Constructing Confidence Regions for Autoregressive-Model Parameters ()
1. Introduction
The mth-order autoregressive models (see [1] ) are flexible enough to describe a large assortment of stationary time-series data, thus enabling us to make reasonably reliable predictions of future observations. This rests on our ability to accurately estimate parameters of these models, based on a given set of past observations (see [2] ); we also need to establish the model’s smallest order capable of achieving adequate agreement with available data.
We start by reviewing basic formulas for constructing the likelihood function (LF) of any such model, whose maximization then results in maximum-likelihood (ML) estimates (these are the actual numerical values thus obtained) of the model’s parameters (note that the same MLEs, seen as random variables, i.e. functions of yet-to-be taken observations, are called estimators). We then proceed with an asymptotic theory of the estimators’ sampling distribution (see [3] ), and a way of constructing an accurate confidence interval (region) for one (or more) of the parameters; this requires abandoning the direct approach suggested by Central Limit Theorem and using the sampling distribution of
instead. We also design tests to decide whether it is possible to reduce the number of the model’s parameters without adversely affecting its predictive power. Finally, we modify the technique to cover the possibility of estimating only a subset of the model’s parameters while ignoring the rest (known as nuisance parameters).
2. Autoregressive Model
In this model, the ith observation (denoted
) is generated by a linear combination of the last m observations and an extra term
, independent of these and Normally distributed with the mean of zero and standard deviation
(
in our notation), i.e. by
(1)
where m is a small integer. When
or 2, the model is called Markov or Yule respectively; in all other cases, we refer to it as the AR(m) model. We study it in its stationary mode only, meaning that the process has equilibrated before we start observing it (this implies, among other things, that all
have the same Normal distribution). The value of the
parameter is arbitrary,
is positive, while the
values must meet (for the process to be stationary) three specific inequalities, introduced shortly (see [4] ).
Note that, after standardizing the
by
(2)
(1) simplifies to
(3)
where
.
2.1. Variance and Serial Correlation
One can readily establish that the joint distribution of all the
(
) random variables is multivariate Normal with the same mean of μ and a common variance which equals to
further multiplied by a function (5) of the α parameters. The (serial) correlation coefficient between
and
is the same regardless of the value of i (this follows from being stationary); we denote it
(note that
).
To find the first m values of
, we need to solve the following set of linear equations (a routine exercise)
(4)
with the understanding that
, while the common variance is
(5)
The remaining
values (we need to go up to
) then follow from the following recurrence formula
(6)
while the
element of the (n by n) variance-covariance (VC) matrix (which we denote by
) of the
’s equals to
.
Note that
and
remain the same for the
sequence, while σ is then equal to 1.
These formulas are all well established in existing (and extensive) literature; it should suffice to quote [5] as our reference.
2.2. ML Estimation
To construct the corresponding multivariate probability density function (PDF), which becomes the likelihood function (denoted LF) when the
’s are replaced by actual observations, we need the inverse of
and also its determinant. There is a general formula for elements of the inverse; getting the determinant is more difficult (note that symbolic computation on large matrices is practically impossible). Nevertheless, there is a way of bypassing this problem (see [6] ) by finding the PDF of
,
first (a simple exercise, since symbolic inversion and determinant computation of an m by m matrix becomes feasible) and then transforming it to get the PDF of the original set (equally simple: substitute (2) and divide by
); this yields
of the X sequence (while ignoring the constant
term), namely
(7)
where
is now the VC matrix of only the first m terms of the
sequence; the second sum is the standard Normal PDF of the
subsequence, after solving (3) for
and substituting.
As an example, we select (rather arbitrarily)
,
,
,
,
and
and generate a random sequence of 300 consecutive and equilibrated observations using the corresponding AR(3) model of (1), and the following Mathematica code.

The first line generates a sequence of
independent values from the
distribution—the
of (1); the second line (and its continuation) converts them to the
of the same formula, using
. The extra 100 observations were needed to allow the process to equilibrate (the first 100
’s are then deleted); the last line displays the resulting AR(3) sequence in Figure 1.
Using the generated sequence as data from an AR(3) model whose five parameters are unknown and to be estimated, we proceed to
• solve (4) for the first 3 (m in general) ρ’s,
• compute V using (5),
• and the corresponding inverse of the
matrix (denoted A),
• standardize the observation in the manner of (2),
• build the
multiple of (7) while excluding its last term (the result is called L).
This is done (one line for each bullet) by the following continuation of the previous computer program:
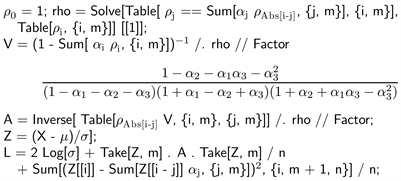
In addition to computing L we have also printed V, as its denominator provides a useful set of if-and-only-if conditions for the process to be stationary (all of its three factors must be positive).
Now, we need to either maximize
(a difficult task), or make each of its derivatives (with respect to every parameter) equal to zero and solve the corresponding set of normal equations; the latter approach is easier, faster and more accurate; it involves the following steps:
• compute the five (
in general) derivatives of L (the first two lines of the code below); multiply each by σ2, thus making them free of σ (with the exception of the σ derivative which, when multiplied by σ3 becomes linear in σ2); denote the results dμ, dσ and dα (the last being a set of m expressions),
![]()
Figure 1. Randomly generated data based on AR(3) model.
• similarly (line three), differentiate the extra
term of (7) with respect to each α parameter, denoting the answer dV (a collection of m functions of only the α parameters),
• set the initial value of μ to
, of σ (arbitrarily) and of each α to 0, and start the following iteration (performed by Mathematica’s routine ite):
• solve
(8)
for a new, updated set of α values (the second line of ite; its first line is only preparatory—note its continuation) where
implies that dα is evaluated using the current value of μ, while
is similarly evaluated using the current set of α values; the corresponding equations for the new α’s are thus linear and easy to solve,
• solve
(9)
to get a new value of μ, where the evaluation is now done using the updated α’s (third line of ite); the equation is linear in μ and thus trivial to solve,
• finally, solve
(10)
for σ, where the evaluation is done using the new values of both μ and α (fourth line of ite; the final line just combines the updated values of μ, σ and α’s into a single output); the equation is linear in σ2 (its positive root yields the updated σ),
• repeat the iteration till the new values of the five parameters no longer change (a total of five iterations normally suffice to reach an adequate accuracy); this is done by the last line of the subsequent code, which also returns the resulting ML estimates.
To do this, we need to further extend the previous Mathematica code by:

thus obtaining the ML estimates of μ, σ and the three α’s (in that order).
An interesting observation: the last term of L (whose numerator is a sum of squares of differences between predicted and actual values of the Z sequence) always results in 1 when evaluated using the ML estimates returned by sol; this can serve as a verification of the program working correctly.
2.3. Asymptotic Distribution
The general version of central limit theorem (CLT) tells us that the sampling distribution of ML estimators is approximately Normal, with the asymptotic means equal to the parameters’ true values. To get the distribution’s VC matrix, we utilize the theory of Fisher information matrix and
• divide
by n, getting
(11)
where
; this follows from (7),
• find the matrix of second derivatives (with respect to each pair of parameters) of this expression,
• find the expected value (indicated by
) of each element of this matrix, remembering that
(12)
• take the corresponding
limit,
• invert the resulting matrix,
• and further divide by n.
Leaving out further details, this yields the following results: ML estimators of μ and σ are, asymptotically (i.e. when n is large) independent of each other and of the α estimators, with standard deviation given by
(13)
respectively, while the α part of the asymptotic VC matrix is
(14)
in the case of Markov (
), Yule (
) and AR(3) model, respectively. Note that each VC matrix is both symmetric and slant-symmetric (i.e. the same when flipped with respect to either diagonal). They have been found by the first line of the following Mathematica code (by specifying the value of m first).
When executed at the end of the last program (where m was already set to 3), the second line establishes the standard error (using (13) and (14), with parameter estimates replacing their true values) of each of the previously computed ML estimates; note that they are all within two standard errors of their true values.

Using these results, we can then compute the standard error of the expected value of the next (yet to happen) observation, established based on (1), the last m observations, and our estimates of μ and the α’s.
3. Confidence Regions
To construct a confidence region (CR) for true values of all
parameters of an AR(m) model, we could directly use their asymptotic Normal distribution of the previous section (see [7] [8] and [9] ). Nevertheless, it is more accurate (in terms of establishing the correct level of confidence), and also notably easier, to utilize the theorem which states that
(15)
has, to a good approximation, the chi-squared distribution with
degrees of freedom (notation:
). Here, the first term of (15) involves the maximum value of
achieved by the ML estimates, while the second term assumes evaluating the same
using the true values of the parameters. The proof of a similar statement can be found in [10] ; the necessary modifications are quite simple and need not be elaborated on. The theorem’s accuracy is demonstrated in Figure 2, which compares the empirical histogram of 105 randomly generated values of (15) to the PDF of
, using a Markov model with
,
,
and
.
Even though the agreement is not quite perfect (it quickly improves with increasing n), both the accuracy and simplicity of this approach greatly outweigh those of CLT (Figure 6 demonstrates the error of the basic Normal approximation: it is far less accurate than what we see in Figure 1).
Utilizing this asymptotic distribution, we then make (15) equal to a selected critical value of
; solution to this equation yields the CR boundaries. To show how it is done in the case of the above Markov model, we run the program of our original example while changing its first three lines to
This returns a set of data displayed in Figure 3 (the individual observations have been connected) and, after executing the program’s next two segments, also the corresponding three ML estimates (saved in sol).
Computing L and res by the previous routines, and adding the following two lines of code (the first evaluating (15), the second doing the plotting)
![]() produces the desired CR, displayed in Figure 4 (in Mathematica, it can be rotated and observed from any direction).
produces the desired CR, displayed in Figure 4 (in Mathematica, it can be rotated and observed from any direction).![]()
Figure 2. Empirical and theoretical distribution of (15).
![]()
Figure 3. Randomly generated data from Markov model.
![]()
Figure 4. 95% confidence region for Markov-model parameters.
3.1. Nuisance Parameters
We have already shown that the three ML estimators of Markov-model parameters are asymptotically independent; this enables us to find a confidence interval (CI) for any one of these (we call it the pivotal parameter) by treating the other two as nuisance parameters (see [11] ). The reference indicates that changing (15) to
(16)
where “mixed” implies using ML estimates for the nuisance parameters and the true value of the pivotal one) makes (16) into a
type of random variable.
Using parameters of the Markov example of the last section, we display, in Figure 5, the empirical and theoretical PDF of (16), while considering μ and σ to be nuisance parameters and
the pivotal one; the agreement is nearly perfect.
Let us contrast this result with similar comparison of the actual (empirical) distribution of the ML estimator of
with its asymptotic (CLT-based) limit (Normal, with the mean of 0.9 and variance, based on (14), of
), which is displayed in Figure 6. This time the error of the approximation is clearly inacceptable; using it for constructing CI for the true value of
is not recommended.
![]()
Figure 5. Empirical and asymptotic PDF of (16); nuisance parameters are μ and σ, m = 1.
![]()
Figure 6. Empirical distribution of α1, versus its Normal approximation.
To accurately compute boundaries of a CI for
, we must thus return to (16) and utilize its fast convergence to
distribution. First, we find ML estimates of all parameters (already done in previous section), then add the following two lines of code (the first line evaluating (16), the second one making it equal to the 80% critical value of
and solving this equation for
):

We then claim, with an 80% confidence, that the true value of
lies between the resulting two roots.
Note that the theory allows us to designate any set of parameters as pivotal (the rest are then the nuisance parameters); when the two sets of estimators are asymptotically independent, the distribution of (16) is approximately
, where p is the number of pivotals. As soon as there is a non-zero correlation between the two groups, the distribution of (16) becomes substantially more complicated and, in the case of AR(m) models, practically impossible to deal with. The technique can thus be applied only to situations when all α parameters are either all pivotal or all nuisance, as demonstrated by our next example.
This time, we generate data from Yule model with
,
,
,
, using
, by the usual

which produces the sequence of Figure 7.
We then run the common part of the program to find the four ML estimates, saving them under the name res. Executing the following two extra lines (the first line evaluating (16), the second one making it equal to the 95% critical value of
, solving for
and
, and displaying the resulting contour):

we get the 90% CR of Figure 8 for the true values of
and
, while considering μ and σ as nuisance parameters.
This is based on our previous assertion that the distribution of (16) is, in this case, approximately
; to check the accuracy of this statement, we display the empirical version of this distribution (using the same Yule model and 105 sequences of 100 consecutive observations) together with the PDF of
in Figure 9; the agreement is again practically perfect.
![]()
Figure 7. Randomly generated data from Yule model.
![]()
Figure 8. 90% confidence region for α1 and α2.
![]()
Figure 9. Empirical and theoretical PDF of (16); nuisance parameters are μ and σ, m = 2.
3.2. Establishing Model’s Order
Until now, we always assumed that the value of m (the order of the model) is known; this may normally not be the case, so the question is: how do we test whether an AR(m) model has the correct number of α parameters to be an adequate representation of a given set of consecutive observations? The obvious idea is to see if, by extending the model by an extra
parameter, the corresponding increase in the maximum value of the
function is statistically significant. This can be easily tested by using an extension of the last theorem: when the data does follow an AR(m) model, the following difference
(17)
(where the subscript indicates the number of α parameters used to maximize
) has
distribution.
We verify this by yet another Monte-Carlo simulation of 105 sequences generated from the AR(3) model of our first example, displaying empirical histogram of the resulting (17) values, together with the PDF of
, in Figure 10. The agreement indicates that the latter distribution is again an excellent approximation of the former.
Returning to the original example; we have already computed ML estimates of the five parameters, which are easily converted into the corresponding value of
. We then need to use the same data and run the same program with
, similarly converting the resulting six estimates to a new (always higher) value of
. Evaluating (17) and substituting the result into the CDF of
(we let the reader come up with the corresponding code) yields 0.111; this, being less than 95%, tells us that the data is adequately described by the original AR(3) model.
![]()
Figure 10. Empirical and asymptotic PDF of (17); m = 3.
On the other hand, trying to fit a Yule model (
) to the same data yields substantially higher difference between
and
, resulting (using the same example) in a CDF value indistinguishable from 1 (the corresponding P-value is of the order of 10−61), indicating that no Yule model can properly describe this data.
We mention in passing that, to test the same
hypothesis, we could resort to a less sophisticated approach of using the asymptotic distribution of the ML estimator of
(Normal, with the mean of 0 and variance equal to
, under the null hypothesis), getting a similarly small P-value of 10−40; this test is not only less accurate (the Normal approximation has a large error, as we have seen) but also less sensitive than the one based on (17).
4. Conclusions
In this article, we have provided a variety of techniques for estimating parameters of an AR(m) model, including construction of confidence intervals/regions and testing various hypotheses regarding parameter values and the model’s order. We have used Monte Carlo simulation extensively to find empirical distributions of various sample statistics and explore the accuracy of each proposed approximation. This led us to conclude that the traditional use of CLT and of the corresponding Normal distribution is to be discouraged due to the resulting large errors. On the other hand, utilizing differences between various
functions and the corresponding
distribution yielded very accurate results even with relatively small sets of past observations.
There are several directions to pursue in terms of potential future research, e.g.: investigating how flexible AR(m) models are to describe, to a sufficient accuracy, general stationary stochastic processes (such as moving averages) that do not necessarily originate from (1); after all, real data do not exactly follow any mathematical model—these function only as useful approximations. Another possible extension of the current research would be to similarly deal with ARMA models; here, one would need to find some practical way of inverting (and finding determinants) of large symbolic matrices, essential for computing the corresponding
function.