Topology Data Analysis Using Mean Persistence Landscapes in Financial Crashes ()
1. Introduction
Topological data analysis (TDA) extracts topological features by examining the shape of the data through persistent homology to produce topological summaries. Two topological summaries, the persistent barcode [1] [2], and the persistent diagram [3], provide visual representation of persistent topological features. However, these topological summaries lack geometric properties and do not have a unique (Fréchet) mean [4], which makes it difficult to conduct statistical analysis and machine learning. In fact, Bubenik [5] states effective algorithms do not exist for computing means for a wide variety of examples, but he notes that [6] and [7] have made noteworthy advancement in this direction.
In Bubenik [5], the persistence landscape is provided as an alternative topological summary. The computation time is less for the persistence landscape than the persistence barcode and persistence diagram, because the persistence landscape is a sequence of piece-wise linear functions. Yet, the main advantage of using a persistence landscape is that they are situated in a separable Banach space, which means that we may use probability theory and random variables. After defining the persistence landscape and the norms of persistence landscapes, Bubenik [5] further develops his work by introducing the mean or average persistence landscape, which may be used for statistical analysis and again is something the persistence diagram and persistence barcode do not have. Furthermore, he proves many statistical properties for using persistence landscapes, such as convergence, stability, the Central Limit Theorem, and the Strong Law of Large Numbers (SLLN), which is important, so that one may conduct statistical inference. In particular, Bubenik [5] conducts a permutation test using multiple persistence landscapes to obtain a p-value (see Section 2.5, Section 2.6, Section 3.4), which is something that also cannot be done with persistence diagrams and persistence barcodes. This permutation test and the persistence landscape can be found in [8]. Other notable topological data analysis applications include the discovery of a subgroup of breast cancers [9], an understanding of the topology of the space of natural images [10], brain signals [11], and pre-clinical spinal cord injury [12].
With this alternative topological summary and the ability to conduct statistical inference, we bring our focus to critical transitions in complex dynamical systems, in particular, the financial market. Scheffer et al. [13] asserted that predicting critical transitions in a complex dynamical system prior to occurring is unreliable and very challenging, because the state of the complex system may not fluctuate substantially before reaching a critical threshold. However, in their work, they found for vast classes of systems, early warning signals may exist to indicate when a critical transition is imminent. Even though Scheffer et al. [13] presented examples of early warning signals in ecosystems, time series, climate dynamics, and epileptic seizures, there is not an example of an early warning signal for a financial crash. While Scheffer et al. [13] clarified that some predictability may be employed by experts, in general financial markets are complicated to predict. Although Scheffer et al. [13] referenced excellent works with financial early warning indicators, such as the VIX (volatility based index), systematic relationships in the variance and first order auto-correlation, and correlation increases across returns in falling markets, it was not relevant to our study, which leads us to research more about financial market dynamics.
Ensor and Koev [14] focused on the multivariate GARCH (MGARCH) and the hierarchical regime switching dynamic covariance (HRSDC) models, in which both models examined the co-variance structure within and between market sectors for the time period January 2, 1998 to December 2001. The HRSDC model provided early detection of several anomalous behaviors, such as the decline of Enron, the unusual returns for Silicon Graphics, and the fall of Lehmann Brothers. The detection of these anomalous behaviors is based on price movement of individual securities when viewed as a system of securities with the correlation within and between sectors. Therefore, Ensor and Koev [14] demonstrated a nested model is useful for understanding the correlation structure between different market sectors and how these sectors interacted as the market changes between regimes.
While Ensor and Koev [14] study prompted us to use ETF sectors in our study and is effective in identifying anomalous behaviors, such as the decline of Enron and the fall of Lehnman Brothers, our interest is to use TDA to detect early warning signals for financial crashes and examine topological features changing within time with statistical significance. A number of recent studies have explored the use of TDA on financial time series data to detect early warning signals of financial crashes. Gidea [2] analyzed the cross correlation network of the daily returns (adjusted closing prices) of the Dow Jones Industrial Average (DJIA) stocks listed as February 19, 2008 from January 2004 to September 2008. They tracked the topological changes when approaching a critical transition and showed some presence of early signs of a critical transition. On the other hand, Gidea et al. [15] analyzed four major cryptocurrencies (Bitcoin, Ethereum, Litecoin, and Ripple) before the beginning of 2018 and showed these cryptocurriences exhibiting highly erratic behavior. The paper introduced a method that combines TDA with machine learning to understand what happens before a critical transition. Moreover, they use Takens’ theorem, the time delay embedding theorem, and C1-norms of persistence landscapes. While the paper has valid analysis, our interest is in stocks and ETF sectors rather than cyprtocurrencies.
Alternatively, Gidea and Katz [16] investigated the daily log-returns of four stock indices (DJIA, S&P500, NASDAQ, and Russell 2000) from December 23, 1987 and December 08, 2016, where the topological properties of these stock indices were examined. This paper uses a sequence of a point cloud data set with a sliding window. Gidea and Katz [16] provided an excellent framework using persistence diagrams, persistence landscapes, and norms for persistence landscapes and we were able to replicate all of their results for 2000 and 2008 crashes. They demonstrated that the variance as defined in [17] shows rising trends, we are not convinced about the average spectral densities and auto-correlation function (ACF) with their associated Kendall-Mau tests demonstrated trends.
While these papers provide insightful groundwork for TDA in financial markets and cryptocurrencies, such as showing how to use cross correlation networks to track topological changes, using TDA with machine learning to understand what happens before a critical transition, and using the norms of persistence landscapes to indicate an approaching critical transition, these financial papers lack statistical inference. We are motivated to explore how the topological features change within a given time period for stocks and ETF sectors and find any statistical significant using a permutation test [5] [8], which we discuss in detail in Section 2.5, Section 2.6, and Section 3.4.
While we acknowledge the previous cited authors, we deem our contributions as an empirical framework that adapts their analytical models to new data sets and expand by conducting statistical inference. Similar to Gidea and Katz [16], we investigate the same four major indices (DJIA, S&P500, NASDAQ, and Russell 2000), but we extend our data set to include 10 ETF sectors (Consumer Discretionary, Consumer Staples, Energy, Financials, Health Care, Industrials, Materials, Information Technology, Utilities, and Index) for January 4, 2010-July 1, 2020 to examine their topological features to detect a critical transition or transitions. Moreover, we generate several topological summaries, norms for persistence landscapes
and
, and conduct statistical inference on how these topological features change over time. In particular, we want to compare only sliding windows within a sliding step of one day from each other, which will be done separately for all the stock indices and for all the ETF sectors. We also compare all the stock indices against ETF sectors within the same sliding window. Our hypotheses tests will distinguish for two groups at a time if the means of topological features are the same either within a sliding step of one day in their respective sliding windows or within the same sliding window. The statistical tests of interest have not been seen before in any financial papers and will be our main contribution. The remainder of this paper is organized as follows.
In Section 2, we provide background information on algebraic topology, homology, constructing the Vietoris-Rips complex, persistent homology, topological summaries, norms of persistent landscapes, and statistical inference. In Section 3, we outline our methods for obtaining the data, constructing a sequence of a point cloud data, using persistent homology on a sequence of a point cloud data set, generating topological summaries, and performing statistical inference. In Section 4, we present our findings from our data. In Section 5, we discuss and provide an interpretation of our results. In Section 6, we conclude the paper.
2. Background
This study presents a topological data analysis of financial time series data. Here we provide background material about four relevant areas: algebraic topology, homology, topological summaries, and norms for persistent landscapes. We apply topological data analysis to a sequence of point cloud data sets to examine their topological properties within a point cloud matrix of d 1-dimensional time series. For our analysis, a sequence of point cloud data sets denoted
is shown below:
(1)
where each point in the sequence is expressed as
, d is the column number from a 1-dimensional time series, w is the sliding window size for a certain number of trading days (
) with a sliding step of one day, and
. To obtain q, the difference is taken between the total number of days of the daily log returns (
) and one less than the sliding window size
, so that q becomes
or
. The total number of days of the daily log returns (
) is the total number of trading days (
) minus 1 or
. To approximate the daily log returns, the formula is discussed in Section 3.1. So, every point cloud is compromised of a
matrix, where
[16]. Note our method uses a sliding window w as seen in [16] and it does not apply the sliding window embedding theorem or Takens’ theorem. In the next two subsections, we provide background information on algebraic topology and persistent homology, so that for every point cloud, we generate topological summaries and compute their
norms based on their corresponding persistence landscapes to conduct statistical inference. For a more in depth background, we refer readers to [3] [5] [18] [19] [20] [21].
2.1. Algebraic Topology
To produce topological summaries, we must first construct a Vietoris-Rips filtration for each point cloud in a sequence of point cloud data sets, which requires understanding simplices and simplicial complexes and are defined below [19]:
Definition 2.1 Let
be a geometrically independent set in
. We define the n-simplex
spanned by
to be the set of all points x of
such that:
(2)
and
for all i.
Definition 2.2 A simplicial complex K in
in a collection of simplices in
such that:
· Every face of a simplex of K is in K.
· The intersection of any two simplexes of K is a face.
2.2. Homology
In homology, we are interested in a vector space
to a space X for each natural number
, because
counts the number of k-dimensional holes in X. For example,
counts the number of 0-dimensional holes or the number of connected components in X, while
counts number of 1-dimensional holes or the number of loops in X. Furthermore, the algebraic structures must be homotopy invariant, meaning they must not change through deformations. Yet, it is very challenging to determine the homology of arbitrary topological spaces, because it is computationally inefficient, so instead we approximate using simplicial complexes.
Now that simplicial complexes have been defined, we are introducing the pth homology of a simplicial complex K. First, we denote the field with two elements as
. Second, for a given simplicial complex K, we let
denote the
-vector space with basis given by the p-simplices of K. Third, for any
, we define the linear map:
(3)
The kernel of
is the subgroup
of
and is called the group of p-cycles. The image of
is the image
is the subgroup of
of
and is called the group of p-boundaries [19].
Definition 2.3 For any
, the pth homology of a simplicial complex K is the quotient vector space is defined as:
(4)
Its dimension is defined by:
(5)
which is called the pth Betti number of K [22].
The p-cycles that are not boundaries represent p-dimensional holes, which the pth Betti number counts. For the pth homology of a filtered simplicial complex K, we apply definition 2.3 and define as:
Definition 2.4 Let K be a finite simplicial complex, and let
be a finite sequence of nested subcomplexes of K. The simplicial complex K with such a sequence of subcomplexes is called a filtered simplicial complex. The pth persistent homology of K is the pair
where
for all
,
are the linear maps induced by the inclusion maps
[22].
The pth persistent homology of a filtered simplicial complex provides more information about the maps between each subcomplex than the homologies of single subcomplexes, which is explained further in Section 2.2.2. While there are several filtered simplicial complexes, such as the Cech, Alpha, and Delaunay, we chose the Vietoris-Rips complex, because it is computationally efficient [22].
2.2.1. Vietoris-Rips Construction
Definition 2.5 Let
be a collection of points in
. Given a distance
,
denotes the simplicial complex on n vertices
, where an edge between the vertices
and
with
is included if and only if
or generally the k-simplex are included with vertices
if and only if all of the pairwise distances are at most
. This type of simplicial complex is called a Vietoris-Rips complex [8] [16].
When
, the Vietoris-Rips complex forms a filtration,
, which by definition 2.4 is a filtered simplicial complex. While there is no clear criteria for select
, [23] used
in their study. In this study, the Vietoris-Rips complex of
is denoted as
and follows definition 2.5, where
is a sequence of point cloud data sets as given by Equation (1). Moreover, the filtration of
is shown below:
(6)
where q is the difference between the number of the daily log returns and the sliding window
or
. By definition 2.4,
is a filtered simplicial complex.
2.2.2. Persistent Homology
Using definition 2.4 and definition 2.5, it is possible to find the p-dimensional homology of the Vietoris-Rips complex of
labelled as
with coefficients in field
for small values of p and for different values of
[8]. Recall from section 2.2,
is a vector space and
counts the number of p-dimensional holes. When
, we apply definition 2.4 to the filtration
, which induces linear maps
as seen below:
(7)
where
. Each
is a vector space whose generators correspond to holes in
, and the linear maps
allow us to track the generators from
. A suitable basis is selected by applying the Fundamental Theorem of Persistence Homology.
Theorem 2.1 (Fundamental Theorem of Persistent Homology) The Fundamental Theorem of Persistent Homology states there is a choice of basis vectors
for each
such that each map is determined by a bipartite matching of basis vectors [22].
Given Theorem 2.1, there is a choice of basis vectors of
, such that one may construct a well-defined and unique collection of disjoint half-open intervals, where a generator
corresponds to a half-open interval
, which represents the lifetime of x. The endpoints
and
refer to x first appearing and finally disappearing respectively in
. Specifically, if
is not in the image of
, then x is born in
. Conversely, if
is the smallest index for which
, then x dies in
. Persistence is determined by a generator’s lifetime in the half-open interval, where a generator is considered more persistent the longer it appears in the half-open interval. If
for all
in
, then x lives forever, and its lifetime is represented by the interval
[22]. Then, the set of vector spaces
together with the corresponding linear maps is referred to as a persistence module, which is the foundation for constructing topological summaries.
2.3. Topological Summaries
To visualize, construct, and produce topological summaries, Theorem 2.1 is used to select the choice of basis vectors from
and the corresponding linear maps
, in which all topological summaries are derived from the persistent modules.
2.3.1. Persistence Module, Persistence Barcode, Persistence Diagram
Definition 2.6 A persistence module is defined as a vector space
for all
and linear maps
for all
such that:
1)
is the identity map;
2) For all
.
For additional information about the construction of a persistence module, see [5]. There are three main types of topological summaries associated with a persistence module. The first type of topological summary is a called a barcode. It represents a finite collection of disjoint half-open intervals
, in which each interval’s endpoints are a birth-death pairs, (b) and (d) respectively. In particular, an interval starts with the time of birth (b) and ends with the time of death (d) of a topological feature. The pth barcode is denoted by
. A topological feature’s survival or persistence is represented by the interval’s length. The second type of topological summary is the pth persistence diagram, which is denoted as
, where
and
are the bar codes intervals’ end points and
.
Unfortunately, the geometric properties of the barcodes and persistence diagrams present a difficult challenge for the calculation of means and variances, since two barcodes or two persistence diagrams may not have the same unique Friechet mean, which means statistical inference cannot be done. While the barcode and the persistence diagram are conventional topological summaries, Bubenik [5] showed how the persistence landscape is a better alternative.
2.3.2. Persistence Landscapes and Mean Landscape
Bubenik and Dlotko [18] proved numerous statistical properties of persistence landscapes that we may use for statistical inference, such as stability, convergence, central limit theorem, and strong law of large numbers. The persistent landscape and mean landscape are also used as topological summaries to indicate how persistence changes by examining the number of peaks. First, given a pair of numbers
with
, the piecewise linear (PL) function
is defined by [18]:
(8)
Second, given a persistence module, M, the persistence landscape may be defined as the function
given by:
(9)
Third, given a persistence diagram
for
,
, and the persistence landscape is defined as follows:
(10)
where kmax denotes the kth largest element. Using Equation (10) for
, the persistence landscape of
denoted by
is the following:
(11)
where
. This results in the following lemma from [5]:
Lemma 2.2
The persistence landscape has the following properties:
1)
,
2)
, and
3)
is 1-Lipschitz.
From Equation (10), the persistence landscape is obtained and used to calculate the mean landscape, which is defined below:
Definition 2.7 Let
be independent and identically distributed copies of Y, and let
be corresponding persistence landscapes. The mean landscape
is given by the point wise mean, in particular,
, where
(12)
Using Equation (12) for
, we have the following:
(13)
where
. The mean landscape is used in section 2.5 and section 2.6.
2.4. Norms for Persistence Landscapes
Gidea and Katz [16] applied
norms of the persistence landscapes to identify the signs of a financial crash, which usually occurs within a time of high variance and cross-correlations among stocks or ETFs, and demonstrated that
and
norms of the persistence landscapes of four stock indices exhibited significant rising trends before the financial crashes. We adopt their approach in our study.
Therefore, for real valued functions on
, for
, p-norms of persistence landscapes are defined as:
(14)
and for
,
(15)
Applying Equation (14) to our sequence of point cloud data sets
results in:
(16)
where
.
2.5. Statistical Inference: Part I
To compare the topological features between two groups, the persistence landscape is used to conduct a hypothesis test and statistical inference, which require several assumptions provided by [5]. First, the persistence landscapes lie in a separable Banach space
for
, where
. Second, Y is to be a random variable on some underlying probability space
with a corresponding landscape
. Third, if we have
, then
is the random variable and
is the corresponding topological summary statistic. To avoid confusion, we use Y instead of X as a random variable, because our sequence of point cloud data sets uses the variable
. In addition, Bubenik [5] proved the convergence of persistence landscapes using the Strong Law of Large Numbers and the Central Limit Theorem, which is extremely important for setting up our random variables and hypothesis test. Our random variable Y is defined as:
(17)
where
is a continuous linear functional,
, and Y satisfies the (SLLN) and (CLT) as seen in [5], which implies Y has an adequate sample size and follows an approximately normal distribution.
The statistical properties and definitions above are utilized to a conduct hypothesis tests with corresponding p-value based on a permutation test. To compare the topological features of two groups,
and
, where
and
are samples taken from these groups respectively, and
and
are the corresponding landscapes respectively. The associate sample values of
and
are denoted as
and
and the corresponding landscapes of these sample values are labelled as
and
. We apply Equation (17) to
and
, so the functional of
and
are as follows:
(18)
Recall the sample mean is
, so the sample means of the
and
are the following:
(19)
where again
and
are the samples taken from
and
. We assume that
and
are the expectations of
and
. So,
and
are assumed to be the population means of
and
. Therefore, the statistical hypothesis is:
(20)
To test the null-hypothesis, we use a two sample permutation test. Let
(21)
Using Equation (21),
of the test statistic are calculated for permutations
. The observed value of the test statistic is expressed as
. The p-value is calculated by comparing
with
and averaging the number of times
. Thus, Equation (21) becomes:
(22)
A general form of Equation (22) is:
(23)
Hence, using Equation (22) and every instance where
, the p-value is obtained as:
(24)
To measure the statistical significance, [8] used a significance level
in their study, which we incorporate in our study. We may apply the above assumptions, equations, and definitions to compare the topological features of more groups.
2.6. Statistical Inference: Part II
Instead of conducting one hypothesis test, multiple hypotheses tests are conducted to determine how the topological features in our sequence of point cloud data sets
change within a particular time frame. The hypotheses tests are done on all the sliding window matrices within
. In particular, two adjacent sliding window matrices are compared, where adjacent means the sliding window matrices differ by a sliding step of one day. For example, the sliding window matrices
and
would be compared, while the sliding window matrices
and
would not be compared. Therefore, the assumptions, equations, and definitions from section 2.5 are applied to
. When hypotheses tests are performed, there are
random variables (see Equation (1)), which is also the size of the sequence of the point cloud data set
.
So, we let
be random variables, where
are taken as samples from these groups respectively, and
are the corresponding landscapes respectively. The associate sample values of
are denoted as
,
,
,
, and the corresponding landscapes of these sample values are labelled as
,
,
,
. The functional in Equation (17) is used to define the following for
:
(25)
where
. Recall the sample mean is
, so the sample means of the
as follows:
(26)
where
. We assume that
are the expectations of
. So,
are assumed to be population means of
, and the statistical hypotheses are:
(27)
where
. To test the null-hypothesis, we use a two sample permutation test with statistics,
(28)
where
. Using Equation (28),
of the test statistic are calculated for permutations
. The observed value of the test statistic is expressed as
. The p-value is calculated by comparing
with
and averaging the number of times
. Using Equation (23), Equation (28) becomes:
(29)
where
. Hence, using Equation (29) and every instance where
, the p-value is obtained as:
(30)
where
. In our study, we also conduct hypotheses tests between two sequences of point cloud data sets,
and
, within the same sliding window, so using the same assumptions, definitions, and results from this section. The only difference is a change in subscripts and superscripts. This case is presented in Section 3.4.
3. Methods
In this section, we describe the methods to obtain the data and analyze the financial time series using topological data analysis, statistical inference, and RStudio [23]. The data, which were obtained from Yahoo Finance, consisted of daily adjusted closing prices (amended for corporate actions such as stocks and dividends) for four major US stock indices: S&P 500, DJIA, NASDAQ, and Russell 2000 and 10 ETF sectors between January 4, 2010 and July 1, 2020 (2641 trading days). During this time period, a decline in the daily log returns happened on March 16, 2020. In order to examine this date of interest, we limited our data sets to 1001 trading days (
) before March 16, 2020 to observe any patterns in the
norms and determine any critical thresholds. To analyze the data, we first approximated the daily log returns of the adjusted closing prices. A return is defined as
, where
is the actual value (adjusted closing price) of the desired stock index or ETF sector. The daily log returns are defined as:
which is an approximation of a return [24]. Since the daily log returns are forward daily changes, then the time frame of the daily log returns is from January 5, 2010 to June 30, 2020.
3.1. Point Cloud Data
After approximating the daily log returns, we designed two sequences of point cloud data sets, each with a sliding window of
and a sliding step of one day, which is based on the same method found in [16]. The first sequence of point cloud data set denoted by
examined the four major US stock indices (
), which resulted in a 4 × 50 matrix for each individual point cloud for a total of
point clouds as seen below from using Equation (1):
(31)
The second sequence of point cloud data set denoted by
examined the 10 ETF sectors (
), which yielded a 10 × 50 matrix for each single point cloud for a total of
point clouds as seen below from using Equation (1):
(32)
3.2. Vietoris-Rips Complex and Persistent Homology
Next, we constructed Vietoris-Rips complexes and filtration for each point cloud in
and
from definition 2.4, definition 2.5, and Equation (6) and R-package “TDA” [25]. The Rips filtration for all the stock indices and all the ETFs are denoted by
and
respectively for
. For the maximum filtration, we used
and
, which are based on similar methods found in [16]. Therefore, we obtained the following Rips filtration:
(33)
(34)
where
. Based on the Equations (6), (33), and (34), we computed only the
dimensional homology
with coefficients in the field
from Equation (7) as follows:
(35)
(36)
where
. Also, we are only interested in the persistence of loops in as they appear in each point cloud during the transition states of the market, which is why we did the first dimensional homology. From definition 2.4, the filtration from Equations (33) and (34) induced a sequence of linear maps
and
. The images of these maps are the persistent homology groups. The collection of vector spaces
and
along with the corresponding linear maps is a persistent module, which leads us to the topological summaries.
3.3. Topological Summaries
By modifying the R script in [5], the first dimensional persistence diagrams denoted by
and
for each point cloud data set were used along with Equations (10) and (11) to produce the analogous first dimensional persistent landscapes
and
as seen below:
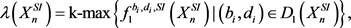 (37)
(37)
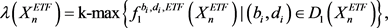 (38)
(38)
where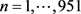 . Next, the norms of the persistence landscapes
. Next, the norms of the persistence landscapes 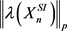 and
and 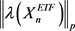 were computed for
were computed for  and
and 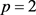 using Equations (14)-(16). The norms of the persistence landscapes and the daily log returns were plotted in juxtaposition, where it is important to remember that a point in the norms of persistence landscapes refers to a sliding window of 50 trading days in the daily log returns. After generating the topological summaries, the mean landscape is constructed using definition 2.7 and Equations (12)-(13) for the time period between July 1, 2019 and July 1, 2020 (253 trading days) or the time frame between July 2, 2019 to June 30, 2019 (252 days for the daily log returns). For this reason, the sequences of point cloud data sets will go from
using Equations (14)-(16). The norms of the persistence landscapes and the daily log returns were plotted in juxtaposition, where it is important to remember that a point in the norms of persistence landscapes refers to a sliding window of 50 trading days in the daily log returns. After generating the topological summaries, the mean landscape is constructed using definition 2.7 and Equations (12)-(13) for the time period between July 1, 2019 and July 1, 2020 (253 trading days) or the time frame between July 2, 2019 to June 30, 2019 (252 days for the daily log returns). For this reason, the sequences of point cloud data sets will go from 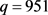 to
to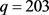 . Also, recall that the daily log returns are forward daily changes, so the time frame of the daily log returns are from July 2, 2019 to June 30, 2020. We assigned
. Also, recall that the daily log returns are forward daily changes, so the time frame of the daily log returns are from July 2, 2019 to June 30, 2020. We assigned 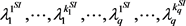 and
and 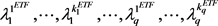 to be the corresponding landscapes for all the point clouds in
to be the corresponding landscapes for all the point clouds in 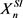 and
and 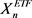 to obtain the mean landscapes as seen below:
to obtain the mean landscapes as seen below:
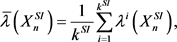 (39)
(39)
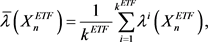 (40)
(40)
where 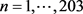 for
for  and
and 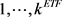 samples [5]. We are interested in time period between July 1, 2019 and July 1, 2020, which has 253 trading days, because we wanted to observe market conditions prior to our market decline of interest and see if we are able to detect any critical transitions. Therefore, we provide summary statistics for this time period for all the stock indices and all the ETF sectors. The daily log returns, persistent diagrams, persistent landscapes, and the mean landscapes for sliding windows of 50 trading days were generated and plotted together for July 2, 2019 and June 30, 2020, but we only highlighted specific date ranges near our market fall of interest and peaks in the norms in the persistence landscape for all the stock indices and ETF sectors, which is discussed in Section 4.
samples [5]. We are interested in time period between July 1, 2019 and July 1, 2020, which has 253 trading days, because we wanted to observe market conditions prior to our market decline of interest and see if we are able to detect any critical transitions. Therefore, we provide summary statistics for this time period for all the stock indices and all the ETF sectors. The daily log returns, persistent diagrams, persistent landscapes, and the mean landscapes for sliding windows of 50 trading days were generated and plotted together for July 2, 2019 and June 30, 2020, but we only highlighted specific date ranges near our market fall of interest and peaks in the norms in the persistence landscape for all the stock indices and ETF sectors, which is discussed in Section 4.
3.4. Statistical Inference
While the topological summaries were useful for examining topological features, we were also interested in finding statistical significant for any changes of these topological features within time. The time period of interest is July 1, 2019 to July 1, 2020, which has ![]() trading days.
trading days.
We make the same assumptions from Section 2.5 and Section 2.6. Our random variables will derive from our two sequences of point cloud data sets, ![]() and
and![]() . Since our time period of interest has 253 trading days, our sequence of point cloud data sets are size
. Since our time period of interest has 253 trading days, our sequence of point cloud data sets are size![]() . For this reason, we have
. For this reason, we have ![]() random variables in each sequence of point cloud data sets.
random variables in each sequence of point cloud data sets.
For all the stock indices and all the ETF sectors, we have ![]() and
and ![]() be random variables respectively for
be random variables respectively for ![]() and
and ![]() samples for these groups respectively and
samples for these groups respectively and ![]() and
and ![]() are the corresponding landscapes respectively for
are the corresponding landscapes respectively for![]() . The associate sample values of
. The associate sample values of ![]() and
and ![]() are denoted as
are denoted as ![]() and
and ![]() respectively and the corresponding landscapes of these sample values are labelled as
respectively and the corresponding landscapes of these sample values are labelled as ![]() and
and ![]() respectively.
respectively.
The functional in Equation (25) is used to define the random variables for all the stock indices and all the ETFs as follows:
![]() (41)
(41)
![]() (42)
(42)
where ![]() for
for ![]() and
and ![]() samples. We recall the sample mean
samples. We recall the sample mean![]() , so using Equation (26) for the sample means for the random variables of all the stock indices and ETF sectors, we have the following:
, so using Equation (26) for the sample means for the random variables of all the stock indices and ETF sectors, we have the following:
![]() (43)
(43)
![]() (44)
(44)
where ![]() for
for ![]() and
and ![]() samples. We assume that
samples. We assume that ![]() and
and ![]() are the expectations and population means of
are the expectations and population means of ![]() and
and ![]() respectively for
respectively for![]() . We set up three sets of hypotheses test and an analogous p-value based on a permutation test. For our first two sets of statistical hypotheses, we desire separate hypotheses tests for all the stock indices and for all the ETF sectors within a one day lag in their respective sliding windows. Our statistical hypotheses will distinguish for two groups at a time if the means of topological features are the same within a one day lag in their respective sliding windows and point cloud data sets as seen below:
. We set up three sets of hypotheses test and an analogous p-value based on a permutation test. For our first two sets of statistical hypotheses, we desire separate hypotheses tests for all the stock indices and for all the ETF sectors within a one day lag in their respective sliding windows. Our statistical hypotheses will distinguish for two groups at a time if the means of topological features are the same within a one day lag in their respective sliding windows and point cloud data sets as seen below:
![]() (45)
(45)
![]() (46)
(46)
For our third set of statistical hypotheses, we also wish to compare all the stock indices against all the ETF sectors within the same sliding windows. Our statistical hypotheses will determine for two groups at a time if the means of topological features are the same within the same sliding window as shown below:
![]() (47)
(47)
where in Equations (45)-(47),![]() . To test the null hypotheses found in Equations (45) and (46), we used a two-sample permutation test from Equation (28) to obtain:
. To test the null hypotheses found in Equations (45) and (46), we used a two-sample permutation test from Equation (28) to obtain:
![]() (48)
(48)
![]() (49)
(49)
where ![]() for
for ![]() and
and ![]() samples. To test the null hypotheses found in Equation (47), we used a two-sample permutation test from Equations (28) to obtain:
samples. To test the null hypotheses found in Equation (47), we used a two-sample permutation test from Equations (28) to obtain:
![]() (50)
(50)
where ![]() for
for ![]() and
and ![]() samples. Using Equations (48), (49), and (50),
samples. Using Equations (48), (49), and (50), ![]() of the test statistic were calculated for permutations
of the test statistic were calculated for permutations![]() . The observed value of the test statistic is expressed as
. The observed value of the test statistic is expressed as![]() . The p-value is calculated by comparing
. The p-value is calculated by comparing ![]() with
with ![]() and averaging the number of times
and averaging the number of times![]() . Using Equation (23), Equations (48) and (49) become:
. Using Equation (23), Equations (48) and (49) become:
![]() (51)
(51)
![]() (52)
(52)
Similarly, Equation (50) becomes:
![]() (53)
(53)
where in Equations (51)-(53), where ![]() for
for ![]() and
and ![]() samples. Hence, using Equations (48) and (52) and every instance where
samples. Hence, using Equations (48) and (52) and every instance where![]() , the p-values were obtained as:
, the p-values were obtained as:
![]() (54)
(54)
![]() (55)
(55)
Similarly, using Equation (53) and every instance where![]() , the p-value was obtained as:
, the p-value was obtained as:
![]() (56)
(56)
where in Equations (54)-(56),![]() . To evaluate statistical significance, using Equations (41)-(56), a permutation is completed at a significance level of
. To evaluate statistical significance, using Equations (41)-(56), a permutation is completed at a significance level of ![]() for homology in degree 1 for all our hypothesis tests. Since we are only interested in the number of loops, we will look at homology in degree 1. All these hypothesis testing methods were modified from the R script in [5]. After finding the p-values, we plotted the daily log returns with the p-values that were less than or greater than or equal to our significant level
for homology in degree 1 for all our hypothesis tests. Since we are only interested in the number of loops, we will look at homology in degree 1. All these hypothesis testing methods were modified from the R script in [5]. After finding the p-values, we plotted the daily log returns with the p-values that were less than or greater than or equal to our significant level ![]() for either all the stock indices or all the ETF sectors along a sliding window of 50 trading days.
for either all the stock indices or all the ETF sectors along a sliding window of 50 trading days.
4. Results
The goal of this study is to detect a statistically relevant critical transition and characterize any changes in topological features over time. To assess the statistical significance of observed differences in the topological features that change over time, we used a permutation test. For degree 1, we obtained ten sample values of the random variables ![]() and
and ![]() as in Equation (41). Using Equations (43), (45), (48), (51), and (54), the permutation test is implemented with a significance level
as in Equation (41). Using Equations (43), (45), (48), (51), and (54), the permutation test is implemented with a significance level ![]() when comparing all stock indices in different sliding windows between July 1, 2019 and July 1, 2020. The permutation test yields 164 p-values of 0.0000, 2 p-values of 0.001, and 36 p-values of 1 for homology in degree 1.
when comparing all stock indices in different sliding windows between July 1, 2019 and July 1, 2020. The permutation test yields 164 p-values of 0.0000, 2 p-values of 0.001, and 36 p-values of 1 for homology in degree 1.
Using Equations (44), (46), (49), (52), and (55), the permutation test is conducted with a significance level ![]() when comparing all the ETF sectors in different sliding windows between July 1, 2019 and July 1, 2020. The permutation test returns 164 p-values of 0.0000, 4 p-values of 0.001, and 33 p-values of 1 for homology in degree 1. Using Equations (43), (44), (47), (50), (53), and (56), the permutation is performed with a significance level
when comparing all the ETF sectors in different sliding windows between July 1, 2019 and July 1, 2020. The permutation test returns 164 p-values of 0.0000, 4 p-values of 0.001, and 33 p-values of 1 for homology in degree 1. Using Equations (43), (44), (47), (50), (53), and (56), the permutation is performed with a significance level ![]() when comparing all the stock indices and all the ETF sectors in the same sliding windows between July 1, 2019 and July 1, 2020, which results in 199 p-values of 0.0000 and 2 p-values of 0.001 for homology in degree 1.
when comparing all the stock indices and all the ETF sectors in the same sliding windows between July 1, 2019 and July 1, 2020, which results in 199 p-values of 0.0000 and 2 p-values of 0.001 for homology in degree 1.
In order to understand these results, we will review the daily log returns, the norms of the persistence landscapes, and the topological summaries of all the stock indices and all the ETF sectors. When reviewing the daily log returns for DJIA, the S&P 500, NASDAQ, and Russell 2000 between January 5, 2010 and June 30, 2020 (see Figure 1), the stock indices range from −0.05 and 0.05 from 2010 to mid 2011, with some positive and negative spikes that appear leading up to 2012. From 2012 to March 2020, the daily log returns once again fall between −0.05 and 0.05. However, from March 2020 to June 2020, the market is highly volatile. Similar patterns are observed for the ETF sectors, but there is a notable spike around 2017 and from March 2020 to June 2020, the ETF sectors are more volatile than the stock indices as shown in Figure 2.
When we examine the daily log returns of all of the stock indices between January 5, 2010-June 1, 2020, the minimum daily log return occur on March 16, 2020, where Russell 2000 had a return of −0.154, the S&P 500 had a return at −0.1277, and the other stock indices were in between these values. When reviewing the daily log returns for all of the ETFs sectors for the same time period, the minimum daily log return also occurs on March 16, 2020, where Information Technology (XLK) had a return of −0.1487, Consumer Staples (XLP) had a return of −0.0702, and the other ETF sectors were in between these values. While March 16, 2020 is not recognized as an official financial crash or meltdown, this
![]()
Figure 1. The figures are the daily log returns for all the stock indices from January 5, 2010 to June 30, 2020. The reporting period of this figure contains 2641 trading days from January 4, 2010 to July 1, 2020.
![]()
Figure 2. The figures are the daily log returns for all the ETF sectors from January 5, 2010 to June 30, 2020. The reporting period of this figure contains 2641 trading days from January 4, 2010 to July 1, 2020.
date is noteworthy, and warrants closer examination for potential critical transitions prior to this date. Focusing on when the peaks occur, we include summary statistics for July 1, 2019 to July 1, 2020 for all the stock indices and all the ETF sectors in Table 1 and Table 2, respectively.
The norms of the persistence landscapes in homology degree 1 presented in Figure 3 and Figure 4 display all of the stock indices and all of the ETFs respectively for ![]() and
and ![]() for 1001 trading days prior to March 16, 2020. For the stock indices, the L1 distances are less than 0.01 between 2017 and 2018, less than 0.02 between 2018 and 2020, but the greatest L1 distance occurs in 2020 at approximately 0.08 as seen in Figure 3. The L1 distance for all of the ETFs, have more spikes than the L1 distances of the stock indices, especially between 2018 and 2020, but the greatest L1 distance occurs in March 2020 at approximately 0.14 as seen in Figure 3. While the L2 norms for all of the stock indices and all of the ETFs have similar distances, there is a noticeable spike in 2020. However, the distances in L2 are not as great as in L1, as shown in Figure 3 and Figure 4.
for 1001 trading days prior to March 16, 2020. For the stock indices, the L1 distances are less than 0.01 between 2017 and 2018, less than 0.02 between 2018 and 2020, but the greatest L1 distance occurs in 2020 at approximately 0.08 as seen in Figure 3. The L1 distance for all of the ETFs, have more spikes than the L1 distances of the stock indices, especially between 2018 and 2020, but the greatest L1 distance occurs in March 2020 at approximately 0.14 as seen in Figure 3. While the L2 norms for all of the stock indices and all of the ETFs have similar distances, there is a noticeable spike in 2020. However, the distances in L2 are not as great as in L1, as shown in Figure 3 and Figure 4.
Figure 3 and Figure 4 highlight the peak in more detail for the time period between January 3, 2020 to June 30, 2020. While critical points are discernible in the month of February 2020, the peaks occurred on February 21, 2020 and March 3, 2020 for all of the stock indices and for all of the ETF sectors respectively as seen in Figure 4. Recall that a point on the norms of the persistence landscapes coincides with a sliding window of 50 trading days in the daily log returns, which means the peaks are from February 21, 2020 to May 1, 2020 and March 3, 2020 to May 12, 2020 for all of the stock indices and for all of the ETF
![]()
Table 1. Summary statistics for stock indices.
![]()
Table 2. Summary statistics for ETF sectors.
![]()
Figure 3. The figures are the norms of the persistence landscapes of all the stock indices, where ![]() (solid line) and
(solid line) and ![]() (dashed line)) and each point in the figure represents a sliding window of 50 trading days. Panel A plots the time frame June 3, 2016 to March 16, 2020, where the last sliding window is from March 16, 2020 to May 26, 2020 and the reporting period of this figure contains 1001 trading days from June 2, 2016 to May 27, 2020. Panel B plots the time frame between January 3, 2020 to June 30, 2020, where the last sliding window is from April 21, 2020 to June 30, 2020 and the reporting period of this figure contains 76 trading days from January 2, 2020 to July 1, 2020.
(dashed line)) and each point in the figure represents a sliding window of 50 trading days. Panel A plots the time frame June 3, 2016 to March 16, 2020, where the last sliding window is from March 16, 2020 to May 26, 2020 and the reporting period of this figure contains 1001 trading days from June 2, 2016 to May 27, 2020. Panel B plots the time frame between January 3, 2020 to June 30, 2020, where the last sliding window is from April 21, 2020 to June 30, 2020 and the reporting period of this figure contains 76 trading days from January 2, 2020 to July 1, 2020.
![]()
Figure 4. The figures are the norms of the persistence landscapes of all the ETF sectors, where ![]() (solid line) and
(solid line) and ![]() (dashed line)) and each point in the figure represents a sliding window of 50 trading days. Panel A plots the time frame between June 3, 2016 to March 16, 2020, where the last sliding window is from March 16, 2020 to May 26, 2020 and the reporting period of this figure contains 1001 trading days from June 2, 2016 to May 27, 2020. Panel B plots the time frame between January 3, 2020 to June 30, 2020, where the last sliding window is from April 21, 2020 to June 30, 2020 and the reporting period of this figure contains 76 trading days from January 2, 2020 to July 1, 2020.
(dashed line)) and each point in the figure represents a sliding window of 50 trading days. Panel A plots the time frame between June 3, 2016 to March 16, 2020, where the last sliding window is from March 16, 2020 to May 26, 2020 and the reporting period of this figure contains 1001 trading days from June 2, 2016 to May 27, 2020. Panel B plots the time frame between January 3, 2020 to June 30, 2020, where the last sliding window is from April 21, 2020 to June 30, 2020 and the reporting period of this figure contains 76 trading days from January 2, 2020 to July 1, 2020.
sectors respectively. In particular, Figure 5 and Figure 6 emphasize this point, where the norms of the persistence landscapes and the daily log returns of either all of the stock indices or all of the ETF sectors are next to each other. The sliding windows of 50 trading days of the daily log returns synchronize to the first point in the norms of the persistence landscape and to the maximum values of the norms of the persistence landscapes as indicated by Figure 5 and Figure 6.
Aside from the norms of the persistence landscapes, we produce topological summaries to represent the persistence of topological features for all the stock indices and for all the ETF sectors between January 3, 2020 and June 30, 2020. Along with these topological summaries (the persistence diagram, the persistence landscape, the mean landscape), we plotted the daily log returns for the corresponding sliding window of 50 trading days shown in Figures 7-12.
Figure 7 and Figure 8 indicate that the daily log returns are centered around zero from January 3, 2020 to February 21, 2020 for all of the stock indices and from January 3, 2020 to February 26, 2020 for all of the ETF sectors. Not much persistence is evident in the persistence diagram and few spikes appear in persistence landscape and mean landscape. Figure 9 and Figure 10 illustrate more variability in the daily log returns from March 1, 2020 to April 16, 2020 for all of
![]()
Figure 5. The figures are the norms of the persistence landscapes and the daily log returns of all the stock indices from for July 2, 2019-June 30, 2020. Panel A is the norms of the persistence landscape, where ![]() (solid line) and
(solid line) and ![]() (dashed line)), each point in the figure represents a sliding window of 50 trading days, and two dashed lines depicting the first and maximum points in this figure. Panel B plots the daily log returns with two sliding windows of 50 trading days (depicted as rectangles) corresponding to the first and max points in the Panel A. The first sliding window is from July 2, 2019 to September 11, 2019, while the second sliding window is from February 21, 2020 to May 1, 2020. The reporting period of this figure contains 253 trading days from July 1, 2019 to July 1, 2020.
(dashed line)), each point in the figure represents a sliding window of 50 trading days, and two dashed lines depicting the first and maximum points in this figure. Panel B plots the daily log returns with two sliding windows of 50 trading days (depicted as rectangles) corresponding to the first and max points in the Panel A. The first sliding window is from July 2, 2019 to September 11, 2019, while the second sliding window is from February 21, 2020 to May 1, 2020. The reporting period of this figure contains 253 trading days from July 1, 2019 to July 1, 2020.
![]()
Figure 6. The figures are the norms of the persistence landscapes and the daily log returns of all the ETF sectors from for July 2, 2019-June 30, 2020. Panel A is the norms of the persistence landscape, where ![]() (solid line) and
(solid line) and ![]() (dashed line)), each point in the figure represents a sliding window of 50 trading days, and two dashed lines depicting the first and maximum points in this figure. Panel B plots the daily log returns with two sliding windows of 50 trading days (depicted as rectangles) corresponding to the first and max points in the Panel A. The first sliding window is from July 2, 2019 to September 11, 2019, while the second sliding window is from March 3, 2020 to May 12, 2020. The reporting period of this figure contains 253 trading days from July 1, 2019 to July 1, 2020.
(dashed line)), each point in the figure represents a sliding window of 50 trading days, and two dashed lines depicting the first and maximum points in this figure. Panel B plots the daily log returns with two sliding windows of 50 trading days (depicted as rectangles) corresponding to the first and max points in the Panel A. The first sliding window is from July 2, 2019 to September 11, 2019, while the second sliding window is from March 3, 2020 to May 12, 2020. The reporting period of this figure contains 253 trading days from July 1, 2019 to July 1, 2020.
![]()
Figure 7. These figures are the daily log returns and topological summaries of all the stocks indices from January 3, 2020-March 16, 2020. Panel A plots the daily log returns for all the stock indices with a sliding window of 50 trading days. Panel B plots the first dimension of the Vietoris-Rips persistence diagram, where the solid black dots represent connected components and the red triangles represent loops. Panel C plots the first dimension of corresponding persistence landscape. Panel D plots the corresponding the mean landscape.
![]()
Figure 8. These figures are the daily log returns and topological summaries of all the ETF sectors from January 3, 2020-March 16, 2020. Panel A plots the daily log returns for all the ETF sectors with a sliding window of 50 trading days. Panel B plots the first dimension of the Vietoris-Rips persistence diagram, where the solid black dots represent connected components and the red triangles represent loops. Panel C plots the first dimension of corresponding persistence landscape. Panel D plots the corresponding the mean landscape.
![]()
Figure 9. These figures are the daily log returns and topological summaries of all the stocks indices from February 21, 2020 to May 1, 2020. Panel A plots the daily log returns for all the stock indices with a sliding window of 50 trading days. Panel B plots the first dimension of the Vietoris-Rips persistence diagram, where the solid black dots represent connected components and the red triangles represent loops. Panel C plots the first dimension of corresponding persistence landscape. Panel D plots the corresponding the mean landscape.
![]()
Figure 10. These figures are the daily log returns and topological summaries of all the ETF sectors from March 3, 2020-May 12, 2020. Panel A plots the daily log returns for all the ETF sectors with a sliding window of 50 trading days. Panel B plots the first dimension of the Vietoris-Rips persistence diagram, where the solid black dots represent connected components and the red triangles represent loops. Panel C plots the first dimension of corresponding persistence landscape. Panel D plots the corresponding the mean landscape.
![]()
Figure 11. These figures are the daily log returns and topological summaries of all the stocks indices from March 16, 2020-May 26, 2020. Panel A plots the daily log returns for all the stock indices with a sliding window of 50 trading days. Panel B plots the first dimension of the Vietoris-Rips persistence diagram, where the solid black dots represent connected components and the red triangles represent loops. Panel C plots the first dimension of corresponding persistence landscape. Panel D plots the corresponding the mean landscape.
![]()
Figure 12. These figures are the daily log returns and topological summaries of all the ETF sectors from March 16, 2020-May 26, 2020. Panel A plots the daily log returns for all the ETF sectors with a sliding window of 50 trading days. Panel B plots the first dimension of the Vietoris-Rips persistence diagram, where the solid black dots represent connected components and the red triangles represent loops. Panel C plots the first dimension of corresponding persistence landscape. Panel D plots the corresponding the mean landscape.
the stock indices and from March 1, 2020 to May 1, 2020 for all of the ETF sectors. Significant persistence is apparent in the persistence diagram and more spikes appear in the persistence landscape and mean landscape.
5. Discussion
From reviewing the norms of the persistence landscape, the daily log returns, persistence diagrams, persistence landscapes, and mean landscapes for all of the selected dates, it is clear that the number of the loops in the relevant point clouds are more pronounced resulting in more persistence, which signifies that the stock market is transitioning from a stable state to a more unpredictable, volatile state. Moreover, the ETF sectors demonstrate more volatility than the stock indices. These stock indices’ findings coincide with the 2000 and 2008 market crashes findings found in [16]. Similar to Gidea and Katz [16], we observe L1 distances that confirm the critical thresholds prior to the 2020 peak and exhibit more than the L2 norm. In other words, the Lp-norms exhibit strong growth around the emergence of the primary peak.
While the highest peak occurred on February 21, 2020 for all of the stock indices and March 3, 2020 for all of the ETF sectors in the Lp norms, the Coronavirus (COVID-19) broke out in 2019 in Wuhan, China, but on January 21, 2020, the first US case was confirmed. The most important dates are March 13, 2020 when President Trump declares national emergency, March 15, 2020 when the Center of Disease Control and Prevention warns against large gatherings, and March 17, 2020 when COVID is present in all 50 states. The daily log returns for all of the stock indices and for all of the ETF sectors do not include negative values. Yet, there are other dates that could have lead to a market decline in March 16, 2020. For example, on January 30, 2020 when World Health Organization (WHO) declares a global health emergency or between February 5, 2020 and February 29, 2020 when the outbreak becomes an epidemic. While we acknowledge that it is quite difficult to predict a market crash, the norms of the persistence landscape performed really well as indicator in detecting critical transitions and the topological summaries authenticated volatility by of the number of loops increasing.
Our hypotheses tests aimed to find how topological features change within time, notably between July 1, 2019 and July 1, 2020. Our hypotheses tests for all of the stock indices found evidence of difference in topological features when comparing adjacent sliding windows of a sliding step of one day. In particular, we found for the chosen time frame that the daily log returns of all the stock indices significantly differ in the number of loops. Equivalently, our hypotheses tests for all of the ETF sectors found evidence of difference in topological features when comparing adjacent sliding windows of a sliding step of one day. Specifically, we found for the selected time frame that the daily log returns of all the ETF sectors significantly differ in the number of loops. Our last hypotheses tests between all of the stock indices and all of the ETF sectors within the same sliding window found inconclusive evidence of difference in topological features for the entire time frame.
6. Conclusions
In this paper, we investigated the topological features of four major indices and 10 ETF sectors for January 4, 2010-July 1, 2020. We used two sequences of point cloud data sets, one for all the stock indices and the other for all the ETFs with a sliding window![]() . Both sequences were used to perform TDA through algebraic topology and persistent homology. From there, topological summaries are generated to determine persistence and the norms for persistence landscapes are used to detect a critical transition by adapting methods found in [16]. Our goal is to determine how the statistical significance of topological features of stock indices and ETF sectors change for a specific time frame. We found that between July 1, 2019 and July 1, 2020, there is evidence of difference of topological features for all the stock indices and all the ETFs. As a result, critical transitions are determined using the norms of the persistence landscape and topological features of stock indices and ETF sectors change within time when comparing two sliding windows of a sliding step of one day.
. Both sequences were used to perform TDA through algebraic topology and persistent homology. From there, topological summaries are generated to determine persistence and the norms for persistence landscapes are used to detect a critical transition by adapting methods found in [16]. Our goal is to determine how the statistical significance of topological features of stock indices and ETF sectors change for a specific time frame. We found that between July 1, 2019 and July 1, 2020, there is evidence of difference of topological features for all the stock indices and all the ETFs. As a result, critical transitions are determined using the norms of the persistence landscape and topological features of stock indices and ETF sectors change within time when comparing two sliding windows of a sliding step of one day.
We conclude with possible future research goals. Further work could be done analyzing persistence landscapes for homology in degree two. It would be interesting to study topological features based on higher degree persistence. Furthermore, it would be fascinating to expand to commodities, futures, and other financial time series. Moreover, it would be more resourceful to expand topological data analysis to statistics beyond statistical inference and use for predictive modeling with machine learning.
This table presents summary statistics for all the stock indices. We estimated the mean (![]() ), standard deviation (
), standard deviation (![]() ), variance (
), variance (![]() ), skewness (
), skewness (![]() ), and kurtosis (
), and kurtosis (![]() ) of the daily log returns from July 2, 2019 to June 30, 2020. The reporting period of this table contains 253 trading days from July 1, 2019 to July 1, 2020.
) of the daily log returns from July 2, 2019 to June 30, 2020. The reporting period of this table contains 253 trading days from July 1, 2019 to July 1, 2020.
This table presents summary statistics for all the ETF sectors. We estimated the mean (![]() ), standard deviation (
), standard deviation (![]() ), variance (
), variance (![]() ), skewness (
), skewness (![]() ), and kurtosis (
), and kurtosis (![]() ) of the daily log returns from July 2, 2019 to June 30, 2020. The reporting period of this table contains 253 trading days from July 1, 2019 to July 1, 2020.
) of the daily log returns from July 2, 2019 to June 30, 2020. The reporting period of this table contains 253 trading days from July 1, 2019 to July 1, 2020.
Acknowledgements
The authors would like to thank Tracy Volz for helpful discussions in the editing process. The authors would also like to thank the Center of Computational Finance and Economic Systems (https://cofes.rice.edu).