1. Introduction
Using the likelihood function to find an approximate confidence region for several parameters (often only one, in which case we speak of a confidence interval) of a specific distribution goes back to the classic publication of Kendall and Stuart [1] . To understand the rest of our article, it is necessary to briefly review their main result, summarized by
Theorem 1. Assuming a case of regular (meaning the distribution’s support is not a function of any of the distribution’s parameters) estimation, the following random variable
(1)
has approximately the chi-square distribution with K degrees of freedom, where K is the number of parameters to be estimated,
is the set of n observations (allowing for the possibility of a multivariate distribution),
denotes the corresponding likelihood function,
is the vector of the resulting ML estimates, and
represents the true (but unknown) values of the parameters.
Proof. Realizing that
(2)
where
are the individual observations, then differentiating the RHS with respect to
and setting each component of the answer to 0 yields
(3)
where
implies differentiating
with respect to each parameter; the result is thus a vector with K components.
To solve the corresponding set of equations, we expand the LHS of (3) at
, thus getting
(4)
where the second derivative of
is a symmetric K by K matrix. Dividing each side of the last equation by n, we solve it for
getting, to the first-order accuracy
(5)
where
(6)
(7)
Note that the expected value of
is
, since
(8)
and its variance-covariance matrix equals to
, due to
(9)
where
(10)
is the variance-covariance matrix of
(the small circle implies direct product of the two vectors), and
is the zero matrix.
Similarly expanding (1) and utilizing (5) we get, to the same level of accuracy
(11)
resulting in the following simple approximation to (1)
(12)
where
has (due to Central Limit Theorem) a K-variate Normal distribution with the mean of
and the variance-covariance matrix of
. Introducing
, the moment generating function of (12) is then computed by
(13)
easily identified as the MGF of
distribution. ■
The result then leads to a simple (we call it basic) algorithm of constructing the corresponding confidence region based on a random independent sample of n observations.
Examples
From the last theorem it follows that an approximate confidence region is found by following these steps:
● Using sample values drawn from the distribution, maximize its likelihood function, thus getting the ML estimates of all parameters;
● Choose a confidence level (denoted
) and make (1) (where
represents the ML estimates, but
are now variables to be solved for) equal to the corresponding critical value of the
distribution;
● Solve for
, resulting in two limits of the corresponding confidence interval when
, a closed curve when
, a closed surface when
, etc.; this means that, beyond a one-parameter case, the resulting region can be displayed only graphically (a trivial task for today’s computers).
The following Mathematica program shows how it is done, first using a Geometric distribution with a (computer generated) sample of 40 and confidence level of 90%, then a Gamma distribution with a sample of 60 and confidence level of 95%.

The last line of the program has produced the following 95% confidence region (see Figure 1) for α (horizontal scale) and β (vertical scale).
A three-parameter estimation can be done in a similar manner, only the call to “ContourPlot” needs to be replaced by “ContourPlot3D”. Visualizing a confidence region for more than three parameters would require slicing it into a sequence of cross-sections.
![]()
Figure 1. Confidence region for α and β.
The error of this procedure depends on the sample size, decreasing with n in the
manner; it can reach several percent for small samples. The purpose of the next section is to show how to substantially reduce this error, making it rather insignificant in all practical situations.
2. High-Accuracy Extension
There have been many attempts at improving the accuracy of this approximation, starting with Bartlett [2] , followed by [3] and many others, all concentrating on higher moments of the approximately Normal distribution of ML estimators. Our approach is different: we aim at finding an appropriate correction to the
distribution of the Likelihood function. The technique we use is not unlike that of [4] , in spite of diverging objectives.
It has been shown in previous publications [5] and [6] that the distribution of (1) is more accurately described by the following probability density function
(14)
where
is the chi-square PDF of the original theorem, A is a quantity (often a simple constant) specific to the sampled distribution, and K is the number of parameters to be estimated. In terms of the corresponding CDF, this becomes
(15)
(the two-argument
denotes the incomplete Gamma function) or, more explicitly
when
, and
(16)
when
(the two most important cases).
Note that the expected value of distribution (14) is
; similarly expanding (1) then yields the formula for computing A, given the PDF of the sampled distribution.
Leaving out less important details, we now indicate the individual steps of such derivation.
● Extend the LHS of (4) by two more terms of the corresponding expansion, namely by
(17)
Note that the third and fourth derivatives of
constitute fully symmetric tensors of ranks 3 and 4 respectively; each is further multiplied by the corresponding power (one less than the derivative’s order) of
. The multiplication is carried out by taking the dot product along one of the tensor’s indices with vector
, and repeating as many times as the power of
indicates; the result is thus always a vector with one remaining index.
● Solve the resulting equation (iteratively) for
, to the same order of accuracy. This extends our existing solution (5), which we denote
, by the following quadratic term
(18)
and a cubic term, given by
(19)
where
(20)
(21)
(we have already explained how to multiply a symmetric tensor by a power or a product of vectors).
● Similarly expand (1); further divided by the sample size n, this results in the following scalar expression
(22)
where the × symbol between two vectors (not used beyond this formula) implies an operation we call contraction of the two vectors, carried out by
(23)
This is also how we perform a contraction of two specific indices of a tensor (required shortly); e.g. contracting the first two indices of
would be done (and denoted) by
(24)
resulting in a vector.
● Finally, take the expected value of (22) to get
.
This yields (term by term)
(25)
where
(26)
with
and
defined analogously. Bold-face notation indicates that each term of (25) has been contracted in all of its indices, resulting in a scalar. For some of these terms, there are several possibilities to carry out such a contraction (e.g. the six indices of
can be contracted in altogether five non-equivalent ways, only two of which we actually need); it is thus very important to indicate (in the ambiguous cases only; note that all pair-wise contractions of
, and also of
, yield the same answer) the proper way of doing it.
A dot implies contraction of two of the indicated indices (
thus making the result into a vector, while
implies, by the absence of a dot over 2, that the first two indices have been contracted with the third and fourth index, rather than with each other); similarly, two circles indicate that the corresponding two indices are to be contracted:
thus makes the first index of
contract with its last index, returning a vector yet to be contracted with the first index of
(due to the lack of a dot over 2); similarly
indicates contracting the last index of
with the first index of
, while the remaining two indices of
are contracted with the remaining two indices of
.
Since
, which can be verified in a manner of (9), the final formula for 2A then reads
(27)
when
, the formula simplifies to
(28)
We should mention that, in principle, the
-proportional correction in (14) has two more terms of increasing complexity (see [5] ), namely
(29)
where the B and C coefficients can be found in a manner very similar to how we have just established the value of A; most surprisingly, both B and C then turn out to be equal to zero.
2.1. Location and Scaling Parameters
An important feature of the last two formulas is the fact that A may be a function of shape parameters (if any) of the sampled distribution, but not of a location or a scaling parameter, as these always cancel out from the resulting expression. To understand why, consider
(30)
This enables us to simplify the two derivatives of
thus
(31)
(32)
from which it is clear that each further differentiation (whether with respect to
or
) yields a function of y, divided by an extra power of
. Taking the expected value of any product of such derivatives amounts to further multiplying by
and integrating over all possible values of y, leaving us with a number divided by power (equal to the derivative’s total order) of
. These powers of
then always cancel out from (27).
This implies that, for distributions having only location and/or scaling parameters, A will turn out to be a constant.
2.2. Examples
Values of A are summarized in Table 1 for some of the most common distributions.
For Gamma and Beta distributions, A is a complicated function of its first (Gamma) and both (Beta) parameter(s); yet, under the indicated constrains (see the above table), the value of A remains fairly constant.
For Gamma distribution (to illustrate the complexity of A as a function of a shape parameter), the full formula reads
(33)
where
is the
derivative of the natural logarithm of the
function, evaluated at
. Yet, by plotting the last expression as a function of
, we can confirm that, with the exception of only the smallest (say < 0.5) values of
,
A is nearly a constant, quickly approaching its
limit of
. We can
![]()
Table 1. Value of A for various distributions.
make similar conclusion in the case of Beta distribution, as mentioned already. Note that, in the case of bivariate Normal distribution, A is a constant, free not only of the two location and the two scaling parameters, but also of the shape parameter
.
Incorporating the A-related correction requires only a trivial modification of the previous program; in the Geometric example, we need to replace the “CL = ...” line by the following two lines:
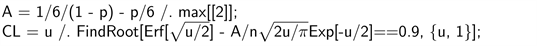
Note that, to compute A, instead of using the true but unknown value of p, we had to use its point estimate instead.
In the Gamma example (since the
estimate was bigger than 0.5), we can use the large-
limit of A; the “CI = ...” line now has to be replaced by
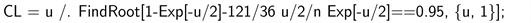
3. Hypotheses Testing
The same formulas can be utilized for high-accuracy testing of a null hypothesis, claiming that parameters of distribution have specific values. Thus, for example, when the distribution has two parameters, we first need to find their ML estimates (based on a random independent sample of size n); using these we then evaluate (1), where
now stands for the parameter values as specified by the null hypothesis, and substitute the result for u in (16); this yields the confidence level of rejecting the null hypothesis—subtracting this from 1 then returns the corresponding P-value.
The following Mathematica program illustrates how it is done, using the Cauchy distribution and testing whether its two parameters (m and s, say) have true values equal to 0 and 1 respectively (our random sample of 40 independent observations has been generated using
and
).

Based on the resulting P value, the null hypothesis would be rejected at 1% level of significance.
In our second example, we test whether parameters of a bivariate Normal distribution have the following values:
,
and
(these are also the values we used to generate the sample of 100 bivariate observations).

The resulting P value would lead to accepting the null hypothesis at any practical level of significance.
4. Accuracy Improvement
To investigate the accuracy of the new approximation, we need to be able to compute the level of confidence of the resulting region exactly. This can be done only in a few situations, such as the Exponential and Normal distributions. Exploring these two cases will give us a good indication of the improvement achieved by incorporating the A correction in general. The details of computing the exact confidence level may be of only passing interest to most readers; it is the resulting error tables which are important.
4.1. Exponential Case
We know that the ML estimator of the β parameter is given by the sample mean
whose exact distribution is Gamma(n, β/n). Since
(34)
then
(35)
(note that this expression is always non-negative, reaching a minimum value of zero when
). The limits of the confidence interval of the basic technique are found by making (35) equal to a critical value of the
distribution (let us call it
, where
is the corresponding level of confidence) and solving for
(and then, trivially, for
).
One can show that the two real solutions are given by
(36)
where W is the Lambert (also called Omega, or “ProductLog” by Mathematica) function and the subscripts refer to its two real branches. To find the true confidence level, we need to integrate the PDF of
between these two limits (our code utilizes the corresponding CDF instead); subtracting the result from
establishes the error of the basic algorithm. Further subtracting
(37)
then converts it into the error of our new formula (15). The following Mathematica program does that in four simple lines.

Both errors (using various sample sizes) are displayed in Table 2, using
.
The table demonstrates that, as n increases, the error decreases with the first power of
for the basic approximation, and with the second power of
for our new algorithm.
4.2. Normal Case
Similarly, it is well known that the ML estimators of
and
of the Normal distribution are
and
respectively, that they are independent of each other, and that their respective distributions are
and Gamma(
). Since
(38)
(1) then becomes
(39)
To get the exact confidence level of the basic algorithm, we need to made this expression less than the critical value (denoted
, as in the previous example) of the
distribution, and integrate the joint PDF of
and
over the resulting region. Solving the equation of its boundary for
in the manner of (35) now yields
(40)
where Z stands for
, having the standard Normal distribution.
![]()
Table 2. Aproximation errors (Exponential case).
We then integrate the PDF of
(having the
distribution) using these two limits (again, the program utilizes the corresponding CDF instead); finally, we multiply the answer by the PDF of Z and integrate over all marginal values of Z (i.e. from 0 to
)—the last step is done numerically. This yields the true confidence level of the resulting confidence region; subtracting it from
then provides the corresponding error of the basic algorithm; further subtracting
(41)
converts that into the error of the new algorithm. This is how it is done using Mathematica:

Table 3 summarizes the results.
![]()
Table 3. Approximation errors (Normal case).
Similarly to the previous example, one can clearly discern the
-proportional decrease of the basic error, and the more rapid
-proportional decrease achieved by our correction.
5. Conclusion
In this article, we have modified the traditional way (based on the corresponding likelihood function and a random independent sample of size n) of constructing a confidence region for distribution parameters, aiming to reduce its error. This has been achieved by adding, to the usual
distribution of the original technique, a simple,
-proportional correction whose coefficient is computed, for each specific distribution, using a rather complex formula; we have done the latter for many common distributions, summarizing the results in Table 1. We have also provided several examples of a Mathematica code, demonstrating the new algorithm and its simplicity (each computer program takes only a few lines); a practically identical approach can then be applied to the task of hypotheses testing. Finally, we have numerically investigated the improvement in accuracy thereby achieved, finding it rather substantial. It is worth emphasizing that, once the value of A has been established, incorporating the corresponding correction is extremely easy and done with a negligible computational cost.
Future research will hopefully explain why are the B and C coefficients of (29) both equal to zero; so far we have been able to prove that only by a brute-force computation, but we believe that there is some more fundamental reason behind this result, which we have not been able to uncover.