A Novel Scheme for Separate Training of Deep Learning-Based CSI Feedback Autoencoders ()
1. Introduction
Deep learning techniques have gained immense popularity in various fields, including wireless communication physical layer [1]. Generative-based models like Autoencoders [2] have emerged and demonstrated its remarkable ability in data compression and reconstruction. CSI feedback is a crucial communication indicator used to measure channel state information, especially in the frequency division duplexing (FDD) MIMO system [3]. Previous models, such as CsiNet [4], DCGAN [5], and TransNet [6] etc. have achieved significant performance in DL-Based CSI feedback task. However, these papers mainly focus on models of achieving high compression and reconstruction performance, which involves joint training of a single encoder-decoder pair. During joint training, the encoder and decoder collaborate and share information, which can potentially result in privacy leakage and leave the system more vulnerable to adversarial attacks [7]. Moreover, whether in a multi-user or multi-base station system, joint training requires encoders of all users and decoders of all base stations to be trained simultaneously. This results in the need to retrain all models when new users (or new base stations) join (or leave) the system. This not only demands a significant amount of computational resources but also makes it difficult to apply and deploy joint training in large-scale Multi-user Multi-base station system.
Separate training is a novel approach to solve these issues. With separate training, the encoder and decoder of multiple users receive independent and individualized local training and then apply our separate training strategy, the optimization between encoder and decoder is separated. This technique ensures that the encoder cannot learn any specific details related to the decoder, and vice versa. As a result, the privacy of the algorithm and model is better protected. Moreover, separate training is more flexible and allows for easier addition or removal of users or base stations from the system. It also permits greater personalization and customization of different model structures, making system more compatible and scalable.
Our system utilizes separate training in two different scenarios. In the first scenario, multiple User Equipment (UEs) simultaneously transmit CSI to a single Base Station (BS) in what is known as the
case. For this scenario, we employ a separate training decoder that works in conjunction with multiple pretrained encoders of UEs. In the second scenario, a single UE transmits CSI to multiple BSs in what is known as the
case. For this scenario, our system employs a separate training encoder that works in conjunction with multiple pretrained decoders of BSs. These pretrained models have been obtained through independent one-to-one local joint training. They can provide prior information to facilitate separate training, while ensuring the confidentiality and privacy of the algorithmic models used.
Notation: The channel matrix is denoted by H, and the channel eigenvectors is represented by
,
and
represents the number of transmitting and receiving antennas,
is the number of subcarriers while S represents the number of subbands. The symbol
denotes statistical expectation.
refers to the number of feedback bits, while B suggests the use of B-bit quantization and dequantization.
denotes the latent space vectors set while the split datasets of training is denoted by
.
2. System Model Design
2.1. System Model
We consider a 5G-NR massive MIMO transmission system with spatial-frequency CSI feedback [8]. We use 48 Resource Blocks (RBs) and divide them into S = 12 subbands, each of which contains 4 RBs in the frequency domain. At the base station (BS), there are 32 transmitting antennas (
), while the User Equipment (UE) is equipped with 4 receiving antennas (
). In UE side, the received signal is denoted as:
.
where
denotes the UE’s downlink channel response matrix at the i-th subcarrier,
. W is the precoding matrix, s is the bitstream signal, and n denotes the additive noise. We calculate the convariance matrix of s-th subband:
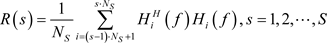 (1)
(1)
where
denotes the number of subcarriers on each subband, which equals to
. The
reflects the average correlation of the channels across different subcarriers in s-th subband. For rank = 1, we obtain the eigenvector
corresponding to the largest eigenvalue of this
. Traverse all subbands, we get the all the eigenvectors of S subbands. The dimensionality of the CSI eigenvectors
is
, where the factor of 2 represents the real and imaginary parts, respectively. In the UE uplink CSI feedback transmission, we employ uniform quantization with B bits of precision. The basic architecture of the autoencoder, which employs CSI eigenvectors for compression and reconstruction, is illustrated in Figure 1. Basic architecture of Autoencoder for CSI Eigenvectors compression and reconstruction where r and i denotes real and imaginary of eigenvectors, respectively. As CSI feature vectors serve as our data, we measure the similarity between the recovered vectors and the original vectors using the Square Cosine Similarity (SCS), which can be our metric of reconstruction. We employ a loss function, denoted as
in this paper, where
: (
denotes eigenvectors). Figure 2 presents the pro- cess of joint training and separate training (including separate training decoder
![]()
Figure 1. Basic architecture of Autoencoder for CSI Eigenvectors compression and reconstruction where r and i denotes real and imaginary of eigenvectors, respectively.
![]()
Figure 2. Joint training, Separate training decoder and Separate training encoder. Quan and Dequan refer to quantization and dequantization, the
are latent space vectors for split datasets
respectively.
and separate training encoder). We consider general of n-pairs of encoder-deco- der, firstly we divide our dataset to
, of which are treated as independent encoder-decoder datasets to jointly train their respective encoder and decoder. We use
as the i-th encoder and
as the i-th decoder, the encoder and decoder can be parameterized by
and
, where refers to the weights and biases of neural network. And the
are latent space vectors for
respectively.
Joint training involves optimizing n autoencoder models (encoder-decoder pairs) simultaneously on their respective datasets, that is an unsupervised learning approach which simultaneously trains encoder and decoder models. Conversely, separate training involves retraining a single decoder in
case and with n pre-trained encoders and retraining a single encoder with n pre-trained decoders in
case, as pre-trained encoders and decoders are from Equation (2) where
.
(2)
2.2. Separate Training Decoder
When separate training decoder, we should retrain a decoder (
) to minimize
(3)
where
. Since
are pre-trained.
can be obtained by feeding the corresponding split datasets
to respective encoder networks.
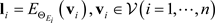 (4)
(4)
Take Equation (4) to Equation (3), we get
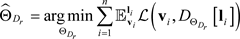 (5)
(5)
where
.
The optimized function in Equation (5) implies that by utilizing the generated labels from prior joint training, we can convert the previous unsupervised learning approach of joint training autoencoders into a supervised problem. In this new approach, multiple latent space vectors serve as inputs, and CSI eigenvectors serve as outputs for our retrained-decoder, as illustrated in Figure 2. During separate training, we concatenate
and
. Thus, the objective of separate training decoder is to minimize the overall loss in Equation (6).
(6)
Equation (6) indicates the retrained-decoder
is to reconstruct the original CSI from the latent space vectors which offer prior information about encoders and are generated by
. As a result, the retrained- decoder has no idea about the specific weights and biases of each encoders, which can help further protect the privacy of the individual encoder models and algorithms.
Figure 3 portrays the
separate training decoder system
, where three User Equipments (UEs) apply CSI feedback to one Base Station (BS). Our model is transformer-based and was inspired by [6] with positional encoding. Our design incorporates three distinct encoder architectures: The first encoder (encoder1) employs a 6-layer transformer block, the second encoder (encoder2) employs a 5-layer transformer block, while the third encoder (encoder3) uses a simple fully connected (FC) layer. The decoder consists of a 6-layer transformer-decoder block.
2.3. Separate Training Encoder
As for separate training encoder, we should retrain a encoder (
) to minimize (where
.)
(7)
However, in separate training encoder, we cannot use the same label generation method like separate training decoder because the pre-trained models are
![]()
Figure 3.
case for separate training decoder system
.
. The unidirectional architecture of the encoder-decoder model hinders the direct transformation of information from the decoder into labels for separate training encoder. Moreover, since the encoder is tasked with learning a compressed representation of underlying data features, it poses challenging to fit multiple pre-trained decoders. To overcome this limitation, we have developed an adaptation layer architecture that adapts non-linear transformations for multiple decoders as shown in Figure 1, which enables the retrained encoder to be compatible with multiple decoders.
Figure 4 depicts the
separate training encoder system
, where one User Equipment (UE) apply CSI feedback to three Base Stations (BSs). Our design incorporates three distinct decoder architectures: the first decoder uses a 6-layer transformer block, the second decoder uses a 5-layer transformer block while the thrid decoder is a residual block consisting of 27 layers of
and one layer of
.
represents the convolutional layer with c as the output channels of the CNN layer, and
and
as the height and width of the kernel size, respectively. The encoder consists of a 6-layer transformer block.
We have developed an adaptation layer based on multilayer perceptron (MLP) that utilizes mixed activation functions. As shown in Figure 5 MLP-Based Adaption Layer architecture., our approach differs from previous encoders, as it is not directly connected to the quantization layer. Instead, the output of the last fully connected (FC) layer, which has a dimension of 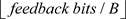 and is activated by a sigmoid function, passes through two fully connected layers forming the adaptation layer. These layers are associated with the relu and tanh activation functions, respectively, providing distinct non-linear transformations. The shapes of these two output layers are denoted by
. Before connecting to the quantization layer, we also include another FC layer with an output shape of
and is activated by a sigmoid function, passes through two fully connected layers forming the adaptation layer. These layers are associated with the relu and tanh activation functions, respectively, providing distinct non-linear transformations. The shapes of these two output layers are denoted by
. Before connecting to the quantization layer, we also include another FC layer with an output shape of 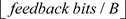 and a sigmoid activation function.
and a sigmoid activation function.
Therefore, we propose a general separate training algorithm for the encoder with adaptation layer architecture, which is presented in Table 1 Algorithm of Separate training encoder with adaption layer. The adaptation layer, denoted by
, is parameterized by
, which includes n different weights and biases adaption layers, namely
.
![]()
Figure 4.
case for separate training encoder system
.
![]()
Figure 5. MLP-Based Adaption Layer architecture.
![]()
Table 1. Algorithm of Separate training encoder with adaption layer.
By Equation (8), we can observe that the separate training of
involves feed forwarding and gradient receiving from
, while keeping the decoders’ weights and biases private. The adaptation layer architecture is designed to minimize the performance loss when adapting an encoder to multiple pre-trained decoders, ensuring that the system can maintain high performance levels while preserving the privacy of the decoder models. By doing so, the method offers greater flexibility and security compared to joint training. Moreover, Equation (8) also reveals that the whole data
is to optimize
while
is updated by their respective split datasets
, which proves that the design of adaption layer
is to help the encoder
learn the common underlying features of the data while adaption layer coordinates the compatibility between the
and
.
3. Results and Analysis
3.1. Dataset and Hyperparameters Configuration
Our dataset was generated based on the Clustered Delay Line (CDL) channel at Urban Macro(UMa) scenario with a carrier frequency of 2 GHz, bandwidth of 10 MHz, and carrier spacing of 15 KHz, as per the Scenarios and Requirements for AI-enhanced CSI from 3GPP Release 16 discussion. The UE receiver settings included 80% indoor (3 km/h) and 20% outdoor (30 km/h). The CSI eigenvectors are acquired as described in Section 2.1. Each dataset (
) consists of 100,000 training and 12,000 validation samples, and 60,000 testing samples are used to evaluate the performance of models from both joint training and separate training. The transformer’s linear embedding dimension was set to
, the shapes of these two output adaption layers are
. Moreover, we set the number of attention heads for multi-head attention to be 8. We trained our models using 2-bit uniform quantization (
) and Adam optimization algorithm. The initial learning rate was set to 1e−4 and decreased by half every 40 epochs. We trained our models on a single NVIDIA 2080 Ti GPU with a batch size of 64 and up to a maximum of 200 epochs. We utilized the loss function $1−SCS$, as specified in Section 2.1. The more detailed data description and open source codes are available at https://github.com/xls318027/CSI-Separate-training.
We consider 4 different CSI feedback payload bits of 49, 87, 130 and 242. The output shape of encoder before quantization layer is , which implies the compression ratio
of our model is 24/768, 43/768, 65/768 and 121/768, respectively. Our performance metric is Square Generalized Cosine Similarity (SGCS) where denotes the average square cosine similarity of S subbands: (
for real and imaginary parts of eigenvectors while s denotes s-th subbands.)
, which implies the compression ratio
of our model is 24/768, 43/768, 65/768 and 121/768, respectively. Our performance metric is Square Generalized Cosine Similarity (SGCS) where denotes the average square cosine similarity of S subbands: (
for real and imaginary parts of eigenvectors while s denotes s-th subbands.)
(9)
3.2. Performance Comparison Result between Joint Training and Separate Training
Figure 6 presents the results of comparing joint training and separate training decoder on different feedback bits. The retrained decoder
exhibits an average decrease in SGCS performance of 0.0131, 0.0146, and 0.0239 on
,
, and
, compared to the respective joint training decoders
,
, and
. This corresponds to a decrease of 1.90%, 2.15%, and 3.99% in terms of percentage. The results illustrate that the method of separately training the decoder in
Equation (6) provides a slight decrease in SGCS performance compared with joint training. This minor decrease shows that separate training decoder algorithm makes different users independently and freely train their respective encoder models without having to retrain all models as in the case of joint training of
system when new users join or leave.
Figure 7 presents comparing joint training and separate training encoders on different feedback bits, with and without adaptation layer. The retrained encoder
with respective adaption layer
,
,
exhibited an average decrease in SGCS performance of 0.0142, 0.0201, and 0.0212 on
,
and
, compared to the respective joint training encoders
,
, and
. This represents a decrease of 1.94%, 2.77%, and 3.17% in terms of percentage.
In contrast, ablation experiment without adaptation layer indicates the performance of ![]() decreased significantly by 0.3070, 0.3290, and 0.3731, representing a decrease of 44.48%, 47.98%, and 56.72% respectively.
decreased significantly by 0.3070, 0.3290, and 0.3731, representing a decrease of 44.48%, 47.98%, and 56.72% respectively.
Our experimental results demonstrate that the use of the adaption layer design algorithm presented in Table 1. For separately training encoder models offers only a marginal reduction in SGCS compared to joint training. However, the non- adaption method leads significantly worse performance. Those results shows that not only the separate training encoder enables each user to selectively switch between communicating base stations without altering the decoders at individual base stations but also our proposed algorithm with adaption layer could significantly mitigates the performance loss of separate training.
3.3. Influence of Feedback Bits, Compatibility of Different Models
The performance of the separately training decoder shows a relatively small impact with different feedback bits of 49, 87, 130, and 242, resulting in a performance decrease of 0.0171, 0.0156, 0.0180, and 0.0178, respectively. This corresponds to a percentage decrease of 2.92%, 2.48%, 2.77%, and 2.56%.
These results suggest that the concatenation of latent space vectors for the
separate training decoder is only slightly influenced by the feedback bits. In contrast, the separate training encoder is significantly impacted, exhibiting performance decreases of 0.0095, 0.0113, 0.0143, and 0.0391, respectively, which correspond to percentage decreases of 1.52%, 1.71%, 2.08%, and 5.19%. This demonstrates that as feedback bits increase, the output shape of our fixed adaptation output shape
, with a size of 1536, also decreases in performance due to the increased value of![]() . Thus, when considering
adaption layer, we should make set appropriate adaption layer settings for achieving considerable performance.
. Thus, when considering
adaption layer, we should make set appropriate adaption layer settings for achieving considerable performance.
Both separate training decoder and separately training encoder demonstrate that when the encoder and decoder have different architectures, it results in a more noticeable performance decrease, as observed in the cases of
for separately training decoder and
for separately training encoder. Therefore, there should be a consideration of the trade-off between model compatibility and complexity.
4. Conclusion
Our paper has introduced a new method for training DL-based CSI feedback autoencoders separately. We have proposed the use of concatenated latent space vectors for separate training decoder and a unique adaption layer for separate training encoder. Through a series of comprehensive comparative experiments, we have shown that separate training can achieve similar performance to joint training while providing additional benefits such as improving protection of model and algorithm privacy and enhancing system scalability due to its flexible mechanism of independently local training and sufficient separate training strategies.
Acknowledgements
This work was supported in part by the National Natural Science Foundation of China under Grant (No. 92067202), Grant (No. 62071058) and CICT Mobile Communication Technology Co., Ltd.