Reducing Participation Bias in Case-Control Studies: Type 1 Diabetes in Children and Stroke in Adults ()
1. Introduction
Participation bias, a subset of selection bias, affects many study types and is often ignored by authors [1] . It is well documented that case-control studies can be affected by participation bias in the control group [2] -[4] , which can result in an overor underestimation of odds ratios [5] .
In recent years, routine data has become more widely available; partially due to advances in technology, increased routine data collection and emphasis on data sharing, along with the recent move towards and focus on Big Data. Linked data sources such as hospital episode statistics (HES) [6] , the clinical practice research database (CPRD) [7] and Research One [8] are allowing information to be shared more easily and further research to be carried out. Often these databases hold much more information, on a greater number of people, than could easily be collected through a study. Some census databases also contain information relating to every member in a population [9] [10] .
We propose the use of population data in place of control data, along with the case data from a case-control study. We demonstrate this method by reanalysing a Yorkshire childhood diabetes case-control study and an Indian study of stroke. We explain how potential participation bias can be identified and show how to improve precision of the estimated odds ratios. We therefore present a method to reduce the amount of bias from the control group; which can be used in place of controls in future case-control studies to save time and resources, or as an approach to evaluate the results from previous studies.
2. Methods
2.1. The Data
The diabetes data set used was taken from a case-control study [11] , which had recorded cases of children under 16 years diagnosed with insulin-dependent diabetes mellitus (IDDM), or Type 1 diabetes, while resident in the area of the former Yorkshire Regional Health Authority, since 1978, with data collected 1993-1994. The stroke data set used 100 computed tomography (CT) proved cases of stroke, with age and sex matched controls, from hospital attendees in India [12] . These data sets have been used to demonstrate the effect of participation bias on the analysis of risk factors, and the potential for population data to provide improved estimates. The published results have been compared with results generated when population data is used in place of control data.
2.2. The Population Data
There are three values required from the population for each odds ratio replicated, which must be correct for the time and location of the original study:
1) The exposure in the population;
2) The size of the population;
3) The number of cases in the population.
For these examples, various sources were used, but all were publicly accessible to demonstrate the ease of the method (Table 1). However, more recent or detailed data could be obtained from previous studies or databases if available, which would be likely to improve the accuracy of the results.
2.3. The Proposed Method
The steps required to use population data in place of control data are as follows:
1) Use the population and case numbers to calculate the number of controls.
2) Use the exposed population and exposed case data to calculate the number of exposed controls.
3) Use the previous steps to calculate the remaining number of unexposed population, cases and controls.
4) Use these values to calculate odds ratios from a contingency table or using logistic regression.
These steps are shown below for the caesarean exposure in the diabetes data set as an example. This was repeated for exposures in both the diabetes and stroke data sets, using the methods used in the original study. The odds ratios published were also replicated, with all calculations using R [22] .
Example, Caesarean:
population = cases + controls 774,840 = 248 + controls 774,840 = 248 + 774,592

Table 1. Population data used for the proposed method.
Table 2. Odds ratios and 95% confidence intervals comparing the published odds ratios with those generated using population data.
exposed population = exposed cases + exposed controls
(0.09 × 774,840) =  + exposed controls 69,736 = 43 + 69,693 not exposed population = not exposed cases + not exposed controls
+ exposed controls 69,736 = 43 + 69,693 not exposed population = not exposed cases + not exposed controls
(774,840 – 69,736) = (248 − 43) + (774,592 − 69,693)
705,104 = 205 + 704,899 This can be written generally; let P be the number of people in the population of interest, D be the disease of interest, E be the exposure of interest, a be the number of exposed cases and c be the number of unexposed cases. Values from the population can then be substituted into the equations below. The necessary steps are in bold.




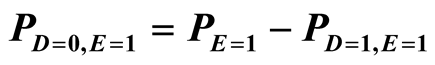

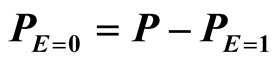


3. Results
Table 2 shows the odds ratios and confidence intervals calculated using the population values, along with the
published odds ratios from the corresponding original study. It can be seen from Table 2 that the population odds ratios support the findings from the original analysis of significantly raised odds ratios for birth by caesarean and amniocentesis in the diabetes data set. The results for the stroke data set all have increased odds ratios for the population data when compared with the initial study, however the confidence intervals of the hypertension population odds ratio and the published odds ratio do overlap. This could suggest support from the population data for the hypertension odds ratio but possible disagreement between the published and population odds ratios for the exposures diabetes and smoking; with greater disagreement when considering diabetes. One possible cause for this disagreement could be participation bias. Note the controls in the Indian stroke study were hospital attendees; this could have resulted in Berkson’s bias [23] , since those who smoke, have hypertension, or have diabetes, may have associated conditions requiring hospital admission. This higher proportion of smokers, hypertensive controls and diabetics in the control group than in the population would have resulted in lower odds ratios in the published results. Hence participation bias is likely to have occurred.
Table 2 also shows the population odds ratios have much narrower confidence intervals than the published odds ratios. This corresponds to the increase in the number of subjects considered in the population odds ratios compared with the number in the original case-control study.
4. Discussion
Participation bias can cause the results from studies to be inaccurate [5] , especially in case-control studies where certain potential controls are more likely to participate than others. Researchers who may wish to use our method in place of, or in conjunction with, case-control studies, may have access to medical records or similar information which is likely to give more accurate odds ratios which are less affected by participation bias. In addition, the proposed method allows the identification of participation bias, as shown in the Indian stroke example, where Berkson’s bias has been suggested. The method can also be extended to allow for matching in the original study, by stratifying or adding the confounder to the regression model, using more detailed population data, such as young and old stroke cases or male and female smokers.
Approximations may need to be made when data are available but not in the required format. For example, it was assumed that the number of 15 year old in Yorkshire was approximately a fifth of the 15 - 19 year old Yorkshire population [15] . Matched case-control studies may also be more time-consuming as more detailed population data are required, along with the confounding variable data for the cases. The case data will be available for new studies, but may not always be available for past studies. This was true for the Indian stroke study, where an unmatched analysis was required as an approximation, since the details linking the confounding variables to the cases were not published. As data availability has increased over the last few decades and census questions have become more detailed, similar population data for studies more recent than the diabetes study may be more readily available. It can, however, still be used as a tool to revisit older studies to confirm or question their findings. It is also likely that those working in these research areas would have access to databases or information from previous studies, allowing more accurate population data to be used. There will be circumstances where the required relevant population data will not be available and then a case-control study would be preferable.
This proposed method of using population data is very simple and quick to apply; far cheaper and easier than recruiting controls for a case-control study. This approach allows the study time and resources to be focused on the collection of case data, giving a larger sample of cases than previously possible. The method allows an efficient way to conduct a new large study, with less effort in the control group than previously required. The population data, if carefully selected, is likely to have reduced participation bias when compared with the corresponding control data, yielding more accurate results and increasing the chances of determining the true cause of a disease. Ideal sources of population data are those which capture information from the entire population of interest and which are considered to be reliable. Examples include population wide health databases or appropriate census data. However, if a population value is used and later thought to be inaccurate, the calculations can easily be rerun to generate improved estimates. The larger sample sizes resulting from this approach also generate narrower confidence intervals, allowing easier categorisation of the variables to significant protective factor, significant risk factor or insignificant risk or protective factor. All steps in the method were conducted using case information only in the paper, without the need for the original data set. Therefore, this analysis could be repeated for all variables published, to see whether any potential risk factors have been miscategorised. This method can support the findings from the study, or identify any potential bias in the results.
Identifying the true causes or risk factors of a disease is an important step towards developing a cure or preventing others from becoming cases. Case-control studies are a useful study design to help find the causes of a rare disease, but they can be affected by participation bias. A simple amendment to the method, such as the one proposed here, could help to yield more accurate results and move closer towards discovering the cause of the disease.
Funding
Claire Keeble is a Ph.D. student funded by a MRC Capacity Building Studentship. Graham Law, Stuart Barber, Paul Baxter and Roger Parslow are funded by HEFCE.