A BP Artificial Neural Network Model for Earthquake Magnitude Prediction in Himalayas, India ()
1. Introduction
Earthquakes (EQ) are one of the most destructive costly natural hazards faced by the nation in which they occur without an explicit warning and may cause serious injuries or loss of human lives as a result of damages and destroy a lot of properties and buildings or other rigid structures. The prediction of earthquakes remains one of the considerable importances for humanity and most frustrating issues in the Earth Sciences and independent forms of evidence may have been cited to predict the occurrence of major seismic events.
During the past several years a number of earthquake prediction researches were successfully implemented in the way of Theoretical, Mathematical, Computational and Statistical techniques. Recently, the authors presented a review of Earthquake prediction with various optimization techniques [1] .
Artificial intelligence, Artificial Neural Network, Fuzzy logic and expert systems have been increasingly used in various applications in the last 30 years: Engineering design, Image recognition [2] ; Prediction, Estimation, Pattern recognition, and optimization [3] ; Petroleum exploration and production; civil engineering, environmental and water resources engineering, traffic engineering, highway engineering, geotechnical engineering [4] ; Image classification [5] ; Fingerprint analysis [6] ; Software defect prediction [7] ; Breast cancer identification [8] ; Human action recognition, video surveillance to health-care [9] ; Video retrieval [10] ; Localization scheme of wireless sensor networks, military surveillance, environmental monitoring, robotics, domestics, animal tracking [11] ; Image recognition of plant diseases [12] ; Wind power forecasting [13] ; Design and analysis of antennas [14] ; Image recognition [15] ; Multimodal medical image fusion [16] ; Satellite data and GPS [17] ; water resources engineering [18] ; air traffic control [19] ; financial forecasting [20] ; earthquake prediction [21] - [23] .
2. Study Area
The collision between India and Eurasia around 50 Ma ago along the Indus-Tsangpo Suture Zone has subsequently resulted into the uplift of the Himalaya, the highest mountain belt in the world. The uplift has produced linear zones of deformation and resulted into crustal shortening along major regional boundary faults. These faults, from north to south known as the Main Central Thrust (MCT), Main Boundary Thrust (MBT) and the Himalayan Frontal Thrust (HFT) as a result large magnitude paleo- earthquakes have been reported due to the reactivation of some of these thrusts [24] .
Himalayas consists of a complete sequence of Paleozonic, Mesozonic and Tertiary rocks, it is considered on the seismically very active regions of the world. The Himalayan evolved as a consequence of collision and convergence of Indian plate with Tibetan plate and Burmese and Chinese plates also. The entire Himalayan belt is in the state of persistent compression due to continued convergence at a rate of ~50 mm/yr [25] . A part of this strain is accommodated in the form of recurrent seismic activity. The high level seismic activity is manifested by several major earthquakes during past century. Three great earthquakes (M > 8 on Richter scale) have struck the Himalayan region, e.g. 1905-Kangra earthquake, 1934-Bihar-Nepal earthquake, 1950-Assam earthquake, 2015 Kathmandu and were mostly confined to the Main Boundary Thrust and Himalayan Frontal Thrust zone of Himalaya. The spatial distribution of the earthquakes suggests that seismic activity is related to the tectonic framework of the region. Earthquake tremors have been monitored in Himalayan region and recorded Earthquakes, for various spatio-temporal mapping have been found subject to regional tectonics settings reported and major earthquakes recorded during 1505-2015.
3. Earthquake Data Analysis
3.1. Earthquake Data Sources and Acquisition Methodology
This region is characterized of high seismicity with intensity of 9 to 10 magnitude, or even more. The source catalogs for the database of our study have been compiled from several sources. The earthquake for the time period from 1887 to 2015 collected from the Global Hypocenter Database prepared by USGS (United States Geological Survey). Ten available catalogues (Data, Time, Latitude, Longitude, Depth, Maximum Magnitude, Minimum Magnitude, Standard Deviation, Number of Fields and regions). The PDE (preliminary determination of epicenters) data and IMD (Indian Meteorological Department)―Seismology Division data, for the time period from 1983 to 2015 are also used to update the database. The final catalogue consists of about 462 earthquakes [2013-2015] recorded in Himalayan regions. Magnitude range above the threshold ranges Mc ~ 2.5. Largest earthquakes (Ms ≥ 8.0) occur in the subduction zones and continental thrust zones. All earthquake magnitudes should be in the same magnitude scale and a specific time period. This database offers the opportunity to study the temporal and spatial occurrence of earthquakes.
3.2. Data Analysis and Computed Parameters
To carry out the magnitude prediction in the study area, the data source catalog collected during 2013-2016 through an annual. Studying the seismic activity of the world has been done extensively, several researches calculated different parameters of seismicity by using various methods. The empirical relationship between magnitude, frequency and energy of earthquake occurrences is well known as the Gutenberg-Richter (G-R) relationships. The historical earthquake catalog for the study area are divided into a number of pre-undefined time period such as every two events and its time difference between two events, events based on magnitude above 2.5, the input to the neural networks are eight computational parameters called seismicity input vectors. The Computational input vector parameters based on Gutenberg-Richter [26] .
b-value
Since Gutenberg and Richter (1944) [27] estimated the parameters a and b, the evaluation of the parameters have been frequently used in statistical calculation of seismicity. The parameter depends on the seismicity rate which varies greatly from regions to regions. The parameter b is related to properties of focal material and represents tectonic characteristics of a region The b-value is a measure of the relative number of small to large earthquakes that occur in a given area in a given time period. Many researchers estimated the b-value in the intraplate regions, locally, regionally and globally. The low b-value is a characteristic feature of the intraplate regions, except Asia, b-value changes from 0.90 to 2.1 at a corner magnitude Mc of 6.0 to 7.0. In particular, the b-value is the slope of the frequency-magnitude distribution [26] ; for the population of earthquakes. Which is the slope of the earthquake recurrence curve 0.69 in the Himalayas collision zone [28] [29] . The b-value determined in this study was calculated using the ZMAP algorithm [30] . Maximum-likelihood b-value were computed using the following equation
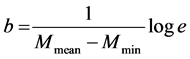 (1)
(1)
where Equation (1) provides the Mmean is the mean magnitude and Mmin the minimum magnitude of the given sample. The frequency-magnitude distribution [27] derives from the power-law relationship between the frequency of occurrence and the magnitude of earthquake (FMD), in the form:
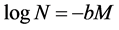 (2)
(2)
For a certain region and time interval, Equation (2) provides the cumulative number of earthquakes (N) having magnitude larger than M where a and b are positive, real constants. The parameter a describes the seismic activity Himalayan region a = 6.17 [28] . It is determined by the event rate and for a certain regions depends upon the volume and time window considered [31] .
Mmean: The average magnitude of the last two events (Mmean)
Energy E
Most calculations of the magnitude-energy relation depend directly or indirectly on the Equation (3) for a wave group from a point source [26] , (E in ergs)
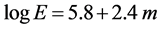 (3)
(3)
where: m magnitude Richter scale value.
Energy J
Seismic wave energy J (Markus bath & Hugo Benioff, 1958), The energy J (ergs) has been computed from the magnitude M from the Equation (4)
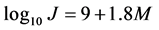 (4)
(4)
SD―Standard Deviation from seismic station.
C―The coefficient of variation of the meant time σ/µ where σ―SD/Mmean and µ― Mean Time in days (time period between two events).
η―Mean square deviation (σ2/n) where n―Number of earthquakes above Mmean between two events.
Soft computing techniques are used n order to reduce the aforementioned computational cost. In this work the application of Artificial Neural Networks (ANNs) is used for training and earthquake magnitude prediction in future also ANN is then used to predict future values due to different sets of random variables.
The multi-layer BP network design issues to be considered
Making the BP network design should be considered with the number of layers, the number of neurons in each layers of the network, the initial value and learning rate aspects.
1) The number of layers of the network
It has been proved that a Multi-layer BP network can achieved. Maximum number of layers can further reduce errors can improve accuracy but increasing training time, and reduction of error. Maximum number of neurons of the hidden layer, training is easier.
2) The number of hidden layer neurons
To improve the accuracy need maximum hidden layer and output layers with linear activation function.
3) The selection of the initial value of the right value
The back Back propagation network is a very powerful tool for constructing non- linear transfer function between several continuous valued inputs and the one or more continuous valued output.
4) Learning rate
A suitable learning rate for each specific network is present, but for more complex networks, the different parts of the error complex networks. In order to reduce training times to find the learning rate and training time.
5) The expected error select
The expected error value is obtained by comparing the minima, the hidden layer nodes. As a comparison of two different expected error of the network is trained, hidden layer of the neural network to achieve any continuous function approximation.
4. Modeling
4.1. The Back-Propagation Learning Algorithm
A multi-layer perceptron is a feed-forward neural network (ANN), consisting of a number of neurons linked together and attempts to create a desired relation in an input/ output set of learning patterns. A neural network consists of an input vector layers, more hidden layers and output vector layers. Each layer has its corresponding neurons weight connects. A single training pattern is an Equations (5)-(7) I/O vector of pairs of input-output values in the entire matrix of I/O training set. The neural network model is shown in Figure 1.
![]()
Figure 1. Neural network architecture that was used in modeling magnitude of earthquake.
The input xi, i = 1, 2, ∙∙∙, n which are received by the input layer are analogous to the electrical signal received by neurons in human brain. In the simplest model these input signals are multiplied by connection weights wp,ij and the effective input netp,j to neurons is the weighted sum of the inputs
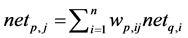 (5)
(5)
where wp,ij is the connecting weight of the layer p from the I neuron in the q (source) layer to the j neuron in the p (target) layer, netq,j is the output produced at the i neuron of the layer q and netq,j is the output produced at the j neuron in the layer p. Inputs xi correspond to netq,j for the input layer.
At the output layer the computed output(s), otherwise known as the observed output(s), are subtracted from the desired or target output(s) to give the error signal.
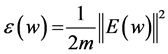 (6)
(6)
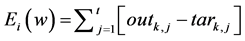 (7)
(7)
where m is the number of training pairs, tark, I and out k, I are the target and the observed output(s) for the node I in the output layer k, respectively. This type of ANN training is called supervised learning.
A learning algorithm tries to determine the weights, in order to achieve the right response for each input vector applied to the network. The numerical minimization algorithms used for the training generate a sequence of weights matrices through an iterative procedure. To apply an algorithmic operation A. a starting value of the weight matrix w(0) Equation (8) is needed, while the iteration formula can be written as follows:
 (8)
(8)
All numerical methods applied in ANNs are based on the above formula. The changing part of the algorithm is further decomposed into two parts as Equation (9)
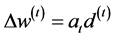 (9)
(9)
where d(t) is a desired search direction of the move and at the step size in that direction.
The training methods can be divided into two categories. Algorithms that use global knowledge of the state of the entire network, such as the direction of the overall weight update vector, which are referred to as global techniques. In contrast local adaptation strategies are based on weight specific information only such as the temporal behavior of the partial derivative of the weight. The local approach is more closely related to the ANN concept of distributed processing in which computations can be made independent to each other. Furthermore, it appears that for many applications local strategies achieve faster and reliable prediction than global techniques despite the fact that they use less information [32] .
4.2. Example Application
As an example, the ANN attempted to predict the next magnitude’s intensity ranges from 4 and above in Himalayan regions and number of days for remains for next events. Himalayan region is defined by the working group on Himalaya Earthquake probabilities as an area between geographic coordinates 20.5N to 47.6N latitudes and 54E to 97.07E longitudes. Historical seismic data recorded in Himalayan region dating back to 1983 is archived by IMD (Indian Meteorological Department)―Seismology Division data, for the time period from 1983 to 2015 are also used to update the database also some data collected form USGS (United States Geological Survey) and is available for free download through the center’s website at http://earthquake.usgs.gov/earthquakes/eqarchives/significant/ and Indian Meteorolo- gical Department―Seismology Division is used to define input classes and test the BP ANN model developed in this research.
The historical earthquake total 326 + 135 = 461 events magnitude above 2.5 recorded of Himalayan region between 1st January 2013 and 29th December 2015.
The historical earthquake total 326 events magnitude above 2.5 recorded of Himalayan region between 1st January 2013 and 29th December 2014 as shown in Table 2. Fifteen output groups are defined based on upper and lower magnitude levels. First group comprised of earthquake of magnitude less than 3.0, second group comprised of earthquake of magnitude above 3.0 to 3.4, third group comprised of earthquake of magnitude above 3.4 to 3.8, fourth group comprised of earthquake of magnitude above 3.8 to 4.2, fifth group comprised of earthquake of magnitude above 4.2 to 4.6, sixth group comprised of earthquake of magnitude above 4.6 to 5.0, seventh group comprised of earthquake of magnitude above 5.0 to 5.4, eighth group comprised of earthquake of magnitude above 5.4 to 5.8, ninth group comprised of earthquake of magnitude above 5.8 to 6.2, tenth group comprised of earthquake of magnitude above 6.2 to 6.6, eleventh group comprised of earthquake of magnitude above 6.6 to 7.0, twelfth group comprised of earthquake of magnitude above 7.0 to 7.4, thirteenth group comprised of earthquake of magnitude above 7.4 to 7.8, fourteenth group comprised of earthquake of magnitude above 7.8 to 8.2, fifteenth group comprised of earthquake of magnitude above 8.2 to 8.6 where each group has a magnitude range of 0.4 Richter.
Table 2 shows the Input classes in the training catalogue for the Himalayan regions, the output magnitude range, and number of training data available for each instances [2013-2014] and [2015].
A nine-element vector of seismicity parameters is computed for each time period forming 326 training input vectors (training catalogue/dataset). The training data is divided into nine input classes depending on the magnitude. Input magnitude of the training dataset, the corresponding output classes, the number of training input vector available in each class are shown in Table 1. As explained above. If we want to increase more accurate output Magnitude accuracy rates we have to increase number of years for training, show that we can get more inclusive class values. Therefore it can be concluded from Table 1, the BP ANN is most successive in classifying events into M < 3, M = 3.0 - 3.4, M = 3.4 - 3.8, M = 3.8 - 4.2, M = 4.2 - 4.6, M = 4.6 - 5.0 and M = 5.0 - 5.4 ranges and may not have much success in classifying events into the M = 5.4 - 5.8, M = 6.2 - 6.6, M = 6.6 - 7.0, M = 7.0 - 7.4, M = 7.4 - 7.8, M = 7.8 - 8.2 and M = 8.2 - 8.6 ranges. The training dataset showing the nine-element input vectors and the corresponding output Magnitude for the event based mean values between 1st January 2013 and 29th December 2014 are shown in Table 2.
For testing, the BP ANN is used to predict the earthquake magnitude range of next events. It is mean average values calculated for every two events in between 1st January 2013 and 29th December 2014 time periods by computed nine-computed parameters test input vectors for each time period. BP ANN training is repeated for each input
![]()
Table 1. Architecture and training parameters of the proposed BPANN.
vectors and the magnitude range of classes for 326 time periods. After each test run, the input vector is added to the training dataset. Therefore the number of training input vectors available for the test iteration is 921 and it is increase by one with each iteration thereafter.
5. Prediction Verification and Result
Computational and Statistical Analysis
The computed values of BP ANN trained and predicted values compared with originally seismometer recorded values in Himalayan regions for 2015. Table 3 shows the Error percentage of successful and unsuccessful prediction rations and Figure 2 shows the comparison chart.
The suitability of the network in predicting small, moderate and large earthquakes is discussed in the following paragraphs:
a) Prediction of small earthquake (Magnitude 3 or less). Originally seismometer records the magnitude 3 - 3.4. The BP ANN predicted 2 - 2.2. It is mention the success in percentage 66.66%
b) Prediction of Moderate earthquakes (Magnitude 3 and above but less than 5.8). Seismometer records the magnitude 4 but BP ANN predicted Magnitude 3 ~ 5 success in percentage 75% - 125%, Seismometer records the magnitude 4.0 ~ 5.8 but BP ANN forecasted Magnitude 4.0 - 4.5 it is less than the originally recorded values.
c) Prediction of large earthquakes (Magnitude 5.8 and above). There is no much more
![]()
Table 3. Comparison between computed values of BPANN predicted values and originally recorded values for 2015.
![]()
Figure 2. Earthquake prediction and comparison [2013 and 2014 with 2015].
data for training the BP ANN, so that the network cannot produced good results for magnitude above 5.8.
6. Conclusions
Earthquake forecasting has become an emerging science; simple earthquake forecasting has been adapted in early ages using simple observations. It is often implicitly assumed that “large” earthquakes, which save the peoples life and potential damages, can be forecasted. It would be a major achievement, from a scientific point of view. Earthquake prediction refers to the specification of the expected magnitude, geographic location and time of occurrence of a future event with sufficient precision that the ultimate success of a prediction can be evaluated. We presented a BP Artificial Neural Network which is a very effective model of nonlinear modeling, analysis and predicting earthquake magnitude in the Himalayan region. It has many advantages such as simple learning, memory and self-adaptation, but very complex multidimensional curve, in which multi-local extremism points exist,
The results show that the BP Artificial Neural Network model provides higher prediction accuracy for the Magnitude ranges 3 - 5. BP ANN model is better than the other proposed models for forecasting Earthquakes below Magnitude ranges 5. This is due to the fact that the BP ANN is capable to capture non-linear relationship compared with statistical methods and other proposed methods.
Acknowledgements
The authors wish to thank the Director, Wadia Institute of Himalayan Geology, Dehradun for providing old and new versions of Himalayan Geology journals; the authors would like to thank two anonymous reviewers for their comprehensive and valuable comments that improved the paper considerable.