1. Introduction
A physical or a socioeconomical system (described through quantum mechanics or game theory) is composed by n members (particles, subsystems, players, states, etc.). Each member is described by a state or a strategy which has assigned a determined probability
. In evolutionary game theory, the system is defined through a relative frequencies vector x whose elements can represent the frequency of players playing a determined strategy. The evolution of the density operator is described by the von Neumann equation which is a generalization of the Schrödinger equation. It is a basic equation and a basic assumption of quantum mechanics proposed by Schrödinger, an Austrian physicist. So people started to use quantum language (entropy function) to study game theory (Orrell, 2019).
Firstly, Shubik (1999) finds there are three basic sources of uncertainty in an economy: exogenous, strategic, and quantum. The first involves the acts of nature, weather, earthquakes, and other natural disasters or favorable events over which we have no control. Strategic uncertainty is endogenous and involves our inability to predict the actions of competitors.
Later in their paper (Haven et al., 2018), they say in quantum mechanics, a state is formalized with a wave function, which is complex valued. That state will now form part of a Hilbert space. Position and momentum in quantum physics are real-valued, and one needs to find so called operators in the Hilbert space which can represent those real quantities. In Drabik (2011), the author introduces the basic concepts of quantum mechanics to the process of economic phenomena modelling. Quantum mechanics is a theory describing the behaviour of microscopic objects and is grounded on the principle of wave-particle duality. It is assumed that quantum-scale objects at the same time exhibit both wave-like and particle-like properties, but he just lists all the physics information, not exactly gives a connection with game theory.
These work (Hubbard, 2017; Hidalgo, 2007a, 2007b) focus on entropy (mostly is minmax question) to analysis the iteration of the game. But we want to analyze the game strategy based on Schrödinger equation solution (which also represents the state). We use the distance of two states to represent “good” or “bad” for two players and the “jump” between two different states is exactly the player’s strategy for the next game around (Samuelson, 1997).
Our paper concludes four sections, in the second section, we will give the model of Schrödinger equation and game theory separately. In third section, we give some basic theorems, examples and proof. In the last section, we have our conclusions and discussions.
2. Model
2.1. Schrödinger Equation
At the beginning of the twentieth century, experimental evidence suggested that atomic particles were also wave-like in nature. For example, electrons were found to give diffraction patterns when passed through a double slit in a similar way to light waves. Therefore, it was reasonable to assume that a wave equation could explain the behaviour of atomic particles. Schrödinger was the first person to write down such a wave equation. The eigenvalues of the wave equation were shown to be equal to the energy levels of the quantum mechanical system, and the best test of the equation was when it was used to solve for the energy levels of the Hydrogen atom, and the energy levels were found to be in accord with Rydberg’s Law.
In this part, we will give the exact Schrödinger equation, for simplifity, the system is closed which means two players can not be affteced by outside factors. So the potential can only change with people’s different thoughts. Also, each one can do optimal choices instead of information loss during their decision. The details will be discussed in the next sections.
Assumption 1. For a fixed time
, for each player, they each only have two states, i.e., for player A, he has states
and
, similarliy, for player B, he has states
and
. And the states represents different solutions of the equation.
Assumption 2. For each player, they have their own same equation with different initial values. There is no entanglement between these two quantum phenomenon.
Schrödinger developed a differential equation for the time development of a wave function. Since the Energy operator has a time derivative, the kinetic energy operator has space derivatives, and we expect the solutions to be traveling waves, it is natural to try an energy equation. The Schrödinger equation is the operator statement that the kinetic energy plus the potential energy is equal to the total energy.
Traditionally, the Schrödinger equation is used to express the evolution of a quantum particle on the surface by its wave function
:
(1)
where
is the gradient operator at x,
is the Laplacian, m is the mass,
is the reduced Planck constant,
is the real time-dependent potential, and
is the initial wavefuntion.
But here we use this equation to express player’s choice moving and simplify the model as
, the potential v is time-independent. Then the modified equation for player A changes to:
(2)
Similarly, for player B, his equation is:
(3)
Since the Schrodinger equation is like the “heat equation” (only difference is time t changes to it, so from the fundamental solution of heat equation, we know that there is also “fundamental solutions” for Schrödinger. After the comparsion, for the Schrödinger equation, we need the calculation of
, which in one dimension situation. Actually the sqaure root of i has two roots which is suitable for our player’s two states in a time.
2.2. Game Theory
Game theory is a set of techniques to study the interaction of “rational” agents in “strategic” settings. Here “rational” measn the standard thing in economic: maximizeing the obejectives functions subject to conditions; “strategic” means the player care not only their own actions, but also about the actions taken by other player.
Modern game theory becomes a field of research from the work of John von Neumann. In 1928, he wrote an important paper about two-person zero-sum games. In 1944, he and Oscar Morgenstern published their classic book (Von Neumann & Morgenstern, 1947), Theory of Games and Strategic Behavior, theta extended the work on zero-sum games, and alsp started cooperative game theory. In the early 1950’s, John Nash made his contributions to non-zero-sum games (Nash Jr., 1950) and started bargaining theory. After that, there was an explosion of theoerical and applied work in game theory and the methodology was well along its way to its current status as a tool (Shubik, 1999; Samuelson, 1997; Selten, 1975; Samuelson, 2016).
And in our paper we will focus on noncooperative game theory, which means the former takes each player’s individual actions as primitives, whereas the latter takes joint actions as primitives. And we have the following assumptions about the players:
Assumption 3. The number of players is 2, player A and player B.
Assumption 4. There is no outside factors affecting their strategies.
Assumption 5. Each one is smart enough to have the optimal choice and no information loss when they have the decision. From the Schrödinger equation, The conservation law is true.
Definition 1. Players has no information loss during any time they make the decision is the
norm integration of their “equation” solution from
to
is always constant 1.
Since this integral must be finite (unity), we must have the solution
as
in order for the integral to have any hope of converging to a finite value. The importance of this with regard to solving the time dependent Schrödinger equation is that we must check whether or not a solution
satisfies the normalization condition.
Definition 2. (Distance Between Different States). Distance between two state i and j is defined as:
Definition 3. (Information of Strategy Sets). A collection of information set, I is a set of linear combination of two solutions for a fixed time
, e.g. player A at time
, his information set is:
Here
are the basic solutions of the equation. It is a mixed strategy for player A since he has two pure strategy distributions.
satisfying
. Just like the famous Schrödinger’s cat paradox which stated by Schrödinger in 1935. He presented a case of cat in a box which has fifty percent of survive and fifty percent it may die. So if we open the box, we can find the cat is alive or dead, but when we close the bos, there are infinity states it can be. According to this, we can explain the startegy: when we do the choice, we only have A and B these two choices. But when we are thinking, no one knows what we are thinking and actually we have infinity thoughts in our own brain.
Definition 4. (States Evolution as Strategy Change). When player A starts to change his strategy according to his guess of player B’s behavior, state change means the evolution for the Schrödinger solution. If his initial state is i, and the state changes to j after time t, the relation between i and j is
.
Of course the time is a continuous parameter we obvious have
Definition 5. (Strictly Dominant Strategy) Similiarly as the definition in traditional game theory, a startegy state
is a strictly dominant strategy for player A is for all
, and all states
for player B,
.
Definition 6. A state i and j for A and B is a Nash Equilibrium if and only if their distance is the least, i.e., for any other states
and
,
. It also has another name: Stable Equilibrium.
Remark 1. This idea is from the model of the electron. The internal power between two electron is related to their distance, more closeness more power. If they are far away, exact little power between them, we do not care about these two electron. The two players are the “opponents” and “partner”, player A is affteced by B and player B is affected by A. So there should be more “power” between them.
Definition 7. (Uncertainty principle for player) Any player of two can not exactly guess what his opponent’s strategy in the next step for what probability.
Remark 2. The uncertainty principle is one of the most famous ideas in physics. It tells us there is a fuzziness about the behavior of quantum particles and we can not determine particle’s position x and momentum p at the same time. There is a famous inequality derived by Werner Heisenberg:
where
is the reduced Planck constant:
. In two-players game, x represent their opponent’s behavior set (which is also the information set), p represets the related probability to take such decision. This phenomenon can not happen: player B continues his strategy always whatever A’s strategy is, then
, a contradiction with the uncertainly principle. In next section, we will give the example and proof about this.
3. Basic Theorem
Theorem 3.1. A player can have at most one strictly dominant strategy.
Proof. If we assume player A has two strictly domiant strategy and each one is state
and
, then for any state
and states j for player B, we have the inequality:
Same idea for state
, we still have the inequality:
We pick
in the first inequality and pick
for the second one, which is a contradiction.
Remark 3. There can be no strategy state i for player A such that for all
of A and j of B,
. B is the same.
Theorem 3.2. The game system is closed under the time-evolution, which means
norm of the state (solution) is always 1.
Proof. It is obvious from the property that
.
Theorem 3.3. The time evolution operator is only related to its end time: intial time
and ending time
, it has no relation with the middle states from
to
. From the strategy idea, two players will have the decision in a fixed time and the opponent does not care about your thinking process.
Proof. Assume we have the inital state
and start to evolve to time
, there are two possibilities: 1) First one is directly “jump” from
to
; 2) Second part we have many “stopping thinking time”
, until
. Compare these two states:
We find they have the same result and finish the proof.
Theorem 3.4. Two players will get Ne (Nash Equilibrium) in a period time.
Proof. If we consider two players evolve separately, which means player A is from state j to state
, and player B is from state i to state
, then calculate their distance:
(4)
So we can only consider the state i evolution! Assume we evolve after time t, then the distance between these two is:
(5)
which is function of t and we want to minimize the
, so need to make sure
as big as enough. Now we write the state in the linear combination of energy eigenstate
:
And each constane
,
can be expressed as the norm times the exponential function of phase:
Then
(6)
For fixed p,
situation:
(7)
Return back to Equation (6), we have the final formula:
To maximize the Equation (5) is equal to:
Since
for any
. Here we will use the following lemma to make sure we can take the equality for special t.
Lemma 3.5. There exists infinite
such that
for each p and the period time is related to
and
.
Proof. We focus on
,
is the same extension.
Assume there exists two numbers
and
such that the following equalities satisfy:
If we rewrite these equations with t, we have the following equality:
Obviously we can choose suitable
such that their difference is
some integer q times
, according from the famous Bohr formula:
, so
is the rational expression
, pick suitable
such that
is also an
integer. Then go back to the t equation to get t. Simliarly, for
, we can still find their least common multiple.
Example 1. (For Definition 7) The prison’s dilemma is a standard example of a game analyzed in game theory and we will use it first as an example for the uncertainty.

1) If A and B each betray the other,each of them serves two years in prison;
2)If A betrays B but B remains silent,A will be set free and B will serve three years in prison (vice versa).
3)If A and B both remain silent,both of them will serve only one year in prison.
So actually each player is in the dilemmas and no one knows his/her opponent’s strategy for the next step. It is a classical application of the “Uncertainty Principle”.
Example 2. (This example is from the lecture notes (Ferguson, 2005) (Odd and Even) Player A and B simultaneously call out one of the numbers one or two. Player A’s name is Odd; he wins if the sum of the numbers is odd. Player B’s name is Even; she wins if the sum of the numbers is even. The amount paid to the winner by the loser is always the sum of the numbers in dollars. We choose
and the table is following:
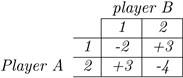
Let us analysis the game from Player A’s point of view.Suppose he calls “one”3/5ths of the time and “two”2/5ths of the time at random.In this case,
1)If B calls “one”,A loses 2dollars 3/5ths of the time and wins 3dollars 2/5ths of the time;on average,he wins 0.It is a even game in the long run.
2)If B calls “two”,A wins 3dollars 3/5ths of the time and loses 4dollars 2/5ths of the time and average he wins 1/5.
Clearly if A mixed his choices in this given way,the game has two ending:even or A wins 0.2dollar on the average every time.
1)If we think about after a long time “even”,A and B have no change,without loss of generality,the schedule for A is 1,1,1,2,2.Then B starts to think if he can do some change and earn money.So when A is “asleep”,she chooses 2when A is 1and she chooses 1when A is 2.Then each time she can earn 3dollars,A is losing! So based on such situation happen,A should be clear each step and do some changes which is hard for B to guess A’s strategy.
2)Similarly,for second situation.B calls “two”and A wins 0.2dollar average time.A is happy since he can earn money without doing any change,but B want to “save”money unless each game she will lose 0.2average.So she will call “one”without any dilemma,at that situation,A get nothing (since the average payoff is 0),so he will try to make some changes.In that case,each one will behave randomly without fixed strategy.
It satisfies the uncertainty principle.
However, player A can not player know B’s strategy, can he guess her probability for the next step? Of course he can, this is the following theorem from the quantum mechanics.
Theorem 3.6. For player A, he can guess the probability of player B’s from state
to
at time t:
Here
is definded as:
is the initial Hamiltoian operator:
. The player A has a time dependent perturbation
, and
,
,
. We write
.
The proof is similar from the reference book (Griffiths, 2007).
Proof. To begin with, let us suppose that thare are just two states
, then the solution function
can be expressed by the combinations of these two:
And now since we have the perturbation, the new Schrödinger equation is:
Then combine these two together and cancel the term, hence
To isolate
, we use the trick: Take the inner product with
, and exploit the orthogonality of
and
, conclude that:
Then after simplifying the equation:
Since our
is “small”, we can solve the equation in a process of successive approximations. Suppose the particle starts out in the lower state:
After the comparsion of zero order and first order, we can have our final conclusion (skip the detail here):
which means the player B can guess player A’s moving probability in a sense. Vice versa, player A can guess player B’s.
4. Conclusion and Discussions
In our article, we firstly combine the two-players strategy game and Schrödinger equation together, have a connection, successfully explain the game evolution using solution state. It transfers the economics problem to the physical question. Also, we determine the “good” or “bad” based on the distance of two states which is clear and easy to compare and apply the famous quantum mechanics results into the game theory, however we still cannot exactly transfer the game “language” into the initial potentials
or the equation directly, which is an limitation. And we hope to get the game strategy based on the equation solution (states) totally.
However, the distance we defined in the previous section is in the eigenstate basis, but when we perform an measurement of the whole system, we need a transformation for the computational basis, also we will get a probability of getting to the exact state, which helps us approximate the opponent’s strategy. It is an ongoing project.