1. Introduction
Cryptocurrency is a virtual or digital currency secured through cryptography; hence it is safe from counterfeit [1] . Blockchain technology has been used in a decentralizing cryptocurrency network. It is not issued by the government, thus immune from interference and manipulation by the central banking system in a country according to [2] . This currency is mostly used as a medium of exchange in online trading where digital ledgers are applied. There is a need for strong cryptography in securing transaction record entries. The transactions do not exist physically, and the individuals involved may not know each other physically [3] . Bitcoin which was the first cryptocurrency, released in 2019 by open-source software, has consistently been used in many countries. It is still famous; however, various alternative coins have been created afterward, with some being bitcoin clones or forks. Litcoin, Namecoin, Peercoin, and Cardano are some of Bitcoin’s competing cryptocurrencies. To model and measure the dependencies in cryptocurrencies, the study proposed the use of copulas where copulas have been distinguished in different families namely, Elliptical copulas, Archimedean copulas, Empirical copulas and Periodic copulas. Each family has different types of copulas depending with the distribution of the functions [4] . Copulas is relevant in finance mainly in portfolio management, risk management, derivative pricing and optimization.
The autoregressive conditional heteroscedastic (ARCH) model [5] and generalized conditional heteroscedastic (GARCH) model that was stated by [6] have been used widely financial time series to model return variance processes. It has been observed that financial time series data exhibit heavy tails and extreme value theory (EVT) has been established as a useful tool in modelling tail behaviour of the distribution instead of the entire distribution. Extreme events study is key in financial risk management mainly to investors since it gives rare events that have catastrophic effects which may comprise of extreme default losses, market crashes and currency crisis. This GARCH-EVT combination has an advantage of being able to capture conditional heteroskedasticity in the given data through the GARCH framework, and at the same time apply EVT method to model the extreme tail behaviour. Linear correlation has been used as a measure of dependence for multivariate variable while calculating the dependence between different asset returns. Gaussian, log-normal and Student-t are multivariate distributions that have been widely used. However, they cannot be applied in the case of assymetrical data. Copulas provides a solution in addressing dependence structure problem, and it offers flexibility unlike correlation approach [7] , hence providing an opportunity for one to examine separately marginal distributions from random variables dependency structures.
This study’s primary objective is to fit the most appropriate GARCH model in modelling cryptocurrencies data, examine the dependence structure of Cryptocurrencies using Copula GARCH model and select a portfolio of cryptocurrencies with the best optimization. Therefore, this study’s main contribution was to model cryptocurrency and selection of the cryptocurrency with the best optimization using Copula standard Garch model.
The paper is organized as follows: Section 2 describes the methods of the study; Section 3 presents main results, simulation study results; Section 4 presents conclusion and suggestions for further research.
2. Methods
2.1. The ARMA-Model
ARMA models can be used in modeling trends and seasonality in time series data. They are mostly constructed on white noise basis whose variance is denoted as
. These models belong to a class of stationary univariate time series models which is utilized in a time series to capture (linear) serial dependence. These combines the two classes of time series models, namely; moving average (MA) process and autoregressive process (AR) that results in a parsimonious polynomial model which combines both moving averages and autoregressive models.
Definition The ARMA(p, q) process Let
for some,
be a white noise sequence on
. Let
and
and
. Then we have any stationary time series
on
satisfying
and
(1)
being an ARMA(p, q) process whose mean
,having
as an ARMA(p, q) process,
. We can write Equation (1) in compact notation that is based on the backshift operator which is given as follows
(2)
where
is given as the “autoregressive polynomial of degree p” and we have
given as the “moving average polynomial of degree q”. One can either use only the moving average or the autoregressive part of a given ARMA equation.
Definition (AR(p)-process)
In Equation (1), let q = 0 thus
. Hence the equation can be simplified to
Given that p = 1, then we have the AR(1)-process
Theorem 3.1. Given that
with
, then we have the ARMA model as given in Equation (1) having unique stationary solution
(3)
where we can determine the coefficients
by
(4)
for any
Definition(MA(q)-process) In Equation (1), let p = 0 and hence
. The equation then simplifies to
For q = 1, then we get the MA(1)-process
2.2. The GARCH-Model
The Generalized Autoregressive Conditional Heteroskedasticity (GARCH) model which was introduced by [6] is a generalized form of the ARCH models which was introduced by [5] . The Autoregressive (AR) process considers observations made in the past up to a given degree into the present and utilizes a feedback mechanism. GARCH model “conditional component” implies variance dependence on immediate past, while “heteroscedasticity” implies time varying volatility. A standard ARCH(p) process that has p lag terms and is designed to capture volatility clustering which can be expressed as
(5)
where
and
, for
which ensures finite variance and we have
in stationarity. Large persistence in volatility leads the ARCH model to require a large number of lags p which can be used to fit the data.
Definition GARCH(p, q) The stochastic process
on a probability space
where
is given by a GARCH(p, q) process if it gives a solution to
with
being an iid sequence and the conditional variance of a GARCH(p, q) being
(6)
The GARCH model parameters must satisfy the following conditions in order for conditional variance to be finite and positive
,
and
for
Different versions and extensions have been made on GARCH model. Equation (6) gives a symmetric model which implies positive and negative shocks have the similar volatility effects. However, positive (negative) innovations to volatility have been suggested to correlate with negative (positive) innovations to returns by empirical literature.
We intend to consider two extensions of the standard GARCH model in order to account for leverage effects and symmetry [8] gave a proposal of a Boolean indicator being introduced in the GARCH Equation (6). We get the GJR-GARCH model conditional variance being given by
(7)
where we have
given that 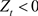 and it is 0 if
.
and it is 0 if
.
The term
also captures the shock in addition to the symmetrical GARCH(p, q) model which is given in (6). GJR-GARCH model is normally used to nest the standard GARCH model by equating all the gi coefficients to zero, hence reducing the GJR-GARCH model to the standard GARCH model.
and
parameters are constrained to be non-negative in order to ensure positivity and stationarity of the GARCH specifications. Non-negativity constraints are too restrictive as argued by [9] , this advocated inclusion of asymmetric volatility response to innovations with the EGARCH model in Nelson’s exponential GARCH model, it is given as
(8)
Parameters
with negative
is used to capture asymmetry, higher impact on valatility are experienced in negative shocks than positive shocks. Marginal distributions of standardized residuals
should be specified in order to complete univariate model specification.
2.3. Copulas and Dependence Structure
2.3.1. Definition of Copulas and Its Properties
Definition Let C be a copula of a multivariate PDF which is defined on
, while its variables marginal probability distribution are uniformly distributed in [0, 1] [10]
Definition For a 2-dimensional copula we have a function
, which fulfils:
1) For every
:
2) For every
:
3) For every
with
and
and
:
Functions fulfilling the first property are referred to as grounded. Implying, that for both outcomes the joint probability is zero given that the marginal probability of either outcome is zero. The second property is known as the copula boundary condition while the third property is known as two-dimensional analogue for a function that is one-dimensional and non-decreasing. Such a function is called 2-increasing.
The theorem presented next establishes the continuity of copulas via a Lipschitz condition on
:
Theorem 1 Let C to be a copula. Then we have that for every
(9)
Theorem 2 Let C to be a copula. Then we have that for every
. We have the partial derivative
a existing in almost all
. Given that a and b, one exists for almost all
. having a and b one has
(10)
The partial derivative analogous statement is true for
. In addition, we have the function
and
on [0, 1] being defined and non-decreasing in almost everywhere .
Definition
Copula density. We let C to be a two times and two-dimensional partial differentiable copula, therefore we have the function
hence
(11)
is referred to as copula density for C
The fundamental theorem of copulas theory is key. It is stated by Sklar’s theorem [11] . Sklar’s theorem issues key properties for copulas
Lemma (Sklar’s theorem) [10]
Let
to be a two dimensional joint probability distribution function for two random variables illustrated as X1 and X2 whose marginal distributions are F1 and F2. Then we have a 2-dimensional copula C, where by
holds. For the continuous F1 and F2 and we have C as unique and defined through
Conversely, having C as a copula and marginal distribution functions F1 and F2, then we have the function F being defined in equation (iv) as a bivariate joint distribution function whose margins are F1 and F2.
From the theorem 3 the bivariate distribution density function
be written in copula form.
(12)
Copulas capture only dependency features that are invariant under increasing transformations [12] .
2.3.2. Bivariate Two-Parameter Copula Families
The families of bivariate two-parameter copula are key in capturing dependencies that are more than one such as upper and lower tail dependence or in finding dependence in one of the tails and concordance [13] .
Definition (Bivariate two-parameter copula families)
These copula families take the form
(13)
where we have K being maximal infinite divisible which we can denote as (max-id). [We have K as max-id given that for all a > 0,
is a cdf] and we have
as a Laplace-transform (LT).
Given that
and
are used to parametrize K by parameter
(denoted by
) then we result to Two-parameter families. Having K increase in its concordance as
increases, then definately there is an increase in concordance of C as
increases while we have
being fixed. It is harder to check concordance ordering,
being fixed with
varying. K taking the Archimedean copula form, then we have C taking the Archimedean copula form. That is, if
for
family, then
(14)
where
For
being fixed and
, with
the ordering of the concordance being
and
could then be established through showing that
is superadditive.
BB1-copula
The definition of BB1-copula is given by
(15)
where
We have the copula density being
(16)
We consider BB1-copula as an example of a bivariate Archimedean copula whose generator function is
.
BB7-copula
The BB7-copula, is at times considered as Joe-Clayton copula, with a similar structure as the one of the BB1-copula, The Archimedean generator function is given by
whereby it is defined as
(17)
where
Copula density is given by
(18)
In BB7-copula the lower and upper tail dependence can range on each other from zero to anywhere freely.
2.3.3. Bivariate Dependence Measures
Pearson Correlation Coefficient
Pearson’s correlation which is also referred to as correlation coefficient or product moment correlation is a measure used widely in measuring linear correlation given two random variables. Correlation and dependence can be used interchangeably.
Definition Let
to be a vector of random variables which have nonzero finite variances. Linear correlation coefficient can be defined as
(19)
The correlation coefficient properties (ρ) are
1).
2) X and Y being independent, then we have
.
3)
if
and
such that
4)
5) X and Y being joint bivariate normal distribution that have standard normal margins then we have, correlation coefficient
being uniquely defined by the existing joint distribution.
Definition The correlation coefficient can be estimated using
Linear correlation is popular due to its ease in calculations but cannot be applied as a canonical dependence measure. It is commonly used in elliptical distributions.
Kendall’s tau
Kendall’s tau for a given vector, given
is given by finding the probability of concordance in the pair of random variables minus the probability of discordance in the pair of random variables chosen in a population version which can expressed in the following definition by [7] [14] [15] .
Therefore, Kendall’s tau can simply be defined as the probability of concordance minus the probability of discordance.
Definition (Kendall’s τ) Let
and
be two pairs of independent random variables whose joint distribution, denoted as F and marginal distributions denoted as
and
. Therefore Kendall’s tau can be illustrated by
(20)
In the equation,
), is referred to as P (concordance), while,
is P (discordance). Therefore,
.
An alternative definition making use of the mathematical expectation operator, expresses Kendall’s tau as
(21)
The empirical version of this expression is
(22)
where we have
and
referring to the t-th observations in the two random vectors that have n observations.
Kendall’s tau can also be represented in terms of copula; the illustration is given as follows
(23)
Theorem Kendall’s tau for a bivariate Archimedean copula C whose generator function is given by
in one-dimensional integral can be written as [16]
(24)
2.4. Tail Dependence
Tail dependence concept is mostly applied in non-normal multivariate families, especially in financial applications. In a bivariate distribution, tail dependence can be represented by the probability of first variable exceeding its q-quantile, when the other also exceeds its own q-quantile. Upper tail dependence coefficient is the limiting probability as q goes to infinity, where we have the copula as the upper tail dependent given that it is not zero. The lower tail dependence is said to be analogously defined. The implication is that given two continuous random variables X and Y, then the tail dependence is a copula property and whose amount of tail dependence will be invariant given strict increasing transformations of X an Y [17] .
Definition (Tail dependence) Let
to be a vector for continuous random variables whose marginal distribution functions denoted as F and G. The upper tail dependence coefficient
of
is therefore the limit of the conditional probability for Y being greater than the a-th percentile for G given that we have X being greater than the a-th percentile for F as a approaches 1, i.e.
(25)
provided that limit
exists. If
, X, Y are asymptotically dependent in upper tail; if
, X and Y are asymptotically independent in upper tail. Similarly the lower tail dependence,
.
(26)
Definition (Upper tail dependence for copulas)
The coefficient for upper tail dependence of the given bivariate copula family denoted as C is such that
(27)
Then C has a lower tail dependence if we have
, and is lower tail dependence if
.
Coefficients of upper and lower tail dependence in bivariate margins are needed to show the difference in two-dimensional Student and Gaussian copulas.
Given X and Y are continuous random variables with Student-t copula, C and the parameters
and
, hence the coefficients of the two tail dependence are equal and they are given by:
where we have
denoting the univariate Student-t distribution function that has
degrees of freedom and the value of
is seen to depend on parameters with Student-t-copula has both the lower and upper tail dependence.
In contrast, the Gaussian copula does not have the tail dependence at all; there is neither lower nor upper tail dependence. Hence the Gaussian copula which has parameter
, thus the tail dependence is given by
Therefore there is no tail dependence in the Gaussian copula.
Tail dependence in the Archimedean copulas can be expressed in form of generator function.
Theorem Let a strict generator be
such that
is seen to belong in the class of Laplace transformation for random variables that are strictly positive. If
being finite then we have
The upper tail dependence does not exist. If copula C has upper tail dependence,
and the upper tail dependence coefficient is given by
(28)
The proof is seen in [7] [18] .
Theorem Letting
as denoted in Theorem The lower tail dependence coefficient for copula
is equal to
(29)
2.5. Copula Parameter Estimation
Full Maximum Likelihood (FML)
The representation of canonical copula is
(30)
Let the sample data matrix be
. Then the log-likelihood function is given by
(31)
where the set of marginal parameters and the copula are given as
. Therefore, with a copula and marginal density probability function set the maximum likelihood estimator is obtain through maximization
(32)
Holding the usual regulatory conditions, then the maximum likelihood estimator being asymptotically efficient and consistent, with the covariance matrix being asymptotically normally distributed given Fisher’s information matrix inverse [19] . Exact MLE computation is intensive in a high dimension case since the margin and copula parameters are jointly estimated.
2.6. Goodness of Fit Test Based on Kendall’s Tau
Hence goodness-of-fit measures gives a summary of discrepancy in expected and observed values in a given model. Mostly it is applied in hypothesis testing however in this case we test if the underlying copula data fits in a chosen copula.
where
is a parameter space and L as the set of copulas. We apply Cramer-von Mises statistic as the test statistic, defined as
(33)
where we have
being observations made from an unknown distribution.
(34)
Given the indicator function as the empirical distribution,
,
and
. A rejection of H0 is made if the statistic leads to large values.
Computing p-values based on test statistic in the empirical process required generating N as the large number of size n independent sample from
and further computing the statistics corresponding values.
test statistics depending on copula under H0 with the parameter
being unknown.
3. Main Results
3.1. Descriptive Statistics
From Table 1 the results showed that none of the crypto was normally distributed since Jarque-Bera statistics are statistically significant, and the data series are negatively skewed except for Bitcoin in addition the data also exhibit excess kurtosis. The summary statistics suggest that the probability distribution for Cryptocurrencies are negatively skewed indicating that left tails are bigger than the right tails except for Bitcoin which is positively skewed
Figure 1 shows that there is a medium to high correlation between the currencies. Interestingly, the currencies are positively correlated with each other. These currencies (Litecoin, Dogecoin and Bitcoin) have a very strong correlation. First, Litecoin has a positive fairly strong correlation with Bitcoin namely Bitcoin (0.63). Second, Dogecoin has a positive very strong correlation with Binance coin, namely, Binance (0.82). Third, Bitcoin has a positive strong correlation with Binance (0.85). Therefore from the results there is no stable cryptocurrency.
3.2. Testing for ARCH Effects
The Box-Ljung test is used to test for the existence of ARCH effects using the squared residuals from the fitted mean equation. The tests null hypothesis is that there are no ARCH effects, while the alternative hypothesis is that there are ARCH effects. Since the p-value’s are less than 0.05, ARCH effects are present in the four Cryptocurrencies. Thus we reject the null hypothesis that there are no ARCH effects as indicated in Table 2. This provides evidence of presence of conditional heteroscedasticity in the mean of cryptocurrencies (Bitcoin, Binance, Litecoin and Dogecoin) returns hence GARCH model that accounts for volatility needs to be employed in modeling Binance, Litecoin, Dogecoin and Bitcoin.
3.3. Selection of the GARCH Models
We observe that the standard GARCH specification of order (1,1) under the highly flexible ARMA-GARCH model is appropriate to identify the true patterns
![]()
Table 2. Box-Lyung test for ARCH effects.
of the studied index returns, Table 3. And having a well specified marginal model is central to robust copula construction.
3.4. Copula Parameter Estimation
After obtaining standardized residuals from the different specifications of GARCH models, next step was to model the marginals distribution using copula. Since our interest is on dependence structure between Litecoin, Dogecoin and Binance coin prices and Bitcoin prices, we consider the following currency prices pairs; Binance - Bitcoin, Litecoin - Bitcoin and Dogecoin - Bitcoin and we estimate copula model parameters. The best fit copula parameter was determined using AIC, BIC and the log likelihood function.
3.4.1. Copula Parameters Binance - Bitcoin Prices
Table 4 presents a summary of BB8 copula parameters. The BB8 provides the best fit since it has the lowest AIC and BIC. The bivariate BB8 copula has two parameters.
3.4.2. Copula Parameters Dogecoin - Bitcoin Prices
Table 5 presents a summary of BB8 copula parameters. The BB8 provides the best fit since it has the lowest AIC and BIC. The bivariate BB8 copula has two parameters.
3.4.3. Copula Parameters Litecoin - Bitcoin Prices
Table 6 presents a summary of BB1 copula parameters. The BB8 provides the best fit since it has the lowest AIC and BIC. The bivariate BB1 copula has two parameters.
3.5. Dependence
Tail Dependence
Tables 4-6 also report the estimated tail dependence coefficients of BB8 and BB1 copulas. The results indicate that for all the studied pairs of returns, the tail dependence parameters,
and
of the BB1 copulas are statistically significant, suggesting that the dependence at the lower and upper tails is symmetric. The results also show that the pair Litecoin and Bitcoin has the highest tail dependence among the the selected cryptocurrencies, this implies that change in prices of Litecoin will influence the prices of Bitcoin and vice versa is true. There was no tail dependence is detected for the pair Binance and Bitcoin, and Dogecoin and Bitcoin. The BB1 copula is the most suitable to describe the dependence structure in the cryptocurrencies.
3.6. Optimization of Cryptocurrency Portfolio
The optimization process produces 24 different portfolios and displays the optimal portfolio investment, which was constructed by maximizing the Sharpe ratio (Figure 2 and Figure 3). The optimal coin portfolio shows a Sharpe ratio of 0.101. These portfolios are optimal as they locate at the efficient frontier. This observation confirms the assumption of the Markowitz model that allocating assets to a portfolio reduces the overall risk compared to the individual risk of these related assets. The optimization process results into a mean of 0.70% and a volatility of 10.38% for the optimal coin portfolio. Further, the maximized return
![]()
Table 4. Copula parameter estimation Binance - Bitcoin.
![]()
Table 5. Copula parameter estimation Dogecoin - Bitcoin.
![]()
Table 6. Copula parameter estimation Litecoin - Bitcoin.
portfolios comprise the full invested (i.e. 100%) of Dogecoin portfolio. However, the maximized return portfolio will not serve as a benchmark portfolio in this analysis. The diversification effect of constructing portfolios of cryptocurrencies, in this case coins significantly reduces risk irrespective of significant correlation among the cryptocurrencies chosen in this analysis.
3.7. Discussion
Exploratory data analysis was first carried out on cryptocurrencies to verify their properties of returns such as normality. It was found that the returns were heavily tailed and negatively skewed except for Bitcoin with presence of ARCH
effects which was examine by using by Ljung box test. sGARCH(1,1) was selected with different specifications where AIC was used to select the most viable GARCH(1,1) model for each cryptocurrency returns. The standardized residuals were used to estimate the marginal distribution for each series. The results showed that BB8 and BB1 copula provides the best fit for the combinations of Litecoin, Binance and Dogecoin and Bitcoin return. Copula GARCH was used to model dependence structure between Litecoin, Binance and Dogecoin returns and Bitcoin returns, where BB1 copula was found to be the most appropriate for examining the dependence between the cryptocurrencies. Optimization of the cryptocurrencies showed that Dogecoin have the best optimization and investing on this coin significantly reduces risk irrespective of significant correlation among Litecoin, Bitcoin and Binance.
4. Conclusions and Suggestions
Cryptocurrencies has attracted a lot of attention to digital market investor and currently there more than 50 cryptocurrencies are actively traded in the market. Economists, financial analysts and investors have focused largely on Bitcoin since it accounts for more than 60% market capitalization. Currently the market knowledge points to the fact that Bitcoin is the most preferred asset in optimization of a portfolio. The study focuses on modelling cryptocurrencies, investigating the currency dependencies and determining an optimal portfolio. Cryptocurrencies are high-risk assets; however, an optimal portfolio eliminates high-risk. The study showed that, standard GARCH of order (1,1) under highly flexible ARMA-GARCH model is the most appropriate model in modelling the cryptocurrency prices and can identify the true pattern of index returns. Cryptocurrency in the market is also highly dependent as Bitcoin, Binance coin, Dogecoin and Litecoin were correlated. Litecoin and Bitcoin have a higher tail dependence and this implied that a change in prices of Litecoin will affect the prices of Bitcoin and vice versa. On optimizing a portfolio composed of cryptocurrencies that is more than necessary for potential investment decisions, Dogecoin has the best optimization. The research contributes to the literature on modelling cryptocurrencies and estimating risk management.
The author of this paper invites scientific community to perform a similar study as this one by considering Bayesian copula Garch which allows model to be data driven and compare the findings.
Acknowledgements
Sincere thanks to my supervisors Dr. Anthony Ngunyi and Dr. Joseph K Mungatu for their professional guidance and performance, and special thanks to my wife and parents for their moral support and rare attitude of high quality.