Variable Selection in Finite Mixture of Time-Varying Regression Models ()
1. Introduction
The problem of variable selection in FMR models has been widely discussed [1] [2] [3]. When a response variable
with a finite mixture distribution depends on covariates
, we obtain a finite mixture of regression (FMR) model. The FMR model with K components can be given as follows [3]:
(1)
where
is an independent and identically distributed (IID) response and
is a
vector of covariates.
denotes the mixing proportions satisfying
,
.
is the kth mixture component density.
for
, for a given link function
, and a dispersion parameter
.
However, in some situations, observations were not independent. As pointed out in [2], in the analysis of the PD data, observations from each patient over time were assumed to be independent to facilitate the analysis and comparison with results from the literature. However, the validity of such assumption may be questionable. Whereupon, we consider a situation that observations were time series.
The generalised autoregressive conditional heteroskedasticity (GARCH) model is widely used in time series analysis. A mixture generalized autoregressive conditional heteroscedastic (MGARCH) model was pointed out in [4]. [5] generalized the MixN-GARCH model by relaxing the assumption of constant mixing weights. Whereupon, we combine the GARCH model and the FMR model to discuss the above problem.
There has been extensive studies about variable selection methods. A recent review of the literature regarding the variable selection problem in FMR models can be found in [6]. There are a general family of penalty functions, including the least absolute shrinkage and selection operator (LASSO), the minimax concave penalty (MCP) and the smoothly clipped absolute deviation (SCAD) in [2] and [7].
The method of the maximum penalized log-likelihood (MPL) estimation is usually the EM algorithm. [8] proposed a new algorithm (block-wise MM) for the MPL estimation of the L-MLR model. It was proved to have some desirable features such as coordinate-wise updates of parameters, monotonicity of the penalized likelihood sequence, and global convergence of the estimates to a stationary point of the penalized loglikelihood function, which are missing in the commonly used approximate-EM algorithm presented in [3].
The rest of the paper is organized as follows: in Section 2, the definition of finite mixture of time-varying regression Models and in Section 3, feature selection methods are discussed. In Section 4, the block-wise MM algorithm for its estimation and the BIC for choosing tuning parameters and components are presented, and the example of the Gaussian distribution is derived. Simulation studies on the performance of the new variable selection methods are then provided in Section 5. In Section 6, analysis of a real data set illustrates the use of the procedure. Finally, conclusions are given in Section 7.
2. Finite Mixture of Time-Varying Regression Models
2.1. Finite Mixture of Autoregression Models
Let
be a response variable which is a time series.
is a p-dimensional vector of covariates, and each of them is a time series. For an FM-AR(d) model with K components, the conditional density function for observation t is given as follows:
(2)
where
(3)
for
, for a given link function
, and a dispersion parameter
.
The master vector of all parameters is given by
, with
(4)
where
,
. Let
, and
, (3) can be rewrote as
.
2.2. Finite Mixture of GARCH Models
Let
be a response variable which is a time series. Let
is a p-dimensional vector of covariates, and each of them is a time series. For some distributions with unequal dispersion parameter
, we propose the FM-GARCH models. For an FM-GARCH (d,M,S) model with K components, the conditional density function for observation t is given as follows:
(5)
where
for
, for a given link function
, and a conditional heteroscedastic (a dispersion parameter)
(6)
where
,
,
, and
,
is an independent and identically distributed series with mean zero and variance unity.
The master vector of all parameters is given by
, with
,
,
, and
,
.
3. Feature Selection Method
Let
be a sample of observations from the FM-AR or FM-GARCH model. The quasi-likelihood function of the parameter
is given by [9]
(7)
The log quasi-likelihood function of the parameter
is given by
(8)
When the effect of a component of
is not significant, the corresponding ordinary maximum quasi-likelihood estimate is often close to 0, but not equal to 0. Thus this covariate is not excluded from the model. Inspired by an idea of [2], we estimate
by maximizing the penalized log quasi-likelihood function (MPLQ) for the model
(9)
with the mixture penalty (or regularization) function:
(10)
for some ridge tuning parameter
, and
is a nonnegative penalty function. In the penalty function
, the amount of
penalty imposed on the componentwise regression coefficients
’s are chosen proportional to
. The functions
are designed to identify the no significant coefficients
’s in the mixture components
. General regularity conditions about the
is given in [2] [3].
We estimate the new method using the following well-known penalty (or regularization) functions:
• LASSO penalty:
.
• MCP penalty:
.
• SCAD penalty:
.
Here, I is the indicative function. The constant
and
pointed in [2], and LASSO tuning parameter
, which controls the amount of penalty. The asymptotic properties about these penalty functions can be analogously derived in [3] and [2]. We call the penalty function
in (10) constructed from LASSO, MCP, SCAD jointly with the mixed
-norm as MIXLASSO-ML2, MIXMCP-ML2, MIXSCAD-ML2 penalties.
4. Numerical Solutions
A new method for maximizing the penalized log-likelihood function is the block-wise Minorization Maximization (MM) algorithm inspired by [8], which is also known as block successive lower-bound maximization (BSLM) algorithm in the language of [10]. At each iteration of the method, the function is maximized with respect to a single block of variables while the rest of the blocks are held fixed. We shall now proceed to describe the general framework of the algorithm.
4.1. Maximization of the Penalized Log-Likelihood Function
We follow the approach of [8] and minorize the
-approximate of -
by
(11)
where
, for some
, and
(12)
Moreover, minorize the log quasi-likelihood function
by
(13)
where
.
Note that
and
are analogous to the posterior probability and the expected complete-data log-likelihood function of the expectation-maximization algorithm respectively.
The block-wise MM algorithm maximizes
iteratively in the following two steps:
• Block-wise Minorization-step. Conditioned on the rth iterate
, the FM-GARCH model can be block-wise minorized in the coordinates of the parameter components
,
,
,
,
, and
, via the minorizers
(14)
(15)
(16)
(17)
respectively. Similar block-wise minorized can be made for FM-AR model.
• Block-wise Maximization-step. Upon finding the appropriate set of block-wise minorizers of
, we can maximize (14) to compute the
th iterate block-wise update of
. Solving for the appropriate root of the FOC (first-order condition) for the Lagrangian, we can compute the
th iterate block-wise update
(18)
for each k, where
, and
is the unique root of
 (19)
(19)
in the interval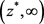 , and
, and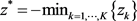 .
.
The block-wise updates for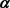 ,
, 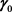 ,
,  ,
,  , and
, and 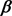 can be obtained by solving (15)-(17) via the first-order condition equal to 0.
can be obtained by solving (15)-(17) via the first-order condition equal to 0.
We now present a example of the Gaussian FM-GARCH model to specify the procedure described above, and give the following Lemma 1 about a useful minorizer for the MPL estimation of the Gaussian FM-GARCH model, which can be found in [11].
Lemma 1 if , then the function
, then the function  satisfy that
satisfy that
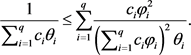 (20)
(20)
Example 1 We consider the Gaussian FM-GARCH Model,
 (21)
(21)
where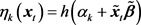 , and
, and .
.
Here, 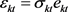 , and
, and 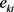 is an independent and identically distributed series with mean zero and variance unity.
is an independent and identically distributed series with mean zero and variance unity.
According to [8], and using Lemma 1, we can obtain the further minorizer of Gaussian FM-GARCH by
 (22)
(22)
where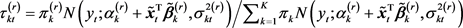 , and
, and
![]()
The block-wise updates of ![]() from Gaussian FM-GARCH Model come from (18), and the block-wise updates for
from Gaussian FM-GARCH Model come from (18), and the block-wise updates for![]() ,
, ![]() , and
, and![]() , can be obtained from (15)-(16) via the first-order condition equal to 0. By doing so, we obtain the coordinate-wise updates for
, can be obtained from (15)-(16) via the first-order condition equal to 0. By doing so, we obtain the coordinate-wise updates for![]() ,
, ![]() block
block
![]() (23)
(23)
![]() (24)
(24)
for each k. Moreover, the coordinate-wise updates for the ![]() and
and ![]() block
block
![]() (25)
(25)
![]() (26)
(26)
for each k, m, and s. Finally, making the substitute (22) into (17), the coordinate-wise updates for the ![]() block
block
![]() (27)
(27)
for each k and![]() , where
, where ![]() is the first derivative of (11) with respect to
is the first derivative of (11) with respect to![]() .
.
Note that (15)-(17) from Gaussian FM-GARCH Model are concave in the alternative parameterization![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , and
, and![]() , thus (23)-(27) globally maximize (15)-(17) over the parameter space.
, thus (23)-(27) globally maximize (15)-(17) over the parameter space.
4.2. Selection of Thresholding Parameters and Components
To implement the methods described in Sections 3 and 4.1, we need to select the size of the tuning parameters ![]() and
and![]() , the constant
, the constant ![]() and
and![]() , for
, for![]() , and components K. The current theory provides some guidance on the order of
, and components K. The current theory provides some guidance on the order of ![]() in [3] and [8] by using generalized cross validation (GCV) and Bayesian Information Criterion (BIC), to ensure the sparsity property. Following the example of [8], we develop a suitable BIC criterion for the FM-AR and FM-GARCH models. Let
in [3] and [8] by using generalized cross validation (GCV) and Bayesian Information Criterion (BIC), to ensure the sparsity property. Following the example of [8], we develop a suitable BIC criterion for the FM-AR and FM-GARCH models. Let![]() , and they are chosen one at a time by minimizing
, and they are chosen one at a time by minimizing
![]() (28)
(28)
where ![]() is the dimensionality of
is the dimensionality of ![]() (i.e. the total number of non-zero regression coefficients in these model), and
(i.e. the total number of non-zero regression coefficients in these model), and ![]() equal to 3K (FM-AR models) or 5K (for FM-GARCH models).
equal to 3K (FM-AR models) or 5K (for FM-GARCH models).
The Block-wise MM algorithm is iterated until some convergence criterion is met. In this article, we choose to use the absolute convergence criterion, where TOL > 0 is a small tolerance constant from [8]. Based on the discussion above, we summarise our algorithm in 1.
5. Simulated Data Analysis
In this section, we evaluate the performance of the proposed method and algorithm via simulations. We consider the Gaussian FM-AR models and Gaussian FM-GARCH models. Following [2] and [8], we used the correctly estimated zero coefficients (S1), correctly estimated non-zero coefficients (S2) and the mean estimate over all falsely identified non-zero predictors (![]() ). The selection of thresholding parameters and components are solving by using Simulated Annealing (SA) algorithm. All simulations were evaluated with varying values of dimension p with 100 repetitions done for each.
). The selection of thresholding parameters and components are solving by using Simulated Annealing (SA) algorithm. All simulations were evaluated with varying values of dimension p with 100 repetitions done for each.
5.1. Simulated Data Analysis of Gaussian FM-AR
The first simulations are based on the Gaussian FM-AR (2) model. Assuming that K is known, the model for the simulation was a ![]() and
and ![]() model of
model of
![]() (29)
(29)
![]()
where![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() , and
, and![]() . Columns of
. Columns of ![]() are drawn from a multivariate normal, with mean 0, variance 1, and two correlation structures:
are drawn from a multivariate normal, with mean 0, variance 1, and two correlation structures:![]() . The regression coefficients are
. The regression coefficients are
![]()
![]()
Table 1 reports the results. We can see that when the dimension p = 100, the S2 in com1 of ![]() from MIXSCAD-ML2 is 100, however, the S2 in com1 of
from MIXSCAD-ML2 is 100, however, the S2 in com1 of ![]() from MIXLASSO-ML2 (S2 = 70.7) and MIXMCP-ML2 (S2 = 51.3) model are small, which indicates that MIXSCAD-ML2 ensures that non-zero coefficients can be correctly identified and some non-zero coefficients in the MIXLASSO-ML2 and MIXMCP-ML2 model are not estimated. The mean estimate over all falsely identified non-zero predictors (
from MIXLASSO-ML2 (S2 = 70.7) and MIXMCP-ML2 (S2 = 51.3) model are small, which indicates that MIXSCAD-ML2 ensures that non-zero coefficients can be correctly identified and some non-zero coefficients in the MIXLASSO-ML2 and MIXMCP-ML2 model are not estimated. The mean estimate over all falsely identified non-zero predictors (![]() ) of
) of ![]() from MIXSCAD-ML2 are between 0.001 and 0.01.
from MIXSCAD-ML2 are between 0.001 and 0.01.
5.2. Simulated Data Analysis of Gaussian FM-GARCH
The second simulations are based on the Gaussian FM-GARCH(2,1,1) model. Also assuming that K is known, the model for the simulation was a![]() ,
, ![]() ,
, ![]() and
and ![]() model of
model of
![]() (30)
(30)
![]() (31)
(31)
for![]() , where
, where![]() ,
, ![]() ,
, ![]() ,
, ![]() and
and![]() ,
, ![]() and
and![]() ,
, ![]() and
and![]() ,
, ![]() and
and![]() .
.![]() ,
, ![]() is an independent and identically distributed series with mean zero and variance unity. Columns of
is an independent and identically distributed series with mean zero and variance unity. Columns of ![]() are drawn from a multivariate normal, with mean 0, variance 1, and two correlation structures:
are drawn from a multivariate normal, with mean 0, variance 1, and two correlation structures: ![]() . The regression coefficients are
. The regression coefficients are
![]()
Table 1. Summary of MIXLASSO-ML2, MIXMCP-ML2 and MIXSCAD-ML2-penalized FM-AR (2) model with BIC method form the simulated scenario. Average correctly estimated zero coefficients (specificity; S1), average correctly estimated non-zero coefficients (sensitivity; S1), and the mean ![]() estimate over all incorrectly estimated non-zero coefficients (MNZ) are also reported.
estimate over all incorrectly estimated non-zero coefficients (MNZ) are also reported.
![]()
![]()
From Table 2, we can see that in all simulations, the value of S1 in com1 and com2 of ![]() and
and ![]() from MIXSCAD-ML2 are the biggest, which indicates that MIXSCAD-ML2 perform better than MIXLASSO-ML2 and MIXMCP-ML2 in correctly estimated zero coefficients. The mean estimate over all falsely identified non-zero predictors (
from MIXSCAD-ML2 are the biggest, which indicates that MIXSCAD-ML2 perform better than MIXLASSO-ML2 and MIXMCP-ML2 in correctly estimated zero coefficients. The mean estimate over all falsely identified non-zero predictors (![]() ) of
) of ![]() from MIXSCAD-ML2 is smaller than which from MIXLASSO-ML2 and MIXMCP-ML2.
from MIXSCAD-ML2 is smaller than which from MIXLASSO-ML2 and MIXMCP-ML2.
6. Real Data Analysis
In this section, we evaluate the performance of the proposed method and algorithm via the analysis of the behavior of urban vehicular traffic of the city of São Paulo. This data set were collected notable occurrences of traffic in the metropolitan region of São Paulo in the period from 14 to 18 December 2009. This was acquired from the website http://archive.ics.uci.edu/ml/datasets.php. Registered from 7:00 to 20:00 every 30 minutes. It contains 135 observations and 18
![]()
Table 2. Summary of MIXLASSO-ML2, MIXMCP-ML2 and MIXSCAD-ML2-penalized FM-GARCH(1, 1) model with BIC method form the simulated scenario. Average correctly estimated zero coefficients (specificity; S1), average correctly estimated non-zero coefficients (sensitivity; S1), and the mean ![]() estimate over all incorrectly estimated non-zero coefficients (MNZ) are also reported.
estimate over all incorrectly estimated non-zero coefficients (MNZ) are also reported.
variables as well as one response variable. Covariate acronyms are hour (HO), immobilized bus (IB), broken truck (BT), vehicle excess (VE), accident victim (AV), running over (RO), fire vehicles (FV), occurrence involving freight (OIF), incident involving dangerous freight (IIDF), lack of electricity (LOE), fire (FI), point of flooding (POF), manifestations (MA), defect in the network of trolleybuses (DNT), tree on the road (TRR), semaphore off (SO), intermittent Semaphore (IS) and the response is slowness in traffic percent. Consider the effect of date on the behavior of traffic, we add a new variable that is day (DA). Figure 1 shows the heterogeneity of the data set, and the FM-AR or FM-GARCH model is applicable.
The levels of the covariates attributes from FMR, FM-AR (2) and FM-GARCH (2,1,1) with ![]() models are given in Table 3. From Table 4, we can see that the MIXSCAD-ML2 penalized FM-GARCH (2,1,1) with
models are given in Table 3. From Table 4, we can see that the MIXSCAD-ML2 penalized FM-GARCH (2,1,1) with ![]() model had the lowest BIC (622.9) across all analyses, the FM-AR (2) with
model had the lowest BIC (622.9) across all analyses, the FM-AR (2) with ![]() model being ranked second (
model being ranked second (![]() ), which is lower than the BIC (682.3) of FMR model. The predicted slowness in traffic percent from the FM-GARCH
), which is lower than the BIC (682.3) of FMR model. The predicted slowness in traffic percent from the FM-GARCH ![]() model had a MSE of 1.93 and a regression
model had a MSE of 1.93 and a regression ![]() of 0.90. The predicted slowness in traffic percent from the FM-AR (2)
of 0.90. The predicted slowness in traffic percent from the FM-AR (2) ![]() model had a MSE of 2.09 and a regression
model had a MSE of 2.09 and a regression ![]() of 0.89. The predicted slowness in traffic percent from the FMR
of 0.89. The predicted slowness in traffic percent from the FMR ![]() model had a MSE of 2.41 and a regression
model had a MSE of 2.41 and a regression ![]() of 0.87. These results suggest that the FM-GARCH (2,1,1) model had the smallest MSE and explained the largest proportion of variance for the slowness in traffic percent data. The results of the predicted response from these models are presented in Figure 2.
of 0.87. These results suggest that the FM-GARCH (2,1,1) model had the smallest MSE and explained the largest proportion of variance for the slowness in traffic percent data. The results of the predicted response from these models are presented in Figure 2.
![]()
Figure 1. Density of slowness in traffic percent in the metropolitan region of São Paulo in the period from 14 to 18 December 2009.
![]()
Table 3. Summary of FMR, FM-AR and FM-GARCH model with BIC method and MIXLASSO-ML2 penality.
![]()
Table 4. Summary of the values of BIC, MSE, and adjusted regression (predicted response on observed response) ![]() from FMR, FM-AR (2) and FM-GARCH (2,1,1) models.
from FMR, FM-AR (2) and FM-GARCH (2,1,1) models.
![]()
Figure 2. Summary of predicted and observed slowness in traffic percent in the metropolitan region of São Paulo in the period from 14 to 18 December 2009.
7. Discussion
In this article, we disccused that the modeling of response variable which is time series and with a finite mixture distribution depends on covariates, and the variable selection problem of them. We propose the FM-AR models and FM-GARCH models for modeling data that arise from a heterogeneous population which is time series, and propose a new regularization method (MIXLASSO-ML2, MIXMCP-ML2, MIXSCAD-ML2) for the variable selection in these model, which composed of the mixture of the ![]() penalty and
penalty and ![]() penalty proportional to mixing proportions. In addition, we estimate the maximum log quasi-likelihood estimate for the new penalized FM-AR and FM-GARCH model, and derive a general expression for the block-wise minimized maximization (MM) algorithm with better features. The simulation results of Gaussian FM-AR and Gaussian FM-GARCH models and an actual data set illustrate the capability of the methodology and algorithm, and MIXSCAD-ML2 is always superior to other penalty methods.
penalty proportional to mixing proportions. In addition, we estimate the maximum log quasi-likelihood estimate for the new penalized FM-AR and FM-GARCH model, and derive a general expression for the block-wise minimized maximization (MM) algorithm with better features. The simulation results of Gaussian FM-AR and Gaussian FM-GARCH models and an actual data set illustrate the capability of the methodology and algorithm, and MIXSCAD-ML2 is always superior to other penalty methods.