Everything You Wanted to Know but Could Never Find from the Cochran-Mantel-Haenszel Test ()
1. Introduction
The Cochran-Mantel-Haenszel (CMH) test [1] [2] is a statistical test used to examine the association between two categorical variables while controlling for the effects of a third variable. It is particularly useful when analyzing data with a 2 × 2 contingency table and a potential confounding variable. By calculating a test statistic that follows a chi-squared distribution, the CMH test determines whether the association between the variables of interest is statistically significant after accounting for the stratifying variable. This test, named after its developers, Cochran, Mantel, and Haenszel, is commonly employed in epidemiology and biostatistics to understand relationships in observational studies and clinical trials while adjusting for potential confounders.
This manuscript, focused on statistical aspects of data analysis, aims to present the technical details of the Cochran [1] and Mantel and Haenszel [2] test in order to achieve an adequate understanding of it. First, the hypotheses and assumptions of the test are stated. Next, the point estimation and confidence interval of the common odds ratio and the check of its significance with a Z test are shown; afterward, the computation of the Cochran’s Q statistic and its sampling distribution is examined, as well as the statistical decision making. The issue of effect size for this nonparametric test is also addressed. The verification of the assumption of a homogeneous effect of X on Y in each stratum is deepened through two tests, namely: the Woolf’s test [3] and the Breslow-Day test [4] with Tarone’s correction [5] . The theoretical part ends by indicating how to proceed in case of unfulfillment of the aforementioned homogeneity assumption and what other, more generalized, alternative exists to the CMH test. Finally, an example of application of this test is presented. The effect of tobacco smoke, smoked at home, on bronchial asthma in pediatric minors is analyzed, statistically controlling the effect of air quality in the place of residence. For this purpose, a simulated sample composed of 2000 participants, which is composed of k sub-samples randomly collected from the general population of k countries, was generated. This example is a realistic simulation aimed at showing technical and interpretive aspects of the CMH test.
Due to the current emphasis on practical applications of statistical software in textbooks and teaching in empirical sciences, the mathematical foundations of statistical tests are often overlooked. However, curiosity often arises, especially among educators and researchers, regarding how these seemingly magical results generated by software are obtained, and there is an underlying question of whether these quick and easy results are indeed valid. The motivation of this article is to address this need by providing a comprehensible and practical approach to the CMH test.
With the CMH test, as well as the verification of its assumptions and alternatives, all calculations can be performed using statistical software. The article does not cover the need to know how to conduct the calculations semi-automatically, but focuses on unraveling the mystery of the mathematical foundation of the calculations, a mystery because the information is lost when it is systematically overlooked.
2. Statistical Hypothesis of the CMH Test
This non-parametric test, initially devised by Cochran [1] and deepened by Mantel and Haenszel [2] , was developed to test the relationship between two dichotomous qualitative variables, X and Y, while statistically controlling the effect of a third variable Z with k qualitative or ordinal categories; these categories receive the name of strata. Variable X is a factor that affects health; it is evaluated using two categories: 0 = absent or not exposed to X, and 1 = present or exposed to X. On the other hand, variable Y is the clinical outcome or diagnostic status (case), and it is also evaluated using two categories: 0 = non-case and 1 = case [1] [2] . The information of these three variables is arranged in k 2 × 2 tables of a k × 4 table. The null hypothesis holds that variable X has no effect on variable Y, which implies that the odds ratio (OR) of exposure between cases and non-cases is unitary. The alternative hypothesis states that X has an effect on Y, so that the odds ratio is not unitary. If OR is lower than 1, then X acts as a protective factor for being a case; on the other hand, if OR is higher than 1, then X acts as a risk factor for being a case [6] .
The odds of exposure for an event A are the ratio between the probability of being exposed and the probability of not being exposed: Odds(A) = P(A)/[1 − P(A)]. These oddsare calculated both between cases and non-cases. The odds ratio (OR) is the quotient between the odds of exposure in cases (numerator) and the odds of exposure in non-cases (denominator): OR = Odds(A|case)/Odds(A|non-case). An OR higher than 1 informs how many times the presence of the risk factor is more likely than its absence among cases compared to non-cases. On the other hand, an OR lower than 1 informs how many times is more likely the presence of the protective factor than its absence among non-cases compared to cases. A unitary OR shows that the exposure factor has no effect on being a case or not.
Null hypothesis (H0): OR = 1
Alternative hypothesis (H1): OR ≠ 1
3. CMH Test Assumptions
The test requires two dichotomous qualitative variables X and Y. The variable X is supposed to be a risk factor or a protection factor for health, and is measured or evaluated through two categories: exposed and unexposed. Variable Y is a health outcome (be it a disorder, syndrome, or disease), also evaluated through two categories (case vs non-case) assumed to be affected by or dependent on X. There is also a polytomous variable Z, with k qualitative or ordinal categories, that acts as a confounding variable in the relationship between X and Y. Thus, k independent random samples of paired data of X and Y, drawn from the strata or population groups defined by the variable Z, are required. Furthermore, assuming homogeneity across the ORs of the k strata, the effect of X on Y is estimated by the common odds ratio across the k strata.
In order to apply the CMH test, the raw OR of each table, the common OR (the adjusted OR for the stratification variable Z), and the Cochran’s Q test statistic, which is a generalization of the McNemar’s test statistic, are calculated for k 2 × 2 tables [2] . Symbology is expressed in Table 1. Finally, it is necessary to verify the homogeneity of effect between the k strata or equivalence of the OR of the k 2 × 2 tables. The Woolf’s test and the Breslow-Day test with the Tarone’s correction are the most commonly used statistics to verify this assumption [6] [7] .
4. Odds Ratio across Strata
From Table 1, the odds ratio between X and Y in stratum i of the confounding variable Z, ORi, is calculated using the following probability quotient:
(1)
If the random sample drawn from a population stratum is large, the significance of each ORi can be tested and a confidence interval can be estimated from its distributional convergence to a standard normal distribution. Nevertheless, in order to facilitate this convergence, a natural logarithmic transformation is applied [8] .
Statistical hypotheses:
Test statistic and its asymptotic sampling distribution (Table 1):
(2)
(3)
(4)
Decision based on the critical value (z1−α/2) or the critical level (p-value) in a two-tailed test:
z1−α/2 = critical value or quantile of order 1 − α/2 of a standard normal distribution N(0, 1). If α = 0.05 (conventional significance level), z0.975 = 1.96.
P(Z ≤ z) = FZ(z) = value of the cumulative distribution function or cumulative probability of a standard normal distribution.
![]()
Table 1. Joint and marginal frequencies of X and Y in group or stratum i of Z.
Note. X ={0 = not exposed, 1 = exposed} = factor that supposedly generates an effect on health, Y ={0 = no case, 1 = case} = health status or outcome, Z = {1, 2, …, k} = confounding variable in the relationship between X and Y, which defines the k strata. Joint absolute frequencies in stratum i: n11i = ai = exposed cases, n10i = bi = exposed non-cases, n01i = ci = non-exposed cases, and n00i = di = non-exposed non-cases. Absolute marginal frequencies in stratum i: n1•i = n1i = exposed, n0•i = n0i = non-exposed, n•1i = m1i = cases, and n•0i = m0i = non-cases. Total stratum of i: n••i = Ti.
Confidence interval at (1 − α) × 100 of ORi:
(5)
(6)
5. Odds Ratio across Strata
The Mantel-Haenszel common odds ratio [2] can be calculated through the following ratio of sums of proportions (Table 1):
(7)
The significance of the Mantel-Haenszel common odds ratio can be tested using a Z test, as the SPSS program does [9] .
Statistical hypotheses. The null hypothesis holds that population ORMH is equal to 1, that is, variable X has no effect on variable Y across the homogenous k strata. The alternative hypothesis states that population ORMH is not equal to 1 and, consequently, variable X has effect on variable Y.
Assumptions: 1) X is a dichotomous qualitative variable that plays the role of predictor or independent variable; 2) Y, also a dichotomous qualitative variable, serves the role of dependent variable; 3) there are k independent strata defined by the qualitative or ordinal categories of a confounding variable Z; 4) there exists a random sample of paired data from X and Y in each stratum; and 5) the odds ratios are homogeneous across the k strata.
The Z-test statistic and its asymptotic sampling distribution: A natural logarithmic transformation is applied to the Mantel-Haenszel common odds ratio.
(8)
The asymptotic standard error of the log-transformed Mantel-Haenszel common odds ratio is estimated through the formula given by Robins, Breslow, and Greenland [10] .
(9)
The quotient between the log-transformed Mantel-Haenszel common odds ratio (numerator) and its standard deviation or error (denominator) constitutes the Z test statistic that converges, in distribution, to a standard normal distribution.
(10)
Decision and confidence interval. The decision on H0 can be taken based on the critical value (z1−α/2) or the critical level (p-value) in a two-tailed test.
For calculating the confidence interval at (1 − α) × 100 for the Mantel-Haenszel common odds ratio, first, the lower and upper limits of the log-transformed ORMH are obtained, using the Wald’s method [11] ; next, the transformation is undone in order to arrive to the Mantel-Haenszel common odds ratio limits.
(11)
(12)
6. CMH Q Statistic
The Q statistic is a quotient. Its numerator is the square of the difference between the sum of exposed cases in each stratum and the sum of the expected values under the assumption of independence for these frequencies. Its denominator is the sum of the variances of the frequencies in each stratum under the assumption of independence. The higher the numerator is with respect to the denominator, the higher the relationship between the two dichotomous variables [2] [6] .
 (13)
(13)
The Q test statistic converges to a chi-square distribution with 1 degree of freedom; guarantee of an adequate convergence includes: frequencies expected under the null hypothesis of independence (
) higher than or equal to 5, absence of any null observed joint frequency, and totals (Ti) higher than 25 in each stratum. In order to improve the convergence to a chi-square distribution with one degree of freedom, it is recommended to apply the Yates’ correction; the reason for implementing this controversial correction is the need to smooth the transition from a discrete binomial distribution to a continuous chi-square distribution [12] .
(14)
Decision based on the critical value or critical level in a right-tailed test:
= critical value or quantile of order 1 − (α/2) of a chi-square distribution with one degree of freedom.
= probability value to the right tail of a chi-square distribution with one degree of freedom.
It should be noted that Mantel and Haenszel [2] , had previously presented a formula to define the confidence interval of the common odds ratio, but it is less efficient and precise, especially with small samples [10] .
(15)
7. Effect Size
The magnitude of the effect size for the CMH test is the common OR that estimates the effect of X on Y and, for interpretation, it can be transformed into a Cohen’s d with Chinn’s formula [13] . Values of d lower than 0.2 reflect an effect size that is trivial, from 0.2 to 0.49 is small, from 0.5 to 0.79 is large, and higher than or equal to 0.8 is very large (Cohen, 1988).
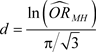 (16)
(16)
8. Tests of Homogeneity of Odds Ratios
In order to avoid overextending this manuscript, only the two most widely used tests for testing the assumption of homogeneity between ORs will be presented, namely: Woolf’s (1957) test and Breslow-Day test (1980) with Tarone’s (1985) correction. Nevertheless, it should be noted that there exist more tests, such as those developed by Bliss; Zelen; Yusuf, Peto, Lewis, Collins, and Sleight; Liang and Self; and Kulinskaya and Dollinger [14] [15] [16] . These last two are especially recommended for small samples [17] .
8.1. Woolf’s Test
Woolf’s test is one of the first tests developed for assessing homogeneity of ORs. Woolf’s method is based on a statistic first introduced by Cochran [1] and it aims to test the assumption of homogeneity of ORs for k independent strata from 2 × 2 tables (effect of a dichotomous variable X on a dichotomous variable Y). The calculation of Woolf’s statistic is simple and its small sample performance is better than that of other tests [7] ; it is available in programs such as Real Statistics Resource Pack for Excel [18] and R software package for statistical analysis [19] .
Assumptions: 1) a random sample composed of, at least, 25 participants in each stratum; 2) two dichotomous qualitative variables: one is the independent or antecedent variable X and the other is the dependent or consequent variable Y; and 3) a polytomous variable Z that generates the k independent strata in the 2 × 2 tables and that acts as a confounding variable in the relationship between X and Y [20] .
Test statistic:
(17)
(18)
(19)
(20)
Sampling distribution and decision based on the critical value or critical level in a right-tailed test:
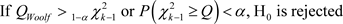
8.2. Breslow-Day Test Using Tarone’s Bias Correction
The Breslow-Day test requires large samples in each stratum, and is not adequate to use it with small sample sizes (n < 20). Its test statistic is consistent, but it presents a slight bias, and that is why Tarone [5] developed a correction. Precisely, Breslow [21] recommends the use of this correction, although he points out that, when the sample size is large, the resulting change in the estimate is minimal and only perceptible beyond the third or fourth decimal place of the probability value. The Breslow-Day test using Tarone’s correction is the most powerful when comparing various OR homogeneity tests, all of which are not very powerful with small strata sizes [17] . It is worth noting that the Breslow-Day test using Tarone’s correction is the most frequently OR homogeneity test included in several statistical software packages available in the market and, consequently, it is the most reported OR homogeneity test in research articles [7] .
The omnibus formulation of hypotheses and assumptions of the Breslow-Day test, with or without the Tarone’s correction, are the same as in the Woolf’s test; nevertheless, its asymptotic approximation to the chi-square distribution with k − 1 degrees of freedom is better when Tarone’s correction is used.
Breslow-Day test statistic is a goodness-of-fit test. The expected absolute frequencies are calculated under the assumption of a common OR estimated by the formula of Mantel and Haenszel [2] .
(21)
ai = n11i = absolute (joint) frequency of exposed cases in stratum j.
bi = n10i = absolute (joint) frequency of exposed non-cases in stratum j.
ci = n01i = absolute (joint) frequency of non-exposed cases in stratum j.
di = n00i = absolute (joint) frequency of non-exposed non-cases in stratum j.
ORMH = common odds ratio of k strata estimated through Mantel-Haenszel method
E(ai|ORMH) = expected value for the number of exposed cases in stratum j conditioned on ORMH. This value is obtained upon solving the following quadratic equation:
(22)
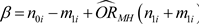
(23)
Every quadratic equation has two solutions. In this case, the solution in the set of real numbers with a value higher than 0 and lower than or equal to the minimum of m1i and n1i is chosen. The expected values are not rounded to integers, but are handled with their decimal places.
Once the expected frequency of the exposed cases, E(ai|ORMH), is estimated, the other expected frequencies can be obtained under the condition of a common odds ratio (ORMH).
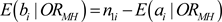 (24)
(24)
(25)
(26)
Next, taking into account the expected values E(ai|ORMH) of each stratum, the Mantel-Haenszel common odds ratio (1959) can be calculated, and this allows checking that there are no errors in the calculation of the expected frequencies, as the ORMH value is already known.
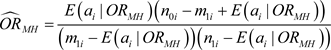 (27)
(27)
The squares of the differences between the observed and expected frequency within each stratum are equal.
Likewise, the variances of the frequencies conditioned to a common odds ratio ORMH coincide within each stratum, and they are obtained through the following formula:
(28)
Thus, the Breslow-Day statistic can be simplified to the following formula with k addends:
(29)
Tarone’s correction for the Breslow-Day statistic involves subtracting from the QBD a quotient whose numerator is the square of the difference between the sum of the exposed cases and the sum of their expected values conditioned to the Mantel-Haenszel common odds ratio, whereas its denominator is the sum of the variances of the exposed cases conditioned to the Mantel-Haenszel common odds ratio; hence, once the data for the QBD calculation are available, its correction is very simple.
(30)
(31)
(32)
Sampling distribution and decision based on the critical value or critical level in a right-tailed test:
9. Unfulfillment of the Assumption of Homogeneous Effect in the k Strata
In the event that the null hypothesis of equivalence of the odds ratio between the k strata is rejected, it is necessary to identify which strata are homogeneous and which strata are heterogeneous in order that the CMH test can be applied to the homogenous ones, and the effect size can be reported either by strata groups or individual strata.
Pairwise comparisons can be made with a Z test [7] with the Holm-Bonferroni or Holm-Sidak correction in order to control the increase in type-1 error or with the Benjamin-Hochberg correction in order to control the false discovery rate [22] .
Statistical hypotheses:
Test statistic:
(33)
Decision based on the critical value or critical level in a two-tailed test:
Given k independent groups, the number of pairwise comparisons corresponds to combinatorics without repetition: k of 2, C(k, 2), which means m = k(k − 1)/2 comparisons. To make the Holm-Bonferroni correction, the probabilities are ordered ascendingly: an order value (i) equal to 1 is assigned to the smallest probability, an order value (i) equal to 2 is given to the second smallest probability, and so on until assigning a value equal to m to the highest probability; in the event that two or more probability values are repeated, an average order value is assigned (sum of the corresponding orders divided by the number of added orders). Next, the significance level α (usually 0.05) is divided by m + 1 − i, thus obtaining the corrected significance level:
. In the Holm-Sidak correction, the corrected significance level is:
. The Benjamini-Hochberg corrected significance level is:
[22] . See an example with four independent groups (Table 2).

A more general test than the CMH test is conditional logistic regression. This multivariate technique can include more than one antecedent or predictor variable, whether qualitative (dichotomous, polytomous, ordinal) or quantitative (discrete or continuous). When conditional logistic regression handles a single dichotomous predictor, apart from the confounding variable that defines k strata, the score test statistic corresponds to the CMH Q statistic [20] . Being θ the estimated regression parameter or weight, the score test statistic, denoted by S(θ), is the quotient between the derivative in θ of the natural logarithm of the likelihood function ln(θ|x) and the Fisher information about the parameter θ. The statistic, in this one-parameter situation, follows a chi-square distribution with one degree of freedom, as the CMH Q statistic does.
Conditional logistic regression was developed in 1978 by Breslow, Day, Halvorsen, Prentice, and Sabai [23] . When data for the predicted dichotomous variable and predictors are recorded by stratum, this technique has a clear
![]()
Table 2. Holm-Bonferroni, Holm-Sidak, and Benjamin-Hochberg corrections for a significance level α at 0.05 and four compared groups.
advantage over unconditional logistic regression, especially when there are many small strata sizes, such as the extreme case of paired data or n/2 strata of size 2. Logistic regression includes the confounding variable that generates the k strata as one more predictor, and estimate location parameters for each of its k strata. Nevertheless, conditional logistic regression does not require calculating these parameters and achieves more efficiency in its estimates and power, which becomes more evident as the number of strata increases [4] .
Conditional logistic regression is available in the R statistical software using the “clogit” function in the survival package. It is located in this package because the log-likelihood of a conditional logistic model is the same as the log-likelihood of a Cox model with a paired or stratified data structure [24] .
10. Simulated Example of the Application of the CMH Test
In order to see a more realistic example, a feasible study in epidemiology is presented. A sample composed of 2000 Mexican males from 0 to 14 years old (pediatric population) was collected and classified into two groups: 1 = case of bronchial asthma and 0 = no case. The diagnosis of unspecified uncomplicated bronchial asthma (CA23.32) was made by pediatricians from public health centers using the criteria of the eleventh edition of the International Classification of Diseases (ICD-11) of the World Health Organization [25] . The exposure factor was established based on indoor smoking of tobacco at home by parents and other adults who reside with the minor: 1 = daily exposure to tobacco smoke at home and 0 = no exposure to household tobacco smoke. Tobacco is understood as any product processed from the leaves of the plant known as Nicotianatabacum, such as cigarettes, cigars, or pipe tobacco. Of the 2000 participants, 595 lived in an urban location with good air quality most days of the year, 1007 in a location with usually acceptable air quality, and 398 with usually poor air quality, according to the official Mexican standard: NOM-172-SEMARNAT-2019 on Guidelines to Obtain and Communicate the Air Quality and Health Risks Index [26] . The objective of the study is to verify the relation between daily exposure to tobacco smoke at home and the child’s bronchial asthma by controlling the confounding variable (air quality in the urban area of residence) in males aged 0 to 14 years using the CMH test [2] [6] with a significance level at 5%. In case of positive association, the effect size with the Mantel-Haenszelcommon odds ratio [2] is estimated. Also, the assumption of homogeneous odds ratio across the three strata is tested by the Woolf’s test [3] and Breslow-Day test with the Tarone’s correction [5] with a significance level at 5%.
Table 3 shows the three 2 × 2 contingency tables stratified by the confounding variable (air quality in the urban area of residence) of the pediatric participants (0 to 14 years of age). The three strata are good, fair, and poor air quality most days of the year. The two crossed dichotomous variables are: X = daily exposure to tobacco smoke at home = {0 = no, 1 = yes} and Y = bronchial asthma = {0 = no case, 1 = case}.
![]()
Table 3. Joint absolute and marginal frequencies of daily exposure to tobacco smoke at home and whether or not the participant is a case of bronchial asthma, stratifying by the confounding variable (air quality in the urban area of residence) of the participants.
Note. X = daily exposure to tobacco smoke at home = {0 = no, 1 = yes}, Y = bronchial asthma = {0 = no case, 1 = case}, Z = air quality in the urban area of residence = {1 = good, 2 = fair, 3 = poor}, ∑column = sum per column in each stratum, ∑row = sum per row in each stratumi.
The first step is to calculate the odds ratio of each stratum both in its point estimate, using Equation (1), and 95% interval confidences, using Equations(2), (3), (5), and (6). In order to facilitate these calculations, Table 4 has been created. The significance of each OR is calculated with the Z-test (Equation 4), and the effect size in each stratum with the OR transformed into a Cohen’s d with Chinn’s formula [13] that appears in the Equation (16).
Let Z be the confounding variable, that is, air quality in the urban area of residence of the participant: Z = {1 = good, 2 = fair, 3 poor}.
The OR for strata 1 (good air quality) and 2 (fair quality) are significant with a significance level at 5%, since they do not include the value 1 when they are estimated with a confidence level at 95%, and the two-tailed probability-values of their Z-test statistics are lower than the α significance level of 0.05. They reflect a small effect size (0.2 ≤ d < 0.5) and a detrimental or health risk effect (OR > 1). The OR of stratum 3 (poor air quality) is not significant at significance level equal to 0.05 and shows a trivial effect size (d < 0.2). Nevertheless, the 95% confidence intervals of the three OR overlap, so that they seem to be equivalent from this first analysis, and the significant, small, and detrimental effect that daily exposure to tobacco smoke at home has on bronchial asthma in pediatric male patients remains unclear.
![]()
Table 4. Joint frequencies between X and Y, and total for each air quality stratum.
Note. ai = n11i = exposed cases in each stratum i, bi = n10i = exposed non-cases in each stratum i, ci = n01i = non-exposed cases in each stratum i, di = n00i = non-exposed non-cases in each stratum i, Ti = n••i = total participants in each stratum or sum per row (i from 1 to 3), ∑i = sum by column i from 1 to 3.
The second step is to calculate the common odds ratio for the three strata using the Mantel-Haenszel formula [2] . Firstly, Mantel-Haenszel point estimate is calculated using Equation (7).
Secondly, the 95% confidence interval for the Mantel-Haenszel common OR (ORMH) is calculated by applying a logarithmic transformation upon ORMH, as shown in the Equation (8); next, the asymptotic standard deviation of the natural logarithm of ORMH is computed [10] , as in Equation (9); then, the lower and upper limits for the log-transformed ORMH are obtained using the Wald’s method [11] , as in Equation (11); and lastly, the logarithmic transformation is undone in order to obtain the limits for the ORMH, as in the Equation (12).The effect size, which turns out to be small, is calculated with Equation (16), which transforms an OR into a Cohen’s d.
Using the logarithmic transformation of the ORMH and its standard deviation, the significance of the effect of X on Y can be tested with a Z test, just as it was done with the odds ratio in each one of the three strata [10] . See Equation (10). In a two-tailed test with a significance level of 5%, the Mantel-Haenszel common OR is different from 1. Thus, exposure acts as a risk factor for being a case.
Thirdly, the CMH Q statistic is computed using Equation (13). Table 5 shows the frequencies of the exposed cases (ai), the marginal frequencies
![]()
Table 5. Frequency of exposed cases, their expected values and their variances assuming independence between X and Y.
Note. Strata or categories of the confounding variable Z = air quality in the area of residence = {1 = good, 2 = fair, 3 = bad}, X = antecedent variable: daily exposure to tobacco smoke at home = {0 = no, 1 = yes}, Y = outcome variable: case of bronchial asthma = {0 = no, 1 = yes}, ai = n11i = exposed cases in stratum i, (cases of bronchial asthma that were exposed to tobacco smoke at home in stratum i), n1i = n1•i = total of participants (with and without bronchial asthma) exposed to tobacco smoke at home in stratum i, n0i = n0•i = total of participants (with and without bronchial asthma) non-exposed to tobacco in stratum i, m1i = n•1i = total cases of bronchial asthma in stratum i, m0i = m•0i = total of non-cases (participants without bronchial asthma) in stratum i, Ti = n••i = total number of participants in stratum I, ei = (n1i × m1i)/Ti = expected number of ai under the assumption of independence between X and Y,
= variance of ai under the assumption of independence between X and Y.
(n1i, n0i, m1i, m0i) and the total (Ti) in each stratum. With these data, the expected value, ei, and the variance of the exposed cases in each stratum,
, are calculated under an assumption of independence between X and Y.
The null hypothesis regarding of unitary OR is rejected with the Q statistic without the Yates’ continuity correction. The latter statistic is calculated using Equation (14).
Owing to the use of an asymptotic approximation of a discrete distribution to a chi-square distribution with one degree of freedom, it is advisable to use the Yates’ correction. Nevertheless, considering that the sample size is large, the difference between the statistics without or with continuity correction is minimal, QCMH = 9.6495,
and
, 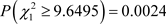 , respectively.
, respectively.
Likewise, because the sample size is large, when the confidence interval of the common odds ratio is calculated with the Mantel-Haenszel formula [2] , as shown in the Equation (15), 95% CI [1.1814, 2.1663], the result is very similar to that obtained with the formula given by Robins et al. [10] , as shown in the Equation (12), 95% CI [1.1882, 2.1540]. The latter is more efficient and accurate; however, this difference becomes evident especially when the sample is small.
Next, the assumption of homogeneity of the OR across the three strata is tested using the Woolf’s test [3] , as shown inin Equation (17). The required calculations for this test are presented in Table 6, which includes the odds ratios (ORi), the logarithmic transformations of these odds ratios (ln(ORi)) using Equation (18), and the variances of the logarithms of the odds ratio for each stratum (s2[ln(ORi)]) using Equation (19). The natural base exponential of the quotient between the sum of the three quantities in the fifth column of Table 6 and the sum of the three quantities in the sixth column of the same table yields the common odds ratio, calculated with Equation (20).
![]()
Table 6. Odds ratio by stratum and calculations for Woolf’s test.
Note. Strata or categories of the confounding variable Z = AQ = air quality = {G = good, F = fair, P = poor}, ORi = odds ratio of stratum i, ln(ORi) = natural logarithm of the odds ratio of stratum i, s2[ln(ORi)] = variance of the natural logarithm of the odds ratio of stratum i, ln(ORi)/s2[ln(ORi)] = quotient between the natural logarithm of the odds ratio of stratum i and its variance, 1/s2[ln(ORi)] = inverse of the variance of the natural logarithm of the odds ratio of stratum i, [ln(ORi) − ln(OR)]2/s2[ln(ORi)] = quotient between the square of the difference between the natural logarithm of the odds ratio of stratum i and the natural logarithm of the common odds ratio (numerator) and the variance of the natural logarithm of the odds ratio of stratum i (denominator), ∑i = sum per column (i from G toP).
The sum of the three quantities in the sixth column of Table 6 yields the Woolf’s Q test statistic. Each of these three quantities is the quotient between the square of the difference between the natural logarithm of the odds ratio of each stratum and the natural logarithm of the common odds ratio (numerator) and the variance of the natural logarithm of the odds ratio of each stratum (denominator), as shown in Equation (17).
The value of the test statistic Q is small and lower than the quantile of order 0.95 of a chi-square distribution with two degrees of freedom (k − 1 = 3 − 1 = 2); thus, the null hypothesis of equality of effect across the three strata is hold.
Finally, the assumption of homogeneity of the effect across the three strata is tested by Breslow-Day test with Tarone’s correction [5] , as shown in Equation (21). As in the case of the Woolf’s test,
,
, the null hypothesis of equivalent odds ratio across the three strata is fulfilled. Because the samples per stratum are large, the difference of the Breslow-Day test in regard to Woolf’s test is very small, QBD = 1.270705,
, and it becomes minimal upon applying the Tarone’s correction, QBDT = 1.270382,
.
The computation of the Breslow-Day test statistic starts with the calculation of the expected value, E(a1|ORMH), using Equation (23), and the variance of the number of exposed cases in relation to the Mantel-Haenszel common OR in the first stratum, s2(a1|ORMH), using Equation (28). In order to obtain the expected value E(a1|ORMH), it is necessary to pose a quadratic equation that should be solved, which is shown in Equation (22). The joint and marginal frequencies observed for stratum 1 (good air quality) are reproduced in Table 7 in order to facilitate the follow-up of the calculations.
The expected value of a1 (exposed cases from the first stratum) conditioned to the common OR estimated by the Mantel and Haenszel formula [2] , upon having solved the quadratic equation and chosen a result within the range of 0 to 93 (minimum value for n11 and m11), is equal to 77.8904. It can be verified that this expected frequency is close to the observed one, which is equal to 80.
![]()
Table 7.Joint and marginal frequencies of stratum 1 (good air quality).
Note. X = exposure to indoor tobacco smoke at home, Y = bronchial asthma in pediatric minors. ∑j = sum per rows (j = 0 and 1), ∑i sum per columns (i = 0 and 1).
With E(a1|ORMH), the expected values for the other three cells of the 2 × 2 table of the first stratum are computed. The expected frequencies are close to the observed ones, namely: b1 = 381, c1 = 13, and d1 = 121. These calculations correspond to Equations (24), (25), and (26).

The sum of the four expected frequencies is equal to the total of 595 participants in the first stratum, and it can be verified that the expected frequency for a1 allows to correctly obtain the ORMH. See Equation (27).
The variance of the exposed cases, conditioned to the common OR estimated by the formula of Mantel and Haenszel formula [2] in the first stratum, is equal to 11.1058. See Equation (28).
We proceed in the same way with the calculation of the expected value and the conditioned variance to the common OR of the exposed cases in the second stratum. The observed joint and marginal frequencies of stratum 2 (fair air quality) are shown in Table 8.
The expected value of a2 (exposed cases from the second stratum) conditioned to the Mantel-Haenszel common OR [2] in Equation (23), upon having solved the quadratic Equation (22) and chosen a result within the range of 0 to 171 (minimum of n12 and m12), is equal to 143.9868. As it happened in the first stratum, this expected frequency is close to the observed one, which is equal to 145.
The expected frequencies for b2, c2 and d2 are also close to the observed ones, which are equal to 642, 26, and 194, respectively. These calculations correspond to Equations (24), (25), and (26).
![]()
Table 8. Joint and marginal frequencies of stratum 2 (fair air quality).
Note. X = exposure to indoor tobacco smoke at home, Y = bronchial asthma in pediatric minors. ∑j = sum per rows (j = 0 and 1), ∑i sum per columns (i = 0 and 1).
The sum of the four expected frequencies is equal to the total of 1007 participants in the second stratum, and it can be verified that the expected value of a2 allows to correctly obtain the ORMH. See Equation (27).
The variance of the exposed cases, a2, conditioned to the common OR estimated by the Mantel and Haenszel formula [2] in the second stratum, is equal to 19.7235. See Equation (28).
Finally, the expected values and the variance conditioned to the common OR of the cases exposed in the third stratum are calculated. The observed joint and marginal frequencies of stratum 3 (poor air quality) are shown in Table 9.
The expected value of a3 (exposed cases from the third stratum) conditioned to the Mantel-Haenszel common OR [2] in Equation (23), upon having solved the quadratic Equation (22) and chosen a result within the range of 0 to 86 (minimum of n13 and m13), is equal to 65.2416. As in the first and second strata, this expected frequency is close to the observed one, which is equal to 62.
![]()
Table 9. Joint and marginal frequencies of stratum 3 (poor quality).
Note. X = exposure to indoor tobacco smoke at home, Y = bronchial asthma in pediatric minors. ∑j = sum per rows (j = 0 and 1), ∑i sum per columns (i = 0 and 1).
The expected frequencies for b3, c3, andd3 are also close to the observed ones, which are equal to 210, 24, and 102, respectively. These calculations correspond to Equations (24), (25), and (26).
The sum of the four expected frequencies is equal to the total of 398 participants in the third stratum, and it can be verified that the expected value of a3 allows to correctly obtain the ORMH. See Equation (27).
Once the expected values of the four frequencies of each stratum and the variances of the exposed cases with regard to the common OR of each stratum are available, the Breslow-Day Q test statistic [4] can be calculated, as shown in Equation (21). This statistic can be calculated using two formulas. The first formula is a chi-square goodness-of-fit statistic and it needs the expected values for the four frequencies of each stratum. See Table 10. See Equation (28).
![]()
Table 10. Joint frequencies observed in the three strata, expected frequencies, and variances conditioned upon the assumption of a common OR estimated by the Mantel-Haenszel formula.
Note. Zk = confounding variable with three ordinal categories = air quality in the place of residence (k: 1 = good, 2 = fair, and 3 = poor), Xi = exposure with two categories (i: 0 = no and 1 = yes), Yj = bronchial asthma in pediatric minors with two categories (j: 0 = non case and 1 = case), Oijk = joint absolute frequency of category i of X and category j of Y in stratum k of Z, Eijk = expected absolute frequency conditioned to a common odds ratio estimated by the Mantel-Haenszel formula, (Oijk − Eijk)2 = square of the difference between the observed and expected probability, (Oijk − Eijk)2/Eijk probability divided by the expected frequency, s2(Oijk|) = Var(Oijk|ORMH) = variance of the observed frequencies conditioned to a common odds ratio estimated by the Mantel-Haenszel formula, (O − E)2/s2 = (O11k − E11k)2/Var(O11k|ORMH) = quotient between the square of the difference between the observed frequency and the expected frequency of the exposed cases (numerator) and the variance of the exposed cases conditioned to a common odds ratio estimated by the Mantel-Haenszel formula (denominator), ∑ = sum per column.
The second formula, given in Equation (30), is a simplified form of the first one, shown in Equation (21), considering that the squares of the differences between the observed and expected frequency for each stratum are equal, as well as the variances conditioned to a common odds ratio. This second formula needs the expected frequencies of the exposed cases of the three strata and their variances conditioned to the Mantel-Haenszel common OR. This mathematical expectation is calculated with Equation (31) and the variance is calculated with Equation (32). See Table 10.
The Breslow-Day statistic with Tarone’s correction [5] undergoes a minimal change than without correction. See Equation (30), (31), and (32).
11. Statistical Power and Type-2 Error
When rejecting the null hypothesis, it is important to also report the statistical power or probability of rejecting the null hypothesis conditional on it being false (ϕ). One way to calculate power is by the complement of the cumulative distribution function of the noncentral chi-square distribution or right-tailed probability. The degrees of freedom are 1 (gl = 1). The non-centrality parameter is the value of the test statistic: PNC = QCMH. This function is evaluated at the critical point:
. If the null hypothesis is accepted, the type-2 error or probability of maintaining the null hypothesis conditional on it being false (β) is calculated, which is the probability at the left tail of the previously defined no-central distribution.
Returning to the example in which the null hypothesis of no effect was rejected and using the QCMH statistic with the Yates’ correction, the statistical power is high:
12. Conclusions
Based on the analyses conducted on the simulated and realistic data presented in this study, it can be concluded that exposure to indoor tobacco smoke at home has a detrimental effect on bronchial asthma in pediatric males, when statistically controlling for the confounding variable of air quality in the urban area where the participants reside. The effect size of tobacco smoke is small, ORMH = 1.60, d = 0.26, and its effect is homogeneous across the three strata: good, fair, and poor air quality. Exposure is 1.6 times more likely than non-exposure in males 0 - 14 years of age who suffer bronchial asthma compared with age-matched males without bronchial asthma. The implication that would follow from these results is that community preventive campaigns and pediatric interventions should focus on or take into account this health risk, namely smoking by parents or adults in the home. On the other hand, the confounding variable also has a significant effect, making air quality another health issue to be addressed by health authorities. These conclusions are similar to those obtained by Paciência, Cavaleiro-Rufo, and Moreira in a review study [27] .
As has been done in this study, it is important to check the assumptions of the test, calculate the statistical power in case the null hypothesis of no effect is rejected or the type-2 error in case it holds, report the effect size in case the Mantel-Haenszel common OR is non-zero, and adjust for the limitations involved in using qualitative variables, one dichotomous as antecedent, another dichotomous as an outcome, and a third statistically controlled polychotomous variable. A broader alternative to the CMH test is conditional logistic regression. This latter statistical technique is used to analyze the relationship between a dependent variable and independent variables in matched or clustered data. It accounts for within-set dependencies and allows for controlling confounding factors. It estimates the odds ratio and uses maximum likelihood estimation to estimate regression coefficients, providing a valuable tool for analyzing matched or clustered data while controlling for confounders.
Acknowledgements
The authors thank the reviewers and editor for their helpful comments.