Effects of Functional Illiteracy on the Living Conditions of Households in Congo ()
1. Introduction
“Literacy is not a luxury; it is a right and a responsibility. If our world is to meet the challenges of the twenty-first century, we must harness the energy and creativity of all our citizens” (Clinton, 1994, the International Literacy Day). Illiteracy is a significant barrier to economic and social development for individuals, communities, and States. Van Pelt (2018) suggests that illiteracy results in the lack of the skills to read dosage/warnings on medicine bottles, follow cooking instructions, properly manage finances, or apply for jobs that allow individuals to live above the poverty line. For Hanushek (2013), these cognitive skills are a long-term economic growth engine that allows the least developed countries to fill the gap in economic development. In addition to the negative impact on economic growth, illiteracy negatively affects individuals’ health and employment and children’s education. Indeed, many studies have shown a correlation between communities with high literacy rates and lower infant mortality rates. This may be because literate adults have a greater ability to seek medical treatment for themselves and their families and differences in their reproductive behavior, including increased contraception use (Van Pelt, 2018). In terms of employment, those with low literacy skills often have difficulty finding jobs that pay more than a living wage. Once in these jobs, they are promoted or received less frequently, limiting their professional mobility. These employees have more difficulty supporting their families and are more likely to depend on additional means such as social assistance or food stamps. Regarding children’s education, Hart and Risley (2003) point out that there is a gap of thousands of words between children from low-income families and children from high-income families. They conclude that the average child in a high-income family will have heard almost 45 million words by age 4, compared to 13 million words for the average child living in a low-income family. This finding demonstrates the economic impact of illiteracy on families and the continuing cycle of low literacy it creates.
In 2016, 750 million people in the world were considered illiterate (UNESCO, 2016). Compared to 1994, this number represents important progress, as illiteracy had fallen by 14 percent in 22 years. All geographic areas showed progress: In South Asia, the literacy rate increased from 46 percent of the population in 1990 to 72 percent in 2016. Literacy rates increased from 64 percent to 81 percent in North Africa and West Asia; from 82 percent to 96 percent in Southeast and Eastern Asia; from 52 percent to 65 percent in sub-Saharan Africa; and from 85 percent to 94 percent in Latin America and the Caribbean. In all societies where the literacy rates increased, UNESCO (2016) also measured increases in national wealth (GDP) and decreased the number of people living below the poverty line. In the case of Congo, between 1970 and 2017, the gross domestic product (GDP) per capita has increased by 1.2 percent (World Bank, 2019). In this interval, people living under the poverty line went from 50.7% in 2005 to 46.5 in 2011 (CNSEE, 2005, 2011).
Despite the steady increase in literacy over the past 50 years, more than 750 million people worldwide are still illiterate, especially children, adolescents, and women (UIS—Unesco Institute of Statistics, 2017). This figure represents a number more than three times the population of Brazil. It illustrates the enormous waste of human potential that could threaten progress towards the achievement of the United Nation’s Sustainable Development Goals (SDGs), particularly Target 4.6, the goal to ensure literacy and numeracy among young people and adults by 2030.
As is true for most phenomena that hamper economic and social development, sub-Saharan Africa remains the sub-region most affected by illiteracy and has seen much slower progress (UIS, 2017). Indeed, the literacy rate only increased by 25 percent in 22 years, while in the same period, South Asia experienced an increase in the literacy of 56.5 percent, and Africa, North, and West Asia saw an increase of 27 percent. This phenomenon does not spare Congo.
Although the proportion of illiterate people in the population aged 15 - 49 has fallen from 24.5 percent in 2006 to 19.5 percent in 2012 (CNSEE, 2005, 2012), the country still has around 400,000 people aged 15 and over are illiterate (NIS 2007). Moreover, Mboko (2018) showed that in Congo, 50.1 percent of the population lives below the poverty line and poverty disproportionately affects Congolese households with low levels of literacy (among the illiterate, 69 percent of heads of households are poor, while 30 percent of heads of households have higher income levels). These statistics illustrate the progress still needed for Congo to reach Targets 1.1 and 4.6 of the SDGs by 2030. This situation led us to ask what impact functional illiteracy has on the household standard of living in Congo? This research’s objective was to analyze the effect of functional illiteracy on households’ living conditions in Congo.
The remainder of the paper is structured into five sections. Section two discusses the literature review. In the third section, we explain the methodological framework for the study and the data used. In the fourth section, we present and interpret the findings. The section five discusses your results in the light of literature review and finally the sixth section presents conclusions and policy implications of this research.
2. Literature Review
This section is subdivided into two parts. The first presents existing theories related to literacy. The second part presents empirical work that has considered this question.
2.1. Theoretical Review
The relationship between language and economics is embodied in two essential theoretical frameworks: human capital theory and the theory of discrimination. Based on Becker’s (1964) work, human capital’s impact on economic growth is well established. Indeed, education is one of the determining factors of individual income. It increases personal productivity and improves individuals’ information regarding the challenges they face in society (the market). It also increases social mobility (Riveros, 2005). This framework presents the desire and motivation to learn a language as purely economic motivations (Zhang, 2008). From the perspective of discrimination theory (Lang, 1986), minority language groups may be marginalized in the labor market due to discrimination. They cannot get a good job, making their income naturally lower. Lang (1986) developed a model in which the cost of learning a language and linguistic discrimination explained the wage differentials between members of different language groups. In this context, Levinsohn (2007) examined English proficiency in South Africa concerning globalization and found that proficiency had increased overall. However, it had increased mainly for whites but not for blacks, suggesting language proficiency is influenced by race and discrimination (Zhang & Grenier, 2012).
Ultimately, Marschak (1965) originated a new discipline in economics that is exclusively devoted to the link between language and economics, what is now commonly called “economics of language” (Zhang & Grenier, 2012). This discipline understands the dynamics of languages and their links with economics through game theory. Neuman and Morgenstern (1944) developed game theory as a set of analytical tools to facilitate understanding interactions between rational decision-makers (agents, players). In its standard form, this theory is based on two basic assumptions (Yildizoglu, 2011): 1) decision-makers are rational, and they pursue exogenous and independent objectives; 2) decision-makers take into account the knowledge they have or the expectations they have of the behavior of other decision-makers (they reason strategically). Rubinstein (1996, 2000) attempted to use game theory models to explore the nature, mechanism, and evolution of a language. He aimed to explain how natural language characteristics are associated with optimizing certain “reasonable” target functions. In general, game theory’s current approach to pragmatic strategies under discussion falls into two categories of problems. First, the speaker tries to convince the listener to take action or accept the speaker’s position; that is, there is mutual influence on both sides rather than towards a third party (Glazer & Rubinstein, 2004, 2006). Second, a low-cost debate or discussion occurs between the two stakeholders to influence a third party (Rubinstein, 2000; Spector, 2000; Glazer & Rubinstein, 2001, 2005; Krishna & Morgan, 2001). Research on the pragmatics of persuasion has theoretical implications in economics in two areas of research. One is the signaling game or the transceiver game, in which the question is whether there is a sequential set of information. The other is related to the principal-agent model, in which a principal tries to obtain verifiable information from the agent. However, the agent can choose the information to be transmitted.
While traditional economic analysis of language considers language a variable in an economic model, in Rubinstein’s (1996, 2000) series of studies, language itself is treated as a function rather than a variable. Rubinstein’s (1996, 2000) innovation in this field demonstrated the relevance of economic thought for studying the language by presenting several ‘economic type’ analyses to deal with linguistic questions (Zhang & Grenier 2012).
2.2. Empirical Review
As in the theoretical review, the literature on the empirical data on the impact of illiteracy on individuals’ social, economic, and cultural lives is quite abundant. In this empirical review, we do not attempt to list all of the work that has dealt with the question but instead presents a summary.
Concerning poverty, Marinho (2007) demonstrated that low-income families place more importance on child labor than on education because of the latter’s opportunity cost. He found the pressing need to supplement family income was the main cause of school drop-out and illiteracy among young people. Besides, the temptation to quit school was heightened by the perception completing studies was not rewarded with better wages and job prospects. Therefore, poor youth are more inclined to drop out of school and, as a consequence, remain illiterate.
Illiterate people experience higher rates of workplace accidents (WLF, 2015) because they do not understand the written instructions concerning machines’ operation, putting their health and their colleagues at risk. Not using safety equipment increases not only the risk of accidents but also work-related illnesses. This increases the need for medical services (and its associated costs) and causes absenteeism from work. For example, in the United States, wage losses and differences in unemployment rates associated with lack of English skills were between 3.8 percent and 38.6 percent and between 1 percent and 6.5 percent, respectively (Gonzalez, 2005). Also, specific language skills (such as listening, reading, and writing) positively affect income (Chiswick, 1991; Carnevale et al., 2001).
Completion of 12 years of schooling (i.e., completion of secondary education) offers an 80 percent chance of earning sufficient income to move out of poverty (WLE, 2015). In short, illiteracy increases the risk of inadequate professional practices.
Carneiro, Meghir, and Parey (2007) noted that the more literate/educated the mother, the fewer behavioral problems the children had. Comings, Shrestha, and Smith (1992) showed that literate parents were more likely to help their children. This included, for example, meeting with teachers and discussing academic performance with children.
Regarding social cohesion, the links between illiteracy and society are strong and mutually reinforcing (UNESCO, 2005). In modern societies, “literacy skills are fundamental for informed decision-making, for active and passive participation in local, national and global social life, as well as for the development and establishment of social life—the sense of personal competence and autonomy” (Stromquist, 2005). Also, illiterate people suffer from low self-esteem, are less independent, and have less critical thinking skills (UNESCO, 2006). The democratic process requires active participants. When a population is not aware of and fighting for their rights and organizing themselves into political parties, unions, and a wide range of civic organizations, it is impossible to develop adequate public policies that benefit the entire population and strengthen the rule of law (Entreculturas, 2007).
There is evidence that illiteracy limits the knowledge and practices necessary for personal care, especially among women in health. This harms households’ health, hygiene, and nutrition (UNESCO, 2006). Thengal (2013) categorized the effects of illiteracy into three levels: home, workplace, and sexual and reproductive behavior. At the household level, studies have shown a negative impact of illiteracy on mothers’ health awareness. Indeed, illiterate people, especially mothers, are more likely to adopt inadequate nutrition and hygiene practices at home. Literate women, and those who participate in literacy programs, have better skills and follow better health practices than their illiterate counterparts (Thengal, 2013). They also have better access to preventive health measures, such as vaccination and medical visits, among other factors (Burchfield, Hua, Iturry, & Rocha, 2002; UNESCO, 2006). Easterby-Smith and Araujo (1999) and Desai and Soumya (1998) reported that as mothers gain more years of schooling, their ability to acquire knowledge that improves their children’s nutrition increases. If a mother or her children are not treated in time, the disease can progress or even lead to death. In summary, literacy’s health benefits have been documented in a growing number of longitudinal studies, showing that the impacts from adult literacy programs can be even more powerful than those of formal education (EFA Global Monitoring Report Team, 2005).
In summary, this literature review provides an overview of economic factors linked to language and a review of the main traditional theoretical orientations (human capital theory and theory of discrimination) and a newer approach (game theory) in economics. This review focuses on both positive and negative characteristics of education, especially the pragmatics of language in economics. The positive effects are associated with the growing importance of using the language in economic globalization. The negative aspects arise mainly from what Zhang and Grenier (2012) qualify as congenital anomalies (lack of methods and resources, lack of unity in research). Pragmatics examines the influence of context on the interpretation of an utterance. Simultaneously, theoretical game concepts relating to “solutions” are best suited to stable real-world situations that are often “played out” by large populations of players. Thus, the theoretical tools of games can effectively explain linguistic phenomena. Because game theory serves as a bridge, linking economics to the pragmatics of language (Zhang & Grenier 2012), we use it in the framework of this research to explain the effects of functional illiteracy on the living conditions of populations in Congo.
3. Methodology
3.1. Data Sources
In this study, we used the 2007 General Population and Housing Census (RGPH) database, provided by the National Institute of Statistics of Congo because of its opportunity to analyze socio-economic and demographic phenomena. Our study population consisted of heads of households aged 15 to 64 at the time of the census, or 632,502 individuals, 22.4 percent of whom were women.
Study variables
Several qualitative and quantitative variables were used in this research. The endogenous variable was the standard of living for the households. Functional illiteracy was the primary exogenous variable. The other exogenous variables were demographics and socioeconomics.
Endogenous variable-the standard of living. This variable measures household poverty defined based on construction materials of the house, capital goods, and household comfort. We calculated this variable following the method proposed by Filmer and Prichett (1999), Kobiané (2004), and Mboko (2015), which involves applying Principal Component Analysis (PCA) on the variables of household living conditions (possession of certain household goods, household amenities, etc.). For this research, the standard of living is represented by PCA’s well-being scores of household goods and comforts (Mboko 2015).
Exogenous variable-functional illiteracy. This variable has several operational definitions depending on the context. In 1958, UNESCO defined illiteracy as the inability of a person to read and write or understand a simple and brief statement relating to their daily life. Illiterate was then a generic term that did not consider the person’s formal education level or faculties in mathematics. In 1965, the World Congress of Ministers of Education on the Eradication of Illiteracy highlighted the link between literacy and development. It proposed for the first time the concept of functional literacy. Thus, “A person is functionally literate if he can engage in all activities which require literacy for the effective functioning of his group or community and also to enable him to continue using reading, writing, and arithmetic for his own development and that of the community” (UNESCO, 1978).
As defined, the concept of functional illiteracy has the advantage of considering the context of the person. Functional illiteracy is understood as the insufficiency of basic skills relative to the demands of each society’s economic, technological, and cultural contexts. However, this concept has the disadvantage of ambiguity vis-à-vis the definition of the population concerned. One of the most used indicators for literacy is that of education. For some specialists, functional illiteracy describes individuals who have completed four or five primary school years (Sotomayor, 1995). European researchers speak of a minimum of eight years of schooling (Vélis, 1990). In Canada, researchers prefer to talk about the skills under study (literacy, numeracy, and problem-solving in technological environments) rather than literacy (illiteracy), which remains too generic a term. Few definitions match UNESCO’s definition (ISQ, 2015).
For this research, in the absence of data best suited to UNESCO’s new definition, individuals were considered functional illiterate if they were aged 15-64 years at the time of the survey and had not completed at least the last year of the primary cycle, Middle Course 2 (CM2). According to Sotomayor (1995), such people do not have sufficient capacities and skills in reading, writing, and mathematics to cope with daily life demands, work, and social participation. The variable functional illiteracy is binary, with 1 for functional illiterate individuals who have not completed at least CM2. The variable takes a value of 0 otherwise. We assumed that the probability of being poor was higher for the illiterate than for the literate.
Exogenous variable-demographic characteristics. Control variables used to characterize demographic factors included age, sex, marital status, household size, and possession of a birth certificate:
Age: this variable measured the age of the individual at the time of the study. The sign of the expected coefficient was positive (+). We expected the well-being score to increase with age.
Sex: In this research, sex was treated as a binary variable that took the value 1 if male and 2 if female. The expected sign was negative (-). We assumed that the welfare score would be lower for households headed by women than those headed by men.
Marital status: this variable was recoded into the following five modalities: 1 single; 2 married; 3 free unions; 4 divorced/separated; 5 widower/widow. We expected higher well-being scores in households other than those headed by single people or people in common-law unions.
Household size: this variable measured the number of people living in the household. The sign of the expected coefficient was negative (-). In the context of economic insecurity, we expected the well-being to decline with increased household size.
Possession of birth certificate: in the context of this research, the variable possession of birth certificate was a binary variable that took the value 1 if the individual had a birth certificate and 2 otherwise. The expected sign was negative (-). The well-being score is expected to be lower in households headed by individuals without birth certificates.
Exogenous variable-socioeconomic characteristics. The variables used to characterize the economic factors were the place of residence and economic activity.
Place of residence: this variable was binary, taking the value 1 if urban and 2 if rural. The expected sign was negative (−). We assumed that rural areas would have lower welfare scores than those residing in urban areas.
Economic activity: this variable was recoded in two modalities, unemployed = 0; employed = 1. The expected sign of the coefficient was positive (+) based on the assumption that the welfare score would be highest in households headed by people engaged in economic activity.
3.2. Analysis Methods
We modeled the effect of functional illiteracy on living standards scores as a linear regression as follows:
. (1)
This expression can be decomposed such that
.
Considering
, we have
, (2)
where NVi is the well-being score;
Corresponds to the standard of living scores of household i;
a vector of variables characterizing the head of household i;
correspond to the vector of the coefficients of the various exogenous variables; and
represents a random error associated with each head of household, assumed to have zero mean and a variance
(constant).
This model is based on the following assumptions:
H1: the
are determined without errors,
;
H2:
;
H3:
(Homoscedasticity of errors);
H4:
(No autocorrelation of errors);
H5:
(the errors are linearly independent of the exogenous variables); and
H6:
(the errors follow a multidimensional normal law);
This model can be estimated by the classical method of ordinary least squares (OLS). However, in solving this equation, two situations may contradict the stated assumptions. The first relates to the phenomenon’s hierarchization, thus moving the solution approach towards a model with compound errors (Bressoux, 2007; Goldstein, 2011; Rabe-Hesketh & Skrondal, 2012). The second refers to the correlation between errors and certain exogenous variables, particularly in mixed models (Baum, Schaffer, & Stillman, 2003; Steele, Vignoles, & Jenkins, 2007; Hanchane & Mostafa, 2010; Grilli & Rampichini, 2006; Qian, Klasnja, & Murphy 2020). A study entitled “The contribution of multilevel models to educational research,” Bressoux (2007) showed that OLS has obvious limitations when hierarchical data are available. Indeed, in Congo, economic situations arise differently from one department to another (CNSEE, 2011). This hierarchy suggests that model (2) cannot easily analyze functional illiteracy’s effects on households’ living conditions. On the other hand, multilevel models offer adequate solutions and open up critical possibilities for analysis. They allow the effects of environments to be treated as random effects, making it unnecessary to choose a level of analysis. The units are considered to be at their “right” level, and estimates are made simultaneously for the different levels. The multilevel model can be formalized by distinguishing the entries according to the different levels involved in the analysis. Mourji and Abbaia (2013) suggested that to account for the difference in individual variables between departments, and it suffices to assign an index j to
and
. The model then becomes:
(3)
Since
and
are random, they are assumed to be distributed according to a probability function (Kreft & De Leeuw, 1998). We can therefore say
where c represents the average constant for all departments;
the average slope for all the departments;
represents the deviation of each department from the constant (it is a random variable with zero mean and variance
);
represents the deviation of each department from the mean relationship (it is a random variable with zero mean and variance
).
To have the level 2 equations (department level), it suffices to add to the previous system of the equation the characteristics of the departments (vector W). We then obtain
.
By replacing the coefficients
and
in Equation (3), we obtain
. (4)
Because there are now two error terms at level 2, we can estimate an additional parameter: the covariance between the constants and the slopes denoted
. The following shows, in a condensed way, the design of the structure of the random parameters to be estimated at level 2:
.
At level 1,
, and at level 2, the errors
and
, follow a normal distribution, with zero mean, with variances
and
, and with covariance
. The model’s error structure involves the estimation of four random parameters, three at level 2 and one at level 1.
To simplify the expression of (4),
·
;
·
;
·
.
The model becomes
, (5)
where:
·
,a vector of household characteristics (household i of department j);
·
,a vector of joint effects (departmental quantities of household characteristics);
·
,a vector of the individual characteristics of the departments;
·
,theerrortermofthemodel,with
;
·
, the department-level error term, corresponds to the characteristics of unobserved departments and is assumed to have a mean zero and a variance of
Equation (5) is a multilevel random intercept model based on the following assumptions:
h1:
;
;
,the independent variables at each level are not correlated with the terms of the errors of the other levels;
h2:
, the independent variables of level 1 are not correlated at the end of the error of this level;
h3:
and
, the independent variables of level 2 are not correlated with the terms of errors of this level;
h4:
, the level 1 error term
is independent and normally distributed
h5:
, the level 2 error term
is independent and normally distributed
h6:
, the error terms of level 1 and 2 are independent
Thus, the multilevel model makes it possible to amend certain very restrictive OLS hypotheses (Bressoux, 2007). It allows non-independence of errors within each macro unit. It replaces the homoscedasticity assumption with a weaker assumption that the error variance can vary as a linear or nonlinear function of the explanatory variables. In fact, this amounts to studying a possible heterogeneity of relations between the different groups. The multilevel model makes it possible to treat the effects of environments as random effects and no longer requires choosing a level of analysis because they are considered to be at their “right” level. The estimations are done simultaneously for the different levels. Thus, the relationship between NVij and Xij may vary from one department to another. Indeed, the individual household variables do not operate in the same way from one department to another.
Endogeneity of exogenous variables. When there are omitted effects, measurement errors, and/or concurrency in multilevel models, explanatory variables may be correlated with random components. Standard estimation methods do not provide consistent estimates of model parameters (Kim & Frees, 2007). Indeed, unlike model (4), model (5) has several independence assumptions, involving various random components at different levels. The strictest assumption is that not all predictors correlate with all random components. Although this strict assumption is generally assumed without validation, a minimal correlation between certain predictors and a random component can lead to severe bias in estimating model parameters (Wooldridge, 2002; Ebbes et al., 2004; Frees, 2004; Kim & Frees, 2006). In practice, three common sources of correlated effects are encountered (Kim & Frees, 2007): the omission of certain exogenous variables, the measurement errors of the variables, and the simultaneity bias. In this research, we focused primarily on the simultaneity problem and the different approaches researchers use to solve this problem. Under the conditions of simultaneity, the assumptions (h1), (h3) (endogeneity level 2), and (h2) (endogeneity level 1) are violated, which leads to biased estimates.
Several studies dealing with endogeneity in mixed models have focused on solving level 2 endogeneity. Rabe-Heskeith and Skrondal (2012) proposed using Mundlak’s (1978) approach of integrating the level 2 means (
) in the equation. Snijders and Berkhof (2007) pointed out that the inclusion of such a variable makes it possible to disentangle the intra- and inter-group effects. Kim & Frees (2006) proposed using generalized moments (GMM) to solve endogeneity cases in multilevel models. In this research, we adopted an approach that adapts the simultaneous equation approach proposed by Steele, Vignoles, and Jenkins (2007). It consists of solving the system of the following equation:
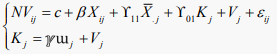 (6)
(6)
where ɯj is a vector of the explanatory variables used as level 2 (department); ℽ is the coefficients vector, and
is the level 2 error term such that
. These two equations are linked at the department level and must be estimated jointly.
In practice, system (6) is estimated simultaneously by maximum likelihood incomplete information (MVIC) thanks to the conditional mixed process (CMP) program developed by Roodman (2011). Indeed, maximizing the log-likelihood of the system (6) requires solving a triple integral. This is not obvious since such a problem does not generally use an analytical solution (Roodman, 2011). The CMP program solves this problem using a digital simulation algorithm of the GHK type (named after Geweke, Hajivassiliou, and Keane). Thanks to microcomputers, speed and power exist today.
The estimation method used in this research was the maximum likelihood method with complete information. Indeed, each of the equations can be estimated individually (Gujarati, 2003). Seeking to estimate the equations individually assumes that the different equations’ error terms are independent of each other, which seemed to be a strong assumption for our estimates. Therefore, we preferred the full information maximum likelihood method. We used CMP developed by Roodman (2011) to carry out this method.
This technique not only has the advantage of taking into account a greater diversity like endogenous variables (discrete, censored, continuous, etc.), but it is also suitable and appropriate for recursive models insofar as it allows consideration of relationships that may exist between the different equations (endogeneity problem) management of selection and simultaneity biases. This means that our system’s systemic estimation would lead to more efficient estimations than the individual estimation of each equation (Roodman, 2011). This characterizes this method’s advantage over others, particularly the two-step Heckman approach, which does not allow simultaneous consideration of several equations with dependent variables of different nature.
4. Presentation and Interpretation of Results
Table 1 presents the results of the estimations of four models designed to illustrate the effect of functional illiteracy of heads of household on household well-being scores. The first model (OLS) is a linear regression of well-being scores on functional illiteracy, with certain household heads used as a control variable. This equation was subsequently estimated by a model (IV) with instrumental variables to highlight the endogeneity of the “employment” variable on well-being scores. We studied the concern about the hierarchization of the standard of living by region in Congo through a mixed linear model (MIXED). Finally, the three previous models’ imperfections led us to use a CMP model (CMP: MIXED-IV). This powerful program, developed by Roodman (2011) under Stata using the MVIC method, makes it possible to solve simultaneity problems at different levels of the hierarchy.
4.1. From Linear Model to Mixed Model
The first modeling approach was linear regression, taking into account the variable’s nature to be explained (the well-being scores). The estimated R2 shows that this model explains 63 percent of the total variability. However, the household income level, here approximated by the head of household’s type of employment, almost certainly correlated with unobserved variables in this equation. In other words, we questioned the endogeneity of employment on household well-being scores. Indeed, Lewchuk et al. (2013) showed that job insecurity directly affects household well-being and community ties, regardless of income. This study showed how precariousness considerably amplified the difficulties of supporting low-income households. This argument suggested using a model to solve simultaneity problems, which is how we used the instrumental variables model (IV). However, the correlation between instrumental variables and exogenous ones is often small, and, in this case, the estimator of the instrumental variable was inefficient (Rabe-Hesketh & Skrondal 2012). For this research, the model was instrumented by the employment variable. We were the household head’s age and the total number of people in the household for the instruments. Durbin and Wu-Hausman endogeneity tests supported the choice of employment as endogenous to well-being scores. However, the instrument correlation test showed only a tiny link with the employment variable, revealing the instruments’ weakness.
The second concern of this approach was to consider regional disparities in poverty in the Congo (ECOM, 2011). This led to the use of a multilevel model of well-being scores. Analysis of the empty model’s inter-regional variance confirmed this approach’s relevance (Fouzi & Abbaia 2013).
4.2. The Conditional Mixed Process
The three approaches presented above all showed limitations in that they led to inefficient estimates for predicting household well-being scores. To overcome these limitations, we looked for a model that would consider both the endogeneity of employment and regional disparities in household well-being in Congo. Researchers are divided on what approach should be adopted to resolve this concern. Qian, Klasnja, & Murphy (2020) and Kim & Frees (2007) presented literature reviews on this issue. Within this research framework, we adopted an approach that used a model with instrumental variables, taking into account the phenomenon studied hierarchy. In fact, it is a system of simultaneous equations integrating the multilevel dimension (Bartus & Roodman, 2014). To model this very complex process, we used the CMP process developed by Roodman (2011).
The CMP (MIXED-IV) column in Table 1 presents the multilevel simultaneous equation system estimates of functional illiteracy on household well-being scores resulting from the CMP. The atanhrho statistic, which measures the covariance of the terms of error of the two equations used, was significant, indicating that employment is endogenous to household well-being scores. Also, taking into account the multilevel dimension here made it possible to significantly improve the estimators’ quality compared to the estimators obtained from the other three models (OLS, IV, and MIXED).
Estimates show that functional illiteracy had a negative and statistically significant effect on household well-being scores, all other things being equal. Indeed, functional illiteracy reduced the household well-being scores by 10.6 percent. The marginal effect of functional illiteracy was negative on the order of 10.6 percent (Table 2). In other words, the household head’s functional illiteracy status reduced the likelihood of being well-being by 10.6 percent.
![]()
![]()
Table 1. Net effects of functional illiteracy on household well-being scores
Source: Authors.
![]()
Table 2. Marginal effects of the household well-being score equation
Source: Authors.
Two important facts to underline are the findings related to female heads of household and married heads of household. For households headed by a woman, the probability of well-being increased by 17 percent, all other things being equal. This was an unexpected result of this research. In contrast, when the head of the household was married, well-being scores decreased by 4 percent, with a negative marginal effect of around 11 percent on the probability of well-being. This is also an unexpected result of this research.
5. Discussion
The various estimates (OLS, IV, MIXED, CMP) show a constant and negative significant effect of functional illiteracy on the well-being score. We also observe that the coefficients associated with functional illiteracy change from one estimate to another. However, the coefficient obtained by the instrumental variables method seems better adjusted than those of the multilevel and ordinary least squares methods. In comparison, the coefficient estimated by the CMP method is better accommodated than that obtained by instrumental variables. This tends to confirm Roodman (2011) conclusions, according to which the systemic estimation of the equations makes it possible to obtain more efficient coefficients than the individual estimate of each equation.
Regardless of the estimation method used, our results clearly show that illiterate populations are more likely to live in poverty than literate ones in Congo. In other words, functional illiteracy constitutes a form of discrimination of specific categories of people towards access to well-being. This tends to confirm the work of Lang (1986) according to which members of minority language groups may be marginalized in the labor market due to discrimination so that they cannot get a good job, and their income cannot be obtained, can, of course, not be high. This discrimination makes it possible, ultimately, to place illiteracy at the center of a signaling game of the transmitter-receiver type, in the sense of Rubinstein (2000), where the signal emitted by functionally illiterate people on the labor market does not allow to access employment or to have a poor paid job; this does not let them get out of poverty. Our results agree with those of Gonzalez (2005), and Carnevale et al. (2001), where functional illiteracy has adverse effects on the unemployment and income of individuals.
6. Conclusion and Policy Implications
This research’s general objective was to analyze the effect of functional illiteracy on households’ living conditions in Congo. To do this, we used the CMP model based on data from the 4th general census of the population and housing of the Congo. Our approach was based on an adaptation of game theory in the economics of language, proposed by Rubinstein (1996).
The results show that functional illiteracy significantly conditions households to live in precariousness. This result confirms the importance of education, particularly the mastery of literacy and numeracy, in the fight against poverty. Thus, if we consider the process of gaining literacy as a game between the school and the individual (transceiver), the functional illiteracy-well-being score relationship can serve as an empirical framework to illustrate game theory’s relevance to language economics as understood by Zhang and Grenier (2012).
Two implications can be drawn from this study. The first, purely theoretical, consists of curbing what Zhang and Grenier (2012) have qualified as a congenital anomaly by carrying out more theoretical and above all empirical work to promote language both as a variable and as a function in economics sciences. The second, more political, is to encourage formal education programs at least until the secondary cycle, not only for children of school age (6 - 18 years in Congo) but rather for the entire population (six years of age or older). Indeed, results have shown, regardless of age and sex, heads of households with the primary level suffer severely from the effects of poverty compared to those with the secondary level or above, even after isolating particular economic effects such as the agglomeration effect (region of residence and access to employment).
This study has two significant limitations. The first is related to the quality of the functional illiteracy variable. Indeed, in the absence of information conforming to the UNESCO (1978) definition on this concept, individuals with primary level were considered to be functional illiterates. The second limitation of the study is the lack of biographical or historical data allowing an assessment of individual situations’ evolution over time.