Efficiency of Some Estimators for a Generalized Poisson Autoregressive Process of Order 1 ()
Received 27 May 2016; accepted 20 August 2016; published 23 August 2016

1. Introduction
Time series are used to model various phenomena measured over time. Successive observations are often correlated, since they may depend on some common external factors, but which remain unknown to the analyst. In this case, autoregressive models will be useful to model this dependence.
In some situations, we might be interested in the number of events which occur during a certain period of time. Such observations will necessarily be non-negative and integer-valued. Models which have been used for sequences of dependent discrete random variables include the Poisson autoregressive process of order 1, denoted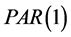 , introduced by Al-Osh and Alzaid [2] and the generalized Poisson autoregressive process of order 1, denoted
, introduced by Al-Osh and Alzaid [2] and the generalized Poisson autoregressive process of order 1, denoted  (see Alzaid and Al-Osh [1] ). The
(see Alzaid and Al-Osh [1] ). The 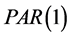 process, a stationary process with Poisson marginal distributions, is a special case of the
process, a stationary process with Poisson marginal distributions, is a special case of the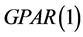 .
.
The paper is organized as follows. In Section 2, for completeness, we review some properties of the generalized Poisson autoregressive process of order 1. In Section 3, we derive the expressions for the moments estimators, the quasi-likelihood and the maximum likelihood estimators of the 3 parameters of the . These methods have appeared in the literature (see Al-Nachawati, Alwasel and Alzaid [3] for the quasilike- lihood and moments method and Brännäs [4] for likelihood methods). However, asymptotic properties such as efficiencies of these methods are not discussed in those papers. In this paper (Sections 4 and 5), we study properties of these estimators such as bias and asymptotic efficiency. The last section reanalyzes a real-data example which can be modelled with a
. These methods have appeared in the literature (see Al-Nachawati, Alwasel and Alzaid [3] for the quasilike- lihood and moments method and Brännäs [4] for likelihood methods). However, asymptotic properties such as efficiencies of these methods are not discussed in those papers. In this paper (Sections 4 and 5), we study properties of these estimators such as bias and asymptotic efficiency. The last section reanalyzes a real-data example which can be modelled with a  process, where testing is discussed.
process, where testing is discussed.
We hope that with this study, practitioners will have more information to select one estimation method versus another one and to perform tests concerning values of the parameters.
2 GPAR(1) Process
To define the  process, we need first to review the generalized Poisson and the quasi-binomial distributions.
process, we need first to review the generalized Poisson and the quasi-binomial distributions.
A random variable X has a generalized Poisson distribution with parameters  and
and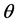 , denoted
, denoted , if its probability mass function (pmf) is defined by
, if its probability mass function (pmf) is defined by

where ,
,  and
and  is the greatest positive integer for which
is the greatest positive integer for which  when
when ![]() is negative. Note that, for
is negative. Note that, for![]() , the random variable X becomes a Poisson (
, the random variable X becomes a Poisson (![]() ) distribution. In this paper, we will restrict ourselves to the case where
) distribution. In this paper, we will restrict ourselves to the case where![]() .
.
Consul [5] has shown that the expected value ![]() and variance
and variance ![]() of X are given, when
of X are given, when![]() , by
, by
![]()
so that, for positive values of![]() , we have overdispersion (i.e.
, we have overdispersion (i.e.![]() ).
).
The sum ![]() of two independent random variables X and Y with
of two independent random variables X and Y with ![]() and
and ![]() distributions, also has a GP distribution, with parameters
distributions, also has a GP distribution, with parameters![]() . Ambagaspitiya and Balakrishnan [6] have derived the recurrence formula for the probability function of the compound generalized Poisson distribution, used in risk theory.
. Ambagaspitiya and Balakrishnan [6] have derived the recurrence formula for the probability function of the compound generalized Poisson distribution, used in risk theory.
A non-negative integer-valued random variable X has a quasi-binomial distribution, denoted![]() , if its pmf is given by
, if its pmf is given by
![]()
where ![]() and
and ![]() is such that
is such that![]() . Its mean, equal to
. Its mean, equal to![]() , is independent of the parameter
, is independent of the parameter![]() .
.
The following proposition, proved in Alzaid and Al-Osh [1] , shows the relation between the QB and GP distributions.
Proposition 1: If X and ![]() are two independent random variables with
are two independent random variables with ![]() and
and ![]() distributions, then
distributions, then ![]() follows a
follows a ![]() distribution.
distribution.
The ![]() process generalizes the
process generalizes the ![]() process introduced by Al-Osh and Alzaid [2] . The
process introduced by Al-Osh and Alzaid [2] . The ![]() model, where
model, where![]() , has been used to model time series in various fields, for example in insurance for short-term workers' compensation because of work-related injuries (Freeland and McCabe [7] ) and in medicine for the incidence of infectious diseases (Cardinal, Roy and Lambert [8] ).
, has been used to model time series in various fields, for example in insurance for short-term workers' compensation because of work-related injuries (Freeland and McCabe [7] ) and in medicine for the incidence of infectious diseases (Cardinal, Roy and Lambert [8] ).
In practice, many integer-valued series will often exhibit overdispersion, (i.e. ![]() is greater than
is greater than![]() ). The
). The ![]() model would therefore not be appropriate for those time series. In cases where the extra variation can be explained in a deterministic way, adding regressors would be adequate (see Freeland and McCabe [7] ), but where the extra variation is of a stochastic nature, the
model would therefore not be appropriate for those time series. In cases where the extra variation can be explained in a deterministic way, adding regressors would be adequate (see Freeland and McCabe [7] ), but where the extra variation is of a stochastic nature, the ![]() model could be used for modelling overdispersed time series.
model could be used for modelling overdispersed time series.
The ![]() model, introduced by Alzaid and Al-Osh [1] , is defined as
model, introduced by Alzaid and Al-Osh [1] , is defined as
![]() (1)
(1)
where
1) ![]() is a sequence of iid random variables with a
is a sequence of iid random variables with a ![]() distribution.
distribution.
2) ![]() is a sequence of iid random variables with a
is a sequence of iid random variables with a ![]() distribution.
distribution.
3) These two sequences are independent of each other.
4) ![]() has a
has a ![]() distribution independent of
distribution independent of ![]() and
and![]() .
.
Proposition 2: The ![]() process
process ![]() has a GP marginal distribution.
has a GP marginal distribution.
Proof: See Alzaid and Al-Osh [1] . The ![]() process is obtained from the
process is obtained from the ![]() and
and ![]() distributions, and not from the
distributions, and not from the ![]() and
and ![]() distributions, as stated in Al- Nachawati et al. [3] .
distributions, as stated in Al- Nachawati et al. [3] .
The autocorrelation function (acf) of the ![]() process
process ![]() is equal to
is equal to
![]()
The acf of this process is the same as that of an ![]() process except that it is always non-negative, since
process except that it is always non-negative, since![]() . The partial autocorrelation function (pacf) of the
. The partial autocorrelation function (pacf) of the ![]() process is equal to
process is equal to
![]()
The sample acf and pacf will be useful to identify the ![]() model from an observed time series.
model from an observed time series.
3. Estimation of the Parameters
Estimating the parameters in a ![]() process will present some challenges, since the conditional distribution of
process will present some challenges, since the conditional distribution of![]() , given
, given![]() , is the convolution of a
, is the convolution of a ![]() and a
and a ![]() distri- bution.
distri- bution.
In this section, we will review three estimation methods for the parameter vector ![]() of the
of the ![]() process, the methods of moments, quasi-likelihood and conditional maximum likelihood. These methods have been proposed in the literature, see for example, Al-Nachawati et al. [3] or Brännäs [4] . However, less emphasis is placed on their asymptotic properties, such as efficiency. In Section 4, we study the bias of these estimators, and in Section 5 their efficiency.
process, the methods of moments, quasi-likelihood and conditional maximum likelihood. These methods have been proposed in the literature, see for example, Al-Nachawati et al. [3] or Brännäs [4] . However, less emphasis is placed on their asymptotic properties, such as efficiency. In Section 4, we study the bias of these estimators, and in Section 5 their efficiency.
3.1. Method of Moments or Yule-Walker
The first autocovariance of the ![]() process is equal to
process is equal to
![]() (2)
(2)
By taking the expected value of both sides of the equation given in (1), we find ![]() Since
Since
![]()
we obtain ![]() (3)
(3)
We also know that
![]() (4)
(4)
From the observations![]() , we estimate the means
, we estimate the means![]() ,
, ![]() , the variance Var
, the variance Var ![]() and the autocovariance
and the autocovariance ![]() by their sample analogs
by their sample analogs
![]()
![]()
![]()
![]()
Solving the system of Equations (2), (3), (4) with![]() ,
, ![]() ,
, ![]() and
and ![]() replaced by their sample values, we obtain the moments estimators
replaced by their sample values, we obtain the moments estimators ![]() of parameter vector
of parameter vector![]() ,
,
![]()
![]()
![]()
where![]() .
.
We have corrected here misprints in the formulas for the moment estimators of the parameters ![]() and
and ![]() given by Al-Nachawati et al. [3] .
given by Al-Nachawati et al. [3] .
3.2. Quasi-Likelihood Method
This method, proposed initially by Whittle [9] , replaces the true likelihood by the one which assumes that the observations come from a normal distribution with the same conditional mean and variance. Al-Nachawati et al. [3] obtained the quasi-likelihood estimators ![]() by maximizing
by maximizing
![]()
where ![]() and
and ![]() are given by
are given by
![]()
and
![]()
We have used the expression in Shenton [10] for the formula of the variance of a quasi-binomial distribution, which is a bit different from the one given in Al-Nachawati et al. [3] . Since the ![]() process is restricted to non-negative integers and therefore not symmetrical, one might suspect that the estimators are less efficient than the maximum likelihood estimators, which is indeed the case (see Section 5 for numerical results).
process is restricted to non-negative integers and therefore not symmetrical, one might suspect that the estimators are less efficient than the maximum likelihood estimators, which is indeed the case (see Section 5 for numerical results).
3.3. Conditional Maximum Likelihood Method
To obtain the conditional maximum likelihood estimators (MLE’s)![]() , we need the conditional distribution of
, we need the conditional distribution of![]() , which is the convolution of a
, which is the convolution of a ![]() distribution and a
distribution and a ![]() distribution. Given the observations
distribution. Given the observations![]() , we have to maximize the function
, we have to maximize the function
![]()
We will work with the loglikelihood function ![]() equal to
equal to![]() , which will have to be maximized numerically to obtain the MLE
, which will have to be maximized numerically to obtain the MLE![]() .
.
Under normal regularity conditions, using likelihood theory (see Gouriéroux and Monfort [11] or Hamilton [12] ), the vector ![]() has an asymptotic multinormal distribution, i.e.
has an asymptotic multinormal distribution, i.e.
![]()
where ![]() denotes convergence in law, 0 is the vector of zeros of dimension 3, and
denotes convergence in law, 0 is the vector of zeros of dimension 3, and
![]() is Fisher’s expected information matrix, of dimension
is Fisher’s expected information matrix, of dimension![]() .
.
4. Bias of Estimators
With simulations, we will study the bias of the moments estimators and the MLE’s. Setting the values of the 3 parameters to those in Table 1, two series of 50 and 200 observations were generated from model (1) in C++. This experiment was repeated 200 times.
For each series, the moments estimators were calculated, as well as their average, and the bias. The conditional MLE's were calculated using the iterative Downhill Simplex method (see Press, Teukolsky, Vetterling and Flannery [13] ), which does not require the calculation of the derivatives of the function to be maximized. As initial values, we used the moments estimators. The results of the simulations appear in Figures 1-3.
From Figures 1-3, we see that the bias of the MLE’s is smaller than that of the moments estimators, and that
![]()
Figure 1. Bias of the estimators of p (Moment: ----- MLE: - - -).
![]()
Figure 2. Bias of the estimators of l (Moment: ----- MLE: - - -).
![]()
Figure 3. Bias of the estimators of q (Moment: ----- MLE: - - -).
it decreases when the size of the series increases. Figure 1 shows that the bias of ![]() is much smaller than that of
is much smaller than that of![]() , except when
, except when ![]() and
and ![]() where they are almost equal to 0. The bias of the two estimators is negative. In Figure 2, we see that the bias of
where they are almost equal to 0. The bias of the two estimators is negative. In Figure 2, we see that the bias of ![]() and
and ![]() is close to 0 when
is close to 0 when![]() ; as
; as ![]() increases,
increases, ![]() and
and ![]() are more biased. In all cases, the bias of the estimator of
are more biased. In all cases, the bias of the estimator of ![]() is positive. The bias of the estimator of
is positive. The bias of the estimator of ![]() behaves like that of p (Figure 3); for the two estimation methods, it is similar for
behaves like that of p (Figure 3); for the two estimation methods, it is similar for ![]() or 10.
or 10.
Since the moments estimators and the conditional MLE’s are almost unbiased for large n, we study their asymptotic efficiency in the next section.
5. Asymptotic Efficiency of Estimators
We will first discuss the techniques by which we can obtain the asymptotic variance-covariance matrix of the estimators under the three estimation methods. To study efficiencies, we calculate, in subsection 5.4, the ratios of the variances of the estimators and the ratio of the determinants of their variance-covariance matrix using observations simulated from a ![]() process for various values of the parameters. The results are summarized in Table 2 and Table 3 of this section.
process for various values of the parameters. The results are summarized in Table 2 and Table 3 of this section.
![]()
Table 2. Efficiency of moments estimators.
5.1. Method of Moments
By using an asymptotically equivalent factor of ![]() instead of
instead of ![]() in Equation (3), moments estimators
in Equation (3), moments estimators ![]() are given as solutions of the system of equations
are given as solutions of the system of equations
![]()
![]()
Table 3. Efficiency of quasi-likelihood estimators.
![]()
![]()
Let us define the functions
![]()
![]()
![]()
and the vector
![]()
The expected values![]() ,
, ![]() and
and ![]() are asymptotically equal to 0. Using a Taylor series expansion around
are asymptotically equal to 0. Using a Taylor series expansion around![]() , the true parameter value, we obtain
, the true parameter value, we obtain
![]() (5)
(5)
where![]() , with
, with ![]() denoting convergence in probability.
denoting convergence in probability.
Since ![]() is a solution of
is a solution of![]() , Equation (5) can rewritten as
, Equation (5) can rewritten as
![]()
or ![]()
Using Slutsky’s theorem, we find that
![]()
or ![]() (6)
(6)
where, with probability 1,
![]()
Matrix A evaluated at ![]() can be estimated by
can be estimated by
![]()
If ![]() and
and ![]() are unknown, they can be replaced by appropriate estimates. The variance-covariance matrix of Y is equal to
are unknown, they can be replaced by appropriate estimates. The variance-covariance matrix of Y is equal to
![]()
Let us consider the first element of this matrix:
![]()
since asymptotically ![]() (because
(because ![]() as
as![]() ). In practice, we truncate these expressions, since
). In practice, we truncate these expressions, since![]() , as
, as![]() . If we limit ourselves to a difference of
. If we limit ourselves to a difference of![]() , the last equality becomes
, the last equality becomes
![]()
Using the law of large numbers, we can estimate this last term by
![]()
The other elements of the matrix can be estimated in the same way.
5.2. Quasi-Likelihood Method
To determine the quasi-likelihood estimator![]() , we have to maximize
, we have to maximize
![]() (7)
(7)
Let us define the quasi-score vector
![]()
From Hamilton [12] , using quasi-likelihood theory, we conclude that
![]() (8)
(8)
where with probability 1, D and S are limits in probability matrices. They are defined as
![]()
and
![]()
evaluated at![]() , the true parameter. We can obtain estimates for
, the true parameter. We can obtain estimates for ![]() and
and![]() , where matrix
, where matrix ![]() is defined as
is defined as
![]()
and ![]() is the finite version of S evaluated at
is the finite version of S evaluated at![]() ; the elements of
; the elements of ![]() are evaluated numerically using expression (7). Packages such as MATHEMATICA can handle these derivatives calculations numerically. Consequently, the variance-covariance matrix of
are evaluated numerically using expression (7). Packages such as MATHEMATICA can handle these derivatives calculations numerically. Consequently, the variance-covariance matrix of ![]() can be estimated by
can be estimated by![]() .
.
5.3. Conditional Maximum Likelihood
Using the true loglikelihood function from section 4.3, we define the score vector
![]()
From Hamilton [12] , using likelihood theory, we find that
![]() (9)
(9)
where matrix S is defined analogously as in the previous section, but with a different loglikelihood function.
5.4. Numerical Comparisons
Table 2 and Table 4 give the estimate of the asymptotic efficiency of the moment and the quasi-likelihood estimators compared to the MLE, calculated from 20,000 observations (10 series of 2000 observations) gene- rated from a ![]() process with various parameter values.
process with various parameter values.
Comparing Table 2 and Table 3, the quasi-likelihood estimator for p has a smaller variance than the moments estimator; for![]() , it depends on the values of the parameters. The moments estimator of
, it depends on the values of the parameters. The moments estimator of ![]() has a smaller variance than the quasi-likelihood estimator, except when
has a smaller variance than the quasi-likelihood estimator, except when![]() , where
, where ![]() is better than
is better than![]() .
.
The estimated determinant of the variance-covariance matrix of ![]() using the average of the determinants is always smaller than that of
using the average of the determinants is always smaller than that of ![]() and
and ![]() (last column of Table 2 and Table 3). The MLE is more efficient than the moment or the quasi-likelihood estimator, and the moment estimator more efficient than the quasi-likelihood estimator, in general.
(last column of Table 2 and Table 3). The MLE is more efficient than the moment or the quasi-likelihood estimator, and the moment estimator more efficient than the quasi-likelihood estimator, in general.
6. Applications: Number of Computer Breakdowns
In this section, we perform some tests on a real time series presented by Al-Nachawati et al. [3] on the number of weekly computer breakdowns for 128 consecutive weeks. This series is overdispersed, since its mean and variance are equal to 4.016 and 14.504. In Figure 4, the acf function is seen to decrease with the lag, while the pacf is high for lag 1 and low thereafter; a ![]() model could therefore be appropriate for this series. We use the
model could therefore be appropriate for this series. We use the ![]() model in the analysis.
model in the analysis.
Since the MLE was shown to be the best asymptotic estimator in the previous section, the parameters were estimated with this method; the estimates appear in Table 4, with the estimated variance-covariance matrix.
With the estimated variance-covariance matrices based on expressions (6), (8) and (9) of Section 5, Wald tests can be performed quite easily depending on which estimator has been chosen.
For example, to test ![]() using
using![]() , the quasilikelihood estimator, the statistic can be based on the
, the quasilikelihood estimator, the statistic can be based on the
statistic![]() , where
, where ![]() is an estimate of the variance of
is an estimate of the variance of![]() , which can be obtained from
, which can be obtained from
the corresponding diagonal element of![]() . Since
. Since ![]() is asymptotically
is asymptotically![]() , we reject
, we reject ![]() at level
at level ![]() if
if ![]() is greater than
is greater than ![]()
To test![]() , the test statistic can be based on
, the test statistic can be based on
![]()
which follows a ![]() distribution asymptotically. It is expected that the more efficient the estimator is, the
distribution asymptotically. It is expected that the more efficient the estimator is, the
more powerful the test will be.
With the estimated parameters, we can test the ![]() model versus the simpler
model versus the simpler ![]() model. Since the conditional MLE
model. Since the conditional MLE ![]() equals 0.471, with a variance of 0.0026, performing the test
equals 0.471, with a variance of 0.0026, performing the test ![]() vs
vs ![]() gives
gives![]() . This leads us to reject
. This leads us to reject ![]() and to conclude that the
and to conclude that the ![]() model is more appropriate: there is overdispersion in the observations.
model is more appropriate: there is overdispersion in the observations.
Acknowledgements
The authors gratefully acknowledge the financial support of the Natural Sciences and Engineering Research Council of Canada and of the Fonds pour la Contribution à la Recherche du Québec.