A Comparison of the Estimators of the Scale Parameter of the Errors Distribution in the L1 Regression ()
1. Introduction
Consider the multiple linear regression model
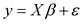 ,
,
where
y is an n × 1 vector of values of the response variable corresponding to X, an n × k matrix of predictor variables that may include a column of ones for the intercept term;
β is a k × 1 vector of unknown parameters and;
ε is an n × 1 vector of unobservable random errors.
The components of ε are independent and identically distributed random variables with cumulative distribution function F. Suppose that F has a unique median equal to zero and a continuous derivative f in the neighborhood of zero such that f(0) > 0. The scale parameter of f is defined as
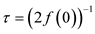 . (1.1)
. (1.1)
So τ2/n is the variance of the median in a sample of size n from the error distribution.
The L1 estimator  of β, minimizes
of β, minimizes 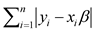 for all values of β, where yi is the i-th element of the vector y and xi is the i-th row of the matrix X.
for all values of β, where yi is the i-th element of the vector y and xi is the i-th row of the matrix X.
The L1 criterion is a robust alternative to the least squares regression whenever the data contains outliers or the errors follow a long tailed distribution such as Laplace or Cauchy.
It is well known that when the errors follow Laplace distribution, the L1 estimators of β are maximum likelihood estimators and so, they are asymptotically unbiased and efficient. [2] proved that the L1 estimator is asymptotically unbiased, consistent and follows a multinormal distribution with covariance matrix τ2(X'X)−1. An important implication of this result is that the L1 estimator of β has a smaller confidence ellipsoid than the least squares estimator for any error distribution for which the sample median is a more efficient estimator than the sample mean.
Based on the asymptotic distribution results, formulae for constructing confidence intervals and testing hypotheses on the parameters of the model have been developed [3] [4]. To apply these formulae and also to compute the standard errors of the estimators of β, it is necessary to have an estimate of the parameter τ. Several estimators of τ were proposed [1]. They recommend the consistent estimator
 ,
,
where
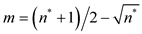 ,
,
n* is the number of non-zero residuals and 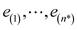 are the non-zero residuals arranged in ascending order.
are the non-zero residuals arranged in ascending order.
It is important to observe that 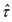 is a measure of the variability of the residuals and, although is influenced by all of them, it is determined by only two of them.
is a measure of the variability of the residuals and, although is influenced by all of them, it is determined by only two of them.
A consistent estimator of τ is also needed to calculate the robust coefficient of determination R proposed by [5]. This coefficient is an informal measure of goodness of fit of a model and it is given by
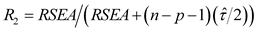 ,
,
where
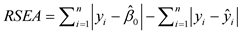 ,
,
 ,
,
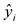 is the predicted value of the response variable in the i-th observation, that is
is the predicted value of the response variable in the i-th observation, that is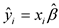 ;
;
![]() is the L1 estimator of the regression coefficients of the model.
is the L1 estimator of the regression coefficients of the model.
A desirable property for a coefficient of determination is that it increases when passing from a reduced to a full model, that is, when new predictor variables are included in the model [6]. For R2 this property is true only if ![]() decreases as new variables are included in the model and this might not happen, as shown in Example 1.
decreases as new variables are included in the model and this might not happen, as shown in Example 1.
Example 1—In this example, we use the real state data from [7]. The predictor variables are taxes, in hundred dollars (X1), lot area, in thousand squares feet (X2), living space, in thousand squares feet (X3), age of the home, in years (X4). The response variable (Y) is the selling price of the home, in thousands of dollars.
In Table 1, we present all possible linear models obtained with the four predicted variables, the number of parameters (k), the estimates ![]() and the values of R2 for each model. In this table, we see that the value of
and the values of R2 for each model. In this table, we see that the value of ![]() for the model with variable X1 only (4.0079) is smaller than the observed value of this statistic in the model with X1 and X3 (5.4301), and then the value of R2 in the model containing only X1 as predictor is larger than in the model with X1 and X3. However, the contribution of X3 given that X1 is already in the model is significant (p-value less than 0.01).
for the model with variable X1 only (4.0079) is smaller than the observed value of this statistic in the model with X1 and X3 (5.4301), and then the value of R2 in the model containing only X1 as predictor is larger than in the model with X1 and X3. However, the contribution of X3 given that X1 is already in the model is significant (p-value less than 0.01).
So, it may happen that the value of ![]() increases even with the introduction of a variable with significant contribution in the model. This fact will decrease the value of R2 and the new model might not be selected if the coefficient of determination is the criterion to select a model.
increases even with the introduction of a variable with significant contribution in the model. This fact will decrease the value of R2 and the new model might not be selected if the coefficient of determination is the criterion to select a model.
This instable behavior of ![]() may be explained by the fact that it is determined by only two residuals and so we can expect that it happens more frequently in small samples.
may be explained by the fact that it is determined by only two residuals and so we can expect that it happens more frequently in small samples.
When errors follow the Laplace distribution, the maximum likelihood estimator of τ is the mean absolute error [8], given by
![]()
where
![]() .
.
![]()
Table 1. Number of parameters (k), ![]() and R2 observed values for all possible regression models for the state data.
and R2 observed values for all possible regression models for the state data.
Although the usual regularity conditions do not hold for Laplace distribution, ![]() is a consistent estimator of τ [9]. This estimator is a measure of variability of the residuals, and it has the property of decreasing when new predictor variables are included in the model. Using this estimator, it is possible to construct a robust coefficient of determination that satisfies the desirable conditions in [6]. It is possible also to calculate the coefficient of determination adjusted by the number of predictor variables proposed in [10].
is a consistent estimator of τ [9]. This estimator is a measure of variability of the residuals, and it has the property of decreasing when new predictor variables are included in the model. Using this estimator, it is possible to construct a robust coefficient of determination that satisfies the desirable conditions in [6]. It is possible also to calculate the coefficient of determination adjusted by the number of predictor variables proposed in [10].
Our objective is to study the possibility of using ![]() as an alternative to
as an alternative to ![]() when the errors follow a distribution other than Laplace. We have special interest in small sample sizes because of the instable behavior of
when the errors follow a distribution other than Laplace. We have special interest in small sample sizes because of the instable behavior of ![]() in such cases.
in such cases.
[11] pointed out the importance of the L1 method of estimation, presenting many practical situations in which its application is recommended. So, the search of procedures that make its use more efficient gives important contribution to the statistical theory.
The paper is organized as follows. Initially, the asymptotic distributions of ![]() were derived analytically assuming errors with Normal, Mixture of Normals, Laplace and Logistic distributions. These results allowed to compute the asymptotic bias and mean squared error of this estimator. Then, we performed a simulation study and generated empirical distributions of
were derived analytically assuming errors with Normal, Mixture of Normals, Laplace and Logistic distributions. These results allowed to compute the asymptotic bias and mean squared error of this estimator. Then, we performed a simulation study and generated empirical distributions of ![]() and
and ![]() in small samples, after the fitting of models with one predictor variable and errors with the same distributions considered previously and Cauchy distribution also. The distributions considered in this study were characterized according to the weight of their tails [12]. The results obtained in this study allowed indicating situations in which
in small samples, after the fitting of models with one predictor variable and errors with the same distributions considered previously and Cauchy distribution also. The distributions considered in this study were characterized according to the weight of their tails [12]. The results obtained in this study allowed indicating situations in which ![]() can be used as an alternative to estimate τ.
can be used as an alternative to estimate τ.
2. Asymptotic Distribution of ![]()
In this section, we derive analytically the asymptotic distribution of![]() , considering four different distributions for the errors. We assume errors with normal (0, σ2) distribution, mixture of Normals when random variables are selected from a normal (0, 1) with probability p and of a normal (0, σ2) with probability 1 − p, Logistic distribution with mean zero and variance γ2π2/3 and Laplace distribution with mean zero and variance 2σ2.
, considering four different distributions for the errors. We assume errors with normal (0, σ2) distribution, mixture of Normals when random variables are selected from a normal (0, 1) with probability p and of a normal (0, σ2) with probability 1 − p, Logistic distribution with mean zero and variance γ2π2/3 and Laplace distribution with mean zero and variance 2σ2.
First, we note that ![]() may be written as
may be written as
![]()
where
![]() is the L1 estimator of
is the L1 estimator of![]() .
.
Since ![]() is a consistent estimator of
is a consistent estimator of ![]() [2], the asymptotic distribution of
[2], the asymptotic distribution of ![]() is the same of
is the same of![]() , and this quantity is equal to
, and this quantity is equal to![]() , where εi is the i-th element of the vector of errors of the model. Next, we study the asymptotic distribution of this random variable for different errors distributions.
, where εi is the i-th element of the vector of errors of the model. Next, we study the asymptotic distribution of this random variable for different errors distributions.
3. Errors with Normal (0, σ2) Distribution
Using the fact that ![]() we observe (see Appendix A) that
we observe (see Appendix A) that
![]() and
and![]() .
.
Further, the random variables![]() ,
, ![]() , are independent and identically distributed and, by the Central-limit theorem
, are independent and identically distributed and, by the Central-limit theorem
![]() .
.
So, it follows that
![]() .
.
Finally, since ![]() then
then![]() , which implies that
, which implies that
![]() ,
,
or that
![]() .
.
4. Errors with Mixture of Normal Distributions
In this case, we assume that the errors distribution is a mixture of two normal distributions: a Normal (0, 1) selected with probability p and a Normal (0, σ2) selected with probability (1 − p). Hence, the probability density function of εi is
![]()
It is not very difficult to see that
![]() ,
, ![]() and that the parameter τ is
and that the parameter τ is
![]()
Furthermore, ![]() ,
, ![]() are independent and identically distributed random variables with mean and variance (see Appendix A) given by
are independent and identically distributed random variables with mean and variance (see Appendix A) given by
![]() and
and
![]() .
.
So, as the same way that in the Normal errors distribution case
![]() ,
,
and
![]() ,
,
that is,
![]() .
.
5. Errors with Logistic Distribution
Let us suppose that the errors follow a Logistic distribution with probability density function
![]()
such that![]() ,
, ![]() , and, therefore, τ = 2γ.
, and, therefore, τ = 2γ.
Also, because![]() ,
, ![]() , are independent and identically distributed random variables, it is proved in the Appendix A that the mean and the variance of these variables are 1.386γ and 1.37γ2.
, are independent and identically distributed random variables, it is proved in the Appendix A that the mean and the variance of these variables are 1.386γ and 1.37γ2.
So, by the Central-limit theorem
![]() .
.
Using the same arguments of the previous demonstrations, it follows that
![]()
Since in this case τ = 2γ, we have
![]() .
.
6. Errors with Laplace Distribution
When the errors follow a Laplace distribution with mean zero and variance 2σ2 then
![]() ,
, ![]() and
and![]() .
.
Therefore, because of the Central-limit theorem
![]() ,
,
and hence
![]() .
.
Remark: Based on the asymptotic distribution of![]() , confidence intervals for τcan be developed. In the Normal errors case, an asymptotic confidence interval for τ is
, confidence intervals for τcan be developed. In the Normal errors case, an asymptotic confidence interval for τ is
![]()
where, ![]() ,
, ![]() and z is the percentile of order (1 + γ)/2 of the standard Normal distribution and γ is the confidence coefficient of the interval.
and z is the percentile of order (1 + γ)/2 of the standard Normal distribution and γ is the confidence coefficient of the interval.
This confidence interval enables us to test hypothesis like H: τ = τ0 at a significance level α = (1 − γ).
7. Asymptotic Bias of ![]()
Because the sample mean of the values of the absolute residuals is a continuous and limited function, by the Helly-Bray Lemma [13], the expectation of ![]() converges to the mean of its asymptotic distribution. Therefore, it is possible to calculate the asymptotic bias of this estimator.
converges to the mean of its asymptotic distribution. Therefore, it is possible to calculate the asymptotic bias of this estimator.
The analysis of the results presented in the previous section shows that the bias of this estimator is different of zero for every errors distribution considered, except the Laplace distribution.
When the errors follow the Normal (0, σ2) distribution, the asymptotic bias is
![]() ,
,
that is negative, and so, in average, ![]() sub-estimates τ.
sub-estimates τ.
For the mixture of Normal distribution errors, the asymptotic bias is
![]() ,
,
that is negative if![]() , and is positive otherwise.
, and is positive otherwise.
In the Logistic distribution, the asymptotic bias is given by
![]() ,
,
and so, it is always negative.
8. Simulation Study
In this section, we perform a simulation study with the objective of generate empirical distributions of the estimators ![]() and
and ![]() considering small sample sizes, under the following distributions of the errors εi:
considering small sample sizes, under the following distributions of the errors εi:
- Normal (0, 1) (τ = 1.253);
- Logistic with mean zero and variance π2/3 (τ = 2.00);
- Laplace with mean zero and variance 2 (τ = 1.00);
- Mixture of Normals (NM 85-15) when random variables are selected from a Normal (0, 1) with probability 0.85 and a N (0, 49) with probability 0.15 (τ = 1.439);
- Mixture of Normals (NM80-20) when random variables are selected from a Normal (0, 1) with probability 0.80 and a N (0, 49) with probability 0.20 (τ = 1.513) and
- Cauchy with median zero and scale parameter 1 (τ = 1.571).
Our objective is to find situations determined by errors distributions and sample sizes, under which ![]() has empirically a better behavior than
has empirically a better behavior than ![]() in terms of bias and mean squared error.
in terms of bias and mean squared error.
The simulation study was designed as follows.
➢ We considered regression models with one independent variable generated from a Normal (0, 1) distribution, independently of the errors. Without loss of generality, the true parameters β0 and β1 were fixed equal to 1;
➢ The sample sizes (n) were set as 10, 20, 30, 50, 100 and 200;
➢ For each combination of sample size and errors distribution, 1000 sets of data were generated;
➢ Using the L1 method, a regression model was fitted for each set of data and the values of ![]() and
and ![]() were calculated. So, this procedure generated 1000 values of
were calculated. So, this procedure generated 1000 values of ![]() and
and![]() .
.
The computations were performed using a special routine constructed in S-Plus 4.5.
The results obtained in this study are summarized in Tables B1-B6 in Appendix B. They suggest that
➢ ![]() is a good alternative to
is a good alternative to ![]() when the errors follow Laplace, NM 85-15 or NM 80-20 distributions. In these cases,
when the errors follow Laplace, NM 85-15 or NM 80-20 distributions. In these cases, ![]() has bias and mean squared error smaller or of the same order than
has bias and mean squared error smaller or of the same order than![]() ;
;
➢ When the errors follow Normal or Logistic distribution, ![]() tends to sub-estimate τ. The means of
tends to sub-estimate τ. The means of ![]() distributions generated in the study are closer to the parameter value and its mean squared errors are in general uniformly smaller than that of
distributions generated in the study are closer to the parameter value and its mean squared errors are in general uniformly smaller than that of![]() , for all considered sample sizes.
, for all considered sample sizes.
➢ For the Cauchy distribution errors, ![]() tends to super-estimate τ. This result may be a consequence of the fact that all the residuals are considered in the computation of this estimator. Although
tends to super-estimate τ. This result may be a consequence of the fact that all the residuals are considered in the computation of this estimator. Although ![]() has smaller bias and mean squared error than
has smaller bias and mean squared error than![]() ,
, ![]() does not seem to be a good estimator of τ for sample sizes smaller or equal to 30.
does not seem to be a good estimator of τ for sample sizes smaller or equal to 30.
9. Some Characteristics of the Distributions in the Study
The distributions considered in the previous sections are symmetrical about zero and can be ordered by the weight of their tails [12]. For![]() , an appropriate coefficient that can be used with this objective is
, an appropriate coefficient that can be used with this objective is
![]() ,
,
where
![]() ,
,
F (x) is the distribution function of the errors and
![]() is the median of the density function associated to
is the median of the density function associated to![]() .
.
This coefficient has the following properties
![]()
Table 2. Values of b2(α) for the distributions in the study.
➢ ![]() ;
;
➢ Its computation does not require that the errors distribution have any finite moment;
➢ Its value is independent of the parameters of location and scale.
Large values of b2(α) indicate that the distribution has heavy tails.
In Table 2 we present the values of b2(α) for the distributions considered in this study, taking α = 0.10 and α = 0.05. For these values of α, it is clear that the ordering of the distribution according to its tails weights is: Normal, Logistic, Laplace, NM 85-15, NM 80-20 and Cauchy.
10. Concluding Remarks
In this paper, we studied the behavior of the estimator ![]() with the objective of using it as an alternative to
with the objective of using it as an alternative to![]() . We also determined analytically its asymptotic distribution under different distributions of the errors of the model. It was observed that, in general,
. We also determined analytically its asymptotic distribution under different distributions of the errors of the model. It was observed that, in general, ![]() is asymptotically biased, with asymptotic bias equal to zero when the errors follow the Laplace distribution. In this case, the absence of asymptotic bias was already expected, since
is asymptotically biased, with asymptotic bias equal to zero when the errors follow the Laplace distribution. In this case, the absence of asymptotic bias was already expected, since ![]() is the maximum likelihood estimator of τ when the errors follow the Laplace distribution.
is the maximum likelihood estimator of τ when the errors follow the Laplace distribution.
Performing a simulation study, the two estimators were compared empirically by their bias and mean squared error, under distributions with different tails weights and considering sample sizes varying from 10 to 200. The results suggest that ![]() is a good alternative to
is a good alternative to ![]() when the errors in the model follow Laplace or Mixture of Normal distributions with the values of the parameters fixed in the study; when the errors have Normal or Logistic distributions (lighter tails) or Cauchy distribution (heavy tails),
when the errors in the model follow Laplace or Mixture of Normal distributions with the values of the parameters fixed in the study; when the errors have Normal or Logistic distributions (lighter tails) or Cauchy distribution (heavy tails), ![]() presented the best performance for every considered sample sizes. However, in the Cauchy distribution case, although
presented the best performance for every considered sample sizes. However, in the Cauchy distribution case, although ![]() seemed to be better than
seemed to be better than![]() , its use is not recommended in samples of size smaller or equal to 30 because of the bias of this estimator.
, its use is not recommended in samples of size smaller or equal to 30 because of the bias of this estimator.
The results of the study indicate that ![]() should be used when the distribution of the errors is close to the Laplace distribution, whatever the sample size. By the properties of this estimator mentioned in Section 1, we suggest that the fit of the data to the Laplace distribution be analyzed by the construction of a Q-Q plot of the residuals of the model. If there are not serious deviations,
should be used when the distribution of the errors is close to the Laplace distribution, whatever the sample size. By the properties of this estimator mentioned in Section 1, we suggest that the fit of the data to the Laplace distribution be analyzed by the construction of a Q-Q plot of the residuals of the model. If there are not serious deviations, ![]() should be used. Otherwise, Box-Cox transformations can be applied following [14]. After this, in the analysis of the transformed data,
should be used. Otherwise, Box-Cox transformations can be applied following [14]. After this, in the analysis of the transformed data, ![]() can be used to construct confidence intervals and hypotheses tests about the parameters of the model and in the computation of robust coefficients of determination with and without a correction by the number of independent variables in the model.
can be used to construct confidence intervals and hypotheses tests about the parameters of the model and in the computation of robust coefficients of determination with and without a correction by the number of independent variables in the model.
Appendix A. Results Used in Section 2
In Section 2, when we obtained the asymptotic distributions of![]() , the distributions of the errors were symmetrical about zero. It is easy to see that if X is a random variable with values in the interval ]−∞, ∞[, symmetric about zero and with density f(x), then the density of
, the distributions of the errors were symmetrical about zero. It is easy to see that if X is a random variable with values in the interval ]−∞, ∞[, symmetric about zero and with density f(x), then the density of ![]() is
is
![]()
Using this fact, we got E(|εi|) for εi with Normal, Mixture of Normals, Logistic or Laplace distribution.
If the errors follow a Normal distribution, that is, ![]() , then
, then ![]() has the density
has the density
![]()
and thus
![]()
Also, ![]() , and so
, and so ![]() .
.
When the errors follow a mixture of Normal distribution, the probability density function of Ui = |εi| is given by
![]()
Therefore
![]()
and
![]()
that is the variance of a random variable with mixture of Normal distributions with parameters p, (1 − p), means equal to zero and variances 1 and σ2 respectively.
Consequently,
![]()
When εi has Logistic distribution with mean zero and variance γ2π2/3.
![]()
because![]() .
.
Also![]() , and so
, and so ![]() .
.
For εi with Laplace distribution with zero mean and variance 2σ2, |εi| has exponential distribution with mean equal to σ and variance equal to σ2. Thus, ![]() and
and![]() .
.
Appendix B. Tables
![]()
Table B1. Values of descriptive statistics observed in the distributions of the estimators ![]() and
and ![]() generated in the simulation study for models with Normal (0, 1) errors (τ = 1.253) and different sample sizes.
generated in the simulation study for models with Normal (0, 1) errors (τ = 1.253) and different sample sizes.
![]()
Table B2. Values of descriptive statistics observed in the distributions of the estimators ![]() and
and ![]() generated in the simulation study for models with Logistic errors (τ = 2.00) and different sample sizes.
generated in the simulation study for models with Logistic errors (τ = 2.00) and different sample sizes.
![]()
Table B3. Values of descriptive statistics observed in the distributions of the estimators ![]() and
and ![]() generated in the simulation study for models with Laplace errors (τ = 1.00) and different sample sizes.
generated in the simulation study for models with Laplace errors (τ = 1.00) and different sample sizes.
![]()
Table B4. Values of descriptive statistics observed in the distributions of the estimators ![]() and
and ![]() generated in the simulation study for models with 0.85 Normal (0, 1) + 0.15 Normal (0, 49) errors (τ = 1.439) and different sample sizes.
generated in the simulation study for models with 0.85 Normal (0, 1) + 0.15 Normal (0, 49) errors (τ = 1.439) and different sample sizes.
![]()
Table B5. Values of descriptive statistics observed in the distributions of the estimators ![]() and
and ![]() generated in the simulation study for models with 0.80 Normal (0, 1) + 0.20 Normal (0, 49) errors (τ = 1.513) and different sample sizes.
generated in the simulation study for models with 0.80 Normal (0, 1) + 0.20 Normal (0, 49) errors (τ = 1.513) and different sample sizes.
![]()
Table B6. Values of descriptive statistics observed in the distributions of the estimators ![]() and
and ![]() generated in the simulation study for models with Cauchy errors (τ = 1.571) and different sample sizes.
generated in the simulation study for models with Cauchy errors (τ = 1.571) and different sample sizes.