1. Introduction
Linear regression model, or called linear model (LM), is one of the most widely used models in statistics. There are many kinds of linear models including simple linear models, general linear models, generalized linear models, mixed effects linear models and some other extended forms of linear models [1] [2] [3] [4] [5] . The growth curve model (GCM) is a special kind of general linear models which have applications in many areas such as the psychology data analysis [6] . The GCMs can be used to handle longitudinal data or missing data or even the hierarchical multilevel mixed case [2] [3] [5] [7] - [12] . There are some variations of GCMs such as the latent GCMs which are also very useful. The traditional treatment of the GCMs in the estimation of the parameters in the case of mixed effects for a single response factor is usually to stack all the dependent observations vertically into a very long column vector, usually denoted by y, and all the design matrices (both the fixed effect design matrix and the random effect design matrix), the random errors are accordingly concatenated to fit the size of y. This treatment makes the implementation of the related programming much slow due to the magnificent dimensions of the data (matrices and vectors). Things will get even worse if we encounter a huge dataset (big data) such as the data of genome, web related, image gallery, or social network etc.
In this paper, we first use the generalized inverse of matrices and the singular value decomposition to obtain the norm-minimized estimation of the parameters in the linear model. Then we introduce some basic knowledge about tensors before we employ tensors to express and extend the multivariate mixed effects linear models. The extended tensor form of the model can be also regarded as a generalization of the GCM.
Let us first begin with some basic linear regression models. We let y be a response variable and
be independent random variables for explaining y. The most general regression model between y and
is in form
(1.1)
where
is the error term, and f is an unknown regression function. In linear regression model, f is assumed to be a linear function, i.e.,
(1.2)
where all
are unknown parameters. Denote
which is called a random vector. Let
, an
-dimensional random vector, which is called an observable vector. Given N observations of P, say
,
. Here
stands for the ith observation of the response variable y, and
are the corresponding explanatory observations. The sample model of Equation (1.2) turns out to be
(1.3)
or equivalently
(1.4)
where
(here and throughout the paper
stands for the transpose of a matrix/vector) is the sample vector of the response variable y,
is the data matrix or the design matrix each of whose rows corresponding to an observation of x,
is the regression coefficient vector, which is to be estimated, and
is the random error vector. A general linear regression model, abbreviated GLM, is a LM (1.4) with the error terms
satisfying:
1) Zero-mean:
, i.e., the expected value of the error term is zero for all the observations.
2) Homoskedasticity:
, i.e., all the error term are distributed with the same variance.
3) Uncorrelation:
for all distinct
, i.e., distinct error terms are uncorrelated.
Equations (1)-(3) is called Gauss-Markov assumption [13] . The model (1.4) under the Gauss-Markov assumption is called the Gauss-Markov model. Note that the variance reflects the uncertainty of the model, the zero-mean, homoskedasticity and the uncorrelation of the sample errors form the Gauss-Markov assumption. An alternative form of the Gauss-Markov model is
(1.5)
where
is the
identity matrix and
. In order to investigate the general linear model and extend the properties, we recall some known results concerning the linear combinations of some random variables. Suppose
is a constant vector with the same length as that of y, the random vector under the investigation.
Let
. The g-inverse of A, denoted
, is a generalized inverse defined as an
matrix satisfying [4]
. An equivalent definition for g-inverse is that
is always a solution to equation
whenever
, the column space of A. A well known result is that all the solutions to
(when compatible) are in form
. (1.6)
It is easy to verify that
is unique when A is invertible. The g-inverse of a matrix (usually not unique) can be calculated by using singular value decomposition (SVD).
Lemma 1.1. Let
with a SVD decomposition
such that
and
are orthogonal matrices, and
is in form
where
, and
. Then
(1.7)
where * denotes any matrix of suitable size and
.
The Gauss-Markov Theorem (e.g. Page 51 of [13] ) is stated as:
Lemma 1.2. Suppose that model (1.4) satisfies the Gauss-Markov assumption and
be a constant vector. Then
is estimable, and
is the best (minimum variance) linear unbiased estimator (BLUE) of
, with
.
Based on Lemma 1.2, we get
Proposition 1.3. If
in Equation (1.4) and
satisfies condition in Lemma 1.2. Then the estimator of
with minimal 2-norm is in form
(1.8)
where
with
,
.
Proposition 1.3 tells us that by taking D as a block upper triangle form in the decomposition
.
We can reach a norm-minimised estimator of
. Now denote
. By Gauss-Markov Theorem, we have
which implies that
.
The generalized linear model (GLM) is a generalization of LM [1] . In a GLM model some basic assumptions in linear regression model are relaxed. Also the fitting values of the response variables are no longer directly expressed as a linear combination of parameters, but rather a function which is usually called a link function. A GLM consists of the independent random components
in exponential distribution, the predictive value
, the system components, and the link function f, strictly monotone differentiable function in GLM
. The parameters in a GLM include regression parameters
and the discrete parameters in the covariance matrix, both can be estimated with maximum likelihood method. The estimation of the regression parameter for model (1.4) can be expressed as
where
with
being a known priori weight,
the dispersion parameter,
a variance function, g a link function, and
the work dependent variable with
. The moment estimation of discrete parameters is
. (1.9)
In order to extend the GLMS to more general case, we need some knowledge on tensors. In the next section, we will introduce some basic terminology and operations implemented on tensors, especially on low order tensors.
2. The 3-Order Tensors and Their Applications in GLMs
A tensor is an extension of a matrix in the case of high order, which is an important tool to study high-dimensional arrays. The origin of tensor can be traced back to early nineteenth century when Cayley studied linear transformation theory and invariant representation. Gauss and Riemann et al. promoted the development of tensor in mathematics. In 1915 Albert Einstein used tensor to describe his general relativity, leading tensor calculus more widely accepted. In the early twentieth century, Ricci and Levi-Civita further developed tensor analysis in absolute differential methods and explored their applications [14] .
For our convenience we denote
and use
to denote the index set
.
Let
be any positive integer (usually larger than 1). Sometimes we abuse
as a set
. Denote
. If
stands for an index set, then I is a tensor product of
. An m-order tensor
of size I is an m-array whose entries are denoted by
with
. Note that a vector is a 1-order tensor and an
matrix is a 2-order or second order tensor. An
tensor is a tensor with
. We denote by
the set of all mth order n-dimensional real tensors . An
tensor
is called symmetric if
is constant under any permutation on its index.
An mth order n-dimensional real tensors
is always associated with an m-order homogeneous polynomial
which is defined by
. (2.10)
is called positive definite or pd (positive semidefinite or psd) if
. (2.11)
A nonzero psd tensor must be of an even order. Let
be of size
. Given an r-order tensor
and a matrix
where
. The product of
with
along k-mode is defined as the r-order tensor
defined as
. (2.12)
Note that
is compressed into an
-order tensor when
is a column vector
. There are two kinds of tensor decomposition, i.e., the rank-1 decomposition, also called the CP decomposition, and the Tucker decomposition, or HOSVD. The former is the generalization of matrix rank-1 decomposition and the latter is the matrix singular value decomposition in the high order case. A zero tensor is a tensor with all entries being zero. A diagonal tensor is a tensor whose off-diagonal elements are all zero, i.e.,
if
are not identical. Thus an
tensor has n diagonal elements. By this way, we can define similarly (and analogous to matrix case) the identity tensor and a scalar tensor.
For any
, an i-slice of an m-order tensor
along mode k for any given
is an
tensor
with
A slice of 3-order tensor
along mode-3 is an
matrix
with
, and a slice of a 4-order tensor is a 3-order tensor.
Let
be two tensors of 3-order. The slice-wise product of
, denoted by , is defined as
, is defined as  where
for all
. This multiplication can be used to build a regression model
where
for all
. This multiplication can be used to build a regression model
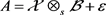 (2.13)
(2.13)
where
is the matrix consisting of n sample points of size m in class k and
is the design matrix corresponding to the kth sample (there are
observations in each class in this situation).
Let k be a positive integer. The k-moment of a random variable x is defined as the expectation of x, i.e.,
. The traditional extension of moments to a multivariate case is done by an iterative vectorization imposed on k. This technique is employed not only in the definition of moments but also in other definitions such as that of a characteristic function. By introducing the tensor form into these definitions, we find that the expressions will be much easier to handle than the classical ones. In the next section, we will introduce the tensor form of all these definitions.
Let
be a random vector. Denote by
the (symmetric) rank-one m-order tensor with
.
is called a rank-1 tensor generated by
which is also symmetric. It is shown by Comon et al. [15] that a real tensor
(with size
) can always be decomposed into form
 (2.14)
(2.14)
where
for all
. The smallest positive integer r is called the rank of
, denoted by
. We note that Equation (2.14) can also be used to define the tensor product of two matrices, which will be used in our next work on the covariance of random matrices. Note that the tensor product of two rank-one matrices is
.
Now consider two matrices
. Then write
in a rank-1 decomposition, i.e.,
.
Tucker decomposition decomposes the original tensor into a product of the core tensor and a number of unitary matrices in different directions [15] so
can be decomposed into
(2.15)
where
is the core tensor, and
are unitary matrices.
Example 2.1. Let  be an
tensor which is defined by
be an
tensor which is defined by
.
Then the unfolded matrices along 1-mode, 2-mode and 3-mode are respectively
.
3. Application of 3-Order Tensors in GLMs
The growth curve model (GCM) is one of the GLMs introduced by Wishart in 1938 [16] to study the growth situation of animals and plant between different groups. It is a kind of generalized multivariate variance analysis model, and has been widely used in modern medicine, agriculture and biology etc. GCM originally referred to a wide array of statistical models for repeated measures data [2] [14] . The contemporary use of GCM allows the estimation of inter-object variability such as time trends, time paths, growth curves or latent trajectories, in intra-object patterns of change over time [17] . The trajectories are the primary focus of analysis in most cases, whereas in others, they may represent just one part of a much broader longitudinal model. The most basic GCMs contain fixed and random effects that best capture the collection of individual trajectories over time. In a GCM, the fixed effects represent the mean of the trajectory pooling of all individuals, and the random effects represent the variance of the individual trajectories around these group means. For example, the fixed effects in a linear trajectory are estimates of the mean intercept and mean slope that define the underlying trajectory pooling of the entire sample, and the random effects are estimates of the between-person variability in the individual intercepts and slopes. Smaller random effects imply the more similar parameters that define the trajectory across the sample of individuals; at the extreme situation where the random effects equal 0, all individuals are governed by precisely the same trajectory parameters (i.e., there is a single trajectory shared by all individuals). In contrast, larger random effects imply greater individual differences in the magnitude of the trajectory parameters around the mean values.
The analysis of a GCM focuses on the functional relationship among ordered responses. Conventional GCM methods apply to growth data and to other analogs such as dose-response data (indexed by dose), location-response data (indexed by distance), or response-surface data (indexed by two or more variables such as latitude and longitude). The GCM methods mainly focus on longitudinal observations on a one-dimensional characteristic even though they may also be used in multidimensional cases [2] .
A general GCM can be indicated by
(3.16)
where
is the random response matrix whose rows are mutually independent and columns correspond to the response variables ordered according to
;
is the fixed design matrix with
; The matrix
is a fixed parameter matrix whose entries are the regression coefficients;
is a within-subject design matrix each of whose entries is a fixed function of d, and
is a random error with matrix normal distribution
where
is an unknown symmetric positive definite matrix. Suppose the samplings corresponding to each object are recorded at p different times (moments)
. Consider an example of a pattern of the children’s weight. The plotting of the weights against the ages indicates a temporal pattern of growth. A univariate linear model for weight given age could be fitted with a design matrix T expressing the central tendency of the children’s weights as a linear or curvilinear function of age. Here T is an example of a within-subject design matrix. If
, a separate curve could be fitted for each subject to obtain a separate matrix of regression parameter estimators for each independent sampling units,
for
, and a simple average of the N fitted curves is a proper (if not efficient) estimator of the population growth curve, that is,
.
The efficient estimator has the form
. (3.17)
If the subjects are grouped in a balanced way, i.e., The N observations are clustered into m groups, each containing the same number, say n, of observations. For simplicity, we may assume that first n each then
, the all-one vector, is the appropriate choice for computing
. The choice of T defines the functional form of the population growth curve by describing a function relationship between weight and age.
Example 3.1. We recorded the heights of n boys and n girls whose ages are 2, 3, 4 and 6 years. From the observations we make an assumption that the average height increases linearly with age. Since the observed data is partitioned into two groups (one is for the heights of n boys and another is for the height of n girls), each consisting of n objects, and
with age vector
. Thus the model for the height vs. age shall be
where
where
is an all-ones vector of dimension k.
Here
are respectively the intercept and the slope for girls and
are respectively the intercept and the slope for boys. We find that it is not so easy for us to investigate the relationship between the gender, height, weight, and age. In the following we employ tensor expression to deal with this issue.
Using the notation in tensor theory, we rewrite model (3.16) in form
or equivalently
(3.18)
where B is regarded as a second order tensor and
as two matrices. Actually, according to Equation (2.12), we have
.
Similarly we can define
. Note that
.
Now we extend model (3.16) in a more general form as
(3.19)
where
is a 3-order tensor, which is usually an unknown constant parameter tensor or the kernel tensor, and
for
. Here the tensor-matrix multiplication is defined by Equation (2.12) according to the dimensional coherence along each mode.
The potential applications of Equation (3.21) are obvious. A HOSVD (high order singular value decomposition) of a 3-order tensor can be regarded as a good example for this model.
Example 3.2. A sequence of 1000 images extracted from a repository of face images of ten individuals, each with 100 face images. Suppose each face image is of size
. Then these images can be restored in an
tensor
. Let
be decomposed as
(3.20)
where
The decomposition Equation (3.20) yields a set of compressed images, each with size
. If each individual can be characterized by five images (this is called a balanced compression), then the kernel tensor
consists of 50 compressed images where each
is a projection matrix along mode-i (i = 1, 2, 3). Specifically,
and
together play a role of compression of each image into an
image, while
finds the representative elements (here is the 50 images) among a large set of images (the set of 1000 face images).
Analog to GCM, we let
be the measured value of Index
in Class
at time
. A tensor
can be used to express m objects, say
, each having p indexes
measured respectively at times
. For each index
, we have GCM form:
(3.21)
where
. Suppose each row of
stands for a class of individuals, e.g., partitioned by ages. To make things more clear, we consider a concrete example.
Example 3.3. There are 30 persons under health test, each measured, at time
, 10 indexes such as the lower/higher blood pressures, heartbeat rate, urea, cholesterol, bilirubin, etc. We label these indexes respectively by
. Suppose that the 30 people are partitioned into three groups (denoted by
) with respect to their ages, consisting of 5, 10, 15 individuals respectively. Denote
and
.
Denote by
the measurement of Index
in group
at time
. Set
,
for
. Then we have
(3.22)
where
and
is an unknown constant parameter tensor to be estimated, where
is the parameter matrix corresponding to the k th index model. The model (3.22) can be further promoted to manipulate a balanced linear mixed model when multiple responses are measured for balanced clustered (i.e., there are same number of subjects in each cluster) subjects.
4. Tensor Normal Distributions
In the multivariate analysis, the correlations between the coordinates of a random vector
are represented by the covariance matrix
, which is symmetric and positive semidefinite. When the variables are arrayed as a matrix, say
, which is called a random matrix, the correlation between any pair of entries, say
and
of matrix
, is represented as an entry of a matrix
which is defined as the covariance matrix of the vector. A matrix normal distribution is defined.
, and
are two positive definite matrices. A random matrix
is said to obey a matrix normal distribution, denoted by
, if it satisfies the following the conditions:
1)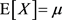 , i.e.,
, i.e., 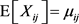 for each
.
for each
.
2) Each row
of
obeys normal distribution
for
.
3) Each column
obeys normal distribution
.
It is easy to show that a matrix normal distribution
is equivalent to
(see e.g. [8] ).
We now define the tensor normal distribution. Let
be an m-order tensor of size
, each of whose entries is a random variable. Let
be an m-order tensor of the same size as that of
, and
be an
positive definite matrix. For convenience, we denote by
the
-tuple
with
. We denote by
and
, both in
respectively the corresponding fibre (vector) of
and
, indexed by
, i.e.,
is called a fibre of
(
resp.) along mode-n indexed by
.
is said to obey a tensor normal distribution with parameter matrices
or denoted by
if for any
, we have
.
is said to follow a standard tensor normal distribution if all the
’s are identity matrices. A model (2.13) with a tensor normal distribution is called a general tensor normal (GTN) model.
To show the application of tensor normal distribution, we consider the 3-order tensor. For our convenience, we use
-value to denote the value related to the ith subject at jth measurement for any
. For example, the kth response observation
at
represents the kth response value measured on the ith subject at time j. Now we let
be respectively the number of observed objects, number of measuring times for each subject, and the number of responses for each observation. Denote by
the response tensor with
being the kth response at
, and by
the covariate tensor with
being the covariate vector at
for fixed effects, and by
the covariate vector at
for random effects. Further, for each
, we denote by
the coefficient vector related to the fixed effects corresponding to the kth response
at
for each pair
, and similarly by
the coefficient vector related to the random effects. Now let
and
. Then
. We call
respectively the design matrix for fixed effects and the design matrix for random effects. Then we have
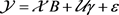 (4.23)
(4.23)
with
,
,
,
,
,
where
is the error term. Here the tensor-matrix multiplications
and 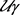 are defined by
are defined by
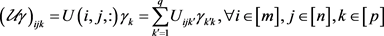 .
.
Denote
, and
where each matrix
is called a slice on mode s, and each vector
is called a fibre along mode-s. We also use
to denote the set consisting of all fibres of
along mode-s, and use notation
to express that each element of
obeys distribution P where P is a distribution function. For example,
means that each 1-mode fibre
(there are
1-mode fibres) obeys a standard normal distribution, i.e.,
.
Now for convenience we let
. We assume that
1)
obeys matrix normal distribution
.
2) The random vectors in 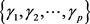 are independent with
are independent with 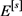 for each
for each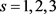 .
.
3) For any 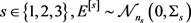 with
with 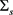 being positive definite of size
being positive definite of size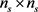 .
.
The model (4.23) with conditions (I, II, III) is called a 3-order general mixed tensor (GMT) model. We will generalise this model to a more general case. In the following we first define the standard normal 3-order tensor distribution:
Definition 4.1. Let 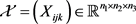 be a random tensor, i.e., each entry of
be a random tensor, i.e., each entry of  is a random variable. Let
is a random variable. Let ![]() be a constant tensor and
be a constant tensor and ![]() be a positive definite matrix for each
be a positive definite matrix for each![]() . Then
. Then ![]() is said to obey 3-order tensor standard normal (TSN) distribution if
is said to obey 3-order tensor standard normal (TSN) distribution if ![]() for all
for all![]() .
.
A 3-order random tensor satisfying TSN distribution has the following property:
Theorem 4.2. Let ![]() be an 3-order random tensor which obeys the tensor standard normal (TSN) distribution. Then each slice of
be an 3-order random tensor which obeys the tensor standard normal (TSN) distribution. Then each slice of ![]() shall obey a standard matrix normal distribution. Specifically, we have
shall obey a standard matrix normal distribution. Specifically, we have
![]() (4.24)
(4.24)
Proof. □
Note that condition (III) is a generalization to the matrix normal distribution, and we denote it by![]() ,
,
![]() .
.
Note that ![]() is a diagonal matrix since both
is a diagonal matrix since both ![]() and
and ![]() are diagonal. Write
are diagonal. Write ![]() where
where ![]() is the expansion of
is the expansion of ![]() along the third mode, specifically,
along the third mode, specifically,
![]()
here ![]() is the tensor consisting of n identity matrices of size
is the tensor consisting of n identity matrices of size ![]() stacking along the third mode, thus
stacking along the third mode, thus ![]() and
and![]() . Then we have
. Then we have
![]() . (4.25)
. (4.25)
Now we unfold ![]() along mode-3 to get matrix
along mode-3 to get matrix ![]() and
and ![]() respectively. Then Equation (4.25) is equivalent to
respectively. Then Equation (4.25) is equivalent to
![]() (4.26)
(4.26)
where ![]() and
and ![]() are generated similarly as
are generated similarly as![]() .
.
The multivariate linear mixed model (4.23) or (4.25) can be transformed into a general linear model through the vectorization of matrices. Recall that the vectorization of a matrix ![]() is a vector of dimension
is a vector of dimension![]() , denoted by
, denoted by![]() , formed by vertically stacking the columns of A in order, that is,
, formed by vertically stacking the columns of A in order, that is,
![]()
where ![]() are the column vectors of A. The vectorization is closely related to Kronecker product of matrices. The following lemma presents some basic properties of the vectorization and Kronecker product. We will use the following lemma (Proposition 1.3.14 on Page 89 of [4] ) to prove our main result:
are the column vectors of A. The vectorization is closely related to Kronecker product of matrices. The following lemma presents some basic properties of the vectorization and Kronecker product. We will use the following lemma (Proposition 1.3.14 on Page 89 of [4] ) to prove our main result:
Lemma 4.3. Let ![]() be matrices of appropriate sizes such that all the operations defined in the following are valid. Then
be matrices of appropriate sizes such that all the operations defined in the following are valid. Then
1)![]() .
.
2)![]() .
.
3)![]() .
.
The following property of the multiplication of a tensor with a matrix is shown by Kolda [18] and will be used to prove our main result.
Lemma 4.4. Let ![]() be a real tensor of size
be a real tensor of size![]() , and
, and ![]() where
where![]() . Then
. Then ![]() if and only if
if and only if
![]() (4.27)
(4.27)
where ![]() are respectively the flattened matrices of
are respectively the flattened matrices of ![]() and
and ![]() along mode-n.
along mode-n.
Proof. Let![]() . Then for any
. Then for any![]() , we have
, we have
![]() . (4.28)
. (4.28)
From which the result Equation (4.27) is immediate. □
Note that our Formula (4.27) is different from that in Section 2.5 in [18] since the definition of tensor-matrix multiplication is different.
We have the following result for the estimation of the parameter matrix![]() :
:
Theorem 4.5. Suppose ![]() in Equation (4.23). Then the optimal estimation of the parameter matrix
in Equation (4.23). Then the optimal estimation of the parameter matrix ![]() in Equation (4.23) is
in Equation (4.23) is
![]() . (4.29)
. (4.29)
Proof. We first write Equation (4.25) in a matrix-vector form by vectorization by using the first item in Lemma 4.3,
![]() (4.30)
(4.30)
where ![]() is the sum of two random terms. By the property of the vectorizations (see e.g. [4] ), we know that
is the sum of two random terms. By the property of the vectorizations (see e.g. [4] ), we know that![]() . By the ordinary least square solution method we get
. By the ordinary least square solution method we get
![]()
By using (1) of Lemma 4.3 again (this time in the opposite direction), we get result (4.29). □
For any![]() , we denote
, we denote ![]() when
when![]() , and
, and ![]() when
when ![]() (
(![]() stands for an g-inverse of a matrix
stands for an g-inverse of a matrix![]() ). Then
). Then ![]() can be regarded as the projection from
can be regarded as the projection from ![]() into
into ![]() since
since![]() . Furthermore, we have
. Furthermore, we have![]() . We now end the paper by presenting the following result as a pre diction model which follows directly from Theorem 4.5.
. We now end the paper by presenting the following result as a pre diction model which follows directly from Theorem 4.5.
Theorem 4.6. Suppose ![]() in Equation (4.23). Then the mean of the response tensor
in Equation (4.23). Then the mean of the response tensor ![]() in Equation (4.23) is
in Equation (4.23) is
![]() (4.31)
(4.31)
where![]() .
.
Proof. By Theorem 4.5 and Equation (4.26), we have
![]()
It follows that
![]() . (4.32)
. (4.32)
By employing Lemma 4.4, we get result (4.31). □
Acknowledgements
This research was partially supported by the Hong Kong Research Grant Council (No. PolyU 15301716) and the graduate innovation funding of USTS. We shall thank the anonymous referees for their patient and elaborate reading and their suggestions which improved the writing of the paper.