Statistical Significance of Geographic Heterogeneity Measures in Spatial Epidemiologic Studies ()
1. Introduction
Spatial epidemiology is an important methodology to deal with spatial-correlated issues in epidemiologic studies. One of its core tasks is to determine geographic variations and quantify the magnitude of geographic variations in diseases, health behaviors, or environmental exposures [1] . Some published epidemiologic studies inappropriately estimated the statistical significance of geographic heterogeneity measures of examined events.
The generalized linear mixed model and the Bayesian spatial hierarchical model are the most commonly applied to fit the data with a multilevel spatial structure. A geographic variation can be directly quantified as neighborhood-level variance 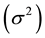 from parameter estimations of the multilevel model fitting. However, this variance has no meaningful unit and is difficult to interpret. Spatial statisticians and epidemiologists have developed two state-of-the-art heterogeneity measures, the median odds ratio (MOR, Equation (1)) [2] - [4] and the interquartile odds ratio (IqOR, Equation (2)) [5] , to facilitate the interpretation of geographic heterogeneity of an event.
from parameter estimations of the multilevel model fitting. However, this variance has no meaningful unit and is difficult to interpret. Spatial statisticians and epidemiologists have developed two state-of-the-art heterogeneity measures, the median odds ratio (MOR, Equation (1)) [2] - [4] and the interquartile odds ratio (IqOR, Equation (2)) [5] , to facilitate the interpretation of geographic heterogeneity of an event.
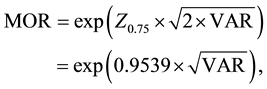 (1)
(1)
where 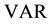 is the neighborhood-level variance, while
is the neighborhood-level variance, while 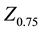 is the
is the 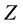 value of the Gaussian distribution at the 75th percentile (0.6745).
value of the Gaussian distribution at the 75th percentile (0.6745).
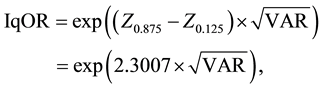 (2)
(2)
where 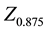 and
and 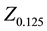 are the
are the 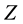 values of the Gaussian distribution at the 87.5th and 12.5th percentiles (1.1504, −1.1504), respectively.
values of the Gaussian distribution at the 87.5th and 12.5th percentiles (1.1504, −1.1504), respectively.
Both MOR and IqOR are derived from the variance and are always greater than or equal to one. Larger values of MOR and IqOR denote greater geographic variations in the event of interest. The MOR reflects the average difference of risk when comparing two subjects who have the same individual characteristics and are selected randomly from two different neighborhoods. The IqOR represents the average difference of risk when comparing the first quartile of study subjects residing in neighborhoods with the highest risk to the fourth quartile of study subjects residing in neighborhoods with the lowest risk [3] [5] . Similarly, the median rate ratio (MRR) and the interquartile rate ratio (IqRR) can be estimated in a prospective study, and the median hazards ratio (MHR) and the interquartile hazard ratio (IqHR) [6] are for time-to-event studies. To facilitate the explanation, the MOR and IqOR are applied in the following discussions.
2. Issues in Determining the Statistical Significance of Geographic Heterogeneity Measures
Geographic variations can be qualitatively assessed by using neighborhood-level variance estimation derived from a generalized linear mixed model. The modeling conducted by a commonly used statistical analysis package, such as the SAS, also gives a Z value and a corresponding P value based on an approximately normal distribution of the estimated parameter. With the standard error of the variance from the multilevel model fitting, a 95% CI is able to be computed mathematically. However, one cannot perform a generalized linear mixed analysis to estimate the statistical significance and 95% CIs of the MOR and IqOR because both MOR and IqOR are derived from the variance and do not have their own standard errors.
Alternatively, a Bayesian spatial hierarchical model with a Markov Chain Monte Carlo (MCMC) simulation has been used to estimate geographic heterogeneities. In this setting, the 95% Bayesian credible interval (CrI), defined by the 2.5th and 97.5th percentiles of Bayesian posterior distribution of the geographic heterogeneity measure, has been commonly reported.
In the estimation of a fixed effect of an exposure, its statistical significance can be identified if the 95% confidence/credible interval of its regression coefficient does not cross zero. However, this empirical method conflicts with the nature of geographic heterogeneity measures. Two unreasonable results are usually reported in the studies in which the 95% CI or CrI of geographic heterogeneity measures were used to determine their statistical significance. The 95% CI of the variance could cross zero based on an approximately normal distribution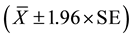 . This is unreasonable because the variance should always be greater than or equal to 0. In addition, the 2.5th percentile of the Bayesian posterior distribution of the variance is always greater than 0 and consequently the MOR and IqOR are always greater than one. This leads to the overestimation of geographic disparities.
. This is unreasonable because the variance should always be greater than or equal to 0. In addition, the 2.5th percentile of the Bayesian posterior distribution of the variance is always greater than 0 and consequently the MOR and IqOR are always greater than one. This leads to the overestimation of geographic disparities.
3. Example and Solution
3.1. Example
A simulation analysis was performed to illustrate the issues relevant to the statistical significance of spatial heterogeneity measures. It is assumed that a population of colorectal cancer (CRC) survivors come randomly from 100 neighborhoods, each with 5 - 20 patients, and that the probability of smoking for each patient is 0.2 - 0.5. A random simulation generated a dataset that included 1245 patients and 420 smokers. Multilevel logistic regression is applied to quantify small-area geographic variation in smoking behavior among these CRC patients (Equation (3)).
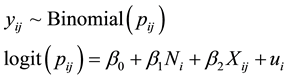 (3)
(3)
where 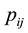 is the probability of smoking for patient
is the probability of smoking for patient 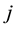 who resides in neighborhood
who resides in neighborhood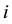 ;
; 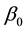 is the intercept;
is the intercept; 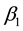 and
and ![]() are the fixed coefficients of neighborhood- and individual-level covariates, respectively;
are the fixed coefficients of neighborhood- and individual-level covariates, respectively; ![]() is characteristics of neighborhood i; and
is characteristics of neighborhood i; and ![]() is a vector of individual-level covariates;
is a vector of individual-level covariates; ![]() is the random effect between neighborhoods with a normal assumption:
is the random effect between neighborhoods with a normal assumption:![]() .
.
To simplify the explanation, an empty model without neighborhood- and individual-level covariates was fit to estimate the overall geographic heterogeneity of smoking among these CRC patients using the Bayesian hierarchical approach with a MCMC simulation in WinBUGS (Version 1.4.3, MRC, UK). After 50,000 iterations for the convergence, additional 50,000 iterations were run to obtain the posterior estimates of three spatial heterogeneity measures. Because the dataset was simulated randomly, the geographic variation in smoking was expected to be small.
Table 1 shows the Bayesian parameter estimates of three heterogeneity measures. Based on an approximately normal assumption, the 95% CIs of three geographic measures were computed as![]() . Alternatively, the 95% CrIs of three geographic measures were expressed as the range from their 2.5th to their 97.5th percentiles. However, the inconsistent results were observed when comparing the 95% CIs of the variance, MOR and IqOR to their 95% CrIs. The 95% CI of the variance crossed zero and the 95% CIs of both MOR and IqOR crossed 1, suggesting no significant geographic variation in smoking behavior among CRC survivors. In contrast, the 95% CrI of the variance was more than zero and the 95% CrIs of the MOR and IqOR were greater than one, suggesting a significant geographic variation in smoking behavior.
. Alternatively, the 95% CrIs of three geographic measures were expressed as the range from their 2.5th to their 97.5th percentiles. However, the inconsistent results were observed when comparing the 95% CIs of the variance, MOR and IqOR to their 95% CrIs. The 95% CI of the variance crossed zero and the 95% CIs of both MOR and IqOR crossed 1, suggesting no significant geographic variation in smoking behavior among CRC survivors. In contrast, the 95% CrI of the variance was more than zero and the 95% CrIs of the MOR and IqOR were greater than one, suggesting a significant geographic variation in smoking behavior.
3.2. Solution
Table 2 shows that, the variance is a non-negative measure, and MOR and IqOR are never less than one. The null hypothesis of the statistical test should be that the variance equals to zero and both MOR and IqOR equal to one, that is, there is no significant geographic variation in the event of interest. Meanwhile, the alternative hypothesis of the statistical test should be that the variance is greater than zero, and both MOR and IqOR are greater than one. Therefore, the statistical test is theoretically one-tailed, rather than two-tailed. The critical value for the significance level at 0.05 is 1.645 instead of 1.960. The statistical significance should be denoted directly using one-tailed (right-tailed) P value. One may not report the 95% CI or the interval between the 2.5th
![]()
Table 1. Three Bayesian estimates of three spatial heterogeneity measures in the simulated example.
*VAR, variance; †MOR, median odds ratio; ‡IqOR, interquartile odds ratio.
![]()
Table 2. Three spatial heterogeneity measures and their statistical hypotheses.
*VAR, variance; †MOR, median odds ratio; ‡IqOR, interquartile odds ratio.
and the 97.5th percentiles of Bayesian posterior distribution (95% CrI) of geographic heterogeneity measures to avoid the misinterpretation of geographic variations. In fact, a one-tailed P value for the variation/heterogeneity estimation has been given from a generalized linear mixed model fitting using common statistical analysis packages, such as the SAS. For the heterogeneity estimation from a Bayesian hierarchical model, one should compute the corresponding statistics, based on the prior distribution of the variance, to obtain their one-tailed P value to determine its statistical significance. In the simulated example, since the Z value for the variance is:![]() , the geographic variation in smoking among CRC survivors is not statistically significant using 1.645 as the cutoff for the significance level at 0.05.
, the geographic variation in smoking among CRC survivors is not statistically significant using 1.645 as the cutoff for the significance level at 0.05.
4. Discussions
The purpose of this study was to point out an inappropriate method that was used to determine the statistical significance of geographic heterogeneity measures. The simulated data suggested that empirically reporting of the 95% CI/CrI of geographic heterogeneity measures may lead to misunderstanding of the statistical significance of geographic variations of an event.
According to the nature of geographic heterogeneity measures, the statistical inference should be one-tailed (right-tailed). It is inappropriate to report a two-tailed 95% CI/CrI of a heterogeneity measure in spatial epidemiologic studies. It could mislead one in understanding the statistical significances of heterogeneity measures. In the studies using standard errors to obtain two-tailed P values or 95% CIs, geographic variations in the events may be underestimated because a two-tailed test is more conservative than a one-tailed test. In contrast, the studies using the interval between the 2.5th and the 97.5th percentiles of a Bayesian posterior distribution to obtain a 95% CrI may overestimate the statistical significance of geographic variation of the event because a Bayesian 95% CrI never crosses zero for the variance and one for both MOR and IqOR. The issue of statistical significance of geographic heterogeneity measures, which was discussed in this paper, is also extendible to a general multilevel study aiming to investigate the variation(s) in one or multiple event(s) of interest across a non-spatial higher level, such as healthcare providers or medical service facilities.
Acknowledgements
This work is supported partly by a Career Development Award (K07 CA178331) and a Research Award (R21 CA169807) funded by the National Cancer Institute, and a Research Award (R01 AA021492) funded by the National Institute of Alcohol Abuse and Alcoholism, both at the National Institutes of Health. I also thank the service provided by the Health Behavior, Communication and Outreach Core, which is supported by the National Cancer Institute Cancer Center Support grant (P30 CA091842) awarded to the Alvin J. Siteman Cancer Center at Barnes-Jewish Hospital and Washington University School of Medicine. I declare no conflict of interest.
Abbreviations and Acronyms
VAR: variance;
MOR: median odds ratio;
MRR: median rate ratio;
MHR: median hazard ratio;
IqOR: interquartile odds ratio;
IqRR: interquartile rate ratio;
IqHR: interquartile hazard ratio.