Adaptive Sparse Group Variable Selection for a Robust Mixture Regression Model Based on Laplace Distribution ()
1. Introduction
The mixture regression model is a powerful tool to explain the relationships between the response variable and the covariates when the population is heterogeneous and consists of several homogeneous components, and the early research can trace back to [1]. In 1977, EM algorithm was first proposed by [2] ; it greatly simplified the solution procedure of the mixture regression model. Then the mixture regression model attracted a lot of interest from statisticians; it was widely applied in many fields, such as business, marketing and social sciences. See [3] [4] [5] for example.
Recently, the research about the mixture regression model is becoming more and more detailed. On the one hand, statisticians paid attention to improving the robustness of mixture regression model, [6] used the t-distribution for overcoming the influence of outliers and [7] introduced a robust mixture regression model by assuming the error terms follow a Laplace distribution. Further, Wu et al. [8] dropped any parametric assumption about the error densities and proposed the mixture of quantile regressions model. On the other hand, variable selection became a research hotspot in mixture regression modeling. Khalili and Chen [9] considered a class of penalization methods, including L1-norm penalty, SCAD penalty and Hard penalty. Furthermore, the adaptive Lasso was introduced as a penalty function in [10], and [11] suggested the use of the Lasso-penalized mixture regression model as a screening mechanism in a two-step procedure.
However, the above regularization methods are more focused on individual variable selection. They all ignore the grouping structures which describe the inherent interconnections among predictors. It may lead to inefficient models. In order to achieve both the robustness of mixture regression model and correct identification of group structures, we assume random errors follow a Laplace distribution and consider a situation that covariates have natural grouping structures, where those in the same group are correlated. In this case, variable selection should be conducted at both the group-level and within-group-level; thus we use the adaptive sparse group Lasso [12] as a penalty function of our proposed mixture regression model and adopt EM algorithm to estimate the mixture regression parameters. Moreover, under some mild conditions, we can prove that the maximum penalized log-likelihood estimators are both sparse and
-consistent simultaneously.
The rest of this article is organized as follows. In Section 2, we introduce the robust mixture regression model based on Laplace distribution and adopt the adaptive sparse group Lasso for variable selection. In Section 3, we prove some asymptotic properties for our proposed method. In Section 4, we solve the problem of tuning parameters and components selection. Section 5 conducts a numerical simulation to evaluate the performance of our method. In Section 6, we apply our proposed method to NBA salary data. Finally, the conclusion of this paper is given in Section 7.
2. Model Overview
2.1. Robust Mixture Regression with Laplace Distribution
Let
be a random sample of observations from the population
, where
is a p-dimensional covariate vector, and
is the response variable which is dependent on corresponding
. Furthermore, for g mixture components, we can say that
follows a mixture linear regression model based on a normal distribution if the conditional density of y given
is
(1)
where the mixing probabilities satisfy
,
and the parameter
. For the jth mixture component, there are intercept
, regression coefficients
and variance
.
It is known that the mixture linear regression model is sensitive to outliers or heavy-tailed error distributions, and outliers impact more heavily on the mixture linear regression model than on the usual linear regression model, since outliers not only affect the estimation of the regression parameters, but also possibly totally blur the mixture structure. In order to improve the robustness of the estimation procedure, we introduce a robust mixture regression model with a Laplace distribution
(2)
Then we can estimate the unknown parameter
by maximizing the log-likelihood function
(3)
2.2. Adaptive Sparse Group Lasso for Variable Selection
Now, we consider a situation that covariates have natural grouping structures and can be divided into K groups as
by some known rules, where
is a group which contains
variables and
. Then, the log-likelihood function can be written as
(4)
where
.
In order to exploit the grouping structures of covariates, we apply the adaptive sparse group Lasso (adaSGL) to the robust mixture regression model, the penalized log-likelihood function
(5)
Here
(6)
where
represents the Euclidean norm,
and
. Moreover, the weights are defined based on the maximum penalized log-likelihood estimator
when
is a Lasso penalty,
(7)
Next, we follow the approach of Hunter and Li [13] and consider to maximize the
-approximate penalized log-likelihood function
(8)
Here
(9)
for some small
, and the weights are
(10)
Following Hunter and Li [13], we can similarly show that
uniformly as
, over any compact subset of the parameter space.
2.3. EM Algorithm for Robust Mixture Regression
However, the above penalized log-likelihood does not have an explicit maximizer. We introduce an EM algorithm to simplify the computation and denote
as a latent Bernoulli variable such that
(11)
If the complete data set
is observable, the complete log-likelihood function is
(12)
where
,
and
.
According to Andrews and Mallows [14], we know that a Laplace distribution can be expressed as a mixture of a normal distribution and another distribution related to the exponential distribution. To be specific, there are latent scale variables
such that we have the complete log-likelihood function
(13)
where
. Naturally, we can obtain the penalized complete log-likelihood
.
Suppose that
is a parameter estimate for the rth iteration. In E step of EM algorithm, we can get
by calculating
(14)
where
. And we can show that
(15)
and
(16)
The calculation for
follows the same argument as in Phillips [15].
In M step, we will maximize
for updating
. Now, we follow the tactic of [16] and find a local quadratic approximation of
,
(17)
in a neighborhood of
. Then, we can replace the penalty function
in
iteration by
(18)
where
and
. Similarly, from Lange [17], we have
(19)
in a neighborhood of
, where p is the dimensionality of
. And we apply (19) to
, there is a local approximation
of
(20)
in a neighborhood of
. Note that (20) can be block-wise maximized in the coordinates of the parameter components
,
,
and
. Here,
,
,
and
.
Under the constraints that
and
, we adopt Lagrangian multiplier to update
by solving
(21)
where
is the gradient operator,
is a positive scalar and
is a zero vector. Then we have the set of simultaneous equations
(22)
where
and
, for each j.
According to
and
, we can obtain the unique root
by solving the equation
(23)
Therefore, the
iterate
(24)
Furthermore, by solving
, we have the updates
(25)
and
(26)
Similarly, for the parameter
in kth group, we obtain the updated formula
(27)
by solving
.
Based on the above, we propose the following EM algorithm.
1) Choose an initial value
.
2) E-Step: at the
iteration, calculate
and
by (15) and (16).
3) M-Step: at the
iteration, update
,
,
and
by (24), (25), (26) and (27).
4) Repeat E-Step and M-Step until convergence is obtained.
Note that if a perfect least absolute deviation (LAD) fit occurs in EM algorithm, i.e.
for some i, j and r. As a result,
will become very large and numerical instability. In this article, we simply introduce a hard threshold to control the extremely small LAD residuals,
will be assigned a value of 106 when the perfect LAD fit occurs.
2.4. Convergence Analysis
The EM algorithm is iterated until some convergence criterion is met. Let tol be a small tolerance constant and M be the maximum iterations for the proposed algorithm, we believe the algorithm has converged to an ideal state when
(28)
or the iterations over the maximum iterations M. See [17] for details regarding the relative merits of convergence criteria.
According to Dempster et al. [2], each iteration of the E step and M step of EM algorithm monotonically non-decreases the objective function (8), i.e.
, for all
. Moreover, Wu [18] proved that if the EM sequence
coverges to some point
,
is a stationary point of (8) under some general conditions for
and
. Given the facts above, in this article, we run multiple times from different initializations
in order to obtain an appropriate limit point.
3. Asymptotic Properties
For the regression coefficient vector
in jth component, we can separate it into
, where
is the set of non-zero effects and
is the set of zero effects. Naturally, we decompose the parameter
such that
contains all zero effects, namely
,
. The true parameter is denoted as
and the elements of
are denoted with a subscript, such as
.
For the purpose of easy discussion, we define
,
,
,
. Furthermore, we let
be the joint density function of
and
be an open parameter space. In order to prove the asymptotic properties of the proposed algorithm, some regularity conditions on the joint distribution of
are also required.
A1. The density
has common support in
for all
and
is identifiable in
up to a permutation of the components of the mixture.
A2. For each
, the density
admits third partial derivatives with respect to
for almost all
.
A3. For each
, there are functions
and
(possibly depending on
) such that for
in a neighborhood of
,
such that
and
.
A4. The Fisher information matrix
is finite and positive definite for each
.
Theorem 1. Let
,
, be a random sample from the joint density function
that satisfies the regularity conditions A1-A4. Suppose that
and
, as
, then there is a local maximizer
of the model (5) for which
where
represents convergence in probability.
Proof. Let
. It suffices that for any given
, there is a constant
such that
(29)
Now, there is a local maximum in
with large probability, and this local maximizer
satisfies
. Then we let
(30)
Without loss of generality, we assume that the first
coefficients of
are non-zero and the first
groups contain all non-zero effects of
, where
is the true regression coefficient vector in the jth component of the mixture regression model. Hence, we have
(31)
Since
is a sum of non-negative terms, removing terms corresponding to zero effects makes it smaller,
(32)
By Taylor’s expansion, triangular inequality and arithmetic-geometric mean inequality,
(33)
Regularity conditions indicate that
and
is positive definite, and it is not difficult to find that the sign of
is completely determined by
. Therefore, for any given
, there is a sufficiently large
such that
(34)
which implies (29), this completes the proof.
Theorem 2. Suppose that the conditions given in Theorem 1 and g is known,
,
,
and
, as
. Then, for any
-consistent maximum penalized log-likelihood estimator
, we have the following:
1) Sparsity: As
,
,
.
2) Asymptotic normality:
where
denotes convergence in distribution and
is a Fisher information when all zero effects are removed.
Proof. In order to prove the sparsity of Theorem 2, we consider the partition
and let
is the maximizer of the penalized log-likelihood function
, which is regarded as a function of
. It suffices to show that in the neighborhood
, there is the probability
as
. Then we have
(35)
On the other hand,
(36)
By the mean value theorem,
(37)
for some
. By the mean value theorem and regularity condition A3, we can get
(38)
Here
is a subvector of
with all zero regression coefficients removed. Regularity conditions imply that
, therefore
. In this case, we have
(39)
for large n. And for the penalized function
,
(40)
Since
and
as
, we have
(41)
with probability to one as
. This completes the proof of the sparsity.
For the asymptotic normality of Theorem 2, we still use the same argument as in Theorem 1 and consider
is a function of
, there is a 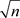 -consistent local maximizer of this function, say
-consistent local maximizer of this function, say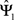 , that satisfies
, that satisfies
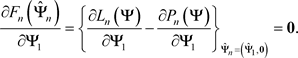 (42)
(42)
By the Taylor’s expansion,
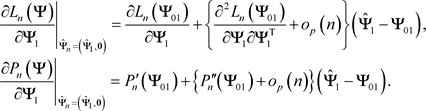 (43)
(43)
Substituting into (42), we have
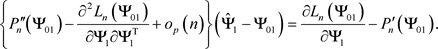 (44)
(44)
In addition, regularity conditions imply that
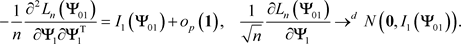 (45)
(45)
Finally, we can get
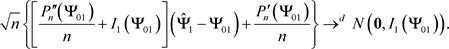 (46)
(46)
by the Slutsky’s theorem. This completes the proof of the asymptotic normality.
Now, we know that, as long as the conditions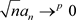 ,
, 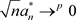 ,
, 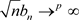 and
and 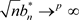 are satisfied when
are satisfied when , the conclusions of theorem 1 and theorem 2 are tenable. Since the estimator
, the conclusions of theorem 1 and theorem 2 are tenable. Since the estimator 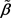 based on the Lasso penalty, it can be
based on the Lasso penalty, it can be 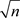 -consistent. Then, for any
-consistent. Then, for any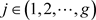 , we have
, we have 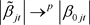 for
for 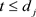 and
and 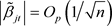 for
for![]() . Based on the fact
. Based on the fact![]() , we can take
, we can take ![]() which satisfies the
which satisfies the ![]() and
and![]() . Similarly, for
. Similarly, for ![]() with
with ![]() for
for ![]() and
and ![]() for
for![]() , we also take
, we also take ![]() to satisfy the
to satisfy the ![]() and
and![]() .
.
4. Tuning Parameters and Components Selection
In this section, we need to solve two problems. One concerns the number of components g and the other problem is the selection of the tuning parameters![]() . Until now, there is little theoretical support for the selection of these hyper parameters. In former literatures, the cross validation [19] and the generalized cross validation [20] provided some effective guidances for these problems. Grün and Leisch [21] and Nguyen and McLachlan [22] indicated that the Bayesian information criterion (BIC) has a good performance in solving these problems. In this paper, we still use the BIC,
. Until now, there is little theoretical support for the selection of these hyper parameters. In former literatures, the cross validation [19] and the generalized cross validation [20] provided some effective guidances for these problems. Grün and Leisch [21] and Nguyen and McLachlan [22] indicated that the Bayesian information criterion (BIC) has a good performance in solving these problems. In this paper, we still use the BIC,
![]() (47)
(47)
where ![]() the number of non-zero regression coefficients in the jth regression model.
the number of non-zero regression coefficients in the jth regression model.
Suppose that there is a set of parameter combinations![]() . For each parameter combination
. For each parameter combination![]() ,
, ![]() , we can obtain the parameter estimate
, we can obtain the parameter estimate ![]() by the proposed algorithm, and there is a
by the proposed algorithm, and there is a ![]() which depends on corresponding
which depends on corresponding![]() . Finally, we set the best parameter combination
. Finally, we set the best parameter combination ![]() for our robust mixture model, where
for our robust mixture model, where![]() .
.
5. Numerical Simulation
To quantify the performance of our proposed robust mixture regression model based on adaptive sparse group Lasso (adaSGL-RMR), we design a numerical simulation and generate sample data ![]() from the following mixture regression model
from the following mixture regression model
![]() (48)
(48)
where Z is a component indicator. There are ![]() groups and each group consists of 5 covariates, covariates within the same group are correlated, whereas those in different groups are uncorrelated. In order to generate the covariates
groups and each group consists of 5 covariates, covariates within the same group are correlated, whereas those in different groups are uncorrelated. In order to generate the covariates![]() , we first generate 30 random variables,
, we first generate 30 random variables, ![]() , independently from
, independently from![]() , then obtain
, then obtain![]() ,
, ![]() , from a multivariate normal distribution with mean zero and
, from a multivariate normal distribution with mean zero and![]() . The generation of the covariates
. The generation of the covariates ![]() as following:
as following:
![]() (49)
(49)
The model parameters include![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
, ![]() ,
,![]() . The random error
. The random error ![]() and
and ![]() are independent and we consider the follow four cases: 1)
are independent and we consider the follow four cases: 1)![]() ; 2)
; 2) ![]() Laplace distribution with mean 0 and variance 1; 3)
Laplace distribution with mean 0 and variance 1; 3)![]() , t-distribution with 3 degrees of freedom; 4) a mixture normal distribution
, t-distribution with 3 degrees of freedom; 4) a mixture normal distribution![]() .
.
We use three methods for comparing. The Gaussian mixture model (GMM) based on Lasso penalty (Lasso-GMM), the GMM model based on adaptive Lasso penalty (adaL-GMM) and the adaSGL-RMR model. The fmr package of the R programming language is used to compute the parameter estimates of Lasso-GMM and adaL-GMM.
In this article, the algorithm is terminated when the change in the penalized complete log-likelihood function is less than 10−5 or meets the maximum iterations 105. Furthermore, we adopt a threshold value for ![]() in the consideration of practical situation. To be specific,
in the consideration of practical situation. To be specific, ![]() will be assigned a value of 0 if
will be assigned a value of 0 if![]() , for some j and t. To evaluate the performances of variable selection and data fitting, we introduce the average number of selected non-zero variables (nvars) without intercepts, average number of selected non-zero groups (ngroups), frequency of correct identification of group sparsity structures (cgroups), false negative rate (FNR) of missing important predictors, false positive rate (FPR) of selecting unimportant predictors and average value of root mean square errors (RMSE). Here,
, for some j and t. To evaluate the performances of variable selection and data fitting, we introduce the average number of selected non-zero variables (nvars) without intercepts, average number of selected non-zero groups (ngroups), frequency of correct identification of group sparsity structures (cgroups), false negative rate (FNR) of missing important predictors, false positive rate (FPR) of selecting unimportant predictors and average value of root mean square errors (RMSE). Here,
![]() (50)
(50)
and
![]() (51)
(51)
where TP is the number of true positives, TN is the number of true negatives, FP is the number of false positives and FN is the number of false negatives for each fitted model.
As shown in Table 1, in case (1) through case (4), Lasso-GMM fails to identify non-zero groups and selects too many unimportant predictors, adaL-GMM is inclined to select less unimportant predictors and achieves higher cgroups at the cost of ignoring some important predictors. As a contrast, adaSGL-RMR has a better performance in variable selection and RMSE indicates that the parameter estimates of our algorithm are closer to the true parameters of mixture regression model. Moreover, the simulation results clearly show that adaSGL-RMR still maintain its superiority in identifying the group sparsity structures when the distribution of random errors has a heavy tail. Therefore, no matter from the model complexity or the goodness of fit to the data, our proposed method is more competitive than other methods.
![]()
Table 1. Results of Lasso-GMM, adaL-GMM and adaSGL-RMR on 100 replicates,![]() .
.
6. Real Data Analysis
In this section, we will analyze how NBA players’ performances of regular season affect their salaries. We gather salaries for all players in the NBA from the website https://hoopshype.com/salaries/players/2018-2019, during the period from 2018 to 2019. Performance measures for individuals are gathered from the website https://www.foxsports.com/nba/stats?season=2018 in the 2018-2019 regular season, which include scoring, rebounding, assists and defense statistics. By liminating missing data, we obtain a complete dataset, which contains salaries for 248 NBA players and 27 measures of performance.
These performance measures are divided into five groups and covariates in the same group are correlated. Score: points per game (PPG), points per 48 minutes (PTS/48), field goals made per game (FGM/G), field goal attempts per game (FGA/G), 3 point FG made per game (3FGM/G), 3 point FG attempts per game (3FGA/G), free throws made per game (FTM/G), free throw attempts per game (FTA/G), high point total in a single game (HIGH), points per shot (PPS). Rebound: offensive rebounds per game (ORPG), defensive rebounds per game (DRPG), rebounds per 48 minutes (RPG/48), offensive rebound% (OFF REB%), defensive rebound% (DEF REB%), rebound% (REB%). Assist: assists per game (APG), assists per 48 minutes (AST/48), assist% (AST%), turnovers per game (TPG), turnover% (TO%). Steal: steals per game (SPG), steals per 48 minutes (STL/48), steal% (STL%). Block: blocks per game (BPG), blocks per 48 minutes (BLK/48), block% (BLK%).
The matrix ![]() should be column standardized to have mean 0 and variance 1 for avoiding a poor fitting result. Then we use the stepAIC function from R package MASS to realize variable selection of the standard linear model via the BIC, the predicted logged salaries from the stepwise-BIC linear model shows a mean square error (MSE) of 0.60 and adjusted R2 of 0.42, these terrible results motivate us to conduct further research for this problem. The logged salaries histogram shows multi-modality from Figure 1, it is acceptable to use the mixture regression model for predicting the logged salaries.
should be column standardized to have mean 0 and variance 1 for avoiding a poor fitting result. Then we use the stepAIC function from R package MASS to realize variable selection of the standard linear model via the BIC, the predicted logged salaries from the stepwise-BIC linear model shows a mean square error (MSE) of 0.60 and adjusted R2 of 0.42, these terrible results motivate us to conduct further research for this problem. The logged salaries histogram shows multi-modality from Figure 1, it is acceptable to use the mixture regression model for predicting the logged salaries.
For comparison, we run multiple analyses that include three sets of starting parameters for each of ![]() models. The predicted results from the
models. The predicted results from the ![]() adaSGL-RMR model (BIC = 625) have a MSE of 0.11 and adjusted R2 of 0.90. The predicted results from the
adaSGL-RMR model (BIC = 625) have a MSE of 0.11 and adjusted R2 of 0.90. The predicted results from the ![]() adaSGL-RMR model (BIC = 598) have a MSE of 0.05 and adjusted R2 of 0.95. The predicted results from the
adaSGL-RMR model (BIC = 598) have a MSE of 0.05 and adjusted R2 of 0.95. The predicted results from the ![]() adaSGL-RMR model (BIC = 517) have a MSE of 0.04 and adjusted R2 of 0.96. See Table 2 for more details. These results suggest that the
adaSGL-RMR model (BIC = 517) have a MSE of 0.04 and adjusted R2 of 0.96. See Table 2 for more details. These results suggest that the ![]() adaSGL-RMR model has the smallest MSE and explains the largest proportion of variance for the logged salaries from the 2018/19 NBA regular season. Moreover, from Figure 2, the predicted densities show a good characterization of the multi-modality in the logged salaries for the adaSGL-RMR models, with the stepwise-BIC linear model not being able to model this.
adaSGL-RMR model has the smallest MSE and explains the largest proportion of variance for the logged salaries from the 2018/19 NBA regular season. Moreover, from Figure 2, the predicted densities show a good characterization of the multi-modality in the logged salaries for the adaSGL-RMR models, with the stepwise-BIC linear model not being able to model this.
![]()
Figure 1. Histogram and density estimate for logged salaries
![]()
![]()
Table 2. Parameter estimates for NBA salary data.
![]()
Figure 2. Summary of densities for predicted and observed logged salaries.
7. Conclusion
In this paper, we propose a robust mixture regression model based on a Laplace distribution and consider the adaptive sparse group Lasso for variable selection. Its oracle properties are proved completely in Section 3. In addition, the numerical simulation and real data application show that our method has better performance in parameter estimation and variable selection than other methods. A limitation of this study is that we only consider the mixture regression model with K no-overlapping groups and ignore the case when there are some overlaps between different groups. In our future work, we will pay more attention to this problem.