Some Likelihood Based Properties in Large Samples: Utility and Risk Aversion, Second Order Prior Selection and Posterior Density Stability ()
1. Introduction
Research Background
The importance of the likelihood function to statistical modeling and parametric statistical inference is well known, from both frequentist and Bayesian perspectives. From the frequentist perspective the likelihood function yields minimal sufficient statistics, if they exist, as well as providing a tool for the generating of pivotal quantities and measures of information on which to base estimation and hypothesis testing procedures [1] .
For researchers employing a Bayesian perspective the likelihood function is modulated into a probability distribution directly on the parameter space through the use of a prior density and Bayes theorem [2] . The Bayesian context preserves the whole of the likelihood function and allows for the use of probability calculus on the parameter space Ω itself. This usually takes the form of averaging out unwanted parameters in order to obtain marginal distributions for parameters of interest.
Current Research
Research into the properties of the likelihood function has often focused on the properties of the maximum likelihood estimator, and likelihood ratio based testing of hypotheses [3] . A review can be found in [4] . As well, recent work has examined likelihood based properties in relation to saddlepoint approximation based limit theorem results [5] . The Cramer Rao bound or Fisher information continues to be of interest across a wide set of applied fields [6] , providing a measure of overall accuracy in the modeling process. Information theoretic measures based on likelihood, such as the AIC measure [7] are commonly applied to assess relative improvement in model predictive properties.
From a Bayesian perspective much recent work has focused on the application of Markov Chain Monte Carlo (MCMC) based approximation and methodology [8] [9] . The algorithms that have been developed in these settings have greatly widened the areas of application for the Bayesian interpretation of likelihood [10] .
Prior density selection has often focused on robustness issues [11] where the sensitivity of the posterior density to the selected prior is of interest. Some focus has also been given to choose priors in order to match frequentist and Bayesian inference in terms of choosing priors that match p-values and posterior probabilities, so-called first order matching [12] . Here a focus is placed on large samples and the broader concept of information.
The application of utility theory in a Bayesian context reflects several possible definitions and approaches [2] and some of these are discussed below. This however has been viewed independently of the likelihood concept with utility functions typically assumed in addition to the assumed prior. Here a learning perspective regarding how information is collected and processed through the parametric model in large samples is considered with the likelihood function and the related score function playing key roles in the interpretation of the posterior density from several perspectives.
Research Approach and Strategy
The Bayesian perspective provides the context for this approach, yielding a probability-likelihood pair that allows us to relate expected utility maximization with optimal statistical inference and large sample properties of the likelihood function. From this perspective the well-known Arrow-Pratt risk aversion theorem is shown to be a function of the standardized score statistic and Cramer-Rao Information bound.
2. Fundamental Principles
The likelihood function can be written;
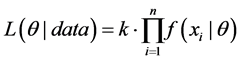 (1)
(1)
where 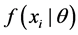 is the probability density for the ith independent response and k is a constant emphasizing the fact that the likelihood is a function of
is the probability density for the ith independent response and k is a constant emphasizing the fact that the likelihood is a function of 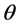 not a density for
not a density for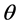 . The likelihood function is the key source of information to be drawn from a given model-data combination. Often the mode of the likelihood function
. The likelihood function is the key source of information to be drawn from a given model-data combination. Often the mode of the likelihood function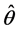 , the maximum likelihood estimator, is the basis of frequentist inference. The local curvature of the log-likelihood about its mode provides the basis of the Fisher Information and related Cramer-Rao information lower bound.
, the maximum likelihood estimator, is the basis of frequentist inference. The local curvature of the log-likelihood about its mode provides the basis of the Fisher Information and related Cramer-Rao information lower bound.
The Bayesian approach or perspective is based on the joint posterior density which can be expressed as;
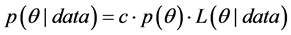 (2)
(2)
here 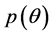 is the prior density,
is the prior density, 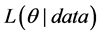 the likelihood function and
the likelihood function and 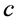 the constant of integration. All three functions of
the constant of integration. All three functions of 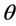 can be viewed as weighting the parameter space, with prior and posterior densities restricted to a probability scale.
can be viewed as weighting the parameter space, with prior and posterior densities restricted to a probability scale.
The posterior density 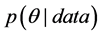 can be viewed as an updated description of the researcher’s beliefs regarding potential values of the parameter
can be viewed as an updated description of the researcher’s beliefs regarding potential values of the parameter 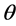 and is interpreted conditionally upon the observed data. From baseline beliefs for
and is interpreted conditionally upon the observed data. From baseline beliefs for 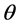 reflected in the shape of the prior density
reflected in the shape of the prior density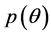 , the likelihood function updates these beliefs in light of the observed model and data giving the posterior density. Once the joint posterior is obtained, integration is employed in the Bayesian setting to obtain marginal posterior densities for any given
, the likelihood function updates these beliefs in light of the observed model and data giving the posterior density. Once the joint posterior is obtained, integration is employed in the Bayesian setting to obtain marginal posterior densities for any given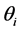 . For example;
. For example;
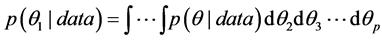 (3)
(3)
gives the marginal posterior for 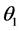 alone. The central region of this density is a Bayesian credible region which can be used for estimation regarding
alone. The central region of this density is a Bayesian credible region which can be used for estimation regarding . Both approaches to inference may employ approximation, typically based on larger sample sizes, to evaluate required tail areas or central estimation regions. With the advent of Markov Chain Monte Carlo (MCMC) based methods calculations in many Bayesian settings are possible [8] .
. Both approaches to inference may employ approximation, typically based on larger sample sizes, to evaluate required tail areas or central estimation regions. With the advent of Markov Chain Monte Carlo (MCMC) based methods calculations in many Bayesian settings are possible [8] .
Bayesian statistical analysis as an approach to the interpretation of statistical models has grown rapidly in application over the past several decades. This has been especially true in the basic sciences which, while traditionally not very open to the more subjective Bayesian perspective, have been open to its broader and more flexible modeling approach [13] . Bayesian analysis does however require an understanding of the analyst’s set of prior beliefs regarding the set of population characteristics or parameters of interest and provides a process by which they will be updated by the observed model-data combination. Typically these are defined in the context of a mathematical model and beliefs must be assumed for the entire set of potential values for the population parameters, even those that may not be significant in the final analysis.
This can initially be seen in relation to central limit theorems. Subject to regularity conditions [1] the following result holds as![]() ,
,
![]() (4)
(4)
a sampling theory result from the frequentist perspective where ![]() is the Fisher information and
is the Fisher information and ![]() the well known Cramer-Rao bound.
the well known Cramer-Rao bound.
It is also true that, conditional on the data x, as![]() ;
;
![]() (5)
(5)
from the Bayesian perspective with ![]() the observed Fisher information. Note in large samples that
the observed Fisher information. Note in large samples that ![]() in probability.
in probability.
The Bayesian perspective on statistics can be viewed as providing models for learning based behavior. The “prior” density ![]() serves as an initial baseline for the analyst’s beliefs regarding potential values of
serves as an initial baseline for the analyst’s beliefs regarding potential values of![]() . The prior is then updated as observed data is processed. The information is collected via the likelihood function and processed through the prior-likelihood pair to give the posterior density. The result is a reweighting of belief regarding
. The prior is then updated as observed data is processed. The information is collected via the likelihood function and processed through the prior-likelihood pair to give the posterior density. The result is a reweighting of belief regarding![]() .
.
3. Likelihood Related Stability in the Posterior Density
The learning aspect of Bayesian methods is based on the likelihood function. The information-theoretic aspects of the likelihood function summarize and provide information to update beliefs regarding![]() . There are various approaches to assessing the rate and stability with which the posterior modifies or “learns”. The inferential stability of the posterior density can be seen as a function of its rate of change and (on a logarithmic scale) depends directly on the additive rates of change in the prior density and log-likelihood.
. There are various approaches to assessing the rate and stability with which the posterior modifies or “learns”. The inferential stability of the posterior density can be seen as a function of its rate of change and (on a logarithmic scale) depends directly on the additive rates of change in the prior density and log-likelihood.
Assuming a scalar ![]() we have;
we have;
![]() (6)
(6)
Note that Bayesian inference, by employing the likelihood function, inherits many optimal properties of the frequentist-likelihood approach to inference. This includes the score function, which is at the heart of frequentist-likelihood inference [3] and can be written;
![]() (7)
(7)
and is also a component of the posterior rate of change. The only difference between the rate of change of the log posterior and the score function is the rate of change in the log prior, which is zero if the prior is non-informative or constant.
![]() (8)
(8)
In these settings, the score function provides information regarding the percent rate of change in the posterior as a function of![]() . In effect the elasticity of the Bayesian posterior density.
. In effect the elasticity of the Bayesian posterior density.
![]() (9)
(9)
In other words the relative changes in the log-posterior will reflect directly the asymptotic behavior of the Score function.
Taking a frequentist perspective on the data, the asymptotic distribution of the score function can be applied to provide large sample bounds for the standardized rate of change in the log posterior in relation to the log prior baseline. Giving the result;
![]() (10)
(10)
where I is the identity matrix here. In case of a scalar ![]() it follows that;
it follows that;
![]() (11)
(11)
Thus on a logarithmic scale the difference in rates of change or elasticity in the posterior versus prior is bounded by the observed Fisher information![]() . Thus the information provided by the likelihood function is key in assessing bounds on a measure of change from prior to posterior. Note that a similar result can be expressed more generally in terms of the Kullback-Liebler distance measure [19] .
. Thus the information provided by the likelihood function is key in assessing bounds on a measure of change from prior to posterior. Note that a similar result can be expressed more generally in terms of the Kullback-Liebler distance measure [19] .
In multivariate parameter settings the effect of integrating out unwanted or nuisance parameters may affect the nominal accuracy of the resulting marginal posterior. Thus the similarity between the results that as![]() ,
, ![]() or
or
![]() may not be as direct on a marginal scale.
may not be as direct on a marginal scale.
4. Utility Functions
The Von Neumann-Morgenstern utility representation theorem [14] has four possible axioms, though the independence axiom is sometimes dropped and is so here where a simple scalar parameter setting is examined. Where the large sample log-likelihood ![]() is concave (quadratic) and continuous, the axioms can be seen to apply directly with the ranking
is concave (quadratic) and continuous, the axioms can be seen to apply directly with the ranking ![]() defined by
defined by![]() , and A, B and C values for
, and A, B and C values for ![]() in the support of the log-likelihood function;
in the support of the log-likelihood function;
1) Completeness: The individual either prefers A to B, or is indifferent between A and B, or prefers B to A. The concave and continuous weighting provided by the large sample shape of the log-likelihood function satisfies this condition.
2) Transitivity: For every A, B and C with ![]() and
and ![]() we must have
we must have![]() . This follows directly from the continuous, quadratic concave shape of the large sample log-likelihood function.
. This follows directly from the continuous, quadratic concave shape of the large sample log-likelihood function.
3) Continuity: Let A, B and C be such that![]() ; then there exists a probability weighting p such that B is equally good as
; then there exists a probability weighting p such that B is equally good as![]() . This holds for the con- tinuous, quadratic concave shape of the large sample log-likelihood when weighted by an appropriately chosen prior density
. This holds for the con- tinuous, quadratic concave shape of the large sample log-likelihood when weighted by an appropriately chosen prior density![]() .
.
In large samples the log-likelihood (or likelihood) provides a pseudo-utility function that satisfies the above axioms of utility in relation to preferred values for the parameter![]() . The likelihood and prior density can be interpreted as a conceptual pair and the resulting posterior or log-posterior an expected utility providing a preference related weighting of the parameter space.
. The likelihood and prior density can be interpreted as a conceptual pair and the resulting posterior or log-posterior an expected utility providing a preference related weighting of the parameter space.
The log-likelihood converges to a quadratic form across a wide set of assumed probability models for the observed data. These typically comprise the exponential family of probability densities. The associated regularity conditions can be found in [1] .
The log-concavity of the large sample likelihood can be expressed;
![]() (12)
(12)
While initially most likelihood functions may not have the properties necessary to be viewed as utility functions, in large samples many likelihoods do have these properties, subject to regularity conditions, and are log-concave, continuous and differentiable.
In the scalar ![]() case the result;
case the result;
![]() (13)
(13)
can be interpreted as the likelihood function having a large sample bell curve shape. The related log-likelihood function is quadratic, an acceptable form for consideration as a utility function and the required conditions above are met.
5. Interpreting Risk Aversion in Large Samples
The Arrow-Pratt absolute risk aversion (ARA) measure [14] is defined generally as;
![]() (14)
(14)
where ![]() is an expected utility function. It is often used as a standardized measure of risk aversion in regard to expected utility. In a large sample where we take a relatively flat prior density, the ARA measure is simply the inverse of the standardized score function and thus a standardized rate of preference modification with regard to the posterior density function and the parameter
is an expected utility function. It is often used as a standardized measure of risk aversion in regard to expected utility. In a large sample where we take a relatively flat prior density, the ARA measure is simply the inverse of the standardized score function and thus a standardized rate of preference modification with regard to the posterior density function and the parameter![]() .
.
Writing ![]() as the log posterior density and assuming a first order
as the log posterior density and assuming a first order
condition on the prior density![]() , we can express the ARA measure in
, we can express the ARA measure in
terms of;
![]() (15)
(15)
This interpretation also allows for a central limit theorem related argument regarding ARA−1 in large samples which bounds the ARA measure of risk aversion in relation to the Cramer Rao information bound;
Theorem 1 The function ![]() has a large sample
has a large sample ![]()
distribution for large n.
Proof. Taking limits and assuming standard likelihood related regularity conditions hold, the central limit theorem for the score function, the strong law of large numbers and Slutsky’s theorem can be applied giving;
![]() (16)
(16)
This is a simple restatement of the large sample or asymptotic efficiency of the score function and optimality of the Cramer-Rao lower bound [1] , but in relation to the consumption of information and related risk aversion. This provides an asymptotic variance for ARA−1 when appropriate. It can also be argued that the ARA−1 measure is efficient in the processing of information as its variation attains the Cramer-Rao information bound in large samples.
While not practical, a large sample 95% confidence related bound on ARA−1 or ARA can be defined in relation to statistical information;
![]() (17)
(17)
It is interesting to note that the Likelihood Principle is implicitly relevant to this result. As noted earlier, this principle states that inference from two proportional likelihood functions, ![]() , should be the same. This is equivalent to saying that the derivative of the log-likelihoods or Score functions are equivalent
, should be the same. This is equivalent to saying that the derivative of the log-likelihoods or Score functions are equivalent ![]() and thus the rate of learning is equivalent if the priors in question are non-informative.
and thus the rate of learning is equivalent if the priors in question are non-informative.
In terms of utility, this implies that two proportional log-likelihood functions in large samples can be viewed as having identical large sample ARA−1 values in relation to the information content of the respective model-data combinations. Thus proportional likelihoods yield similar levels of risk aversion in large samples.
Note that the likelihood function is log-concave generally when we have the con- dition;
![]() (18)
(18)
This may hold in some small sample settings with non-informative prior densities. The simplest approach to ensuring a log-concave likelihood in small samples is to work with log-concave densities [24] . This reflects the basic property that If X and Y have log-concave densities, so does![]() . The Normal, Poisson and Binomial distributions for example have this property, Note that the Cauchy, Pareto and log-Normal distri- butions are not log concave densities. Mixtures of the normal and other distributions may or may not have this property.
. The Normal, Poisson and Binomial distributions for example have this property, Note that the Cauchy, Pareto and log-Normal distri- butions are not log concave densities. Mixtures of the normal and other distributions may or may not have this property.
6. Prior Selection: Enabling Likelihood Based Learning
As noted above, Bayesian methods obtain their accuracy and informative nature by depending heavily on the likelihood function. In emphasizing a learning model perspective, and imposing the requirement that we learn from the likelihood function, the technical link between posterior and likelihood allows for consideration of the likelihood in relation to choosing a prior. In particular, this can be examined from the perspective of statistical information and linking aspects of the log-likelihood with posterior stability, matching the curvature of the log-likelihood function, the observed Fisher Information, to the curvature of the posterior density. This gives rise to conditions that help guide the selection of prior densities.
The Bayesian perspective reflects a learning process in regard to the parameter![]() . This learning process should not be a function of pre-existing belief which in a sense sets the baseline of existing knowledge. Rather it should reflect the properties and information of the model-data combination in the form of the likelihood function. Here we suggest an approach to prior selection which focuses on matching the information properties of the likelihood and posterior densities and gives a family of prior densities from which to choose.
. This learning process should not be a function of pre-existing belief which in a sense sets the baseline of existing knowledge. Rather it should reflect the properties and information of the model-data combination in the form of the likelihood function. Here we suggest an approach to prior selection which focuses on matching the information properties of the likelihood and posterior densities and gives a family of prior densities from which to choose.
Define the concept of posterior information as the local curvature of the log- posterior about its mode;
![]() (19)
(19)
where ![]() is the observed Fisher information
is the observed Fisher information![]() .
.
Given the selection of a prior which is to be non-informative at the level of information processing, and assuming that standard regularity conditions apply to the likelihood function [1] , we set the following second order condition on the prior density;
![]() (20)
(20)
or more reasonably;
![]() (21)
(21)
where k is a constant. This implies that, up to a multiplicative constant, the likelihood based Fisher Information in the model-data combination is the basis of all Bayes posterior information. Researchers learn from the likelihood, not from the prior.
The family of information similar priors chosen in this manner are non-informative to the second order and are of the form;
![]() (22)
(22)
where ![]() are constants. Note that this implies an exponential family related class of prior distributions from which to choose, which may or may not be conjugate to the posterior density. A reasonable restriction on the constants
are constants. Note that this implies an exponential family related class of prior distributions from which to choose, which may or may not be conjugate to the posterior density. A reasonable restriction on the constants ![]() is to require the prior to be well defined. The normal, binomial and Poisson distributions satisfy this restriction as do most standard choices for priors. Technically so do flat or highly non-informative priors. Distributions with third or higher order polynomials are ruled out.
is to require the prior to be well defined. The normal, binomial and Poisson distributions satisfy this restriction as do most standard choices for priors. Technically so do flat or highly non-informative priors. Distributions with third or higher order polynomials are ruled out.
Some examples of priors that are not acceptable in this setting include;
![]() (23)
(23)
Note that while focusing here on learning from likelihood, the effect of integration or shrinkage may imply some prior effect in the multivariate setting when integrating to obtain marginal posteriors. The use of hyperparameters in hierarchical or empirical Bayesian settings raise related issues. These are examined in detail elsewhere.
The Jeffreys prior [25] in large samples achieves such an information similar effect. Considering the Bayesian asymptotic result ![]() the Jeffreys prior can be taken as the inverse of the observed variance or Cramer-Rao bound
the Jeffreys prior can be taken as the inverse of the observed variance or Cramer-Rao bound![]() . This is essentially the inverse of the local curvature of the log likelihood function and will behave locally as the inverse of asymptotic variation; it will be relatively flat where the likelihood is pronounced. This will be approximately non-informative in the sense defined here; it focuses on preserving the local shape of the likelihood about its mode as a key element of the shape of the posterior density.
. This is essentially the inverse of the local curvature of the log likelihood function and will behave locally as the inverse of asymptotic variation; it will be relatively flat where the likelihood is pronounced. This will be approximately non-informative in the sense defined here; it focuses on preserving the local shape of the likelihood about its mode as a key element of the shape of the posterior density.
Example
Consider the case of nonlinear regression with Normal error.
![]() (24)
(24)
where the x are fixed, the ![]() are
are ![]() and
and ![]() represents the nonlinear regression surface. Let
represents the nonlinear regression surface. Let ![]() be a scalar parameter. The Jeffreys prior for this was suggested in [26] and is given by;
be a scalar parameter. The Jeffreys prior for this was suggested in [26] and is given by;
![]() (25)
(25)
where ![]() is the first order derivative of
is the first order derivative of ![]() with regard to
with regard to![]() , where
, where ![]() is assumed known or estimated by the MSE. This is acceptable in terms of information similarity if it has the property;
is assumed known or estimated by the MSE. This is acceptable in terms of information similarity if it has the property;
![]() (26)
(26)
This implies that nonlinear regression surfaces should not be too complex as a function of ![]() if they enter into the related processing of likelihood based information.
if they enter into the related processing of likelihood based information.
Multiparameter Settings
In multiparameter settings, where![]() , this approach provides guidance in selecting priors if information matching is applied. The resulting conditions are given by;
, this approach provides guidance in selecting priors if information matching is applied. The resulting conditions are given by;
![]() (27)
(27)
where ![]() are constants. If symmetry or independence is useful,
are constants. If symmetry or independence is useful, ![]() can be assumed. With cross derivatives set equal to zero, multiparameter priors can be taken with the general form;
can be assumed. With cross derivatives set equal to zero, multiparameter priors can be taken with the general form;
![]() (28)
(28)
This rules out multivariate prior distributions with factors of ![]() that are higher order polynomials of
that are higher order polynomials of ![]() or transcendental functions such as
or transcendental functions such as
![]() (29)
(29)
or
![]() (30)
(30)
This approach to prior selection can be seen as imposing the log-concavity of the likelihood function, which yields a log-concave joint posterior density and risk averse behavior as the amount of information increases. Note that the approach given by reference priors [2] , also reflect the idea of selecting priors to maximize the amount learned, but typically averaged over the sample space. A formal Bayesian conditional perspective reflecting the observed data is maintained here.
7. Discussion
This paper reviews and develops links between several concepts; large sample likelihood, expected utility, risk aversion, posterior stability and aspects of prior selection. These are broadly defined concepts providing templates for the organization and study of behavior and how such behavior is modified in the light of information. In relation to the utility and expected utility aspect, it is information itself that is the consumed good of interest. In the context of a particular large sample model-data combination the Fisher Information and Cramer-Rao information bound are directly related to measures of expected utility based risk aversion.
In large samples the concavity of the log-likelihood of the asymptotic normal density allows for use of the likelihood function in relation to the concept of utility and expected utility. The Cramer Rao information bound is seen to have a large sample relationship in providing bounds on the elasticity of the posterior density and the Arrow-Pratt measure of risk aversion. The imposition of information similarity on the likelihood-posterior relationship provides direct application of the Fisher Information from a learning model perspective. It provides a class of information similar prior densities that emphasize likelihood as the source of model-data related information.
To summarize, the likelihood function is a key element in the processing of infor- mation through defined model-data constructs. This is true from various perspectives. The possible use of the large sample likelihood function as a utility function itself allows for the linking of concepts of risk aversion, as expressed by the Arrow-Pratt measure, with statistical information. As well, the implicit learning oriented focus of the Bayesian perspective, if focused on the properties of the large sample likelihood, leads to restrictions on the type of priors available when information from both Bayesian and frequentist perspectives directly reflect the Fisher information.