Next Words Prediction and Sentence Completion in Bangla Language Using GRU-Based RNN on N-Gram Language Model ()
1. Introduction
Next word prediction or sentence completion works when the user types a single word of a sentence and the program delivers one or more than one most feasible word. In communication in this modern world, we use different types of devices. When we use a device, we type many words to communicate. Sometimes the next word is predicted, but some other times it is not. In the second case, we have to type the next word, and then the prediction is recomputed. This is excessive to type many words and also takes more time to communicate. In this case, the next word prediction method will help to complete work easily because it will predict the next reasonable word. Here we can choose the highest predictable word instead of typing them. Guessing or finding which words are predicted to chase an order of words or part of the text is called word prediction [1] . The next word prediction method predicts new words by scrutinizing former word flow for concluding sentences with much exactness. This technique reduces the number of keystrokes required to misspell and type words. Predicting the next word can help elementary students such as researchers, programmers, or students avoid further spelling mistakes and speed up their typing. We use a big data set to train the N-gram model to predict the proper next words for accurately concluding a Bangla sentence. Physically, perceptively, or cognitively challenged, many people on the earth are slow typists. We studied many methods for the next word prediction and complete sentences in different languages like English, Arabic, and Urdu, but most of them are English texts. Some researchers are working with the Bangla language to predict the next words or complete the full sentence [2] . However, we try to make a new model with better accuracy in our work. This work is used GRU (Gated Recurrent Unit) on the N-gram language model.
The performance of this study outcome is:
• To complete sentences together including the most probable word forecast for the Bangla language.
• To use huge data to find better accurateness, which was not previously used for predicting Bengali words.
• To give more reasonable exactness than other ways that have been used.
• To give 92.64% average accuracy in using 5 models and also gives 99.78% best accuracy in the 5-gram model.
We have applied GRU-based RNN on an n-gram dataset to develop this proposed model. It can predict the next probable words of the input words. We deal with the sequential data, find the most predicted word, not only one word but also one or several words and finally find the predicted sentence in Bangla Language. A total of 310 million people all over the world speak Bangla as a first or second language. Among these, 150 M speakers are from Bangladesh, and another 95 M are from India. West Bengal, Tripura, Assam, and some Indian immigrants in the USA, UK, and the middle east are included as Bangla speakers. Bangla is also the state Language of Bangladesh, and it is an officially recognized language in India. But a huge amount of people is not satisfied when they write a text using Bangla on a device for sending their data. They face problems When they try to guess the next word and try to complete a sentence.
2. Related Works
Some recent studies have been done on text word prediction, and next letter prediction systems in the Bangla word language to find the higher probable words. Next word prediction helps to complete sentences which is very important for saving time. P. Burman et al. mentions in their work [3] that they applied Long short-term memory (LSTM) network with RNN (Recurrent Neural Network) to the Assamese to predict the next probable word. They got 72.10% exactness for Assamese transcripts and 88.20% for text. S. Bickel, P. Haider, and T. Scheffer [4] proposed a model using individual emails, climate information, cooking recipes, and call-center email data to predict the most preferred words while typing.
Haque et al. [5] used N-gram-based word prediction for the Bangla language, where the Bigram model performs politely, but the unigram model’s performance is evidently poor. But the exactness (63.5%) of the backoff model is very good. They have tested personal and professional email, cooking recipes, weather news and others. The Authors create an assessment metric and adapt N-gram models to the difficulty of predicting the subsequent words, given a primary text fragment. The N-gram has been used to reduce the prediction time while typing in the Kurdish language and the model was successful in prediction. This model has been developed in the R programming language. The maximum accuracy recorded in this model is 96.3% [6] . Al-Mubaid and Hisham have [7] proposed a new word prediction machine learning model. By supplying word predictors with highly discriminatory features that were selected using various feature selection procedures, this method presents the problem as a learning-classification task. The unique mix of the best performer in machine learning, SVM, with several characteristic selections, approaches MI, X2, and more is what makes this study unique in its approach to presenting this problem. The experimental findings clearly show that the approach is adequate for predicting the right phrases from limited contexts.
In this research [8] , M. Soam and S. Thakur studied NLP, and various deep learning techniques such as LSTM, and BiLSTM, and executed a comparative study. The accuracy acquired using BiLSTM and LSTM are 66.1% and 58.27% respectively. Ambulgekar et al. [9] used Recurrent Neural Networks (RNN) for next words prediction and their model comprehends 40 letters and anticipates impending top 10 words which will be executed utilizing TensorFlow. In this research [10] , A. Rianti and S. Widodo used the LSTM model to complete the prediction with 200 epochs. The outcome displayed that it claimed to get an accuracy of 75% while the loss was 55%. Kumar et al. [11] used this machine learning technique and TensorFlow, Keras, dictionaries, pandas, and NumPy packages. They have trained the model in 500 iterations (Epochs). In this research [12] , R. Sharma, N. Goel used two deep learning techniques namely Long Short-Term Memory (LSTM) and Bi-LSTM explored for the task of predicting the next word, and an accuracy of 59.46% and 81.07% was observed for LSTM and Bi-LSTM respectively. Endalie et al. [13] present a Bi-directional Long Short Term-Gated Recurrent Unit (BLST-GRU) network model for the prediction of the next word for the Amharic Language. They evaluated the proposed network model with 63,300 Amharic sentences, producing 78.6% accuracy.
3. Methodology
We know methodology is the most important part of a work. It helps to achieve our goals and get significant results. In this paper, we use an advanced technique to achieve a good result. We divided our methodology into two parts. One is a dataset summary, and the other part is implementation.
3.1. Dataset Summary
For this work, we collect a vast amount of data in the Bengali language. We tried a unique method for this work and used 114,852 amounts of data. We collected all data from different sources. Table 1 shows the data collection summary from several sources.
After collecting all data we remove unwanted objects like (“, (), /, ! |, ?, #, [, ]) and also removed the English word, another language word that is found in our dataset. Because we need only Bangla words to get a good result. We can use this cleaning dataset to get standard values for other purposes.
We divided collecting data into two parts which are train data and test data. In this model Train and test data are used for the prediction of the next word. We proposed a sequence model for next words prediction and also used an embedding layer for Natural Language Processing. In this model, there is a dense layer for connecting with every preceding layer.
• Dataset Cleaning Process
For data cleaning, we take our total dataset into a function. This function removes all unwanted objects like (“, (), /, ! , |, ?, #, [, ], ’, ", \) and also remove English and other language word. We create 5 various datasets from the cleaning standard dataset using the n-gram idea which includes uni-gram, bi-gram, trigram, 4-gram, and 5-gram.
We showed in Figure 1, the dataset cleaning format, also the creation of 5 new clean datasets. The n-gram language model allocates possibilities of the next word sequence and this model follows an (n − 1) order of n items. Here we created 5 models which will give us different outputs for different inputs. Usually, to forecast the possible next word or words, the necessary number of input text can be varied. When we input a single word and predict the next probable words. This is called unigram or 1-gram [14] . Unigram does not use the history of words. When input will be two words and predict the next words using the
![]()
Figure 1. Workflow Diagram of dataset cleaning.
history of one word from two words. It is called the Bi-gram model. Similarly, the input will be three words to predict the next words using the history of the last two words from three words. It is called the tri-gram or 3-gram model. Again 4-gram and 5-gram also input four and five words and it also takes the history of the last 3 and 4 words to predict the next words. Generally, the previous 4 or 5 words are enough to understand the sequence sufficiently. For a better understanding of this model, we use a Bengali sentence as an example—We exhibit our models using this sentence in Table 2. 
3.2. Implementation
To train the proposed model, we made a corpus of 114,873 words. The data of the corpus has been taken from popular Bangla newspapers entitled the daily “Prothom Alo”, popular social media Facebook, YouTube, and Bangla academic books. The corpus contains 17,400 unique words. The N-gram model measures the possibility of feasible next words and N-gram models cannot deal with incoming problems for zero possibility due to the dataset’s lack of expected next terms [15] . It elects the maximal probable words from all the probabilities words and sets the new one or more words. Usually, language models calculate the
![]()
Table 2. Exhibit models using a sentence.
Likewise, the 5-gram model uses five inputs and provides three output values like other models.
possibility of the presence of a word counts in a certain sequence. For Example, when the model uses bi-grams, the frequency of each bi-gram is computed by combining every word with its previous work, which the frequency of the related uni-gram would split.
The relationships between the bigram and trigram models are shown in Equations (2) and (3) below [16] .
(1)
(2)
We know n-gram is a good contribution to word prediction but there are some limitations here. For this reason, it cannot advise the next most possible words. It also failed to predict the proper standard. N-gram does not work efficiently where the dataset is a big and too lengthy sequence. Some methods like Back-off and Katz Back-off are used in n-gram for the probability distribution with the small count and a sigmoid activation function in Equation (4) is employed to compress the result between 0 and 1 once the two outcomes are concurrently added [17] . Here, we predict the next proper words using Bengali language corpus data and also suggest two full sentences. Our research also used RNN (Recurrent Neural Network) because this performs nicely with sequential data. RNN uses Equation (3) for permanent state by using output as input where the input is
having a weight W and
having a weight value of U.
(3)
Figure 2 shows the GRU-based RNN models training structure.
There is a limitation of RNN is that RNN has a problem remembering long sequences. Vanishing gradients are an issue with RNNs that makes learning from lengthy data sequences difficult. The gradients contain the data used to update the RNN parameters, and when the gradient shrinks, the parameter updates lose significance, which implies no true learning is done [18] .
We are able to solve the vanishing gradient problem using GRU (Gated Recurrent Unit) and LSTM (Long Short-Term Memory). The update gate and reset gate are the two gates that GRU utilizes, hence we used it in our research [18] . However, LSTM employs three gates—input, forget, and output—to address the gradient problem [18] . GRU lack both internal memory and the output gates found in LSTM. GRU performs quicker than LSTM and consumes less training parameters and memory [19] .
![]()
Figure 2. GRU-based RNN models training structure.
The update gate and the reset gate are two vectors that select the information to pass to the output in the GURU model. In Equation (4) counting the update gate zt for time step t,
(4)
When xt is connected to the network unit, its weight W is multiplied (z). It’s the same with
, which contains information about previous
units and is multiplied by its own weight U(z). Basically, the Reset gate is utilized from the model to determine how much past information must be forgotten. Reset gate use Equation (5) for calculating:
(5)
Inputs
and
are added, their corresponding weights are multiplied, the results are added, and the sigmoid function is used. In this research, we trained all datasets using GRU-based RNN and created five models.
Figure 3 displays the trained model structure. Embedding (Embedding), gru_4 (GRU), gru_5, dense_4 (Dense) and dense_5 are five hidden layers and entire params of 2, 719, 389, trained params 2, 719, 389, non-trained params 0 in trained models.
• Word Prediction
We got five trained models from completing the training of five datasets. These Five models take different length inputs and determine the next predicted words as output. So, when the input word length is one, it will go Uni-gram trained model because Uni-gram trained model is prepared for one input word and predicts three next words.
Similarly, the input word is two, then it will go to the bi-gram trained model because it takes two words as input and predicts the next three words.
![]()
Figure 3. Type of layer with the respective where n = 3.
Correspondingly, the input words are three then it will go to the trained Tri-gram model and predict the following three words using the last two inputted sequences. Again, the input word is four and five, then it will be sent into a 4-gram and 5-gram trained model then it will predict the next three words. Something is different when the input number length is more than 5. In this case, it would use only the last 3-word sequence and then send it to the tri-gram model to predict the next three words.
Figure 4 shows the input that is taken from the keyboard and sent to the trained model and displays the prediction of the next word from the trained model.
• Sentence Completion
Firstly, we said, in this research, will predict the next probable words and further propose a whole sentence using these predicted words. We used our earlier proposed structure of the N-gram model which is trained by GRU base RNN. We add our output (predicted next words) with the previous input values. We can use our new current input values to predict furthermore words which ultimately creates a full sentence. This method will end after completing a full sentence. In this work, we give the highest number of words length 15 for a sentence. Therefore, the whole output should be the proposed possible sentence. Now In Table 3, we have a Bengali sentence as an example to understand it better Predicted words:
4. Results
This time we need to experiment and analyze our proposed method. Because to ratify the proposed method, we must execute tests and analyze our results sincerely.
Consequently, evaluate our offered method on a corpus dataset. We train all models with similar structures up to 2500 epochs (Figure 5). Among the five trained models, the average exactness of the unigram model is 81.22% and the average Loss of this model is 33.73%. The average accuracy in the Bi-gram model is 89.31% and 19.56% is the average Loss in this model. The Tri-gram model
![]()
Figure 4. Processing the next probable word using the trained model.
![]()
Table 3. Example of probable next word.
Completing sentence: 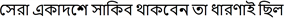
![]()
Figure 5. The average exactness of the trained model in a Graphical Presentation.
has an average accuracy of 97.69% and 4.13% average loss for this dataset. Similarly, 4-gram and 5-gram models get an average accuracy of 99.43% and 99.78%, whereas these two models have an average loss of 2.07% and 1.15%.
Figure 5 shows the average accuracy of our five models. Where every model started 0 and completed 2500 epochs, and after 700+ epochs, the accuracy is stable. The following Table 4 shows the average accuracy and average Loss for five trained models. Where we see when the input number is increased then average accuracy is increased, and average losses are decreased.
![]()
Table 4. The average accuracy and average Loss.
We used GRU in the N-gram language model, where we compared the results of our suggested model with the models in other research papers.
![]()
Figure 6. Comparison with other research papers.
Figure 6 shows the comparison among paper 6, paper 18 and our proposed system. In paper 6, they used Tri and a Hybrid Approach of Sequential LSTM and N-gram and their accuracy was 84%. On the other hand, we have a maximum efficiency of 99.78% for high-order sequences. In paper 18 [20] , they got an accuracy on average 69.1% for their proposed method whereas our paper has 99.78%.
5. Conclusion
We used a larger data corpus than other researchers in the Bangla language. GRU-based RNN has displayed a noteworthy performance in this work to predict the next most probable Bangla words and complete sentences. As we can see, our research work has better results than other research works in the Bengali language. Our proposed method in higher-order like Tri-gram, 4-gram, and 5-gram, exactness rate is very good (respectively 97.69%, 99.43%, 99.78%). All in all, our proposed method is impressive because we use a larger dataset here. In this study, the Bangla dataset used is very challenging because there is no ready-made dataset for the Bengali language. So, we manage datasets from various origins.
Acknowledgments
I would like to thank my all co-authors for their support and encouragement.