Ensuring Quality of Random Numbers from TRNG: Design and Evaluation of Post-Processing Using Genetic Algorithm ()
Received 19 February 2016; accepted 5 April 2016; published 8 April 2016

1. Introduction
As we move towards the Big data and the exascale era, with the Internet and many communication devices becoming more prevalent, cyber-security is becoming increasingly important. Many real world computational science applications (such as finance, medicine, and social networks among others) produce tremendous amount of data that not only require a larger storage capacity such as Cloud, but also secure methods for preserving the data from harmful threats.
In recent years, different solution paths had been explored such as new security models [1] - [3] , analytical tools [4] , prevention strategies [5] , keys and random numbers management systems [6] and more relevant to this study, random number generation schemes [7] . Traditionally, the backbone solution for many of the security issues is the use of cryptographic algorithms. A cryptographic algorithm is used for securing private communi- cation over untrusted environments. These algorithms are usually key-based and depend on the strength of random numbers used to generate the keys [8] .
Over the past few years, with its increasing popularity and wide coverage, Cloud computing has become an important and frequent solution for storage of Big data. There are many challenges to address, one being the new security challenges. Among these new challenges, the combination of managing and storing the keys that provide access to the client’s encrypted data can lead to multiple hazardous situations [9] . A poor key manage- ment scheme can expose the system to unauthorized access, data breaches and lack of control caused by having multiple clients sharing the same resource. It can also expose scenarios where network-based cross-client attacks can occurr over shared network infrastructure components. In the same way, other scenarios include losing control over the network infrastructure, either real or virtualized.
The poor key management problem is exacerbated by two important factors: the accidental key replication and/or the weak random number generation [9] . The first factor is due to a weak security policy. It occurs during the cloning of a virtual machine as part of an on-demand service, and in consequence, the cloned images could contain information that is not intended to be public. The second factor is introduced when the entropy level found in the host is insufficient, which compromises the statistical properties of the random numbers. These situations are created by either the virtualization of hardware that delivers a lower entropy level than is expected, or by having too many clients on the same host exhausting the entropy that the host can deliver.
In general, random numbers are generated using a pseudo-random number generator (PRNG), a true-random number generator (TRNG) or a combination of both [10] . A PRNG is an algorithm that in combination with a given seed creates a deterministic sequence with the characteristic of being forward and backward unpredictable. The sequence is forward unpredictable, when the history of output numbers do not lead to predict the next output value; if the seed used to create the sequence is unknown, consecutive output sequence numbers cannot backtrack to the unknown seed, creating a sequence that is also backward unpredictable. The PRNGs main drawback is being predictable if the seed and the algorithm are known. This is dangerous and vulnerable to attacks. Despite this, the National Institute of Standards and Technology (NIST) [11] has tried to standardize the selection method for the generator, as well as, suggesting a list of approved PRNGs for cryptographic algorithms [12] .
On the contrary, true random generators provide stronger solution. These types of generators use non- deterministic or unpredictable sources to generate random numbers, like thermal, avalanche or atmospheric noise. The random number generation process consists of two phases: extraction and post-processing. In the extraction phase, a non-deterministic source is sampled to extract the random numbers. This sampled values may not be completely unbiased or consistent. Therefore, in the post-processing phase, the extracted random numbers undergo a strenuous process that modifies the numbers to satisfy the designed statistical properties - in other words, ensure that the numbers are close to be independent and identically distributed (i.i.d.) with uniform distribution [13] . Although the research on PRNGs has been exhaustively covered, the generation of seeds based on a TRNG has been overlooked [11] . Given its unpredictability of the random numbers, gaming machines and strong cryptographic applications apply a scheme where a TRNGs seeds a PRNG. In this paper, we focus on the TRNG post-processing.
In the literature, there are multiple types of sources, design and extraction techniques [14] [15] for TRNGs, making it a complicated case for standardization [11] . In some cases, the design uses a thermal noise circuit that is amplified and sampled [14] . In [16] the design focuses on sampling the jitters of a phase-locked loop circuit found on ASIC based technologies. In [17] the authors exploit the features found in digital circuits, like the meta-stable state of flip-flop circuits. As well, researchers have also explored the use of random sources from audio and video signals [18] .
Intel introduced the Intel random number generator [19] , relying on the unpredictability of the thermal noise to modulate the frequency of a clock signal as a source of random binary digits. The design also included a post- processing stage, involving a von Neumann corrector to statistically balance the outputs from data with a bias. Intel re-engineered [20] its own true random number generator in 2011, providing a solution to security threats on the Ivy Bridge processor. In this new design, the noise circuit relied on the thermal noise and the meta-stable state of a R/S Latch, where the source of random binary digits is located at the output of the R/S Latch. One of the main features of this new design is the on-line health tests or On-line Self Test Entropy (OSTE), that empirically test the frequency of binary patterns within a certain range of test against intentional attacks. Using these tests, the random numbers with only the healthy sequences are appended to an entropy pool, from which random numbers are later picked up. Another source for TRNGs are the ones based on race conditions between CPU threads while updating shared variables. This creates a non-deterministic behavior on the value of the updated variable. Colesa et al. [15] took advantage of this phenomena. Their study suggests that the execution environment’s irregularities, the number of cache misses, the number of instructions executed in the pipeline and the imprecision of the hardware clock used for the timer interrupts are the main contributors to the random behavior observed in the shared variable. They claim that their design satisfies 90% of the standard NIST tests [11] .
In [21] , we developed a TRNG that generates high quality random numbers by exploiting the natural sources of randomness on the NVIDIA GPU video card such as race conditions during concurrent memory access. The digitized noise signal generated from non-deterministic sources passes through a post-processing algorithm, to ensure the random numbers follow an uniform distribution. Unlike Intel, which invokes the post-processing stage in hardware, our algorithm implements the post-processing step in software, providing flexibility and the capacity to scale the complexity of the algorithm design. The modularity of the design can be adapted to any noise source.
In this paper, the post-processing algorithm proposed on [22] for TRNGs is further explored focusing on a lighter version optimized for quality and performance, ensuring the generation of random numbers meet wide sense stationarity (w.s.s.). In the post-processing step, we apply an evolutionary based genetic algorithm (GA) heuristic that exploits the inherent parallelism avoiding all data dependencies to produce uniform random numbers that satisfies the same statistical properties over time, thereby enforcing stationarity. We ensure that the quality of the numbers generated from the genetic algorithm is within a specified level of error. As well a detailed evaluation using the statistical battery test from L’Ecuyers TestU01 [23] is provided.
The rest of this paper is organized as follows. In Section 2, we give a brief theoretical introduction about the properties of random numbers, its metrics and algorithms. In Section 3, we present our TRNG framework. Section 4 presents the post-processing phase which includes the genetic algorithm. Section 6 presents the results of the evaluations stated in Section 5. Finally in Section 7, we conclude our work and suggest future work.
2. Properties of Random Numbers
Random numbers are a type of numbers that when chosen, its selection process reproduces the characteristics of an underlying distribution. Conceptually, a random number is generated from a random process with the intention to be nearly indistinguishable from a random behavior [13] . Nevertheless, the study of computer- generated random numbers is a fascinating area of research that has been addressed by multiple researchers [13] [24] - [26] . Formally, we can define a random number as an outcome of a random variable X, that takes on different values, 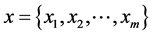 with a probability distribution
with a probability distribution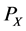 , usually assumed to be an uniform
, usually assumed to be an uniform
distribution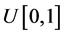 . Once S is defined as a sample space or domain, S can be used to map X to its range x. Then, the i-th random number,
. Once S is defined as a sample space or domain, S can be used to map X to its range x. Then, the i-th random number, 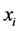 , can be expressed by
, can be expressed by 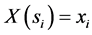 where
where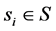 . The
. The 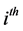 index can represent the sample index on a sequence, and it can also be associated to a time index in the generation of this random numbers. For example, as in Figure 1(a), we can observe multiple realizations of X, where the i-th realization of X,
index can represent the sample index on a sequence, and it can also be associated to a time index in the generation of this random numbers. For example, as in Figure 1(a), we can observe multiple realizations of X, where the i-th realization of X, 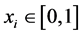 is mapped by
is mapped by 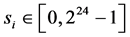 representing a sample between 0 and 1 at the maximum resolution
representing a sample between 0 and 1 at the maximum resolution
using a IEEE 754 floating point format. In general, a random number should meet two basic conditions to be considered random: have an uniform distribution and be unpredictable.
2.1. The Uniform Distribution of Random Numbers
In order to observe the distribution of x, the probability mass function (p.m.f.), or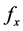 , is a useful tool that relies
, is a useful tool that relies
![]() (a)
(a)![]() (b)
(b)
Figure 1. A sample of 1024 random numbers (a); and the patterns between contiguous random numbers (b).
on three properties. The p.m.f. is always positive, its summation of all the p.m.f. is 1.0, and the p.m.f. can be used to calculate the probability of an event by adding all the elements that conform that event. Under ideal conditions, x should follow an uniform distribution, as in p.m.f. in Figure 2(a). But in reality, for some random number generators this is difficult to achieve, a typical response is shown in Figure 2(d).
2.2. The Correlation of Random Numbers
As well, in ideal conditions all elements of x should be uncorrelated. This can be observed as non-geometric patterns between pairs of contiguous realizations, like between 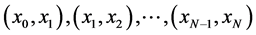 as in Figure 1(b). Similarly, the uncorrelation of x can be proven by observing the shape of the autocorrelation function.
as in Figure 1(b). Similarly, the uncorrelation of x can be proven by observing the shape of the autocorrelation function.
The autocorrelation is a mathematical tool that calculates the correlation between the elements on a sequence of numbers, like x. It is useful at identifying non-randomness in a sequence and its adequate time series model
[27] . The autocorrelation function, 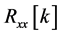 , is defined by the expectation between two elements in x separated by a k lag under the assumption that all elements of x are equi-distant [28] .
, is defined by the expectation between two elements in x separated by a k lag under the assumption that all elements of x are equi-distant [28] .
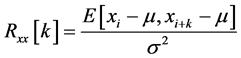 (1)
(1)
where ![]() is the lagged interval, N is the cardinality of x,
is the lagged interval, N is the cardinality of x, ![]() and
and ![]() is the mean and standard deviation of x. As well,
is the mean and standard deviation of x. As well, ![]() can be calculated by replacing
can be calculated by replacing ![]() and
and ![]() for the sample mean
for the sample mean ![]() and the sample variance,
and the sample variance,
![]() (2)
(2)
When there is no lag or![]() , the autocorrelation reaches it’s maximum value,
, the autocorrelation reaches it’s maximum value,![]() . Differently, as
. Differently, as ![]() the autocorrelation is always
the autocorrelation is always![]() . Since the denominator in (2) normalizes the output, the
. Since the denominator in (2) normalizes the output, the
![]()
Figure 2. Probability mass function (a), autocorrelation (b) and power spectral density (c) of x random numbers in an ideal case scenario. Probability mass function (d); autocorrelation (e) and power spectral density (f) of x random numbers from a computer generated algorithm.
autocorrelation function is bounded to![]() . In an ideal case, the autocorrelation of a random sequence will
. In an ideal case, the autocorrelation of a random sequence will
result in an impulse shape, as shown in Figure 2(b), showing that random numbers are only correlated at![]() ,
,
and uncorrelated at any other lag,![]() . In reality, computer-generated random numbers hold small traces of correlation, having a close to zero response when
. In reality, computer-generated random numbers hold small traces of correlation, having a close to zero response when ![]() as shown in Figure 2(e).
as shown in Figure 2(e).
The execution of the autocorrelation function from (2) is a computational expensive task that requires a total of ![]() floating point operations and
floating point operations and ![]() memory accesses. There are many other efficient algorithms, among them, the method based on the Wiener-Khinchin theorem. This method uses two Fast Fourier Transforms (FFT) to calculate the autocorrelation and in combination with a single pass variance calculation,
memory accesses. There are many other efficient algorithms, among them, the method based on the Wiener-Khinchin theorem. This method uses two Fast Fourier Transforms (FFT) to calculate the autocorrelation and in combination with a single pass variance calculation,
like the Welford method [29] [30] ; it takes ![]() floating point operations and
floating point operations and ![]() memory accesses to calculate it. The algorithm includes the following operations,
memory accesses to calculate it. The algorithm includes the following operations,
![]() (3)
(3)
![]() (4)
(4)
where in (3), ![]() represent the complex conjugate operation of the
represent the complex conjugate operation of the![]() , the
, the ![]() operation involves calculating the Fast Fourier Transform of x after removing
operation involves calculating the Fast Fourier Transform of x after removing ![]() and zero padded to
and zero padded to ![]() in size. Then,
in size. Then, ![]() is the power spectral density of x in terms of frequency f, while in (4),
is the power spectral density of x in terms of frequency f, while in (4), ![]() is the inverse FFT
is the inverse FFT
operation. As well in Equation (3), the variance, ![]() , is the Welford method implementation based on the following equations,
, is the Welford method implementation based on the following equations,
![]() (5)
(5)
![]() (6)
(6)
![]() (7)
(7)
This implementation works well against losing precision due to having catastrophic cancellation, even though it is slightly slower than the naive method,
![]() (8)
(8)
2.3. The Spectral Density of Random Numbers
Another useful tool to review the uncorrelation of random numbers is the power spectral density. It relies on the fact that through Fourier analysis, x can be decomposed into frequency components where it describes the energy distribution per unit of frequency, a distinctive signature between sequences of numbers. The relation between the autocorrelation and the power spectral density can be established with the Wiener-Khinchin theorem, which works under the assumption of x is the output of a stationary process. The stationarity of random numbers will be addressed in the following subsection. For the moment, consider that the power spectral density function is formally be defined as
![]() (9)
(9)
where f is the frequencies at which the power spectral density is evaluated, and i is the imaginary unit. Its
implementation can follow the proposed algorithm in (3), which only involves ![]() floating point operations and
floating point operations and ![]() memory accesses. Under ideal conditions, the power spectral
memory accesses. Under ideal conditions, the power spectral
density of random numbers has a step function response at 1, as shown in Figure 2(c). But in reality, due to the small peaks found at ![]() in the autocorrelation of Figure 2(e), the power spectral density spreads around 1 as in Figure 2(f).
in the autocorrelation of Figure 2(e), the power spectral density spreads around 1 as in Figure 2(f).
Another property between the autocorrelation and the power spectral density is the distribution of the peaks found at ![]() in the autocorrelation. For simplicity, these peaks will be referred to as
in the autocorrelation. For simplicity, these peaks will be referred to as![]() . Then, the distribution of
. Then, the distribution of ![]() can be fitted to a normal distribution, for example in Figure 2(e),
can be fitted to a normal distribution, for example in Figure 2(e), ![]() . In other words,
. In other words, ![]() follows a normal distribution
follows a normal distribution![]() . This is
. This is
![]() (10)
(10)
where r is the magnitude of elements in![]() . Then, when mapping the
. Then, when mapping the ![]() from the autocorrelation towards the power spectral density, we can analytically find the shape of the points distribution around the ideal step function in the power spectral density, Figure 2(c), which happens to also follow a normal distribution [22] . This is done by using the characteristic function. The characteristic function of
from the autocorrelation towards the power spectral density, we can analytically find the shape of the points distribution around the ideal step function in the power spectral density, Figure 2(c), which happens to also follow a normal distribution [22] . This is done by using the characteristic function. The characteristic function of ![]() is denoted by
is denoted by![]() , and it is the Fourier transform of
, and it is the Fourier transform of![]() . This is,
. This is,
![]() (11)
(11)
where t is the frequency at which ![]() is evaluated. In most cases, the characteristic function is used to describe a probabilistic distribution behavior over time. In our case, it is a helpful tool to describe that standard deviation of
is evaluated. In most cases, the characteristic function is used to describe a probabilistic distribution behavior over time. In our case, it is a helpful tool to describe that standard deviation of ![]() will always be smaller than the standard deviation from
will always be smaller than the standard deviation from![]() . In
. In![]() , the variance or
, the variance or ![]() is used as a denominator limiting the growth of the exponential to a small range; while in
is used as a denominator limiting the growth of the exponential to a small range; while in![]() , the variance is used to magnify the growth of the exponential, making it more sensible to changes. This means that
, the variance is used to magnify the growth of the exponential, making it more sensible to changes. This means that ![]() from (3) is more sensitive to variations from 1, than
from (3) is more sensitive to variations from 1, than ![]() from (4) or (2) to the changes against an impulse shape. Besides
from (4) or (2) to the changes against an impulse shape. Besides
the sensitivity of the metric, the computational intensity, ![]() , of each algorithm can express the relation between the number of floating point operations(
, of each algorithm can express the relation between the number of floating point operations(![]() ) and the memory access operations (
) and the memory access operations (![]() ) as in [31] .
) as in [31] .
Also, the computational intensity can be evaluated in terms of the data size, as shown in Figure 3(a). The autocorrelation from (2) shows to be data intensive in its majority, and only after the data size passes 210, the number of floating points operations grow closely to the number of memory access operations, Figure 3(b) and Figure 3(c), where both keep a ratio of 1. However, the other two algorithms are compute intensive and follow a similar trend, since the power spectral density is necessary to compute the autocorrelation. As shown in Figure 3(a), the computational intensity of the FFT-based autocorrelation from (4) and the power spectral density from (3) is higher, but the number of floating point operations is smaller than the autocorrelation, Figure 3(b). Therefore the power spectral density is suited for long data segments where the computing architecture is ideal for massive floating point operations.
2.4. The Stationarity of Random Numbers
In order to keep the consistency of the random numbers definition among realizations, the statistical charac- teristics also need to be constant. As discussed previously, the stationarity of random number generation is key concept in this. Therefore, a stationary process is a process characterized by keeping its p.m.f. constant for any
displacement over the sample indexes, this is![]() . This condition is also known as strict or
. This condition is also known as strict or
strong-sense stationarity (s.s.s.). As well, process which are s.s.s. are also i.i.d. Unfortunately, in most cases s.s.s. is not achievable, therefore a less restrictive condition is used, wide-sense stationarity (w.s.s.) or covariance stationarity. A w.s.s. process requires only the mean and the autocorrelation to be constant over all sample indexes, presenting a more relaxed constraint.
According to Basu et al. [32] , one way to confirm the w.s.s. of a process is to compare the power spectral density among all segments of the output. Considering that x is the output, we will extend the notation of x, where ![]() is the j-th segment, so
is the j-th segment, so![]() . Then,
. Then,
![]() (12)
(12)
where, ![]() and
and ![]() represent two different segments of x. Given that x has M segments, comparing the m segment to every other
represent two different segments of x. Given that x has M segments, comparing the m segment to every other ![]() segments is computationally expensive. Therefore, we propose another strategy that relaxes this constraint, and reduces the computational burden from [22] . Taking advantage that
segments is computationally expensive. Therefore, we propose another strategy that relaxes this constraint, and reduces the computational burden from [22] . Taking advantage that ![]() has a
has a
![]()
Figure 3. Comparison of the autocorrelation, FFT-based autocorrelation and power spectral density algorithms analyzing (a) the computational intensity; (b) floating point operations and (c) memory access operation in terms of the data size N.
normal distribution, we can introduce a user-specified standard deviation error,![]() . Then, the segment will be ensured to be close to
. Then, the segment will be ensured to be close to ![]() from being w.s.s., such that
from being w.s.s., such that
![]() (13)
(13)
The details on the algorithm and how (13) becomes an essential metric will be discussed on Section 4.
3. The Architecture of a TRNG
In general, there are three phases [11] [33] that are fundamental in the TRNG architecture, Figure 4:
3.1. The digitized noise source/extraction: This phase is composed of a noise source and a digitizer that periodically samples and outputs the digitized analog signal (DAS) random numbers. In this work we exploit the natural sources of randomness of the Intel DRNG available on Ivy Bridge Processors [34] , the values are being sampled from the /dev/random over a linux kernel.
3.2. The post-processing phase: This phase transforms the DAS random numbers from the previous phase, into internal random numbers by satisfying the given statistical properties of the distribution. In our case, we propose the post processing phase, Figure 4, to be divided into two blocks, histogram specification and stationarity enforcement, as previously suggested on [21] [22] . The histogram specification block maps the output of step 3.1, or DAS numbers, to the specified output distribution, in our case an uniform distribution. This block was studied in detail in [21] and will not be discussed further in this paper.
3.3. The buffer phase: This is usually optional and it represents the final phase. The buffered internal random numbers are outputted as the external random numbers.
In Figure 4, the output of the histogram specification block is referred to as semi-internal (s.i.) random numbers. The s.i. random numbers are then inputted to the stationarity enforcement block which further improves the generated random numbers. The main purpose of this block is to eliminate any periodicity traces found in s.i random numbers.
The stationarity enforcement block uses a genetic algorithm (GA) to permute the output (s.i. random numbers) from the histogram equalization block. It is within this block where we ensure the random numbers to meet w.s.s. by iterating with GA until the random numbers meet w.s.s with a user-defined error level or standard deviation,![]() . Further details on the stationarity enforcement block will be discussed in Section 4.
. Further details on the stationarity enforcement block will be discussed in Section 4.
4. Proposed Algorithm: The Stationary Enforcement Block
Figure 5 illustrates the stationarity enforcement block. In this block, the s.i. random numbers, x, obtained from the histogram specification block are the input to the stationarity enforcement block in Figure 4. The s.i. random numbers may have small traces of periodicity not corrected by the histogram specification block, however, the histogram specification block guarantees x to follow an uniform distribution. Figures 6(a)-(f) show an example of DAS random numbers and semi-random numbers, including its p.m.f. and autocorrelation.
![]()
Figure 5. The architecture of the stationarity enforcement block.
![]()
Figure 6. DAS Random numbers (a); its probabilistic mass function (b) and autocorrelation (c); Semi-internal random numbers (d); its probabilistic mass function (e) and autocorrelation (f).
In Figure 5, each block is considered as one phase (or step) in the proposed iterative algorithm.
4.1. Sampling semi-internal random numbers: As previously defined, x exhibits![]() , an uniform distribu- tion. x will be consider to have a size of N. And
, an uniform distribu- tion. x will be consider to have a size of N. And ![]() will be the j-th segment of size M, that is sampled from x, such that the concatenation of all
will be the j-th segment of size M, that is sampled from x, such that the concatenation of all ![]() form x.
form x.
4.2. Shuffling random numbers with GA: In this stage, ![]() is passed through a genetic algorithm (GA) to alter its sequence order, which in consequence will have a major impact on the power spectral density. We explain our parallel GA implementation in Algorithm 1, which relies on the data non-dependencies to avoid synchronization as much as possible. Given the nature of GA, parallelism can be exploited at a coarse grain level. In this algorithm, we focus on removing the data dependencies, so a large number of threads can be launch without a synchronization constraint, allowing a finer-grain parallelism.
is passed through a genetic algorithm (GA) to alter its sequence order, which in consequence will have a major impact on the power spectral density. We explain our parallel GA implementation in Algorithm 1, which relies on the data non-dependencies to avoid synchronization as much as possible. Given the nature of GA, parallelism can be exploited at a coarse grain level. In this algorithm, we focus on removing the data dependencies, so a large number of threads can be launch without a synchronization constraint, allowing a finer-grain parallelism.
A traditional implementation of permutations-based GA involves generating the parents population of random numbers, followed by calculating the permutation indexes. For simplicity, the parents populations are sorted so the crossover operations are consistent among parents. A drawback of this is the need of unsorting the random numbers before evaluating them. Sorting, calculating the permutation indexes and unsorting them can take from
![]() operations at its best, and in its worst case
operations at its best, and in its worst case ![]() operations. On the other hand,
operations. On the other hand,
our implementation involves generating the populations of permutation indexes representing the parents. This approach avoids sharing values between parents, instead, it only shares the indexes transferring the order pattern to the children. This approach only involves M operations.
The idea behind this algorithm is presented in Algorithm 1. The sequence order or indexes will be considered as a chromosome solution. As well, we introduce the idea of having an external population that migrates part of its genetic content to the pool, avoiding stagnation. Since, its parallel implementation takes advantage of the data independence, every thread holds a unique id, ![]() , and keeps updating a shared array,
, and keeps updating a shared array, ![]() , in which only one memory position is accessed by a thread. In the following, we will explain all the processes that are used in Algorithm 1.
, in which only one memory position is accessed by a thread. In the following, we will explain all the processes that are used in Algorithm 1.
- Selection: This procedure selects the pool of permutation indexes. At this stage, the intention is to sample and select a group of permutation indexes that will be later used on the mating process inside the GA. The selec-
![]()
tion procedure is illustrated in Algorithm 2. We implement the Fisher-Yates shuffle algorithm due to its uniformity among picking a random permutation and its generation speed [30] . So given that n is the number of vectors and M is the length of a vector, this algorithm will return a pool of permutation indexes, a.
- Evaluation: This process is focused on evaluating a pool of permutation indexes based on calculating the standard deviation of the power spectral density from Equation (3), as is detailed in Algorithm 3.
- Cross Over: This process is focused on the cross over operation. The Order 1 cross over is a simple permutation based crossover that connects one group of indexes from one parent with the remaining indexes of the other parent. The process is showed in detail in Algorithm 4.
- Mutation: This process is focused on the mutation operation. The exchange mutation, as in Algorithm 5 is a simple technique that only 5% of the times it selects randomly two indexes and swaps their positions.
- Replacement: This process is dedicated to applying elitism by selecting the best sets of indexes based on their fitness values [35] [36] . It also updates the pool of parents with the best sets possible. This process takes on consideration the pool of children and the pool of externals, which have a key purpose for escaping local minimas or stagnation over the fitness function. The replacement process is described further detail in Algori- thm 6.
![]()
![]()
![]()
![]()
![]()
- Termination condition: The GA exits when the fitness is![]() . If the condition is successful, the algorithm proceeds to update
. If the condition is successful, the algorithm proceeds to update![]() , and in consequence any other thread running will stop by the
, and in consequence any other thread running will stop by the
end of its iteration as shown in 1 at line 6; then the algorithm returns the best sequence of random numbers found, ![]() or the answer for the j-th segment,
or the answer for the j-th segment,![]() . Otherwise, if the condition is unsuccessful the algorithm loops back to the cross over stage on the GA, line 7.
. Otherwise, if the condition is unsuccessful the algorithm loops back to the cross over stage on the GA, line 7.
4.3-4.5. Handling the output buffer: In Figure 5, the output of the GA in 4.2, ![]() , is pushed into the buffer y. Then if the buffer is not full yet, it will loop back the algorithm to sample the semi-internal random numbers at step 4.1. Otherwise y is pushed out as the internal random numbers.
, is pushed into the buffer y. Then if the buffer is not full yet, it will loop back the algorithm to sample the semi-internal random numbers at step 4.1. Otherwise y is pushed out as the internal random numbers.
5. Evaluation Methodology
In this section, we introduce a group of tests to show two aspects: first, the characteristics of the random number generation aided by the GA post-processing; and second, the strengths and weaknesses of the algorithm against the SmallCrush battery test [23] when changing the segment size . The results of these tests are presented in Section 6.
5.1. Characteristics of a GA post-processing stage: In this evaluation, we follow the m segment of random numbers analyzing step by step the change on![]() , its autocorrelation or
, its autocorrelation or ![]() from Equation (4), its power spectral density or
from Equation (4), its power spectral density or ![]() from (3) and its distribution described by its probability mass function or
from (3) and its distribution described by its probability mass function or![]() . The evaluation is iterated over a loop from step 6 - 12 in Algorithm 1 or generation, until the standard deviation of the power spectral density, or
. The evaluation is iterated over a loop from step 6 - 12 in Algorithm 1 or generation, until the standard deviation of the power spectral density, or![]() , is smaller than the user specified quality level,
, is smaller than the user specified quality level,![]() .
.
Having ![]() with
with ![]() samples, the algorithm is evaluated on its convergence capability given an error level (target) of
samples, the algorithm is evaluated on its convergence capability given an error level (target) of![]() . The parents, children and external populations size are set to
. The parents, children and external populations size are set to ![]() each. With the intention of explaining the behavior of the algorithm, we present a snapshot at three different generations; at the first generation or
each. With the intention of explaining the behavior of the algorithm, we present a snapshot at three different generations; at the first generation or![]() , in the middle or
, in the middle or ![]() and then in the last generation or
and then in the last generation or![]() , which will correspond with the output.
, which will correspond with the output.
For the GA parameters, the mutation ratio was set to 0.05% or 5% and the elitism was applied at the replacement stage to all individuals, letting survive only the best fitted individuals, which at the next generation will be considered as the parents pool.
5.2. SmallCrush: This evaluation is intended to highlight the weakness and strengths of the post-processing. It evaluates a vast group of configurations as shown in Table 1. The evaluations are done considering ![]() with
with ![]() samples, an error level (target) of
samples, an error level (target) of![]() . The parents, children and external populations size are set to
. The parents, children and external populations size are set to ![]() each. SmallCrush is a battery test that forms part of the statistical package TestU01 [23] . This a modern test package that includes most available test packages, surpassing by flexibility and extension popular ones like DIEHARD [37] and NIST [38] . As a standard, TestU01 uses statistical testing where the test outcome or p-value, fails if it is outside of the interval
each. SmallCrush is a battery test that forms part of the statistical package TestU01 [23] . This a modern test package that includes most available test packages, surpassing by flexibility and extension popular ones like DIEHARD [37] and NIST [38] . As a standard, TestU01 uses statistical testing where the test outcome or p-value, fails if it is outside of the interval![]() . In essence SmallCrush consist of 10 tests: the birthday spacing test [39] , the collision test, the gap test, the simplified poker test, the coupon collector test, the maximum-of-t test [30] , a weight distribution test proposed by Matsumoto and Kurita [40] , the rank of a random binary matrix test [39] , two tests of independence between the Hamming weights of successive blocks of bits [41] , and various tests based on random walk over the set of integers [23] .
. In essence SmallCrush consist of 10 tests: the birthday spacing test [39] , the collision test, the gap test, the simplified poker test, the coupon collector test, the maximum-of-t test [30] , a weight distribution test proposed by Matsumoto and Kurita [40] , the rank of a random binary matrix test [39] , two tests of independence between the Hamming weights of successive blocks of bits [41] , and various tests based on random walk over the set of integers [23] .
- The Birthday Spacing Test. The birthday spacing test checks the separation between numbers by mapping them to points in a cube. It checks that the number of collisions between their the spacing follows a Poisson distribution.
- The Collision Test. This test checks for n-dimensional uniformity, by checking the number of collisions per subdivision of the interval ![]() is uniformly distributed.
is uniformly distributed.
- The Gap Test. This test checks for the number of times that random number within ![]() fall outside of a expected interval. It applies chi-square testing between the observed and expected number of observations.
fall outside of a expected interval. It applies chi-square testing between the observed and expected number of observations.
- The Simplified Poker Test. This test checks for the number of different integers that are generated, it applies chi-square testing between the observed and expected number of observations.
- The Coupon Collector Test. This test checks over a group of random number integers for integers without collision, unique numbers, it applies chi-square testing between the observed and expected number of observations among the group of random numbers.
- The Maximum-of-t Test. This test checks for the number of times that the maximum random number within ![]() follows an exponential distribution via chi-square and Anderson-Darling test.
follows an exponential distribution via chi-square and Anderson-Darling test.
- The Weight Distribution Test. This test takes a group of uniform distributions; then it computes a binomial distribution and it gets compared via chi-square against the expected distribution.
- The Rank of a Random Binary Matrix Test. This test generate a binary matrix with uniform random numbers and then it calculates the rank of the matrix, or the number of linearly independent rows. Then, the probability distribution is compared to a known distribution via chi-square.
- The Independence Test between Hamming Weights of successive blocks. This involves two test that check for independence among Hamming Weights. The first test considers only the most significant bits of random numbers in a block and its corresponding Hamming Weight, then the Hamming Weights are arrange in successive pairs that later are count for the number of possibilities and compared against expected values via a chi-square test. The second test, considers mapping the counting from the first test into a 2-dimensional plane, where it is segmented into 4 blocks that its values are related to an expected value. Therefore, via a chi-square test the observed quantities can be compared to the expected values.
- The Random Walk Test. This test performs a random walk over integers, having an equal probability to move to right or left during the walk. So a group of statistics and the distribution that its position at the end of the test, both, are compared against their theoretical positions via a chi-square test.
![]()
Table 1. Small crush test configurations.
6. Results
In this section we present the results according to the evaluation methodology presented in Section 5. The results are presented in the following.
1. Results from the Characteristics of a GA post-processing stage:
As observed on Figure 7, the standard deviation of the power spectral density, or![]() , always tends to decrease as the algorithm goes forward on the generations. This behavior is expected. It is caused by the elitism implementation on Algorithm 1, and in the replacement method in Algorithm 6. The elitism ensures to either decrease or stagnate
, always tends to decrease as the algorithm goes forward on the generations. This behavior is expected. It is caused by the elitism implementation on Algorithm 1, and in the replacement method in Algorithm 6. The elitism ensures to either decrease or stagnate![]() , keeping only the best individuals available for the next generation.
, keeping only the best individuals available for the next generation.
In Figure 7 in a didactic manner, we selected three points to compare the progress on the distribution of the power spectral density. Its respective shape on the autocorrelation and the shape of the probability mass function and the points distribution pattern. In Figure 8 at generation![]() , the random numbers show some traces of periodicity, that can be seen on the peaks with a lag different than 0 on the autocorrelation at Figure 8(c). This is also shown on the power spectral density, Figure 8(d), as points that overshoot more than 5.0. These random numbers, at generation 0, are already of an outstanding good quality,
, the random numbers show some traces of periodicity, that can be seen on the peaks with a lag different than 0 on the autocorrelation at Figure 8(c). This is also shown on the power spectral density, Figure 8(d), as points that overshoot more than 5.0. These random numbers, at generation 0, are already of an outstanding good quality, ![]() , but as shown in Figure 8(c) and Figure 8(d) there is still room for improvement. Nevertheless, due to the fact that we only manipulate the order and not the magnitudes of those numbers, the probability mass function remains uniform across all generations.
, but as shown in Figure 8(c) and Figure 8(d) there is still room for improvement. Nevertheless, due to the fact that we only manipulate the order and not the magnitudes of those numbers, the probability mass function remains uniform across all generations.
In Figure 9(d) at generation![]() , the overshoots on the power spectral density converge to less than 5.0, still with traces of periodicity on the autocorrelation, in Figure 9(c), but closer to the solution. At this
, the overshoots on the power spectral density converge to less than 5.0, still with traces of periodicity on the autocorrelation, in Figure 9(c), but closer to the solution. At this
![]()
Figure 7. Standard deviation of the Power spectral density plotted against the change on generations.
![]()
Figure 8. (a) Random numbers at generation 0; (b) its probability mass function; (c) the autocorrelation; (d) the power spectral density.
![]()
Figure 9. (a) Random numbers at generation 300; (b) its probability mass function; (c) the autocorrelation; (d) the power spectral density.
generation with![]() , the distribution pattern of the points in Figure 9(a) is sparser than the one in Figure 8(a).
, the distribution pattern of the points in Figure 9(a) is sparser than the one in Figure 8(a).
The algorithm converges until generation![]() , where the power spectral density is concentrated in its majority below 3.0 with a
, where the power spectral density is concentrated in its majority below 3.0 with a![]() , this can be reviewed on Figure 10(d). As well, the improve-
, this can be reviewed on Figure 10(d). As well, the improve-
ment on the power spectral density is reflected on the autocorrelation as closer appearance of an impulse shape, Figure 10(c). But the overall benefit of the algorithm can be observed on Figure 10(a), where the points are spread covering the majority of the space, with a less visible agglomerates or darker spots as in Figure 9(a) and Figure 8(a).
As we have reviewed, the underlining idea of the Algorithm 1 is to benefit from the interactions of the pools of parents, children, and externals. To review in more detail these interactions, we look at the effects of those distribution in the following two examples.
It is well known, that one of the major drawbacks of elitism is the reduction of genetic content over the population which perpetuates the stagnation of the fitness function. But as well, elitism is characterized for a smooth fitness function. So in order to compensate for the lack of genetic content the external pool is introduced. In Figure 11 over an example, we can observe the distributions of the children pool scores overlapping the external pool scores in its majority. At each iteration, the minimum among the two distribution is selected as the best, as it is described on Algorithm 6. Here, the external pool becomes another set of points over the solution space, uniformly distributed, meanwhile the children pool is distributed nearby the parents distribution, since it keeps traces of the permutation orders, described on Algorithm 2, Algorithm 4, and Algorithm 5.
In contrary to the example on Figure 11, we also present in another example, Figure 12, the effects of the
![]()
Figure 10. (a) Random numbers at generation 4779992, (b) its probability mass function, (c) the autocorrelation, (d) the power spectral density.
![]()
Figure 11. Standard deviation of the Power spectral density from the parents, children and external pool plotted against the change on generations.
![]()
Figure 12. Standard deviation of the Power spectral density from the parents and children pool without external pool plotted against the change on generations.
lack of an external pool. Here, the fitness function tends to stagnate for longer periods and also is noted that children will not impact ![]() as much as the case of Figure 11, since the sample of the solution space is smaller. Consequently, this evolves a lack of genetic diversity and the proliferation of dominant traits on the children observed along different generations as stagnation.
as much as the case of Figure 11, since the sample of the solution space is smaller. Consequently, this evolves a lack of genetic diversity and the proliferation of dominant traits on the children observed along different generations as stagnation.
Balancing between the two factors is beyond the scope of this paper, but a good inside on which variables contribute to modifying the fitness curve are the pool size and the children to external pool ratio.
2. Results from SmallCrush Test
In order to make easier the review of the results, given that there are 10 SmallCrush evaluations with the 3 different configurations on the numbers of processors and 7 different segment sizes, we present a coded color map highlighting the p-value in Figures 13-15. In a SmallCrush test, the test is passed only if all the 10 evaluations have a p-value within the range of![]() .
.
The first configuration is using 2 processors, where the coded color results are presented at different segment sizes. in Figure 13. The evaluation of SmallCrush in this configuration is close to pass the battery test but it fails only in a test, either Maximum-of-t test or the Random Walks. Independently of this, the battery test successfully passes all the tests when the segment size is 17408.
The second configuration is using 4 processors and the results are presented in Figure 14. In this configura- tion, all the test failed either at Maximum-of-t or the Random Walks, in a similar ways as in Figure 13. The results tend to fail exclusively on one the test only. But the only evaluation at which the failing test is close to passing is when the segment size is 17,408.
The third configurations uses only 8 processors, the results are shown in Figure 15. In a similar manner, the failed evaluations are exclusive of each other, between Maximum-of-t and Random Walks. But the only evaluation that passes has a segment size of 17,408.
Recapitulating the overall SmallCrush tests, the segment size plays a key role on the quality of the tests results. As well, only Maximum-of-t and Random Walks fail among different segment sizes and configurations with different number of processors. The Maximum-of-t test focus on extracting the maximum of a sample set of random values, while the maximums follow an exponential distribution. Therefore, failing Maximum-of-t is due to inherit statistical properties of nearly i.i.d. uniform distributions. This improves at certain segment sizes, cause it aligns with the sample set size of the Maximum-of-t test. The Random Walks rely on the properties found on Markov chains, where the probability of the current position depends on the previous, This means that failing Random Walks is due to a lack of consistency among continuous segments. This evaluation passes when the segment size fits the sampling size used over the random walk so this connecting property is satisfied.
![]()
Figure 13. SmallCrush results from TestU01 battery test using 2 processors.
![]()
Figure 14. SmallCrush results from TestU01 battery test using 4 processors.
![]()
Figure 15. SmallCrush results from TestU01 battery test using 8 processors.
So far, the segment size of 17,408 random numbers is one sub-optimal solution for centering the evaluations, it is almost independent of the number of processors. This condition seems to remain constant as the number of processors is increased, since passing the test is connected to the consistency of ![]() among segments which is aided by increasing the sampling size. This is benefited by the parallelism exposed on GA as in the Algorithm 1.
among segments which is aided by increasing the sampling size. This is benefited by the parallelism exposed on GA as in the Algorithm 1.
7. Conclusion
The use of a post-procesing stage for TRNGs using GA inteded for seed generation proves to satisfy the specified quality level within a desirable number of generations. We have presented the theoretical foundations that guarantee the algorithm convergence to a nearby point of![]() , as well as, the analysis of a GA approach aided to avoid stagnation and its respective complexity and performance justification. In addition, guidelines have been presented showing the influence different parameters that connect the statistical properties among the random numbers and the task decomposition from the post-processing algorithm. From this parameters, we observed that the segment size in the post-processing is key for centering the quality of the random numbers. For future work, we will extend the research towards meta-heuristics that target statistical properties connecting segments of random numbers.
, as well as, the analysis of a GA approach aided to avoid stagnation and its respective complexity and performance justification. In addition, guidelines have been presented showing the influence different parameters that connect the statistical properties among the random numbers and the task decomposition from the post-processing algorithm. From this parameters, we observed that the segment size in the post-processing is key for centering the quality of the random numbers. For future work, we will extend the research towards meta-heuristics that target statistical properties connecting segments of random numbers.