and Itoh (1995) for (10) is by intuition, and thus it should be quantitatively measured for the comparison with other constructions.
3. Functionally Incremental Processing in Japanese
English noun phrases do not inflect except genitive case, and thus it is difficult to determine their grammatical functions by their phonetic forms. In the standard derivational theory of syntax, subject and object are defined as NPs (DPs) immediately dominated by S (IP) and by VP respectively ( Chomsky, 1981, 1986, 1995 ). Japanese noun phrases, on the other hand, are case-marked most of the time, and we can find close correspondences between case-markings and grammatical functions. That is, a ga-marked noun phrase behaves as a subject as in (12a) or an object of potential predicate as in (12b).
(12) Grammatical function of ga-marked noun phrase
a. Subject
Otokonoko-ga aruite-iru.
boy-nom walking
“A boy is walking”.
b. Object of potential predicate
Kenji-ga sakadachi-ga dekiru.
name-nom handstand-nom can do
“Kenji can do a handstand”.4
An o-marked noun phrase functions as accusative object as in (13), and a ni-marked noun phrase as dative object, adverbial argument or adjunct of time and place, or subordinate subject of potential predicate as in (14) respectively.
(13) Grammatical function of o-marked noun phrase
Accusative object
Otokonoko-ga batto-o huru.
boy-nom bat-acc swing
“A boy swings a bat”.
(14) Grammatical function of ni-marked noun phrase
a. Dative object
Haha-ga inu-ni esa-o ageru.
mother-nom dog-dat food-acc gives
“My mother gives food to a dog”.
b. Adverbial argument
Haha-ga teeburu-ni kabin-o oku.
mother-nom table-dat vase-acc puts
“My mother puts a vase on the table”.
c. Adverbial adjunct
Chichi-wa shiNya-ni kitaku-suru.
father-top midnight-dat get back does
“My father gets back in the midnight”.
d. Subordinate subject of potential predicate
Chichi-ni kinshu-wa dekinai-to haha-wa omotteiru.
father-dat abstention from drink-top cannot do-Comp mother-top thinks
“My mother thinks that our father cannot abstain from drinking”.5
The grammatical function of a noun phrase can thus be predicted fairly accurately by its case-marking without the reference to the phrase structure. In fact, recent studies suggest that dependency relations in a Japanese sentence can be partially built before the input of a verb as the head of the sentence ( Kamide & Mitchell, 1999 ; Kamide, Altmann, & Haywood, 2003 ; Yamashita, 2000 ; Aoshima, Phillips, & Weinberg, 2004 ; Tokimoto, 2005 ). We here propose (15) as general constraints on Japanese sentence processing.
(15) a. Functional incrementality
The grammatical function of input is determined as incrementally as possible.
b. Monotonicity
Processing results are accumulated monotonically.
Then we estimate the degree of reanalysis cost by (16).
(16) Additivity of constraint violation
The cost of a reanalysis rises monotonically as a function of the number of the monotonicity
violations.
We will discuss the processes of relevant Japanese sentences with reanalyses below on the hypotheses in (15) and (16). (17) is one of our examples of SR.
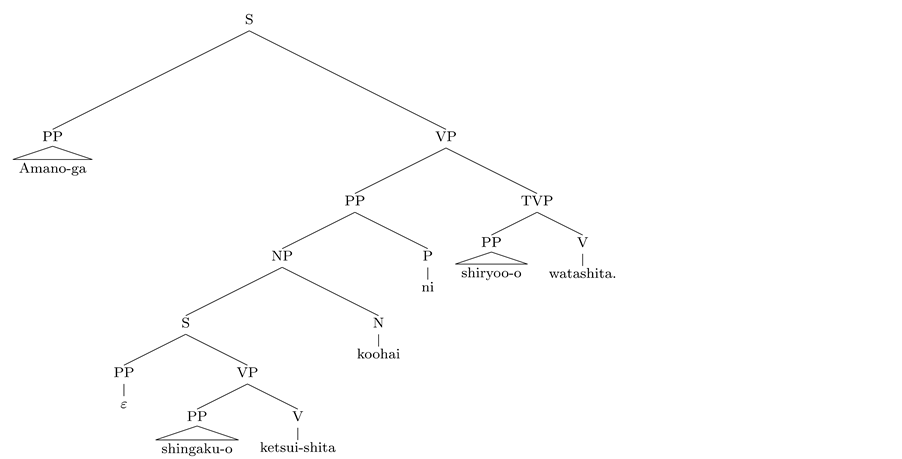
(17) SR
Amano-ga [S shingaku-o ketsui-shita] koohai-ni shiryoo-o
name-nom advance to an upper school-acc decided junior-dat reference materials-acc
watashita.
handed
“Amano handed the reference materials to the junior who had decided to go on to an upper
school”.
As we discussed above, the sentence-initial string in (18a) can be a subject or an object of potential predicate. Here we represent these interpretations by feature structures of Japanese Phrase Structure Grammar as in (18b,c) ( Gunji, 1987, 1995 ; Gunji & Hashida, 1998 ).
(18) a. Amano-ga...
name-nom
b. Feature structure for subject interpretation

MORPH: morphophonemic form; POS: part of speech; DEP: dependency relation;
SEM: semantic representation; SBJROLE: subject (thematic) role; primed words
(e.g., Amano’) represent semantic content
c. Feature structure for interpretation of object of potential predicate
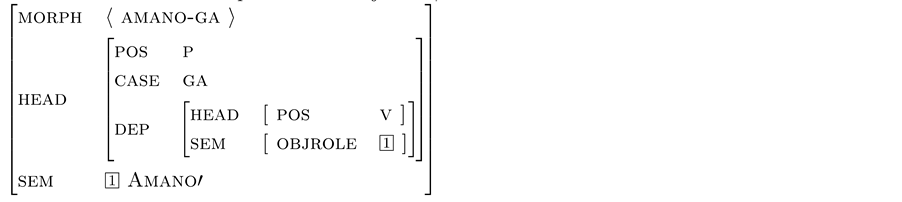
OBJROLE: object (thematic) role
We represent the functional ambiguity of (18b,c) as (19a), and abbreviate it as in (19b).
(19) a. Amano-ga
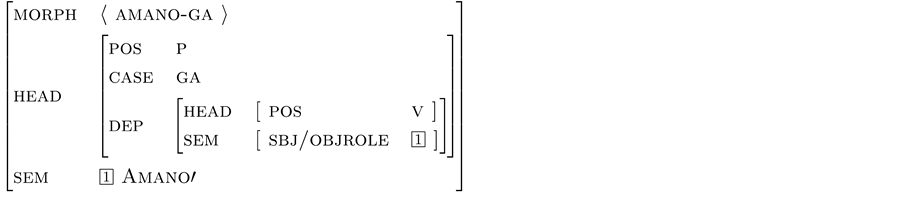
b. p[sbj/obj, ga]:Amano’
The feature structure of shingaku-o (advance to an upper school-acc) is (20).
(20) p[obj, o]:shingaku’
The feature structure of ketsui-shita (decided) is (21a), and we abbreviate it as (21b).
(21) a. ketsui-shita

SUBCAT: subcategorization; GR: grammatical function; SBJ: subject; OBJ: object
b. v[subcat {p[ sbj, ga]:1, p[ obj, o]: 2}]:ketsui-shita’(1, 2)
The feature structures (19), (20) and (21) for the string (22a) can be unified since the subcat value of (21) matches (19) and (20). The unified feature structure is (22b).
(22) a. Amano-ga shingaku-o ketsui-shita
b. v[subcat {}]:ketsui-shita’(Amano’, shingaku’)
When koohai-ni (junior-dat) follows the preceding input as in (23a), the feature structure for koohai-ni can be represented as in (23b). Since koohai does not refer time or place to behave as an adverbial argument or adjunct, its potential function should be subject or object.
(23) a. Amano-ga shingaku-o ketsui-shitakoohai-ni...
b. koohai-ni
p[sbj/obj, ni]:koohai’
As the SUBCAT feature value in (21) indicates, ketsui-shita subcategorizes two postpositional phrases with their heads as ga and o, and these values are appropriately given by Amano-ga and shingaku-o. Since koohai cannot behave as an adverbial adjunct of ketsui-shita, part of (22) must be revised to incorporate the phrase with the present dependency relation. The revision with the least serious violation of monotonicity is to replace the first argument (1) of ketsui-shita’ in (22) from Amano’ to koohai’. The clausal structure here is (24a), and its feature structure is (24b).
(24) a. Amano-ga
[Sε shingaku-o ketsui-shita]koohai-ni...
b. i. Amano-ga
p[sbj/obj, ga]:Amano’
ii. shingaku-o ketsui-shita koohai-ni (to the junior who decided to go to an upper school)

The final dependency relations of our SR (17) is (25).
(25)
In an example of SOR in (26a), on the other hand, the feature structure of hiyashita (chilled) is (26b), and the structure constructed at this verb is (26c).
(26) a. SOR
Yamada-ga miruku-o [S hiyashita] koohii-ni sukoshi kuwaeta.
name-nom milk-acc chilled coffee-dat a little added
“Yamada added milk a little to the coffee he had chilled”.
b. v[subcat {p[sbj, ga]:1, p[obj, o]: 2}]:hiyashita’(1, 2)
c. v[subcat {}]:hiyashita’(Yamada’, miruku’)
The presence of a complex NP is recognized at the input of koohii-ni (coffee-dat). Koohii cannot be the subject of hiyashita, and its adverbial adjunct interpretation is semantically anomalous, as in (27).
(27) *Yamada-ga miruku-o koohii-de hiyashita.
name-nom milk-acc coffee-in/with chilled
“*Yamada chilled milk in/with coffee”.
Koohii thus must behave as the object of hiyashita to build up a dependency relation with the verb. The reanalysis of the second argument of hiyashita’ in (26c) as koohii’ is required, and this reanalysis necessitates another reanalysis of the first argument Yamada’. This is because Yamada-ga and hiyashita cannot have a direct dependency relation with each other since miruku-o (milk-acc) intervenes between them. The clausal structure for the string (28a) is (28b) and its feature structure is (28c).
(28) a. Yamada-ga miruku-o hiyashita koohii-ni...
b. Yamada-ga miruku-o [S ε ε hiyashita]koohii-ni...
c. p[sbj/obj, ga]:Yamada’
p[obj, o]:miruku’
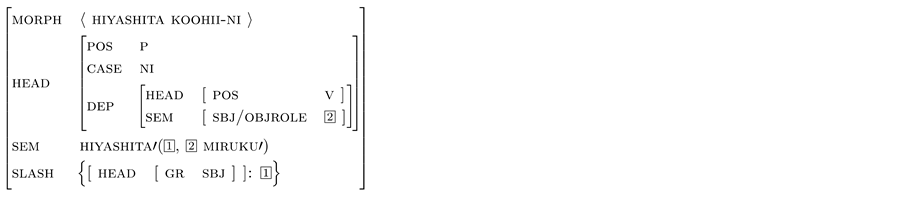
SLASH: missing constituent (gap)
The two arguments (1,2) of hiyashita’ are thus revised at koohii-ni. The dependency relations in (26a) is (29).
(29)

In (29), the subject of hiyashita is left unspecified, and Yamada and the speaker are available as the possible referents. The difference of reanalysis cost between SR of (17) and SOR of (26a) can be attributed to the difference of the number of arguments revised, that is, one (1) in the former and two (1, 2) in the latter.
The processing of (30) (hereafter Kureru and Ageru) corresponding to (10) with phonetically overt main objects is predicted as follows. When we assume the feature structure of toki (time) as a conjunction in (31a), the structure at the input of toki is (31b).
(30) a. Kureru
Gotoo-ga yooji-o daiteita-tok inimotsu-o motte-kureta.
name-nom baby-acc was holding when baggage-acc carrying gave to me
“Gotoo, when I was holding a baby, carried the baggage for me”.
b. Ageru
Gotoo-ga yooji-o daiteita-toki nimotsu-o motte-ageta.
name-nom baby-acc was holding when baggage-acc carrying gave to him/her
“When Gotoo was holding a baby, I carried the baggage for him/her”.
(31) a. toki (when)

b. Gotoo-ga yooji-o daiteita-toki (When Gotoo was holding a baby)
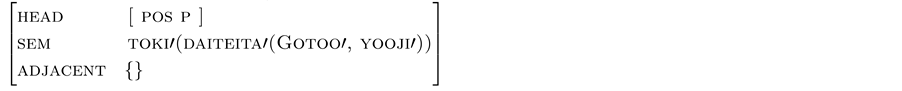
The feature structures of nimotsu-o (baggage-acc) and motte (carrying) are (32a,b) respectively. Since these two can be unified, the feature structure of nimotsu-o motte is (32c).
(32) a. nimotsu-o (baggage-acc)
p[obj, o]:nimotsu’
b. motte (carrying)

MOD: modifier
c. mimotsu-o motte (carrying the baggage)

The value of the first argument of motte’ is not fixed in (32c). Gotoo given by the context will be adopted as the first candidate, and the speaker is also available as the second. The feature structure is (33).
(33) (Gotoo-ga) nimotsu-o motte
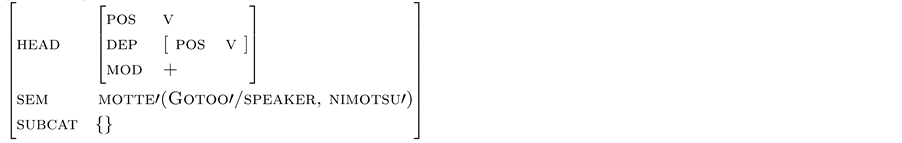
When we represent the semantic relation for the giving and the receiving benefit as affected ( Gunji, 1994 ), the feature structure of kureta as subsidiary verb is (34).
(34) kureta

Kureta behaves as a prosodic phrase (bunsetsu), but its adjacent feature specifies that it must be adjacent to a verb subcategorizing p[obj, o]. This constraint can be recognized in (35).
(35) a. Gotoo-ga nimotsu-o motte-kureta.
Gotoo-nom baggage-acc carrying gave to me
“Gotoo carried the baggage for me”.
b. nimotsu-o Gotoo-ga motte-kureta.
baggage-acc Gotoo-nom carrying gave to me
c. *Gotoo-ga motte nimotsu-o kureta.
Gotoo-nom carrying baggage-acc gave to me
The structures of (33) and (34) cannot be unified since SUBCAT value in the former is empty while the value for the latter is specified as {p[sbj, ga]:1}.The dependency relation between nimotsu-o and motte thus must be cancelled temporarily, and motte must reconstruct a dependency with kureta. The feature structure of motte-ku- reta is (36).
(36) motte-kureta

The feature structure in (37) is then constructed for the string “(Gotoo/speaker-ga) nimotsu-o motte-kureta”.
(37)
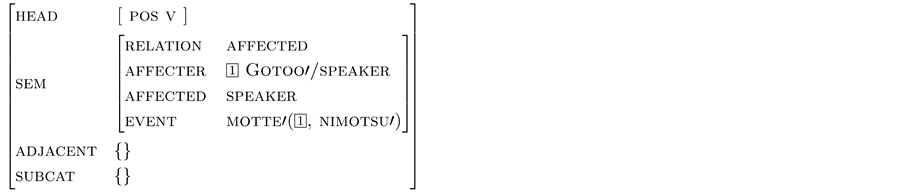
Let us note here that the second argument of motte’ is temporarily unspecified at (36) in the reanalysis from (33) to (37). The dependency relations of (30) is represented in (38). The main subject should be Gotoo since the value of affected is specified as the speaker, and the speaker cannot be chosen as affecter.
(38)
![]()
The dependency relations in (38) are syntactically well-formed, but the situation described by the sentence is pragmatically unnatural. That is, since toki indicates the simultaneity of the events in a main and the subordinate clauses, the situation described by (38) is that Gotoo, who was holding a baby, carried the baggage for the speaker. The pragmatically more natural interpretation should be that ‘when the speaker (I) was holding a baby, Gotoo carried the baggage for the speaker (me).’ This interpretation is possible because Japanese subjects referring to the speaker can be phonetically null. The dependency relations for this interpretation is (39).
(39)
![]()
In this reanalysis, the first argument of DAITEITTA’ in (31b) must be revised from Gotoo’ to the speaker.
The thematic reanalyses at kureta thus involve the first argument of DAITEITA’ and the temporary second of MOTTE’.6 For (30b), the feature structure of ageta is (40).
(40) ageta
![]()
The feature structures of (40) and (33) cannot be unified for the same reason with kureta. That is, when ageta is adjacent to a transitive verb, the verb must subcategorize p[obj, o]. The value of the second argument of motte’ is already fixed as nimotsu’ in (33), and thus it must be reanalyzed to be temporarily unspecified in the same way with kureta. The dependency relations in (30b) are (41).
(41)
![]()
Gotoo and the speaker are available as the main subject at motte, and the latter is chosen at ageta since affecter is specified as the speaker.7 The violations of monotonicity in the four types of sentence above are summarized in (42).
(42) a. SR: One violation at the head noun.
b. SOR: Two violations at the head noun.
c. Kureru: Two violations at kureru, one of which is temporary.
d. Ageru: One violation at ageru, which is temporary.
When we assume that the processing cost of the temporary violation is smaller than that of the unrecovered, the reanalysis costs in the four constructions are predicted as in (43).
(43) Ageru < SR < Kureru < SOR
We will examine this prediction experimentally in the following sections.
4. Experiment 1
4.1. Method
4.1.1. Participants
Forty-two undergraduate students in Tokyo area of Japan participated in the study for payment. They were Japanese native speakers.
4.1.2. Materials
The experimental sentences were Japanese complex sentences of six phrases. The four types of sentence discussed above were examined as experimental sentence types, namely, SR, SOR, Kureru and Ageru. Further, since a complex NP can intrinsically entail some extra processing cost, two other sentence types in (44) including complex NP structures for which no reanalysis was assumed were examined as the baselines to accurately estimate the reanalysis costs in SR and SOR. The presence and the absence of accent in the first and the second phrases are represented by apostrophes.
(44) a. Sentence with a relative clause in which no reanalysis is assumed (NR-Rel)
[S Ho’shino-ga tokei-o katta] depaato-ni Katoo-ga tsutometeita.
name-nom clock-acc bought department store-dat name-nom was working
“Katoo was working at the department store where Hoshino had bought a clock”.
b. Sentence including a complex NP with a nominal complement clause in which no reanalysis
is assumed (NR-Comp)
[S Mi’chiko-ga kyookai-o sasaeta] hyooban-ni Kyooko-ga anshinshita.
namef-nom society-acc supported reputation-datnamef-nom felt relieved
“Kyooko felt relieved at the reputation of Michiko to have supported the society”.
In (44a), the string from the first to the third phrase Hoshino-ga tokei-o katta (Hoshino bought a clock) constitutes a relative clause with its head as depaato (department store). In (44b), the initial string Michiko-ga kyookai-o sasaeta (Michiko supported the society) functions as the nominal complement clause of hyooban (reputation). In (44), the head nouns are placed in the fourth phrase, which is the same with SR and SOR. Let us note here that Japanese complementizerto cannot appear between a head noun and its complement clause, as in (45).
(45) *Michiko-ga kyookai-o sasaeta to hyooban-ni Kyooko-ga anshinshita.
namef-nom society-acc supported that reputation-dat namef-nom felt relieved
The difference of the grammatical functions of the subordinate clauses in (44a,b) is shown by the grammaticality in (46), where their nominal adjunct and complement clauses are deleted.
(46) a. For NR-Rel
Depaato-ni Katoo-ga tsutometeita.
department store-dat name-nom was working
“Katoo was working at a department store”.
b. For NR-Comp
*Hyooban-ni Kyooko-ga anshinshita.
reputation-datnamef-nom felt relieved
“*Kyooko felt relieved at the reputation”.
Without the context for hyooban, the meaning of (46b) cannot be determined.
Complex sentences where the subordinate clauses are connected by toki or node in the same way with Kureru and Ageru but neither phonetically null argument nor reanalysis is involved as in (47) were examined as the baseline for these two types.
(47) Complex sentence without phonetically null argument and reanalysis (Complex)
[PP[S Ta’roo-ga kozara-o watta]-toki] Yukiko-ga hooki-o toridasita.
namem-nom small plate-acc broke-when namef-nom broom-acc brought out
“When Taro broke a small plate, Yukiko brought out a broom”.
Case-markings in the seven types of sentence above were controlled as in Table 1. All P1s were PPs with
![]()
Table 1. Case-markings and clausal structures of seven types of experimental sentence (angle brackets indicate subordinate clauses).
their heads as ga and their complements as common Japanese first or family names. All P2s were PPs with their heads as o. P3s in SR, SOR, NR-Rel and NR-Comp were two-place verbs in the past tense that could select their P1s and P2s as their subjects and objects respectively.
In Kureru, Ageru and Complex, P3s consisted of two-place verbs in the past tense that could take their P1s and P2s as their subjects and objects, and the verbs were suffixed by conjunctive node (because) or toki (when). In SR, SOR, NR-Rel and NR-Comp, P4s were PPs with their heads as ni. P4s in SR and NR-Rel had human and place nouns as their complements respectively. SR were semantically controlled so that their P3s might not take the nouns in P4 as their objects. The head nouns in P4s of SOR were inanimate. SOR were also controlled semantically so that the heads in P4s might not behave (metaphorically) as the subjects of P3s. P4s of Kureru and Ageru were PPs headed by o, which were the main objects. In Complex, P4s were main human subjects headed by ga. P5s of SR were PPs headed by o, which were the accusative objects of the main verbs. P5s of SOR were the adverbials modifying the main verbs. P5s in NR-Rel and NR-Comp were PPs headed by ga with first and family names as their complements, which were the main subjects. In Kureru and Ageru, P5s were verbs in the continuative tense. P5s in Complex were the main objects or adverbials modifying the main verbs. P6s in SR, SOR, NR-Rel and NR-Comp were the main verbs in the past tense. In Kureru and Ageru, P6s were kureta (gave to me) and ageta (gave to the third person) respectively, and these P5 and P6 composed the main complex predicates. P6s in Complex were the main verbs in the past tense.
P1 was accented and P2 was unaccented in half of the experimental sentences while the former was unaccented and the latter was accented in the other half so that prosodically major phrases might not be constructed before P3. The stimulus sentences were written in the standard Japanese orthography, namely, Chinese characters and two syllabaries (hiragana and katakana). All names were of two characters and three morae. Twenty sentences were made for each sentence type, and Ageru were made from Kureru by replacing kureta with ageta. Familiarities of the phrases were controlled for sentence types and phrase positions by Amano and Kondo (1999) . In the two-way ANOVA for the familiarities with sentence type and phrase position as independent variables, the main effects of sentence type and of phrase position and the interaction of sentence type × phrase position were nonsignificant [sentence type: F < 1, phrase position: F = 1.17, ns, and sentence type × phrase position: F < 1].8 Two sets of stimuli were made so that sixty sentences (ten for SR, SOR, NR-Rel, NR-Comp, Kureru and Ageru each) and twenty Complex sentences were included in the stimulus set in the counterbalanced design.
4.1.3. Procedure
The stimulus sentences were presented to participants by a questionnaire, where they were instructed to estimate the degree of comprehension difficulty of a sentence by choosing one of seven scale points from 1 (very easy to understand) to 7 (very difficult to understand). Four kinds of questionnaire were made for the two sentence sets, where the orders of stimuli were randomized differently. The instruction and practices were given on the cover. Participants were randomly assigned to these eight kinds of questionnaire. The experiment took participants approximately twenty minutes.
4.2. Results
The mean ratings of comprehension difficulty for the seven types of sentence are presented in Figure 1.
Two one-factor ANOVAs were conducted on the ratings, one with participants as a random factor, and one with items. The ANOVAs had Sentence Type as the within factor. The main effect of sentence type was significant [F1(6, 246) = 34.17, MSe = .38, p < .0001; F2(6, 114) = 37.17, MSe = .16, p < .0001]. Paired t-tests for the participant analysis indicated significant differences between Complex and Ageru, between Ageru and SR, between SR and Kureru, and between Kureru and SOR. The differences between SR and NR-Rel and between SR and NR-Comp were nonsignificant. Bonferroni’st for the participant analysis indicated significant differences between Ageru and SR and between SR and Kureru, and indicated marginally significant differences between Complex and Ageru and between Kureru and SOR. The differences between SR and NR-Rel and between SR and NR-Comp were nonsignificant.
4.3. Discussion
The ratings of comprehension difficulty were ranked from high to low, as predicted: SOR, Kureru, SR, Ageru, and Complex. However, we did not find significant difference between SR, NR-Rel and NR-Comp. The rating of SR thus may be due not to the reanalysis assumed but to the processing cost for complex NP. Further, we did not examine whether reanalyses were carried out at the processing points predicted. In the next section, we will discuss the self-paced reading experiment to solve these problems.
5. Experiment 2
5.1. Method
5.1.1. Participants
Forty-seven graduate and undergraduate students in Tokyo area participated in this experiment for payment. No participant for Experiment 1 was included in them. They were Japanese native speakers.
5.1.2. Materials
Two stimulus sets were made in the counterbalanced design with the stimulus sentences in Experiment 1 and filler sentences. The stimulus sentences in Experiment 1 were divided into two stimulus sets. The main session included one hundred and twenty sentences: Seventy experimental sentences including ten of SR, SOR, NR-Rel, NR-Comp, Kureru, Ageru and Complex respectively, and fifty fillers of thirty three-phrase, ten four-phrase and ten five-phrase sentences. The fifty fillers were included in the two stimulus sets. Participants were randomly
![]()
Figure 1. Mean ratings of comprehension difficulty for seven sentence types scaling from 1 (very easy to understand) to 7 (very difficult to understand) with standard errors.
assigned to these two stimulus sets.
5.1.3. Procedure
The experiment was conducted on a Power Macintosh G4 running PsyScope ( Cohen, MacWhinney, Flatt, & Provost, 1993 ) with a Button Box. Sentences were presented on a computer screen by a phrase-by-phrase, self- paced, non-cumulative, moving-window reading paradigm. An end-point was presented as a phrase to exactly examine the processing cost of P6. After the end-point of a sentence, a Yes/No question examining the comprehension of the thematic relation in the sentence was presented. The participants were instructed to respond to a question by pressing one of two buttons (Yes or No). The question for SR (17), for example, is “Amano decided to go on to an upper school. Yes or No?” (the correct answer in this case is “No”). Two kinds of audio response corresponding to the answers (correct or incorrect) were given to the participants as feedback. The order of presentation of the stimulus sentences was randomized for each participant. The practice session included four trials. The experiment took participants approximately twenty-five minutes.
5.2. Predictions
Here we discuss the proportions of the errors in the comprehension questions and the residual RTs for the seven phrase positions as the indices of processing cost. The residual RTs were calculated by subtracting the participants’ predicted RTs for a phrase from their raw RTs. The predicted RTs for a phrase were derived by the participants’ linear multiple regression equations with the number of characters and that of morae of the phrase as independent variables ( Miyamoto, Gibson, Pearlmutter, Aikawa, & Miyagawa, 1999 ; Mazuka, Itoh, & Kondo, 2002 ). An end-point was counted as a phrase of one character and two morae (maru). The proportions of errors for sentences with more violations of monotonicity are predicted to be higher, and the residual RT at a process- ing point where more violations are assumed will be longer.
5.3. Results
The data of five participants were excluded from the analyses below because their error rates in the comprehension questions for Complex and filler sentences were higher than 20%.
The mean error rates of the forty-two participants in the comprehension questions for the seven sentence types are presented in Figure 2.
Two one-factor ANOVAs were conducted on the arcsine-transformed error rates, one with participants as a random factor, and one with items. The ANOVAs had Sentence Type as within factor. The main effect of sentence type was significant [F1(6, 246) = 37.40, MSe = .022, p < .0001; F2(6, 114) = 30.52, MSe = .013, p < .0001].
![]()
Figure 2. Mean error rates in comprehension questions for seven sentence types with standard errors.
Paired t-tests for the participant analysis indicated significant differences between Ageru and SR, between SR and Kureru and between Kureru and SOR. Bonferroni’s t for the participant analysis indicated significant differences between SR and Kureru, and between SR and SOR.
The mean residual RTs of the forty-two participants for the seven sentence types at the seven phrase positions are presented in Figure 3.
Two two-factor ANOVAs were conducted on these residual RTs, one with participants as a random factor, and one with items. The ANOVAs had Sentence Type and Phrase Position as within factors. The main effects of sentence type and of phrase position were significant [sentence type: F1(6, 246) = 13.41, MSe = 57510, p < .0001; F2(6, 114) = 13.73, MSe = 27346, p < .0001, and phrase position: F1(6, 246) = 10.81, MSe = 238666, p < .0001; F2(6, 114) = 48.01, MSe = 26061, p < .0001]. The interaction of sentence type × phrase position was also significant [F1(36, 1476) = 8.85, MSe = 42356, p < .0001; F2(36, 684) = 9.07, MSe = 20068, p < .0001]. In one-way ANOVAs for the residual RTs at seven phrase positions, the main effects of sentence type were significant at P4, P5, P6 and P7 [P4: F1(6, 246) = 14.16, MSe = 67160, p < .0001; F2(6, 114) = 20.07, MSe = 23034, p < .0001, P5: F1(6, 246) = 15.15, MSe = 61611, p < .0001; F2(6, 114) = 23.66, MSe = 19205, p < .0001, P6: F1(6, 246) = 10.13, MSe = 76530, p < .0001; F2(6, 114) = 12.85, MSe = 29500, p < .0001, and P7: F1(6, 246) = 16.52, MSe = 13984, p < .0001; F2(6, 114) = 14.94, MSe = 7370, p < .0001]. Paired t-tests for the participant analysis at P4 indicated significant differences between SOR and SR, between SR and NR-Rel and between SR and NR-Comp. Bonferroni’s t for the participant analysis at P4 indicated significant differences between NR-Rel and SR, between NR-Rel and SOR, and between NR-Comp and SOR. At P5, significant differences were found by paired t-tests between SOR and SR, between NR-Rel and SR, between NR-Comp and SR and between NR-Rel and NR-Comp. Bonferroni’s t for the participant analysis at P5 indicated significant differences between NR-Reland SR and between SR and SOR. At P6, the differences between Kureru and Complex and between Ageru and Complex were significant by paired t-tests for the participant analysis. Paired t-tests for the participant analysis indicated a significant difference between Kureru and Ageruat P7. Bonferroni’s t for the participant analysis indicated significant differences between Complex and Kureru at P6, between Comple and Kureru at P7, and between Ageru and Kureru at P7.
5.4. Discussion
The error rates in the comprehension questions were ranked as predicted again. The residual RT at P4 of SOR longer than those of SR, NR-Rel and NR-Comp indicates the highly costly reanalysis was performed here in SOR as predicted. The residual RT at P4 of SR longer than those of NR-Rel and NR-Comp suggests that the reanalysis with measurable cost was carried out here in SR. The residual RTs of NR-Rel and NR-Comp were longer than that of SR at P5, which can be understood as the manifestation of the additional processing costs in NR-Rel and NR-Comp. These additional costs should be the reason for their ratings of comprehension difficulty, which were almost the same with that of SR in Experiment 1. The residual RT of Kureru was longer than that of
![]()
Figure 3. Mean residual reading times for seven sentence types at seven phrase positions (ms).
Ageru at P7 as predicted, and the RT of Ageru longer than that of Complex at P6 suggests that the reanalysis with measurable cost was performed here in Ageru again.9
6. General Discussion
We have succeeded in explaining the differences of processing costs for the four types of sentence by our functional incrementality and additivity of the monotonicity violations. Further, the residual RTs in Experiment 2 suggest that reanalyses were performed at the processing points predicted by our hypothesis. Frazier and Clifton (1998) argue that a reanalysis cost cannot be calculated in purely structural terms, and that the reanalysis cost is a function of sentence token, not sentence type. However, our results demonstrate that functional structure as one of the compositional symbolic representations is still effective to estimate the sentence processing cost in a head-final language.
The thematic ambiguity of the head noun of a relative clause and the implicit prosody of a reanalyzed string can raise the processing difficulty, as was reviewed in the section of Introduction. These factors can make a reanalysis more difficult because they produce ambiguity in the reanalysis. In our experiments, these factors were controlled to remove ambiguity in a reanalysis. We do not deny the relevance of semantic or pragmatic factors in sentence processing. Our claim here is that the determination and the revision of grammatical functions is a main factor in the estimation of processing cost when the ambiguity of a reanalysis is removed.
One of our new findings is the additional processing costs in NR-Rel and NR-Comp. Their ratings of comprehension difficulty are comparable to that of SR, and their residual RTs at P5 are significantly longer than that of SR. As the reason for these relatively long residual RTs, we can point out the syntactic peculiarity of Japanese complex NP. To determine the dependency relation between a relative clause and its head, the grammatical function that the head fulfills in the relative clause must be specified. In English relative clauses, relative pronouns and adverbs indicate the functions of the heads in most cases. In (48a), for example, when an NP is followed by whom, the presence of an object relative clause is recognized before its input. In the same way, the sequence of who/which NP in (48b) indicates an object relative, and who/which V in (48c) a subject relative.
(48) a. .. NP whom..
b. .. NP who/which NP..
c. .. NP who/which V..
In the same way again, relative adverbs indicate the strong possibility that the head nouns grammatically function as (part of) adjuncts in the relative clause, as in (49).
(49) .. NP where/when NP..
Even when relative pronouns and adverbs are absent, the sequence in (50) indicates an object relative except when the immediately preceding verb is ditransitive.
(50) .. NP NP..
In the complex NP with a nominal complement clause in (51), the subordinate clause describing the propositional content of the head noun can be predicted by the complementizer.
(51) .. the fact that..
In Japanese complex NPs, on the other hand, no phonetic form is available to determine the grammatical function of a head noun in the subordinate clause. For its determination, therefore, the semantic computation of the argument structure and the selectional restriction of a subordinate verb are required in relation to the semantic contents of the subordinate subject, object and the head noun. As we discussed in the processes of SR, for example, when P4 is encountered, the presence of a complex NP is recognized. The subordinate predicates are two-place verbs, and their arguments are properly determined at P3. Since the human nouns in P4 cannot behave as the adverbial adjuncts for the subordinate verbs, the only way to construct a complex NP is thus to reanalyze the subordinate subject from P1 to P4. In SOR and NR-Rel again, the parsing decision is deeply concerned with semantic and pragmatic constraints between the input words. We can thus say that the absence of phonetic marker makes the interpretation of Japanese complex NP more semantic and pragmatic than that of the English.
Many recent studies have revealed that the interpretations of relative clauses in head-first languages do not necessarily follow the general parsing principle (local attachment). Frazier and Clifton (1996) proposes that primary and non-primary phrases behave differently in sentence processing. The former is “attached” to the current phrase structure while the latter is “associated”. The primary phrases and relations are defined as in (52).
(52) Primary phrases and relations include
a. the subject and main predicate of any (+ or −) finite clause
b. complements and obligatory constituents of primary phrases.
Further, the processing of primary phrases is given a priority over that of non-primary phrases, as in (53).
(53) a. Construal Principle
i. Associate a phrase XP that cannot be analyzed as instantiating a primary relation into the
current thematic processing domain.
ii. Interpret XP within that domain using structural and nonstructural (interpretive) principles.
b. Current thematic processing domain
The current thematic processing domain is the extended maximal projection of the last theta
assigner.
Since English relative clauses are non-primary phrases, they are associated to the phrase structure and interpreted along the Construal Principle.
As we discussed above, semantic and pragmatic information is the determinant of the dependency between a Japanese relative clause and its head. If a head noun can be processed as the subordinate subject or object, the dependency is specified by a predicate-argument relation, namely, a primary relation. If a head noun cannot establish a predicate-argument relation with the subordinate verb, the dependency will be a non-primary relation, which follows the Construal Principle. The reanalyses in SR and SOR thus should be the processes to establish the dependencies between the subordinate clauses and the head nouns as primary relations. On the other hand, the process for the relative clause in NR-Rel does not build up a primary relation. In the comparison between SR and NR-Rel, the reanalysis in SR requires some processing resources indeed, but the primary relation between the head and the subordinate verb establishes the dependency for complex NP. In NR-Rel, on the other hand, no reanalysis is required, but the dependency is non-primary. Under the assumption that a primary relation is given a priority over a non-primary relation, we understand that the reanalysis in SR at P4 for a primary relation and no reanalysis in NR-Rel at P4 for a non-primary relation were observed as the RTs longer for SR than for NR-Rel at P4 and shorter for the former than for the latter at P5. The RT difference at P5 between SR, NR-Rel and NR-Comp is informative here. The head noun in NR-Comp does not have a predicate-argument relation with the subordinate verb, but it takes the subordinate clause as its complement. It can thus be said that the dependency between a head and its complement clause in NR-Comp has the medium status between primary and non-primary relations. The RT of NR-Comp which was shorter than SR at P4 and was longer than SR but shorter than NR-Rel at P5 should be due to the medium status of its dependency relation. The RT pattern of SR, NR-Rel and NR-Comp thus can be the manifestation of the functional distinction between argument and non- argument in real-time sentence processing.
Acknowledgements
We are deeply grateful for valuable comments by three anonymous reviewers. This study is partially supported by Japan Society for the Promotion of Science through Grant-in-Aid for Scientific Research to the first author (No. 14510629).
NOTES
1A reanalysis cannot be directly observed, and it is a hypothesis for processing difficulty. “SR” and “SOR” are thus not objective terms. However, we employ them in the following discussion since they are quite common among researchers.
![]()
2Yaru is a colloquial form of ageru.
3The receiver of benefit in sentences with kureru can be persons psychologically near to the speaker, for example, family member and close friends, given a proper context.
4Some of Japanese two-place stative predicates can take ga-marked noun phrase as the internal argument as in (i).
(i) Musoko-wa inu-ga sukida.
my son-top dog-nom likes
“My son likes dogs”.
Kowai (fear), hoshii (want), and kiraida (dislike) are other examples. The inflections of these predicates are different from those of verbs, and thus they are generally categorized as adjectives or adjective verbs.
![]()
5Some Japanese native speakers accept a ni-marked noun phrase as a matrix subject as in (i).
(i) Chichi-ni kinshu-ga dekiru.
father-dat abstention from drink-nom can do
“My father cannot abstain from drinking”.
However, the younger generation of present Japanese native speakers tend to reject (i) as unacceptable.
![]()
6The phrase structure in a derivational theory of syntax for (39) can be different from the structure in the text. That is, the PP “(speaker) yooji-o daiteitatoki” will be dominated by the main VP “nimotsu-o mottekureta”, and the structure for the empty subject (ε) of the main VP will be absent in a derivational syntax. In Japanese Phrase Structure Grammar and Head-Driven Phrase Structure Grammar ( Pollard and Sag, 1994 ), no syntactic constraint is assumed that requires bijective correspondences between a predicate and its argument(s), like Theta-Crite- rion ( Chomsky, 1981 ). The phrase structure in (39) is thus licit, but we do not stick to the structure in (39) because the reanalysis of the first argument of “daiteita’” is well represented in either of the two structures.
7One of the anonymous reviewers points out the possibility that nimotsu-o motte in Kureru and Ageru is constituent on the basis of (i). If the pro-verbal form soo-shite in (i) can replace nimotsu-o mottein Kureru and Ageru, the string will make up a constituent.
(i) Gotoo-ga soo-shite kureta/ageta.
Gotoo-nom so doing gave to me/the third person
“Gotoo did so for me/him or her”.
Even when nimotsu-o motte behaves as a syntactic constituent, the functional and the thematic specifications for motte’ and ageta’/ kureta’ are the same with the discussion in the text. Therefore, the two phrase structures make no difference in the predications for the experiments.
![]()
8In the ANOVA, the values of names, kureta in Kureru and ageta in Ageru were excluded because of their frequent repetitions.
![]()
9The canonical order of case-markers in Japanese is often assumed to be ga, ni, and o. The order of the matrix arguments in SOR is ga, o, and ni while that in SR is ga, ni, and o. The former is non-canonical while the latter is canonical. It is known that a sentence with non-canonical order is more costly than a sentence with canonical order ( Tamaoka et al., 2003 ). As one of the anonymous reviewers correctly points out, therefore, the non-canonical order of SOR might increase its processing cost in the comparison of processing difficulty between SOR and SR. We should note here that the orders of matrix arguments in NR-Rel and NR-Comp are ni and ga, which are non-canonical. However, we did not find greater processing difficulty for NR-Rel and NR-Comp than for SR in the comprehension difficulty in Experiment 1, the error rate, the RT at P4, where ni-marked head noun was received, and the RT at the matrix predicates in Experiment 2, where the order of matrix arguments were finally recognized. It is possible that the non-canonical order of SOR raised its processing cost, but the effect of word order will be much smaller than that of the revision of grammatical functions.